









Describes the procedure to write a Xml based Stream custom collector.
Strean Custom Collector
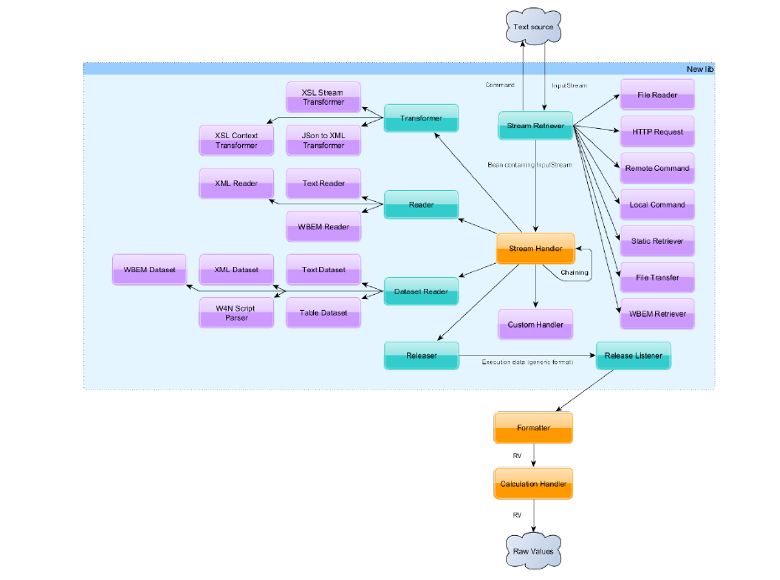
The Stream Collector is divided into multiple components interacting with each other in order to parse text source properly and generate Raw Values.
-
Stream Retriever: These components are used to retrieve the text sources.
-
Dataset Reader: These components divides the text sources into smaller text chunks, this helps to parse multiple small chunks in parallel.
-
Reader: These components parses the different text source and extract information out of them and enhance the context.
-
Transformer: These components modifies or standardize the different text sources in order to parse them.
-
Context: This component provides dynamic information required for the generation of Raw Values.
-
Releaser: This component triggers the generation of Raw Values out of the current context.
-
Release Listener: This component receives the generation requests from the Releaser, computes the Raw Values, and send them to the next component in the collecting chain of the Collector Manager.
Configuring Stream Collector
<collector-configuration>
<source>Source property value</source>
<collecting-group>Retention group</collecting-group>
<default-character-encoding>The expected character encoding in the streams ex:UTF-8</default-character-encoding>
<!-- CHOICE -->
<properties-refresh-periods>The period between a forced +r</properties-refresh-periods>
<!-- OR -->
<auto-detect-properties-refresh />
<collecting-threads-pool-size>The number of threads allowed for all the collecting chains</collecting-threads-pool-size>
<!-- One or more -->
<collecting-configurations name="Configuration name">
<!-- Zero or more -->
<include-contexts>Location to an execution contexts file</include-contexts>
<!-- Zero or more -->
<execution-contexts name="Context name">
<!-- One or more -->
<properties name="Property name">Property value</properties>
</execution-contexts>
<data-retrieval-file>File containing the data retrieval chain </data-retrieval-file>
<!-- One or more -->
<data-listeners id="The releasing ID to listen to"
variable-id="Optional properties for the Raw Value variable ID. Default is source device module part name"
variable-id-separator="Optional separator for the properties for the Raw Value variable ID. Default is nothing"
normalize-variable-id="Optional flag to normalize the properties for the Raw Value variable ID. Default is true">
<!-- Optional -->
<timestamp
context-key="execution context key where the value will be the timestamp"
format="optional format when the value isn't numeric" />
<!-- Zero or more -->
<values context-key="execution context key where the value will be"
type="computation type: counter (default), delta, rate or a contextualized value for runtime selection"
required="true (default) or false">
<name>Optional metric name property</name>
<unit>Optional metric unit property</unit>
<!-- Zero or more property extraction from the value context-key value -->
<extractions pattern="Regex containing groups">
<!-- One or more -->
<value group="regex group">property name</value>
</extractions>
<!-- Zero or more -->
<replace value="value to replace" by="replacement or ommit to nullify"
pattern="true or false (default)" />
<!-- Zero or more -->
<properties context-key="execution context key where the property will be"
property-name="Raw Value property name">
<!-- Zero or more -->
<replace value="property to replace" by="replacement or ommit to nullify"
pattern="true or false (default)">
</properties>
<!-- Zero or more -->
<hardcoded-properties key="property name">Property value
</hardcoded-properties>
<!-- Optional -->
<dynamic-properties
