









VMware Tanzu Standard for Telco provisions and manages the lifecycle of Tanzu Kubernetes clusters.
A Tanzu Kubernetes cluster is an opinionated installation of Kubernetes open-source software that is built and supported by VMware. With Tanzu Standard for Telco, administrators provision Tanzu Kubernetes clusters through Telco Cloud Automation and consume them in a declarative manner that is familiar to Kubernetes operators and developers.
Cluster API for Life Cycle Management
The Cluster API brings declarative, Kubernetes-style APIs for cluster creation, configuration, and management. Cluster API uses native Kubernetes manifests and APIs to manage bootstrapping and life cycle management of Kubernetes.
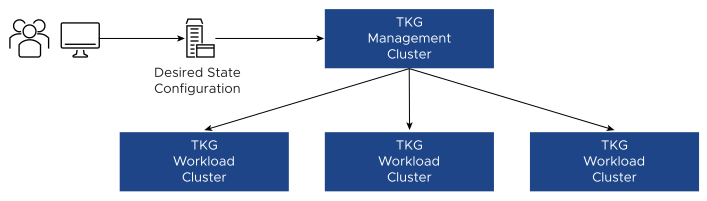
The Cluster API relies on a pre-defined cluster YAML specification that describes the desired state of the cluster and attributes such as the class of VM, size, and the total number of nodes in the Kubernetes cluster.
Based on the cluster YAML specification, the Kubernetes admin can bootstrap a fully redundant, highly available management cluster. From the management cluster, additional workload clusters can be deployed on top of the Telco Cloud Platform based on the Cluster API extensions. Binaries required to deploy the cluster are bundled as VM images (OVAs) generated using the image-builder tool.
The following figure shows the overview of bootstrapping a cluster to deploy Management and Workload clusters using Cluster API:
Tanzu Management and Workload Clusters
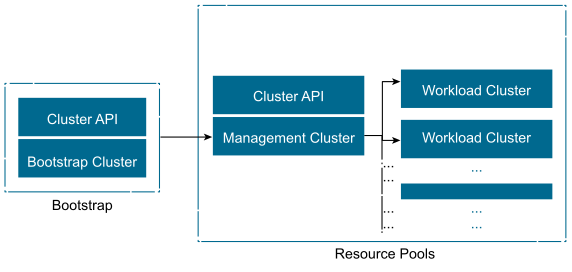
Tanzu Kubernetes Management Cluster is a Kubernetes cluster that functions as the primary management and operational center for the Tanzu Standard for Telco instance. In this management cluster, the Cluster API runs to create Tanzu Kubernetes clusters, and you configure the shared and in-cluster services that the clusters use.
When deployed through Telco Cloud Automation, VMware VMconfig Operator is installed into every management cluster to handle the VM level configuration for items such as additional network interfaces, SRIOV, Latency Sensitivity, and so on.
Tanzu Kubernetes Workload Cluster is a Kubernetes cluster that is deployed from the Tanzu Kubernetes management cluster. Tanzu Kubernetes clusters can run different versions of Kubernetes, depending on the CNF workload requirements. Tanzu Kubernetes clusters support multiple types of CNIs for Pod-to-Pod networking, with Antrea as the default CNI and the vSphere CSI provider for storage by default. When deployed through Telco Cloud Automation, VMware NodeConfig Operator is bundled into every workload cluster to handle the node Operating System (OS) configuration, performance tuning, and OS upgrades required for various types of Telco CNF workloads.
Tanzu Kubernetes Cluster Architecture
The following diagram shows different hosts and components of the Tanzu Kubernetes cluster architecture:
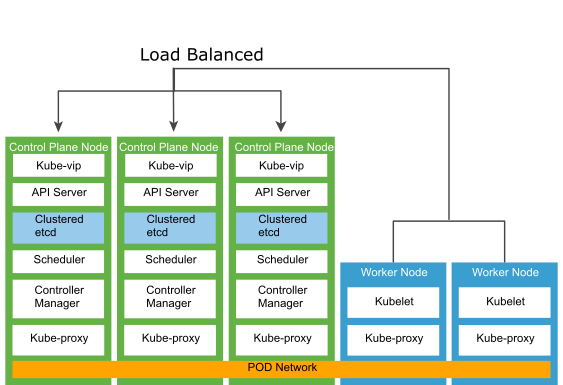
Tanzu Kubernetes Cluster Control Plane
The Kubernetes control plane runs as pods on the Kubernetes Control node.
Etcd is a distributed key-value store that stores the Kubernetes cluster configuration, data, API objects, and service discovery details. For security reasons, etcd must be accessible only from the Kubernetes API server. Etcd runs as a service as part of the control node. For deployment environments with large churn, consider using dedicated standalone VM worker nodes on hosts with SSD-based datastores.
Kubernetes API server is the central management entity that receives all API requests for managing Kubernetes objects and resources. The API server serves as the frontend to the cluster and is the only cluster component that communicates with the etcd key-value store. For added redundancy and availability, a load balancer is required for the control plane nodes. The load balancer performs health checks of the API server to ensure that external clients such as kubectl connect to a healthy API server even during the cluster degradation.
