









Aria Operations communicates with all management components to collect metrics that are presented through various dashboards and views. Aria Operations can collect metrics from various VMware and non-VMware products, including vSphere, vSAN, NSX, and Kubernetes clusters.
Aria Operations - Logical Design
Aria Operations is a single instance of a multi-node analytics cluster that is deployed in the management cluster. A primary node and primary replica node are created for an Aria Operations HA deployment. More analytic nodes can be added to scale the deployment.
In addition to analytic nodes, cloud proxies (formerly called remote collectors) can be deployed. These cloud proxies allow the distributed deployment of Aria Operations.
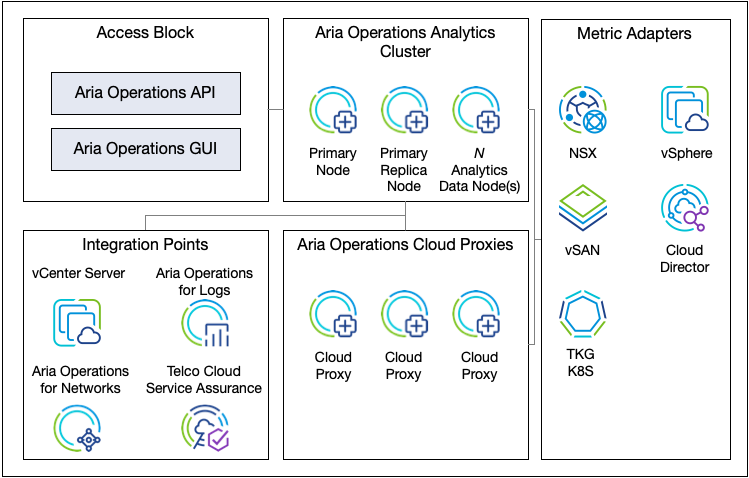
The analytics cluster of the Aria Operations deployment contains the nodes that analyze and store data from the monitored components. The deployment configuration (number and sizing of nodes) for the analytics cluster must be sized to meet the requirements for monitoring based on the number of VMs, objects, and metrics.
Aria Operations integrates with other platforms in the Monitoring / Observability framework of the Telco Cloud to exchange data with platforms. One example is the in-place capabilities of Aria Operations for Logs that allows syslog messages pertaining to a specific event to be viewed seamlessly from Aria Operations.
Aria for operations is a highly scalable platform. The analytics cluster must be sized based on the size of the environment. For more information about dimensioning guidelines for Aria Operations, see Aria Operations Sizing Guidelines.
This design uses medium-size nodes for the analytics cluster and standard-size nodes for the cloud proxies. To collect the required number of metrics, add a virtual disk of 1 TB (or as required) on each analytics cluster node.
The latency requirements between analytics nodes is 5ms. All analytics nodes must be deployed on the same segment and within a single datacenter. In addition, wherever possible, the deployment of Aria Operations nodes must be sized to fit into a single NUMA to provide better performance.
In addition to the Highly Available (HA) mode, Aria Operations also supports a Continuous Availability mode. This mode requires additional functionality such as Fault-Domains in the management domain. The continuous availability mode is not covered in this reference architecture guide.
You can use the self-monitoring capability of Aria Operations to receive alerts about operational issues. Aria Operations displays the following administrative alerts:
System alert: Indicates a failed component of the Aria Operations application.
Environment alert: Indicates that Aria Operations stopped receiving data from one or more resources. This alert might indicate a problem with system resources or network infrastructure.
Log Insight log event: Indicates that the infrastructure on which Aria Operations is running has low-level issues. You can also use the log events for root cause analysis.
Custom dashboard: Aria Operations shows dashboard for data center monitoring, capacity trends, and single pane of glass overview.
When Aria operations is deployed in a highly available design, it requires an external load balancer to provide a single point of entry for users and applications leveraging the Aria operations API.
To leverage the NSX Advanced Load Balancer (AVI), an instantiation of the controllers and service engines needs to be deployed in the Management cluster. This allows for load-balancing to the analytics cluster running in the main management cluster.
