









VIO control plane consists of two categories of controllers. VMware SDDC controllers and VIO core services running in the VMware Tanzu Kubernetes Grid cluster.
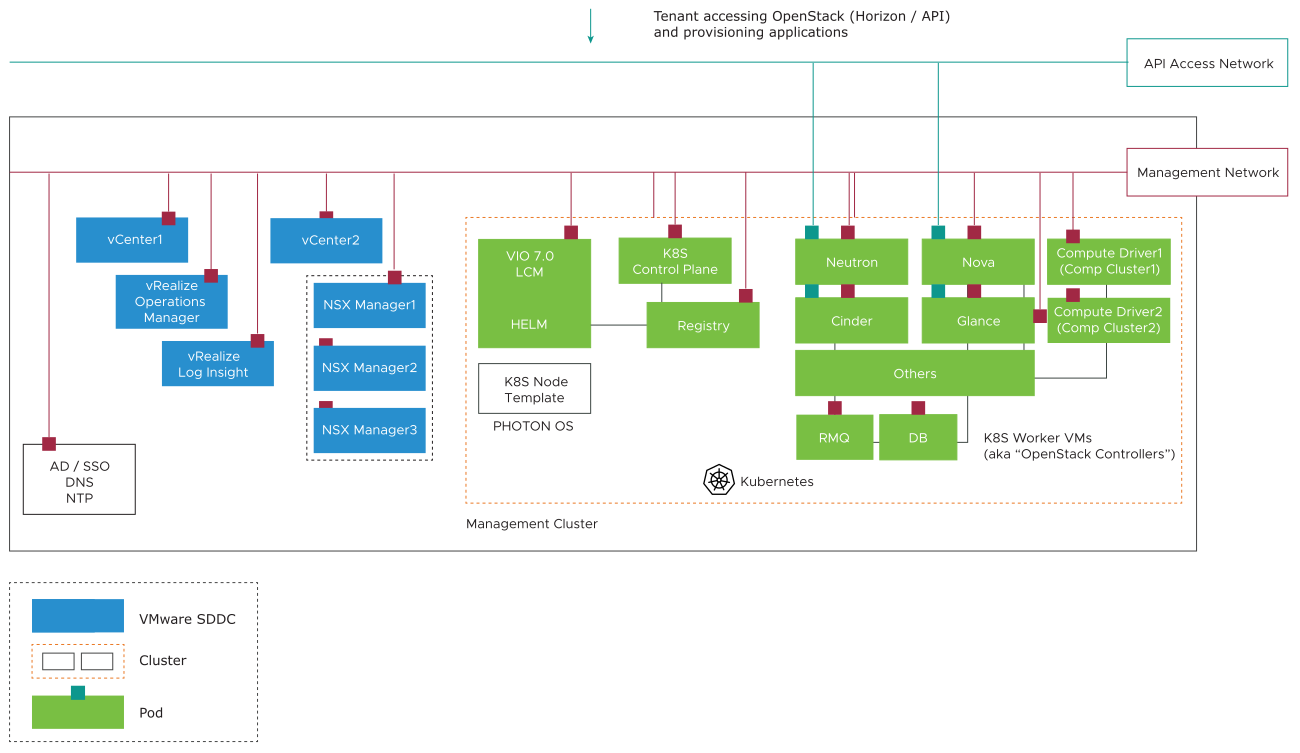
The VIO infrastructure deployments consist of the following two categories of VMs:
VMware SDDC Essential Services
NSX Manager: The centralized network management component of NSX. It provides an aggregated system view.
vCenter Server: Two vCenter instances. One for management and another for resource and edge Pods.
vRealize Operations (vROps): Used by administrators to monitor, troubleshoot, and manage the health and capacity of the OpenStack environment.
vRealize Log Insight: Intelligent Log Management and Analytics tool for OpenStack and SDDC infrastructure. vRealize Log Insight is integrated with vROps to provide a single pane of glass monitoring and logging of the OpenStack and SDDC infrastructure.