prefix-char="The character prefixed to the dynamic properties keys in the execution context (Default = '+')" />
</values>
<!-- Zero or more -->
<dynamic-values>
Same as value but the context-key contains a regex that will be applied
to every execution context property name in order to extract values
</dynamic-values>
<!-- Zero or more -->
<properties context-key="execution context key where the property will be"
property-name="Raw Value property name">
<!-- Zero or more -->
<replace value="property to replace" by="replacement or ommit to nullify"
pattern="true or false (default)">
</properties>
<!-- Zero or more -->
<hardcoded-properties key="property name">Property value
</hardcoded-properties>
<!-- Optional -->
<dynamic-properties
prefix-char="The character prefixed to the dynamic properties keys in the execution context (Default = '+')" />
<relationships
relationship-name="Relationship Name"
context-key=" execution context key where the property will be "
type= “type of the object which is related”>
<dynamic-relations
prefix-char="The character prefixed to the dynamic relations keys in the execution context (Default = '~@R')" />
</data-listeners>
</collecting-configurations>
</collector-configuration>
Each stream collector will have a collector-configuration with following definitions:
-
“source” tag is a hardcoded value to identify the source of the data, this is added as property for each rawvalue.
-
“collecting-group” is the retention group and added as a Meta property for each rawvalue.
-
“properties-refresh-periods” or “auto-detect-properties-refresh” tags define when to force the action for each raw value as refreshed. “properties-refresh-periods” forces the refresh action after defined time period, whereas “auto-detect-properties-refresh” detects automatically when to force the refresh action. Once the action is detected in rawvalue a Meta property “action” with value “r” are added.
-
“default-character-encoding” defines character encoding used by collector.
-
“collecting-threads-pool-size” defines the number threads per “collecting-configurations” defined in this collector.
-
One or more “collecting-configurations” tag which defines collecting configuration of the data, explained in detail below.
Example:
<collector-configuration xmlns="http://www.watch4net.com/Text-Collector-Configuration" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.watch4net.com/Text-Collector-Configuration ../textCollectorConfiguration.xsd ">
<source>OpenStack-Collector</source>
<collecting-group>OpenstackGroup</collecting-group>
<default-character-encoding>UTF-8</default-character-encoding>
<properties-refresh-periods>10m</properties-refresh-periods>
<collecting-threads-pool-size>20</collecting-threads-pool-size>
<collecting-configurations name="openstack-metrics-cache">
:
:
</collector-configuration>
Each collecting-configuration defines following:
-
“include-contexts” includes a file name which has context details of end device to collect the information.
-
“data-retrieval-file” which fetches the stream, transform the stream and converts into execution context data, for more details refer Stream Handling Components
-
One or multiple “data-listeners”, which converts execution context data into raw values, explained in detail below.
<collecting-configurations name="openstack-metrics-cache">
<include-contexts>conf/context-openstack.xml</include-contexts>
<data-retrieval-file>conf/openstack-metrics-cache.xml</data-retrieval-ile>
<data-listeners id="OPENSTACK-IMAGE" variable-id="source keystid parttype partid name">
:
:
</collecting-configurations>
In each data-listeners we define following:
“variable-id” tag used to build unique identification for each packet by grouping the properties. One more tag “variable-id-separator” used to separate the properties.
