









Data enrichment streams pull in data from external sources and enrich other metrics or events with that external data. All metrics, events, and external data object are assumed to be coming in on a Kafka topic.
Here is a simple diagram showing how events and external data interact.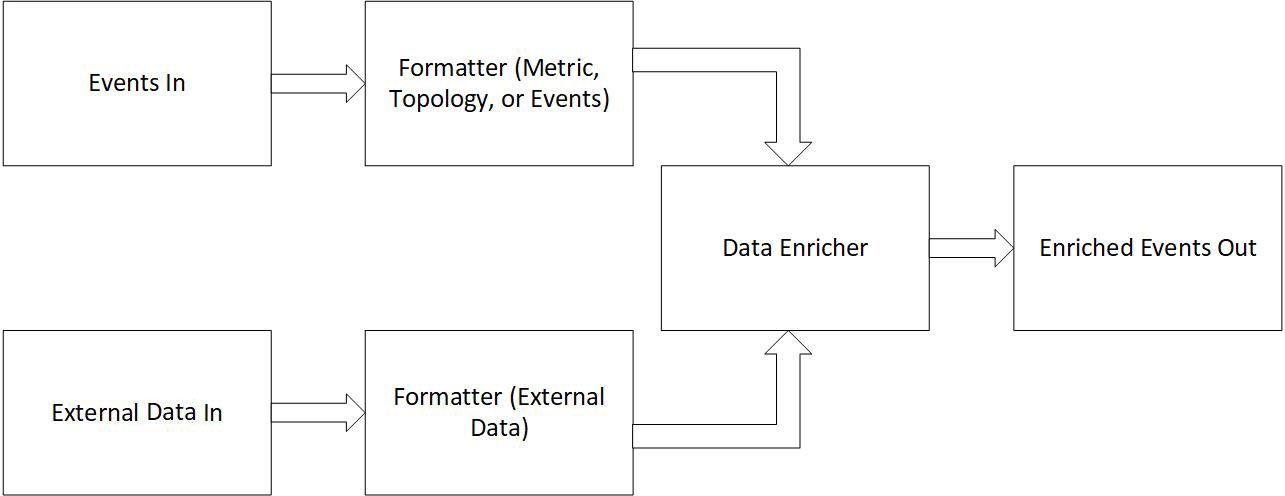
- External Data: Objects with a key and a data field. The key is a unique identifier string, while the data field is a key-value map with all the enrichment data.
- Events: The enrichment stream can handle Metric, Topology, or Event types.
The enricher has two modes of operation: Replicated and Partitioned. In replicated mode, the external data objects are replicated across the cluster so that a copy is present on each node. In partitioned mode, the external objects are spread out across the cluster and must be partitioned in the same way as the events so that they are enriched on the same node. Partitioned mode is scalable if the amount of external data is large.
Data Persistence
An Enrichment stream can be configured to persist the external data to disk so that it can be recovered in case of a restart. It uses Flink checkpoints to achieve this. On a checkpoint, the external data held in memory is written to disk on a kubernetes persistent volume. The checkpoint interval can be customized based on performance needs.
| data-type | How the data enricher stores data. In Replicated mode, the data is copied to every node in the cluster. In Partitioned mode, the data is spread out over the cluster. | Default: Replicated |
| event-key | The key for the event objects. This key is used to match the event with its corresponding data object. | "Instance" for Metrics. "InstanceName" for Events. "ID" for Topology |
| data-key | The key for the data objects. | Default: The "key" field. |
| event-map | The location of the map in the event object where the enrichment data is added. | Default: The "tags" field. |
| data-map | The location of the map in the data object where the enrichment data is read. | Default: The "data" field |
| event-partition-key | Only used in partitioned mode. Determines how the events are partitioned. Must match the data object's partition key to guarantee they are on the same node during enrichment. | Default: same as event-key |
| data-partition-key | Only used in partitioned mode. Determines how the data objects are partitioned. | Default: same as data-key |
Changing the Existing Stream
- Undeploy the default stream.
- Update the key as properites [dataSource].
- Save and deploy the enrichment stream.
- Add the enrichment input data to dataInput topic of the edge-kafka
- Create a collector (for example, Vipetela) corresponding to the dataSource given in the dataInput topic.
- Check the reports.