VIO Core Services run as containers in the VMware Tanzu Kubernetes Grid cluster. Kubernetes cluster is deployed using Photon OS VMs. OpenStack tenant workloads do not run in this cluster, which is dedicated to OpenStack control plane services. A HA VIO Kubernetes cluster consists of the following types of nodes:
Kubernetes Control Plane VM: The primary component for lifecycle management of the VIO control plane. Each VIO deployment includes one Kubernetes control plane VM. This VM runs
Kubernetes control plane processes
Helm and its OpenStack charts
Cluster API for Kubernetes cluster LCM
VIO LCM web user interface
VIO Controller or worker nodes: Kubernetes worker nodes. Three Kubernetes worker nodes in a standard out-of-the-box HA deployment. The VMs house the majority of the OpenStack control plane components running in containers. Cloud admins can scale up the controllers to 10.
OpenStack Services
OpenStack services run in pods made up of one or more containers. Services such as the Horizon UI, Nova, Glance, Keystone, Cinder, and Neutron all run as pods on the controller node. Communications between Pods are either internal, between services, or external with VMware SDDC through various drivers:
OpenStack Service |
VMware SDDC |
Type of Driver |
|---|---|---|
OpenStack Nova |
vCenter |
VMware vCenter Driver (VMware VC Driver) |
Glance |
vCenter |
VMDK Driver |
Cinder |
vCenter |
VMDK Driver |
Neutron service |
NSX-T manager |
VMware NSX plug-in |
For redundancy and availability, OpenStack services run at least two identical Pod replicas. Depending on the load, Cloud admins can scale the number of pod replicas up or down per service. As OpenStack services scale out horizontally, API requests are load-balanced natively across Kubernetes Pods for even distribution.
Nova-Compute Pods
Compute pod represents an OpenStack hypervisor to the nova-scheduler. Unlike the traditional KVM-based approach where each hypervisor is represented as a nova-compute, each VIO nova-compute pod represents a single ESXi cluster. For each vSphere cluster in the deployment, one additional nova-compute pod is created. Each nova-compute is configured independently and can map to different vCenter instances. The VMware vCenter driver activates the nova-compute service to communicate with VMware vCenter Server. All attempts to create, update, or delete a VM on a cluster is handled by the nova-compute pod.
RabbitMQ Pod
RabbitMQ is the default AMQP server used by all VIO services, an intermediary for messaging, providing applications with a common platform to send and receive messages. In general, all core OpenStack services connect to the RabbitMQ message bus. Messages are placed in a queue and cleared only after they are acknowledged. The VIO RabbitMQ implementation runs in active-active-active mode in a cluster environment with queues mirrored between three Rabbit Pods. Each OpenStack service is configured with IP addresses of the RabbitMQ cluster members and one node is designated as primary. If the primary node is not reachable, the Rabbit Client uses one of the remaining nodes. Because queues are mirrored, messages are consumed identically regardless of the node to which a client connects. RabbitMQ can scale up to millions of connections (channels) between endpoints. Channels are TCP-based, brought up or torn down based on the type of requests.
RabbitMQ is not CPU intensive but requires sufficient memory and strict network latency. RabbitMQ nodes can span across multiple data centers but are not recommended unless there is guaranteed low network latency.
RabbitMQ stores cluster information in the Mnesia database. The Mnesia database is internal to RabbitMQ Pod and is extremely lightweight. The database includes the cluster name, credentials, and the status of member nodes. Operational stability of OpenStack is as stable as the RabbitMQ cluster. In an environment where the network stability is low, RabbitMQ cluster can enter into a partitioned state. The partition state happens when node members lose contact with each other. The Mnesia database performs detection and recovery from cluster partitioning.
Database Pods
VIO database is based on MariaDB implementation, which makes use of a three-node Galera cluster for redundancy. The database cluster is active-active-active. However, as some OpenStack services enforce table locking, reads and writes are directed to a single node through load balancers. Whenever a client consumes a resource in OpenStack, one or more of the following databases are updated:
Database |
Description |
|---|---|
Nova |
Stores information about compute nodes, aggregate mapping, instance, SSH key pairs, user quota, and instance metadata |
Heat |
Stores information about heat stack status: Active, deleted, timestamp of creation/deletion, tenant mapping, and so on. |
Glance |
Stores information about image status (public, private, active, deleted, and so on), location, type, owner, format, and so on. |
Neutron |
Stores information about NSX DHCP binding, NSX network-subnet-port mapping, and NSX router binding based on the tenant. |
keystone |
Stores information about service catalog, region, identity provider, user, project, and federation grouping. |
Placement |
Stores the list of consumers and associated usage for CPU, memory, and storage. |