This value is added as meta property for each raw value:
Example: <data-listeners id="SMARTS-TOPO-FASTDXA" variable-id="type Name" variable-id-separator="::"> Assuming type is “VirtualMachine” and Name as “VM-1” name for this rawvalue is updates as VirtualMachine::VM-1.
One or more “values” tag which is a metric for rawvalue will be updated from context. This should be always a float value. If it is not a float then use replace tag to change accordingly. For each values we should provide “unit” value as shown in below example which is the unit by which this metric is measured.
Example:
- Here we are mapping “disabled” key in context as “Availability” metric in outgoing rawvalue
<values context-key="disabled">
<name>Availability</name>
<unit>%</unit>
</values>
Output:
"metrics" : {
"Availability" : {
"properties" : {
"unit" : "%",
"name" : "Availability"
},
"value" : 100.0
}
}
- This example is same as first one but in this case value of disabled is Boolean, to make it as metric we are converting as float using “replace” tag shown below
<values context-key="disabled">
<name>Availability</name>
<unit>%</unit>
<replace value="false" by="100"/>
<replace value="true" by="0"/>
</values>
- This example is same as second one but in this case value of enabled is String, to make it as metric we are converting as float using “replace” tag shown below. If value is “True” then replace with 100 else if it matches regex pattern replace with 0.
<values context-key="enabled">
<name>Availability</name>
<unit>%</unit>
<replace value="True" by="100"/>
<replace value=".+" by="0" pattern="true"/>
</values>
Zero or more “dynamic-values” which will get the metrics value for rawvalue from context upon regex match. To extract metric values dynamically we have to update execution context by appending a specific pattern (ex: ~@M) for each context key which should be treated as metric during the data retrieval and transformer time. And extract the values using extraction pattern as shown in example below
Ex:
In execution context two values are updated with dynamic
value prefix i.e~@MAvailability=100, ~@MUtilization=100, then for the following configuration.
<dynamic-values context-key="~@M.*" required="false">
<unit>%</unit>
<extractions pattern="~@M(.+)">
<value group="1">name</value>
</extraction>
</dynamic-values>
Output:
"metrics" : {
"Availability" : {
"properties" : {
"unit" : "%",
"name" : "Availability"
},
"value" : 100.0
},
"Utilization" : {
"properties" : {
"unit" : "%",
"name" : "Utilization"
},
"value" : 100.0
}
}
Zero more “properties” which is a property for rawvalue, will be updated from context based on context-key provided.
Ex:
- Maps “CreationClassName” key to “type” in raw value
<properties context-key="CreationClassName" property-name="type"/>
- Maps “pwrstate” key to PWRState by replacing actual integer value to string.
<properties context-key="pwrstate" property-name="PWRState">
<replace value="0" by="Unknown"/>
<replace value="1" by="Running"/>
<replace value="3" by="Paused"/>
<replace value="4" by="Shutdown"/>
<replace value="6" by="Crashed"/>
<replace value="7" by="Suspended"/>
<replace value=".+" by="Unknown" pattern="true"/>
</properties>
Zero more “hardcoded-properties” which is a property for rawvalue will be updates directly the hardcoded value.
Ex: <hardcoded-properties key="devtype">CloudService</hardcoded-properties>
Optional Zero or more “dynamic-properties” will consider and add context-key as properties if it is prefixed with character configured. Default prefix-char is “+”.
Ex: - In this example if any context key is prefixed with “@” is considered as property and added as part of property of rawvalue. <dynamic-properties prefix-char=@/>
Zero or more “relations” which is a relationship for rawvalue will be updated from context based on context-key provided.
Ex: - Maps context key “relatedHypervisor” to relationship “PartOf" <relationships relationship-name="PartOf" context-key="relatedHypervisor" type=”Hypervisor”/>
Optional Zero or more “dynamic-relations” will consider and add context-key as properties if it is prefixed with character configured. Default prefix-char is “~@R”. Always relationship show have format Key as <prefix>relationName and value as ClassName:ObjectName|ClassName:ObjectName during transformation and updated in context.
