









Tanzu Kubernetes clusters are deployed in the compute workload domains. The cluster design varies for each function such as Core, RAN, and so on.
The Telco Cloud Platform consumes resources from various compute workload domains. Resource pools within vSphere provide guaranteed resource availability to workloads. Resource pools are elastic; more resources can be added as the resource pool capacity grows.
The target endpoint for a Tanzu Kubernetes Grid is a vSphere resource pool. A resource pool is an abstraction of the resources available to a cluster. By default, each cluster has a root resource pool. Additional resource pools can be created as required.
A resource pool can map to a single vSphere cluster or stretch across multiple vSphere clusters. The stretch feature is not available without the use of a VIM such as VMware Cloud Director. Thus, in the context of Tanzu Kubernetes Grid cluster design, a resource pool is bound to a single cluster, or in the case of RAN cell sites, a single host.
RAN Cell sites can consist of multiple hosts when high availability is a consideration. Most Cell Sites are single nodes, and redundancy is provided through the Radio network.
In the context of Tanzu Kubernetes Grid, each Kubernetes cluster is mapped to a Resource Pool. A resource pool can be dedicated to a Kubernetes cluster or shared across multiple clusters.
Resource pools allocate committed levels of resources to the worker nodes in a K8s environment. Creating multiple resource pools guarantees a specific level of response for a data-plane workload, while offering a reduced level for non-dataplane workloads.
In user plane workloads, the allocation of memory/CPU reservations and limits to a resource pool is separate from the Latency Sensitivity requirements. The reservation of the resource pool must be large enough to accommodate the sum of reservations required by the Tanzu Kubernetes Grid worker nodes.
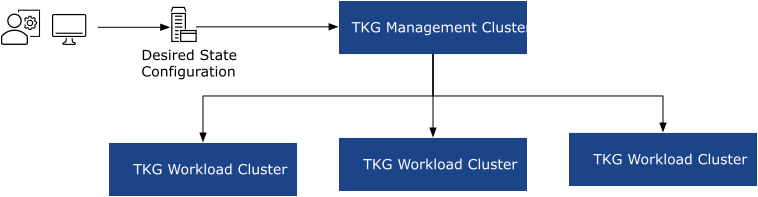
Tanzu Kubernetes Grid uses two types of clusters:
Management cluster: The management cluster is a Kubernetes cluster that is used to manage and operationalize the deployment and configuration of subsequent workload clusters. Cluster-API for vSphere (CAPV) runs in the management cluster. The management cluster is used to bootstrap the creation of new clusters and configure the shared and in-cluster services such as NFS client mounts within the workload domains.
Workload cluster: The workload cluster is where the actual containerized network functions and PaaS components are deployed. Workload clusters can also be divided into multiple Node pools for more granular management.
Cluster & CNF Mapping Design
When creating Tanzu Kubernetes Clusters, note that considerations for Kubernetes in a virtualized environment differ from Kubernetes in a bare-metal environment.
In bare-metal environments, the unit of scale is a bare-metal server and the placement of many pods or workloads on each server becomes important. However, in a virtualized environment, the unit of scale is at the individual VM level, which can lead to a more efficient design of Kubernetes clusters.
Within Telco Cloud Automation, the worker nodes in an individual Tanzu Kubernetes Grid cluster can be grouped into logical units called node pools.
Tanzu Kubernetes Grid - Node Pools
A node pool is a set of worker nodes that have a common configuration set (vCPUs, Memory, Networks, K8s Node Labels) and are thus grouped as a pool.
In the Telco Cloud Automation CaaS deployment, multiple worker node pools can be created in a Kubernetes cluster. Each node pool can have its own unique configuration, along with a replica count.
From a deployment perspective, each node pool must belong to a vSphere cluster or unique host. If required, each node pool in a single Kubernetes cluster can be deployed to different vSphere clusters or hosts for redundancy or load-sharing. In addition, multiple independent Kubernetes clusters can share the same vSphere clusters (resource allocation permitting).
Based on the node pool concept, a Kubernetes cluster deployed to the Telco Cloud can have multiple node pools. Each node pool within a single vCenter can be deployed to a different cluster or even to an individual ESXi host. However, workers within a single node pool cannot be distributed across multiple vSphere clusters or hosts.
