









The workflow steps are a sequential set of tasks. A workflow consists of multiple steps. The behavior of the step is defined through its type. The type of step determines the purpose of the step, the input parameters the step requires, and how the output parameters of the step are processed.
The structure of the step and its relation to the workflow is illustrated in the following diagram.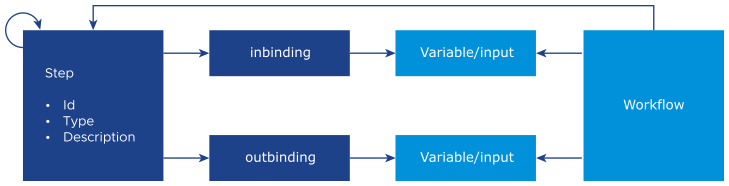
This section provides a detailed description of each step type.
Initial step
The initial step of the workflow is defined by the startStepId field of the workflow, and the steps that follow are defined by the nextStepId field. The workflow ends if the executed step does not have the following step. In this scenario, the startStepId field is not available in the step definition.
The link between the steps is illustrated in the following template fragment:
{
"startStepId": "stepId1",
"steps": {
"stepId1": {
nextStepId": "stepId2",
...
},
"stepId2": {
"nextStepId": "stepId3",
...
},
"stepId3": {
...
}
},
...
}
Specifications for step input binding
- Type: A mandatory data type of the input binding.
- Format: An optional format of the type.
- defaultValue: Default value of the input binding. This value is used if the exportName is not available or is referring to an element with no value.
- exportName: The name of the input or variable from which the step input takes its value.
Inputs and variables of a step are illustrated in the following template fragment.
{ "inputs": { "input1" : { … }, "input2" : { … } }, "variables": { "variable1" : { … }, "variable2" : { … } }, "steps": { "stepId1": { "inBindings": { "stepInput1" : { "description" : "my input value for this step", "type": "string", "defaultValue" : "foo", "exportName" : "input1" }, "stepInput2" : { "type": "string", "defaultValue" : "bar" }, "stepInput3" : { "type": "string", "exportName" : "variable1" } } } }, … }
Using double curly brackets in variables
Default values in step input bindings with string data types contain double curly brackets. You can specify the variable or input names within the curly brackets. The value of the variable or workflow input is substituted.
The usage of double curly brackets is illustrated in the following sample code snippet:
{
"inputs": {
"input1" : { ... }
},
"variables": {
"variable1" : { ... }
},
"steps": {
"stepId1": {
"inBindings": {
"stepInput1" : {
"type": "string",
"name" : "variable1",
"defaultValue" : "fix{{input1}}_{{variable1}}"
}
}
}
},
...
}
Specification of output bindings
The steps are executed based on the step inputs, and after the step execution is complete, the step outputs are produced. The processing of the step outputs is controlled by the outBindings section. The outputs of the step are assigned to the workflow variables and outputs. The key component in outBindings is the name of the output that the step produces. A step output may be used several times to populate other entities or may never be used.
- type: A mandatory data type of the output produced by the step.
- name: A mandatory name of the variable or output to which the step output is saved.
{
"outputs": {
"output1" : { … },
"output2" : { … }
},
"variables": {
"variable1" : { … },
"variable2" : { … }
},
"steps": {
"stepId1": {
"outBindings": {
"stepOutput1" : {
"type": "string",
"name" : "variable1"
},
"stepOutput1" : {
"type": "string",
"name" : "output1"
},
"stepOutput2" : {
"type": "string",
"name" : "output2"
}
}
},
…
},
…
}
Specification of conditional next steps
By default, the nextStepId field controls the step that follows. However, if the step contains a Conditions section, then first, the Conditions section is evaluated before processing the nextStepId field, which determines the next step. The purpose of the conditions section is to create decision points in the workflow. A decision point is an opportunity to select the next step to be executed based on the given conditions. The conditions section contains an ordered list of conditions. Each condition represents a decision point, and each decision point is evaluated one after another.