Ex:
- In this example if any context key is prefixed with “~@T” is considered as relation and added as part of relationship of rawvalue. During transformation context should be updated as follows: ~@TPartOf=Hypervisor:HV-1|Hypervisor:HV-2
<dynamic-relations prefix-char=~@T/>
Ex: Data-listener configuration example.
<data-listeners id="OPENSTACK-IMAGE" variable-id="source keystid parttype partid name">
<values context-key="Status">
<name>Status</name>
<unit>code</unit>
<replace value="active" by="0"/>
<replace value="queued" by="1"/>
<replace value="saving" by="2"/>
<replace value="deleted" by="3"/>
<replace value="pending_delete" by="4"/>
<replace value="killed" by="5"/>
</values>
<dynamic-values context-key="~@M.*" required="false">
<unit>bytes</unit>
<extractions pattern="~@M(.+)">
<value group="1">name</value>
</extractions>
</dynamic-values>
<properties context-key="cformat" property-name="cformat"/>
<properties context-key="isprotec" property-name="isprotec">
<replace value="false" by="No"/>
<replace value="true" by="Yes"/>
</properties>
<properties context-key="ispublic" property-name="ispublic">
<replace value="private" by="No"/>
<replace value="public" by="Yes"/>
</properties>
<properties context-key="updated" property-name="updated"/>
<hardcoded-properties key="datagrp">OPENSTACK-IMAGE</hardcoded-properties>
<hardcoded-properties key="devtype">CloudService</hardcoded-properties>
<hardcoded-properties key="parttype">Image</hardcoded-properties>
</data-listeners>
Example of a Stream Collector configuration:
In this example a collecting configuration is configured with 2 data-listeners.
These collecting configuration are executed against the device context provided in file “conf/context-openstack.xml”
which includes all device credentials and context variables to collect the information from device. All the retrieval information of the data is defined in file “conf/openstack-metrics-main.xml” which will get the stream, transform the stream and provide it to datalistner. DataListner will convert the contexts data available to raw values and publish it to next component defined in collecting.xml.
<?xml version="1.0" encoding="UTF-8"?>
<collector-configuration xmlns="http://www.watch4net.com/Text-Collector-Configuration" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.watch4net.com/Text-Collector-Configuration ../textCollectorConfiguration.xsd ">
<source>OpenStack-Collector</source>
<collecting-group>group</collecting-group>
<default-character-encoding>UTF-8</default-character-encoding>
<properties-refresh-periods>10m</properties-refresh-periods>
<collecting-threads-pool-size>20</collecting-threads-pool-size>
<collecting-configurations name="openstack-metrics-main">
<!--File location which has context details of end device -->
<include-contexts>conf/context-openstack.xml</include-contexts>
<!--File which retrieves and transforms the stream in to context data-->
<data-retrieval-file>conf/openstack-metrics-main.xml</data-retrieval-file>
<data-listeners id="GET-OPENSTACK-HYPERVISORS" variable-id="type device">
<values context-key="CurrentWorkload">
<name>CurrentWorkload</name>
<unit>nb</unit>
</values>
<values context-key="RunningVMs">
<name>RunningVMs</name>
<unit>nb</unit>
</values>
<values context-key="TotalVCpus">
<name>TotalVCpus</name>
<unit>nb</unit>
<properties context-key="cpu-partmod" property-name="partmod"/>
<properties context-key="cpu-partvndr" property-name="partvndr"/>
<hardcoded-properties key="part">System</hardcoded-properties>
<hardcoded-properties key="parttype">Processor</hardcoded-properties>
</values>
<values context-key="UsedVCpus">
<name>UsedVCpus</name>
<unit>nb</unit>
<properties context-key="cpu-partmod" property-name="partmod"/>
<properties context-key="cpu-partvndr" property-name="partvndr"/>
<hardcoded-properties key="part">System</hardcoded-properties>
<hardcoded-properties key="parttype">Processor</hardcoded-properties>
</values>
<values context-key="CurrentUtilization">
<name>CurrentUtilization</name>
<unit>%</unit>
<hardcoded-properties key="part">Physical Memory</hardcoded-properties>
<hardcoded-properties key="parttype">Memory</hardcoded-properties>
</values>
<values context-key="FreeMemory">
<name>FreeMemory</name>
<unit>MB</unit>
<hardcoded-properties key="part">Physical Memory</hardcoded-properties>
<hardcoded-properties key="parttype">Memory</hardcoded-properties>
</values>
<values context-key="TotalMemory">
<name>TotalMemory</name>
<unit>MB</unit>
<hardcoded-properties key="part">Physical Memory</hardcoded-properties>