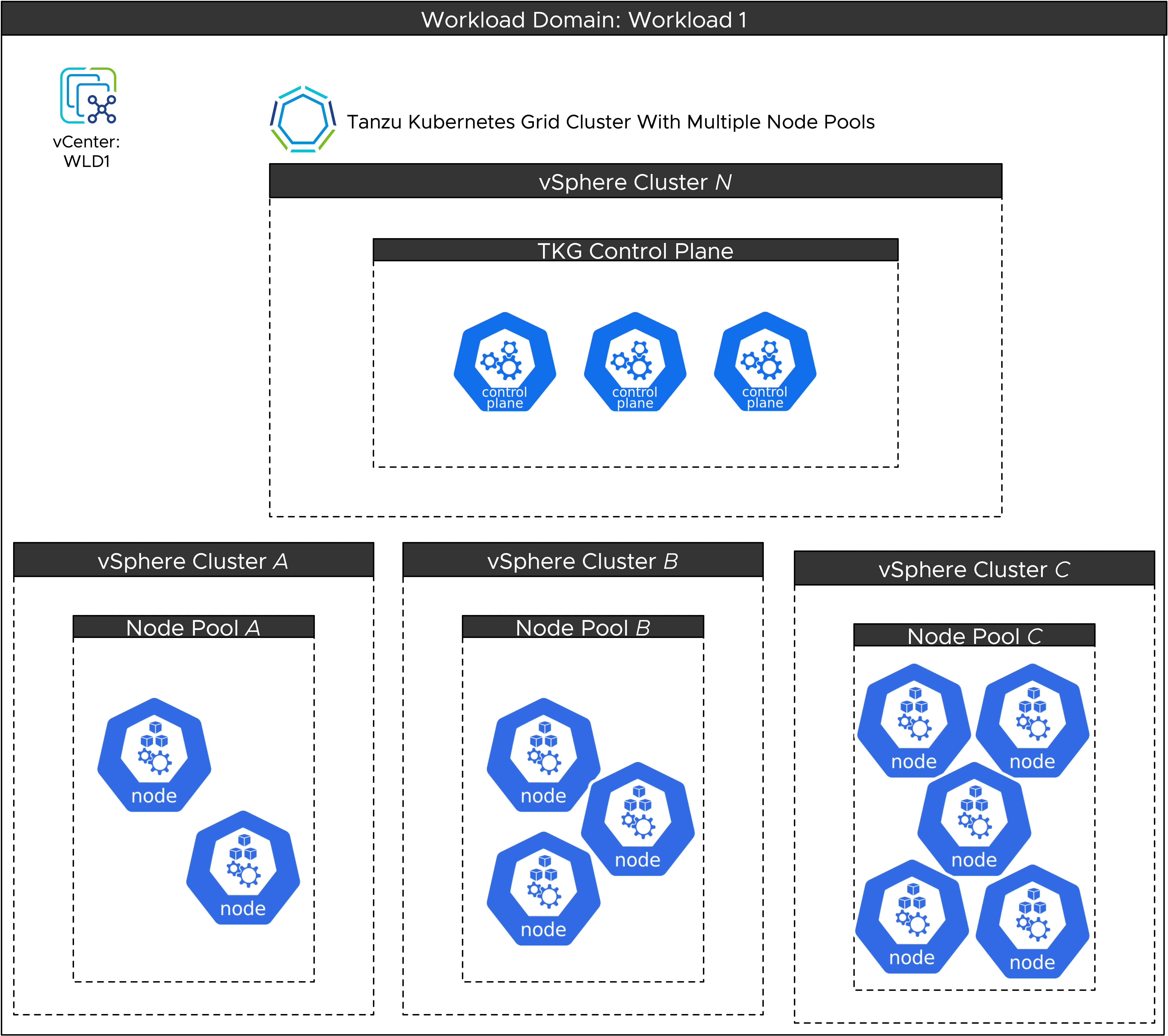
If you create a Tanzu Kubernetes cluster where node pools are deployed to different target endpoints (within a single vCenter), it is called a Stretched Cluster. In this scenario, multiple vSphere endpoints are used as target endpoints for different node pools within a single cluster.
When using stretched cluster designs, storage zoning is required if the datastores on each vSphere cluster are unique (as with a vSAN design). This ensures that node pools within a resource pool on a vSphere Cluster or standalone host can consume the appropriate storage for any persistent volume claims the cluster might need.