Kubernetes controller manager is a daemon that embeds the core control loops shipped with Kubernetes. A control loop is a non-terminating loop that regulates the state of the system. The controllers that are shipped with Kubernetes are the replication controller, endpoints controller, namespace controller, and service accounts controller.
Kube-VIP is used to handle incoming API requests for the Kubernetes API server and is a replacement for HAproxy used in the 1.1.x version of the Tanzu Standard for Telco deployment. Kube-VIP runs as a static Pod on the control plane nodes and uses the leader election functionality to elect a member as the leader. The elected leader owns the VIP address and is responsible for passing API requests to Kubernetes API services.
VMware Telco Cloud Platform also bundles the VM and NodeConfig Operators as custom controllers for Telco workload node customization.
Kubernetes schedulers know the total resources available in a Kubernetes cluster and the workload allocated on each worker node in the cluster. The API server invokes the scheduler every time there is a need to modify a Kubernetes pod. Based on the operational service requirements, the scheduler assigns the workload to a node that best fits the resource requirements.
Tanzu Kubernetes Cluster Data Plane
Tanzu Kubernetes Cluster Data Plane consists of worker nodes that run as VMs. A worker node consists of the container runtime, kube-proxy, and kubelet daemon to function as a member of the Kubernetes cluster.
Telco Cloud Platform requires that all worker nodes are running a Linux distribution with Kernel version that is compatible with tooling required to bootstrap, manage, and operate the Kubernetes cluster. Depending on the type of Telco workloads, the worker nodes might require specialized hardware and software to support advanced network capabilities. DPDK, SR-IOV, and multiple network interfaces are often requirements on the data plane.
In alignment with the Cloud Infrastructure Telco Task Force (CNTT), the following hardware and compute profile modes are illustrated in this solution architecture:
Control Profile |
Network Intensive Profile |
|
|---|---|---|
vCPU Over-Subscription |
Yes |
No |
CPU Pinning |
No |
Yes |
Huge Pages |
No |
Yes |
IOMMU |
No |
Yes |
NUMA |
No |
Yes |
SR-IOV |
No |
Yes |
DPDK |
No |
Yes |
In Non-Uniform Memory Access (NUMA), the memory domain local to the CPU is accessed faster than the memory associated with a remote CPU. High packet throughput can be sustained for data transfer across vNICs in the same NUMA domain than in different NUMA domains. 5G UPF delivers maximum data throughput when the processor, memory, and NICs are vertically aligned and remain within a single NUMA boundary.
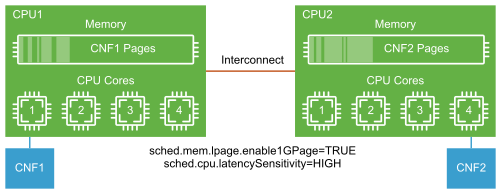
In addition to the vertical NUMA node alignment to provide low-latency local memory access, it is also critical to minimize the CPU context switching and process the scheduling delay.
Under normal circumstances, the kernel scheduler treats all CPU cycles as available for scheduling and pre-empts the executing processes to allocate the CPU time to other applications. Pre-empting one workload and allocating its CPU time to another workload is known as context switching. Context switching is necessary for CPU sharing during an idle workload. However, it can lead to performance degradation during the peak data throughput.
Data plane intensive workloads implemented as CNFs can see optimal packet delivery rate at the lowest packet loss when their CPU resources are pinned and affinitized. Use VMware best practices for data plane intensive workloads for this case. For non-data plane intensive workloads, benefitting from CPU over-subscription requires no such CPU pinning and affinitizing design.
Huge Pages
Translation Lookaside Buffer (TLB) is a small hardware cache used to map virtual pages to physical hardware memory pages. If the virtual address is found in the TLB, the mapping can be determined quickly. Otherwise, a TLB miss occurs and the system moves to a slow software-based translation.
5G CNFs such as the UPFs are sensitive to memory access latency and require a large amount of memory, so the TLB miss must be reduced. To reduce the TLB miss, huge pages are used on the compute nodes that host memory-sensitive workloads. In the VMware stack, ensure that the VM's memory reservation is configured to the maximum value so that all the vRAMs can be pre-allocated when VMs are powered-on.
DPDK Drivers and Libraries
The Data Plane Development Kit (DPDK) consists of libraries to accelerate packet processing. One of the main modules in DPDK is user-space drivers for high-speed NICs. In coordination with other acceleration technologies such as batching, polling, and huge pages, DPDK provides extremely fast packet I/O with a minimum number of CPU cycles.
Two widely used models for deploying container networking with DPDK are pass-through mode and vSwitch mode. The passthrough mode is leveraged in the Telco Cloud Platform architecture.
Pass-through mode: The device pass-through model uses DPDK as the VF driver to perform packet I/O for container instances. The passthrough model is simple to operate but it consumes one vNIC per container interface.