<hardcoded-properties key="parttype">Memory</hardcoded-properties>
</values>
<values context-key="UsedMemory">
<name>UsedMemory</name>
<unit>MB</unit>
<hardcoded-properties key="part">Physical Memory</hardcoded-properties>
<hardcoded-properties key="parttype">Memory</hardcoded-properties>
</values>
<values context-key="TotalDisk">
<name>TotalDisk</name>
<unit>GB</unit>
<hardcoded-properties key="part">Physical Memory</hardcoded-properties>
<hardcoded-properties key="parttype">Disk</hardcoded-properties>
</values>
<values context-key="UsedDisk">
<name>UsedDisk</name>
<unit>GB</unit>
<hardcoded-properties key="part">System</hardcoded-properties>
<hardcoded-properties key="parttype">Disk</hardcoded-properties>
</values>
<properties context-key="fqdn" property-name="device"/>
<properties context-key="fqdn" property-name="fqdn"/>
<properties context-key="ip" property-name="ip"/>
<properties context-key="host" property-name="host"/>
<properties context-key="KEYSTONE_ID" property-name="keystid"/>
<properties context-key="TotalVCpus" property-name="nbcpu"/>
<properties context-key="OPST_HOST" property-name="osendpt"/>
<hardcoded-properties key="datagrp">OPENSTACK-HYPERVISOR</hardcoded-properties>
<hardcoded-properties key="devtype">Hypervisor</hardcoded-properties>
<hardcoded-properties key="type">HypervisorMonitor</hardcoded-properties>
</data-listeners>
<data-listeners id="OPENSTACK-VM" variable-id="type devid">
<values context-key="RootCapacity">
<name>Capacity</name>
<unit>GB</unit>
<properties context-key="root-natvolnm" property-name="natvolnm"/>
<hardcoded-properties key="part">Root</hardcoded-properties>
<hardcoded-properties key="partdesc">Root Disk for @{device}</hardcoded-properties>
<hardcoded-properties key="parttype">Virtual Disk</hardcoded-properties>
<hardcoded-properties key="voltype">Root</hardcoded-properties>
</values>
<properties context-key="avzone" property-name="avzone"/>
<properties context-key="created" property-name="created"/>
<properties context-key="device" property-name="device"/>
<properties context-key="deviceid" property-name="devid"/>
<properties context-key="deviceid" property-name="deviceid"/>
<properties context-key="flavname" property-name="flavname"/>
<properties context-key="flavorid" property-name="flavorid"/>
<properties context-key="hypervsr" property-name="hypervsr"/>
<properties context-key="imageid" property-name="imageid"/>
<properties context-key="imagenm" property-name="imagenm"/>
<properties context-key="KEYSTONE_ID" property-name="keystid"/>
<properties context-key="ip" property-name="ip"/>
<properties context-key="keyname" property-name="keyname">
<replace value="null" by="N/A"/>
</properties>
<properties context-key="TotalVCpus" property-name="nbcpu"/>
<properties context-key="OPST_HOST" property-name="osendpt"/>
<properties context-key="projid" property-name="projid"/>
<properties context-key="pwrstate" property-name="pwrstate">
<replace value="0" by="Unknown"/>
<replace value="1" by="Running"/>
<replace value="3" by="Paused"/>
<replace value="4" by="Shutdown"/>
<replace value="6" by="Crashed"/>
<replace value="7" by="Suspended"/>
<replace value=".+" by="Unknown" pattern="true"/>
</properties>
<properties context-key="status" property-name="status"/>
<properties context-key="updated" property-name="updated"/>
<properties context-key="userid" property-name="userid"/>
<hardcoded-properties key="devtype">VirtualMachine</hardcoded-properties>
<hardcoded-properties key="datagrp">OPENSTACK-VM</hardcoded-properties>
<hardcoded-properties key="type">VirtualMachine</hardcoded-properties>
</data-listeners>
</collecting-configurations>
</collector-configuration>
Stream Handling Components
The Stream Collector is made of several Stream Handling Components that handles Stream of data. Each of them are specialize in a single function and accept a set of components nested in them in order to create a chain of Stream handling in a file and provided as “data-retrieval-file” for “collecting-configurations” as explained in previous section . The chain are then evaluated in order to eventually extract data in the Execution Context and release those context as soon as possible to the Stream Collector. One of the goal of the Stream Collector is also to stream the data as much as possible instead of materializing it in memory. This will make possible the handling of incredibly huge Stream of data without any memory requirements on the collector. Unless stated otherwise, all the following components are working as streaming.