The Tanzu Kubernetes Management cluster is typically deployed within the same vCenter as the workload clusters. However, it is not mandatory. The management and workload clusters can also be on different vCenter Servers but it requires multiple TCA-CP nodes, one for the management cluster and another for the workload clusters.
Each worker node in Kubernetes can be assigned a set of node labels. The Kubernetes scheduling engine uses these free-form labels to determine the proper placement of Pods, distribute traffic between services, and so on.
The labels are simple key/value pairs. For example,
vendor: vendor environment: production function: function_name
Encoding a naming convention into node labels is not necessary. RegExp is not supported for node selectors.
These labels are leveraged by the Network Function to ensure that pods are scheduled to the correct worker nodes. A node can have multiple labels. If the node selector matches only one of these labels, it can be considered a viable target for scheduling.
Different node pools can have different labels associated. However, the same label set (all Key/Value pairs) cannot be applied to multiple node pools.
Tanzu Kubernetes Grid - Single Node Clusters
Single Node Clusters (SNC) are supported from Telco Cloud Platform 5G Edition 3.1 onwards. These clusters require additional design consideration for Kubernetes cluster deployments.
Unlike traditional clusters that have their own control-plane nodes and multiple worker nodes or node pools, a Single Node Cluster is a workload cluster where the network function runs along with the control plane functions within a single Tanzu Kubernetes node.
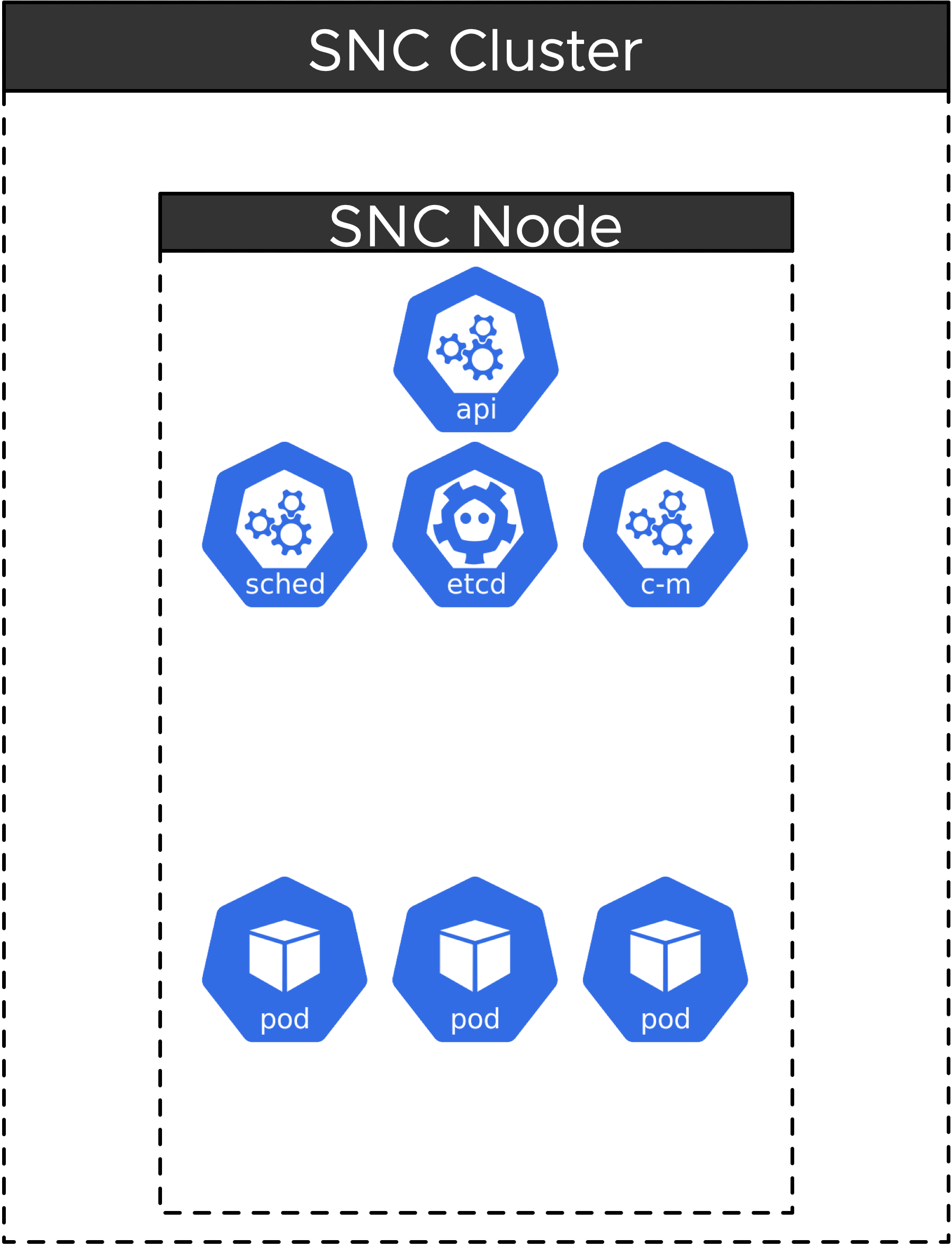
The primary use case for Single Node Clusters is in the RAN, Far-Edge, and Near-Edge deployments, where
resource constraints exist
applications leverage functionality such as SR-IOV or PCI-PT
there is no requirement to provide vSphere-based HA services to the VMs
Single Node Clusters and regular clusters can share the same Tanzu Kubernetes Management cluster.
Tanzu Kubernetes Cluster Design Options
When you design a Tanzu Kubernetes cluster for workloads with high availability, consider the following:
Number of failed nodes to be tolerated
Additional capacity for cluster growth
Number of nodes available after a failure
Remaining capacity to reschedule pods of the failed node
Remaining Pod density after rescheduling
Individual Worker node sizing
Life-cycle management considerations (both CaaS and CNF)
Dynamic Infrastructure Provisioning requirements
Platform Awareness features (such as NUMA)
By leveraging the Nodepools concept, Kubernetes clusters can be designed and built in various ways. Some of the common design options include:
