









In this topic, you can find information about common issues and solutions from VMware Telco Cloud Operations KPI.
- Not able to deploy Stream successfully:
Misconfiguration can cause the stream deployment failure. The stream is deployed along with the KPI Definitions that are configured in the stream. So, if the stream failed to deploy, verify both the stream and the KPI Definitions are used. Ensure that, no double quote is used in the text boxes, you must use a single quote instead.
- Error processing stream events:
When processing the stream events, the KPIs can be calculated per group by using the property in the event.
For Example: the Traffic-by-IP uses IP as the grouping key. KPI Definition can configure one of the event text boxes as the Group By key. If the Key is not present in the event, that can cause processing the stream.
For Example: Metadata ['deviceName'] can resolved, and can be null in some events.
In this case, the following configuration for the Group By text box groups all events without deviceName properties as deviceName = 'unknow':
metadata['deviceName'] == null ? 'unknown' : metadata['deviceName']
You can ignore the KPIs where the deviceName equals 'unknow'.
- There are no events being published to the output of Kafka topic:
The events flow into the stream continuously. The KPI calculation has to collect and calculate the event based on a configured time window. To delimit the time window start/end, the KPI definition can configure the window based on the event timestamp or processing timestamp.
When using event timestamp, if the event timestamp is not present in the event or the data formatter is not parsing the event timestamp properly, then window is not able to proceed.
Therefore no calculation performed in the window. In this case, configure the window to using the processing timestamp solves the problem.
- Stream configuration lost after the failed deployment of a stream from the stream configuration page:
After you configure a stream in the stream configuration page, click DEPLOY & SAVE to deploy the stream.
The combined operation has one drawback:
When updating an existing stream, click DEPLOY to delete the existing stream first, so if deploy fails, the stream configuration is lost. This issue is addressed in the future release.
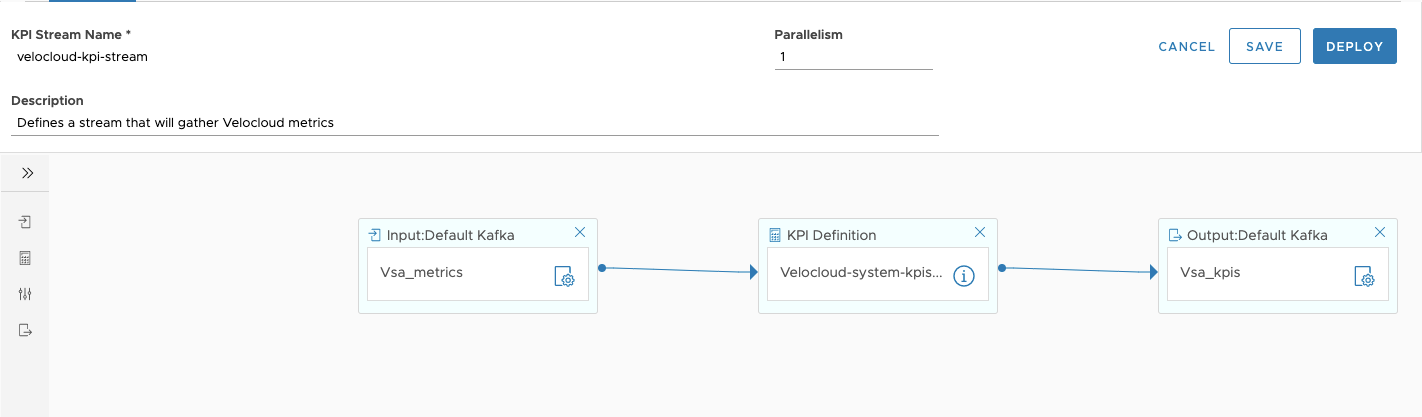
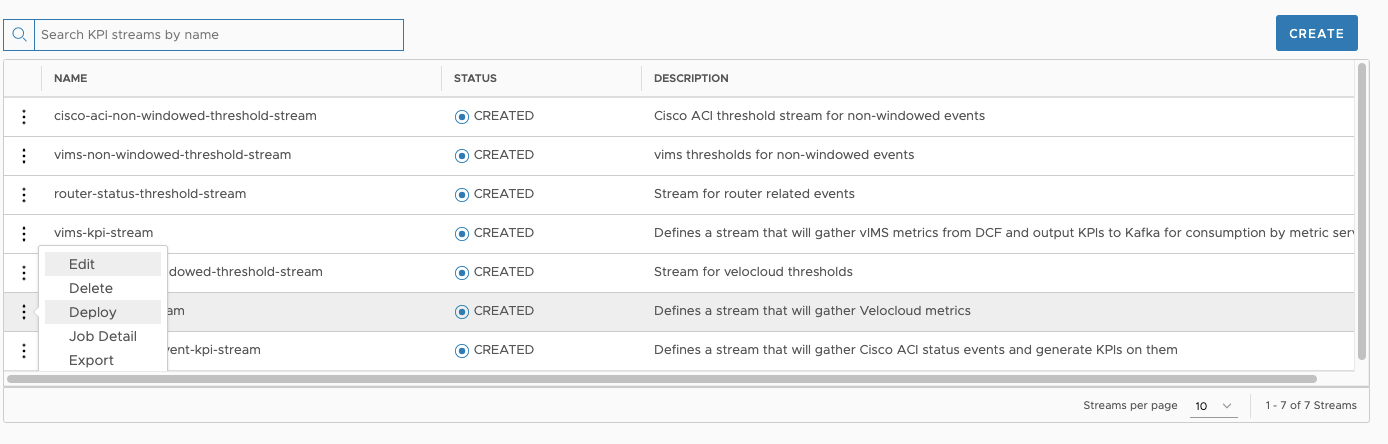
Workaround: Use the Deploy menu item, as displayed:
- When arango worker nodes goes down, events from SAM are not getting synchronized with VMware Telco Cloud Operations.
You must take action to ensure capacity is restored and streams are redeployed in the event, when any of them failed while the Flink service was unavailable. Following scenarios are possible when one of the arango workers in an HA deployment goes down:
- There are occurrence that the job manager may go down if it was initially running on such node.
- There is reduction in the capacity of Flink to run existing jobs due to the taskmanger(s) instances that are also lost.
If scenario "a" occurs, then scenario "b" also takes place, since arango workers always runs taskmanager instances.
The jobmanager service is a single instance and may be running on a different arango node. In case where arango node hosts both taskamagner and jobmanager instances, all Flink jobs are lost and there is degraded capacity.
Even if you recover the jobmanager on another node, capacity is an issue. Full recovery is only possible by bringing the worker node up. Once the node is up, you need to restart the enrichment streams with the reference data.
When only scenario "b" occurs (jobmanager is not affected), capacity is affected and some Flink jobs may fail since there is not enough resources to run all jobs with the remaining taskmangers.