- name: The name of the workflow input, output, or variable against which the condition is evaluated.
- comparator: The comparator of the condition.
- value: The optional second operand of the comparator.
- nextStepId: The mandatory identifier of the next step is the evaluation of the condition that is true.
| Value | String | Boolean | Number | Note |
|---|---|---|---|---|
equals |
x | x | Is the referred element equal to the second operand? | |
isDefined |
x | x | Does the referred element have a value? | |
contains |
x | Does the value contain a second operand? | ||
match |
x | Does the value match the regular expression specified in the second operand? | ||
isFalse |
x | Does the referred element have the true value? | ||
isTrue |
x | Does the referred element have a false value? | ||
different |
x | Is the referred element different from the second operand? | ||
greater |
x | Is the referred element greater than the second operand? | ||
greaterOrEquals |
x | Is the referred element greater than or equal to the second operand? | ||
smaller |
x | Is the referred element smaller than the second operand? | ||
smallerOrEquals |
x | Is the referred element smaller than or equal to the second operand? |
The definition of conditional statements is illustrated in the following template fragment:
{
"input": {
"input1" : { ... },
"input2" : { ... }
},
"variables": {
"variable1" : { ... },
"variable2" : { ... }
},
"steps": {
"stepId1": {
"conditions": [
{
"name": "input1",
"comparator": "smaller",
"value": 5,
"nextStepId": "stepId1"
},
{
"name": "variable1",
"comparator": "greaterOrEquals",
"value": 5,
"nextStepId": "stepId2"
},
{
"name": "variable1",
"comparator": "isDefined",
"nextStepId": "stepId2"
},
{
"name": "variable2",
"comparator": "equals",
"value": "foo",
"nextStepId": "stepId2"
},
{
"name": "variable2",
"comparator": "match",
"value": "myRegularExpr.*",
"nextStepId": "stepId2"
},
{
"name": "variable1",
"comparator": "greater",
"value": 5,
"nextStepId": "stepId2"
},
{
"name": "variable1",
"comparator": "smaller",
"value": 5,
"nextStepId": "stepId2"
},
{
"name": "variable1",
"comparator": "smallerOrEquals",
"value": 5,
"nextStepId": "stepId2"
},
{
"name": "variable1",
"comparator": "greaterOrEquals",
"value": 5,
"nextStepId": "stepId2"
}
]
},
"stepId2" : { ... }
},
...
}
Common inputs for all step types
The name of the input and output bindings of one step is defined by the type of the step. Each step type consists of different inputs and outputs. Each step, irrespective of its step type, defines the timeout and initialDelay input bindings. timeout specifies the maximum waiting time in seconds for the step execution to complete without considering the waiting time for user interaction. initialDelay binding specifies the waiting time before executing the step. Both bindings consist of numbers as the data types.
Input and output bindings are illustrated in the following template fragment:
{
"inputs": {
"inputDelay" : { ... }
},
"steps": {
"stepId1": {
"inBindings": {
"timeout": {
"type": "number",
"defaultValue": 123
},
"initialDelay": {
"type": "number",
"exportName": "inputDelay"
}
}
}
},
...
}
Steps that require a vRO instance to interact with a VIM instance define an input binding that specifies which vRO or VIM instance to be used. The type of this input binding is vimLocation, and the name can be anything that is not used by the step. This binding is called location. The presence of the VIM location is mandatory if the system cannot unambiguously identify it. If the workflow is executed on an NF, then the VIM is deduced from the location of the NF. However, if the workflow is not executed on an NF, then you need to specify the location of the VIM.
Following is a sample template fragment:
{
"inputs": {
"vimInput": {
"type": "vimLocation",
"required": true
}
},
"steps": {
"stepId1": {
"type": "VRO_SCP",
"inBindings": {
...
"vim": {
"type": "vimLocation",
"exportName": "vimInput"
}
},
...
},
},
…
}