A single Kubernetes cluster that hosts multiple CNFs from multiple vendors
The single cluster design resembles metal-based deployments, where the VMs consume large amounts of CPU and memory resources. This model has less overhead than other models but brings complexity in terms of scale and lifecycle management.
In this model, a Network Function upgrade requires the K8s upgrade and the entire cluster upgrade, leading to application interoperability issues.
Different network functions require different network connectivity and different configurations, so providing unique infrastructure requirements to each network function becomes complicated and challenging to manage in a single cluster environment.
A Kubernetes cluster per Vendor that hosts all the relevant CNFs from a given vendor
The per Vendor model solves some of the single cluster challenges. In this model, network functions can be managed across different node pools, and each network function can have different infrastructure requirements.
This model faces LCM concerns, especially if newer functions require different versions of Kubernetes.
A Kubernetes cluster per CNF
This model provides the maximum flexibility. In this model, a Tanzu Kubernetes Grid cluster is created for each Network Function, which simplifies the challenges of providing unique infrastructure requirements per network function. This model also removes the common challenge of lifecycle management and provides the most efficient scaling mechanism.
Tanzu Kubernetes Cluster IP Addressing - DHCP
Tanzu Kubernetes Grid leverages kube-vip to provide a highly available IP address for ingress requests to the Kubernetes API. The kube-VIP address is statically assigned but needs to come from the same subnet as the DHCP scope for the control-plane and worker nodes.
When using Tanzu Kubernetes Grid outside of VMware Telco Cloud Automation the NSX Advanced Load Balancer can be used to provide the kube-vip address. However, this feature is not currently implemented in VMware Telco Cloud Automation
When allocating IP address space for Tanzu Kubernetes Grid, note the following considerations:
DHCP address space configuration for all control-plane and worker nodes
A statically assigned address for the kube-vip address
Space for scale-out and upgrade of worker nodes.
Ensure that the DHCP addresses allocated to the control-plane nodes are converted to static reservations to avoid any potential changes to the control-node IP addresses.
Tanzu Kubernetes Cluster IP Addressing - NodeIPAM
Starting from VMware Telco Cloud Platform 5G Edition 3.1 (VMware Tanzu Kubernetes Grid 2.3), the NodeIPAM feature is supported on clusters running Kubernetes 1.26.