When creating the load balancer, ensure that the certificate covers all nodes (analytics nodes, cloud proxies, and load balancer) of the entire Aria Operations deployment.
Aria Operations - Distributed Design
Aria Operations supports the deployment of Cloud Proxies. Cloud proxies are additional nodes that distribute the ingestion of metrics from the adapters into the analytics cluster. The connection from the cloud proxy node to the analytics cluster is a one-way connection.
The deployment of the cloud proxies in pairs allows the formation of collector groups. The collection of a specific instance of an Aria Operations adapter can be assigned to a collector group, this allows for highly available collection of metrics even in the case of a service impact to one of the cloud proxies.
In the multi-site design, the cloud proxies must be deployed in the multi-site management domain. This enables a distributed collection of metrics across the Telco Cloud with a centralized management view.
A single cloud-proxy or collector group collects metrics from different adapters. Cloud proxies can be deployed in a standard or large form factor, depending on the number of metrics and objects the cloud proxy needs to collect.
There is a latency requirement for less than 200ms between the cloud-proxies and the Analytics nodes
Aria Operations - Scaling
Aria Operations can be scaled to support up to 16 Large Analytic nodes (or 12 Extra-Large nodes). Each node can be deployed in a Small, Medium, Large, or Extra-Large size. The CPU, Memory, and Disk requirements increase depending on the overall size of the Analytics node.
Aria Operations supports scaling up the nodes from medium to large and scaling out the number of supported nodes from 2 to 3 or more. Ensure that all the nodes are scaled up before scaling out.
Storage can also be added independently of scale-out or scale-up operations. When storage is added, ensure that the same additional storage amount is added to each node in the cluster.
The maximum number of metrics that can be supported depends on the node size. A Large node collects up to approximately 20,000 objects and 4 million metrics. A large cloud proxy collects up to 32,000 objects and 6.5 million metrics
Aria Operations - Management Packs
Aria Operations adapters and management packs come in two specific configurations:
Normal adapters require a one-way communication to the monitored resources
Hybrid adapters require two-way communication to the monitored resources
The Telco Cloud deployment for Aria Operations focuses on Normal adapters. The main adapters are vSphere, NSX, Cloud Director, Aria Operations for Logs and Kubernetes management packs.
Depending on the overall environment and the deployment of the Telco Cloud, the following adapters must be deployed:
vSphere collects metrics from vCenter and ESXi hosts.
vSAN collects metrics from vSAN datastores deployed throughout the telco cloud.
NSX collects metrics from the NSX Manager and edge nodes.
Aria Operations for logs collects and integrates Aria Operations with Aria Operations for logs.
If a storage other than vSAN is used, use the Management Pack for Storage devices to collect storage specific metrics.
Each adapter or management pack supports multiple instantiations. There is a single vSphere management pack, although each vCenter endpoint has its own instantiation. When creating each instantiation, the collection of the relevant metrics must be assigned to the correct cloud-proxy or collector group.
Aria Operations - K8s & Prometheus Integration
Aria operations can collect metrics from K8s deployments such as those provided by Tanzu Kubernetes Grid.
Prometheus is commonly used to provide access to metrics from a K8s cluster. However, metrics collected by Prometheus are typically presented in the form of a counter. Counter metrics are presented by a value that always increases.
To ensure that these metrics are interpreted properly by Aria Operations, the metrics must be rated over a period of time and presented to Aria Operations through a specific Prometheus configuration or through Aria Operations configurations.
When using VMware Telco Cloud Automation to deploy the Prometheus add-on to the Tanzu Kubernetes Grid cluster, a reference configuration can be used. The reference configuration includes modified recording rules that instruct prometheus to create additional metrics for consumption by Aria Operations. In addition, by using a custom kubernetes mapping within Aria Operations, these metrics can be assigned to the correct placement in the metric tree for easy viewing.