Figure 5. DPDK Passthrough 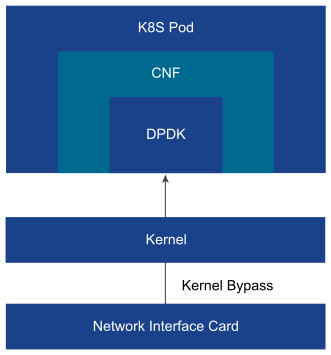
vSwitch mode: In the vSwitch model, a soft switch such as OVS sends packets. Each container instance uses a DPDK virtual device and a virtio-user to communicate with the soft switch. The vSwitch model offers high density but requires advanced QoS within the vSwitch to ensure fairness. The additional layer of encapsulation and decapsulation required by the vSwitch introduces additional switching overhead and impacts the overall CNF throughput.
Figure 6. DPDK vSwitch 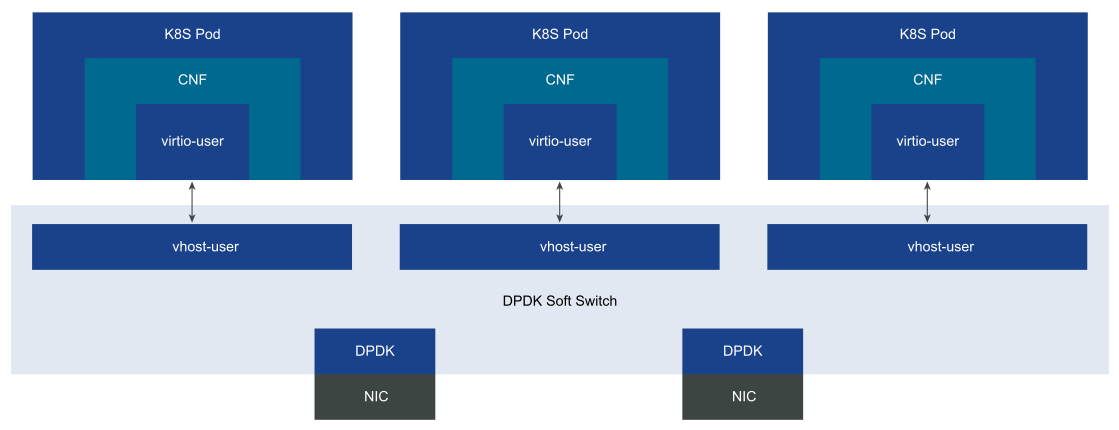
IO Memory Management Units (IOMMUs) protect system memory between I/O devices, by mediating access to physical memory from CNF network interfaces. Without an IOMMU, devices can access any portion of the system memory and can corrupt the system memory. Memory protection is important in the container and virtual environments that use shared physical memory. In the VMware stack, depending on the type of DPDK driver, the hardware-assisted I/O MMU virtualization might be required on the VM setting.
Any DPDK kernel modules to be used (igb_uio, kni, and so on) must be compiled with the same kernel as the one running on the target.
When deploying Tanzu Kubernetes Grid through Telco Cloud Automation, the infrastructure requirements (infra_requirements) configuration in the CSAR ensures the installation of correct packages and the correct OS-level configuration of elements such as huge pages.
Cloud Native Networking Overview
In Kubernetes Networking, every Pod has a unique IP and all the containers in that Pod share the IP. The IP of a Pod is routable from all the other Pods, regardless of the nodes they are on. Kubernetes is agnostic to reachability, L2, L3, overlay networks, and so on, if the traffic can reach the desired pod on any node.
CNI is a container networking specification adopted by Kubernetes to support pod-to-pod networking. The specification defines a Linux network namespace. The container runtime first allocates a network namespace to the container and then passes numerous CNI parameters to the network driver. The network driver then attaches the container to a network and reports the assigned IP address to the container runtime. Multiple plugins may run at a time with the container joining networks driven by different plugins.
Telco workloads typically require a separation of the control plane and data plane. Also, a strict separation between the Telco traffic and the Kubernetes control plane requires multiple network interfaces to provide service isolation or routing. To support those workloads that require multiple interfaces in a Pod, additional plugins are required. A CNI meta plugin or CNI multiplexer that attaches multiple interfaces can be used to provide multiple Pod NICs support. The CNI plugin that serves pod-to-pod networking is called the primary or default CNI (a network interface that every Pod is created with). In case of 5G, the SBI interfaces are managed by the primary CNI. Each network attachment created by the meta plugin is called the secondary CNI. SR-IOVs or VDS (Enhanced Data Path) NICs configured for passthrough are managed by supported secondary CNIs.
While there are numerous container networking technologies and unique ways of approaching them, Telco Cloud and Kubernetes admins want to eliminate manual CNI provisioning in containerized environments and reduce the number of container plugins to maintain. Calico or Antrea is often used as the primary CNI plugin. MACVLAN and Host-device can be used as secondary CNI together with a CNI meta plugin such as Multus. The following table summarizes the CNI requirements based on the workload type:
5G control Profile |
5G Data Plane Node |
|
|---|---|---|
Primary CNI (Calico/Antrea) |
Required |
Required |
Secondary CNI (Multus/MACVLAN/Host-device) |
Generally, not required. Can be leveraged to simplify CNF connectivity. |
Required |