The NodeIPAM feature for Tanzu Kubernetes Grid provides an in-cluster IP Address Management function. IP Pools are created in the Tanzu Kubernetes Management cluster using VMware Telco Cloud Automation. These node pools are used to allocate IP addresses to cluster nodes without the need for external DHCP servers.
When configuring the IP Pools, you need to specify the gateway, a range of IP addresses, the prefix, and DNS servers.
Node IPAM supports either IPv4 or IPv6. Dual-stack addressing through Node IPAM is not supported.
NodeIPAM allocates addresses only for the primary interface and it does not allocate an IP address for the Kube-VIP IP process.
When deploying a Single Node Cluster, the Kube-VIP process requires an IP address in addition to a NodeIPAM address.
Tanzu Kubernetes Grid VM Dimensioning Considerations
A node pool is a set of worker nodes that have a common configuration set (vCPUs, Memory, Networks, Labels) and are thus grouped as a pool. The node pool concept simplifies the CNF placement when the CNF has many different components.
When sizing a worker node, consider the number of Pods per node. Most of the kubelet utilization is contributed by ensuring that Kubernetes pods are running and by constant reporting of pod status to the Control node. High pod counts lead to high kubelet utilization. Kubernetes official documentation recommends limiting Pods per node to less than 100.
Other workloads require dedicated CPU, memory, and vNICs to ensure throughput, latency, or jitter. When considering the number of pods per node for high-performance pods, use the hardware resource limits as the design criteria. For example, if a data plane intensive workload requires a dedicated passthrough vNIC, the total number of Pods per worker node is limited by the total number of available vNICs.
To align with metal provisioning of Kubernetes and other models, TKG worker nodes are sized as large VMs, often consuming half of or even an entire socket. While this design is viable, you can leverage some considerations to create a more optimized infrastructure when dealing with VM-based Kubernetes platforms such as those deployed using Telco Cloud Automation.
Considerations for a sample NF:
CNF Component |
# VCPUs |
# RAM |
# Replicas |
|
|---|---|---|---|---|
Sample NF |
FE |
8 |
32 |
2 |
SIP |
8 |
32 |
2 |
|
BE |
8 |
32 |
2 |
|
RCS |
8 |
32 |
2 |
|
SMx |
4 |
16 |
3 |
|
DB |
8 |
32 |
3 |
|
PE |
8 |
32 |
1 |
This sample NF is only for illustrative purposes and is not intended for any vendor-specific NF.
The worker node sizing for this NF requires 52 vCPU and 208 GB of RAM, which can create complications from placement/scheduling if NUMA Alignment or Latency Sensitivity are required. This model of creating a single worker node also complicates issues if there are components that require specific infrastructure requirements that other components do not.
When large worker nodes are created, the unit of scale is the size of the worker node template. Thus, if the SMx scale increased from 3 Replicas to 4, a new worker node of 52 CPUs is required (assuming the SMx component uses Pod anti-affinity rules).
An alternate and more flexible approach is to have multiple, smaller worker nodes (distributed across multiple node pools), deployed across a Tanzu Kubernetes stretched cluster.
With this architecture, specific co-dependent functions that frequently communicate can be collapsed into smaller worker nodes. For example, FE and SIP are combined into a single node pool, BE and RCS are combined into another node pool, and so on.
The distribution of those components that are co-dependent needs to be determined by the CNF Vendor. Elements such as pod-pod communication may no longer reside within a single node and therefore may incur network latencies, as traffic is sent from hypervisor hosts to different VMs within the environment.
This method has the advantage of keeping the worker nodes smaller in size and thus simpler and easier to scale. It also allows for different configurations at the node-pool level. For example, one component requires 1 GB huge pages and multiple interfaces/SRIOV.
With no standard design rules for building these clusters, all involved parties must discuss and determine the optimal design. The node selector configuration must be modified in the HELM chart to support the targeted placement of pods.