Aria Operations Design Recommendations
Attribute |
Specification |
|---|---|
Appliance Size |
Medium |
Number of vCPUs |
8 |
Memory |
32GB |
Disk Space |
As required based on dimensioning |
Design Recommendation |
Design Justification |
Design Implication |
|---|---|---|
Deploy Aria Operations as a cluster of three nodes:
|
|
All the nodes must be sized identically. |
Deploy two remote cloud proxies for the management domain |
Reduces the load on the analytics cluster from collecting application metrics and provides availability for metric collection |
Requires additional resources to create the cloud proxies |
Deploy two cloud proxies for each management domain if using the multi-site model. |
Places the collector closer to the source of the metrics |
Requires additional resources to create the cloud proxies |
Create collector groups for each management domain |
Allows the adapter instances to be assigned to collector groups for higher availability |
Requires additional configuration. |
Deploy each node in the analytics cluster as a medium-size appliance. |
Provides the scale required to monitor the Telco Cloud |
ESXi hosts in the management cluster must have physical CPUs with a minimum of 8 cores per socket. Aria Operations uses a total of 24 vCPUs and 96 GB of memory in the management cluster. |
Scale up all the existing analytics nodes (if required) before scaling out. |
Ensures that the analytics cluster has enough capacity to meet the VM object and metric growth. |
The capacity of the physical ESXi hosts must be sufficient to accommodate VMs that require the additional requirements without bridging NUMA node boundaries. |
Use anti-affinity rules to ensure that the Analytics nodes (and cloud-proxies) are scheduled on different hosts. |
Ensures high availability, a single node does not impact the overall Aria Operations platform |
Requires enough hosts to be able to distribute the Aria Operations nodes. Host failure scenarios must be considered. |
Deploy the standard-size cloud-proxies. Always deploy in pairs to allow for the creation of a collector group. If remote locations are planned to be large, use Large cloud proxies. |
Creates a distributed and highly available environment for metric collection |
You must provide 4 vCPUs and 8 GB of memory in the management cluster. |
Add a virtual disk of 1 TB for each analytics cluster node. |
Provides enough storage for the expected number of objects. |
You must add the 1 TB disk manually while the VM for the analytics node is powered OFF. |
Configure Aria Operations for SMTP outbound alerts. |
Enables administrators and operators to receive email alerts from Aria Operations. |
Aria Operations must have access to an external SMTP server. |
Ensure that the management cluster is not heavily oversubscribed. |
Oversubscribed management domains can impact the optimal performance of Aria Operations. |
Requires active monitoring of CPU Ready, Co-Stop, and other metrics to ensure that Aria operations is not throttled. |
Integrate Aria Operations with Active Directory users and groups. |
Provides fine-grained role and privilege based access for varying user roles across the organization. |
Requires access to Active Directory |
Create service accounts for use with third-party integration. Align permissions with customer security policies. |
|
Custom configuration on Aria Operations or the integration points might be required. |
Replace all the default certificates with CA signed certificates. |
Ensures that all communication is properly encrypted and proper certificate management processes are followed. |
A single certificate is required for all the nodes including the load balancer. As the Aria Operations deployment scales-out, a new certificate is required to accommodate the new node. |
Deploy and configure connectivity through the following management packs or integration:
|
Ensures that metrics are collected from all endpoints of the Telco Cloud. |
Requires the configuration and allocation to collector groups or cloud proxies for all integration points. |
Configure Aria Operations to send logs to Aria Operations for Logs. |
Enables logging events to be monitored by Aria Operations for Logs. |
None |
If monitoring Tanzu Kubernetes Grid clusters, ensure the deployment of Prometheus through Telco Cloud Automation |
Allows reference configuration to be applied to ensure proper metrics collection |
Requires deployment of add-ons through VMware Telco Cloud Automation Requires the deployment of v2 Clusters |
To protect Prometheus metrics, use Avi to access the Prometheus server through TLS and AD integration. |
Prevents metrics being presented over insecure HTTP endpoints. Allows NSX Advanced Load Balancer to be configured to leverage AD integration for authentication, if required. |
Requires the NSX Advanced Load Balancer operator to be deployed into the cluster Requires service edges to be deployed in proximity to the K8s clusters |
Aria Operations must be configured to use minimum number of nodes. Use fewer, but larger nodes before scaling out and adding more analytic nodes. When adding resources to the Analytics nodes, ensure that you follow the considerations around resources and NUMA.