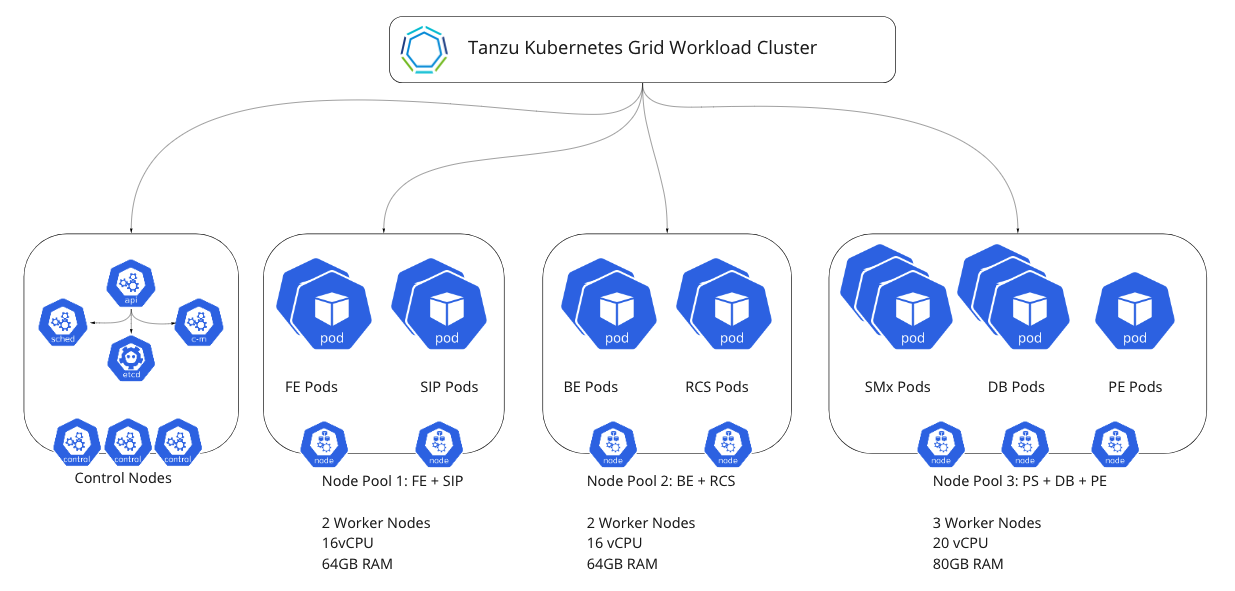
This alternate cluster model creates multiple node pools within a single cluster. The target deployment point for the Network Function is still a single cluster but can be scheduled to the correct worker nodes based on the node pool labeling pods. This model is advantageous over a bare-metal type approach where a single node pool is created with large worker nodes because scale-out can now occur on a per node-pool level. This model makes scaling easier to manage and helps prevent resource waste by dividing worker nodes into smaller, more composable units.
Tanzu Kubernetes Grid Cluster Design Recommendations
Design Recommendation |
Design Justification |
Design Implication |
|---|---|---|
Map the Tanzu Kubernetes clusters to the vSphere Resource Pool in the compute workload domain. |
Enables Resource Guarantee and Resource Isolation |
During resource contention, workloads can be starved for resources and can experience performance degradation. Note: You must proactively perform monitoring and capacity management and add the capacity before the contention occurs. |
Create dedicated DHCP IP subnet pools for the Tanzu Kubernetes cluster management network. Allocate a Static IP for Kubernetes Endpoint API. |
Simplifies the IP address assignment to Kubernetes clusters. Use static reservations to reserve IP addresses in the DHCP pool for Kube-Vip address. |
DHCP servers must be monitored for availability. Address scopes do not overlap IP addresses that are being used. |
Ensure the DHCP pool has enough address space to manage upgrades and LCM events |
Ensure that new nodes can obtain an IP address |
Requires the scope to be larger than the actual cluster size. Short-term DHCP leases can be used to offset this; however, this is not recommended. |
Place the Kubernetes cluster management interface on a virtual network, which is routable to the management network for vSphere, Harbor, and Airgap mirror. |
Provides connectivity to the vSphere infrastructure. Simplifies the network design and reduces the network complexity. |
Increases the network address management overhead. Increased security configuration to allow traffic between the resource and management domains. |
Leverage a per-CNF model for cluster deployments |
Simplifies the lifecycle management and cluster sizing on a per workload basis |
Creates additional resource requirements for control-plane nodes. Can use a single cluster if all products are tightly coupled and from a single vendor. |
Separate control-plane and user-plane functions at both the TKG and vSphere levels |
Isolates different workload types Easier resource management and reduced contention |
Requires different vSphere clusters for different workload types. |