The following sections explain the configuration of each individual tags. The data retrieval file is formatted as such:
<data-retrieval-configuration>
<!-- CHOICE -->
<retrieving-period>The period between two executions of the data retrieval chain</retrieving-period>
<!-- OR-->
<automatic-retrieving/>
<!-- Root Stream Retriever -->
</data-retrieval-configuration>
1) “retrieving-period” or “automatic-retrieving” will define the period between execution chain
a. “retrieving-period” the period between two executions of the data retrieval chain. The retrieving-period element is contextualizable and is expected to be formatted as a series of integer value followed by one of these:
• d: Days
• h: Hours
• m: Minutes
• s: Seconds
b. “automatic-retrieving” The automatic-retrieving option is not available on every Stream Retriever. The Stream Retriever supporting this option will detect automatically when it should generate a Stream of data.
2) In this “data-retrieval-configuration” we have to define chain of Stream handling components and convert the stream of data into meaningful execution context data.
3) Furthermore some parameters are available on every Stream Handling Components:
a) Attribute name: The optional Stream Handling Components that will be used when logging information (see System Properties section). When not set, the Java class name will be used instead.
b) Attribute private-execution: Can be set to true or false (default). Having this attribute enabled will make sure that a Stream Handling Components won’t share the extracted Execution Context data and internal shared objects like connections to its siblings Stream Handling Components. This option should only be used when necessary since it creates a clone of the execution.
c) Element lock: The optional element lock with the attribute name and count is a way to throttle the execution of the Stream Handling Components chain and is explained in the Lock Management section.
Lock Management
Any Stream Handling Components can use a single name lock to restrict conceptual concurrent executions. For example, it’s an efficient way to make sure that multiple different configurations that does a HTTP request to the same device aren’t launching all their request at the same time even if there’s enough collecting threads when this device type is sensitive to concurrent requests. A lock will be the first element in any Stream Handling Components and is formatted as such:
<lock name="lockUniqueName"count="concurrentExecutionCount" />
The name of the lock can be contextualized in order to include the device name for example. The count is the number of concurrent owners of the same lock that can do their execution. The list of locks will be unique among all the data-retrieval-file of the collecting-configurations. If there’s multiple configuration using the same lock, their configuration must be the same. Moreover, it’s impossible to reuse the same lock multiple times in the same chain or use them in a different order (Ex: conf1 uses lock A then B while conf2 uses lock B then A) since it can leads to deadlocks.
JEXL Normalization
Many Stream Handling Components use JEXL when doing script like work. It’s important to note the Execution Context properties will be passed as variables and some normalization is required for the names. Invalid Execution Context key names are changed to be valid JEXL identifiers as follow:
-
Execution Context key starting with a digit: Key is prefixed with an underscore. Example: 1My-ContextKey becomes 1MyContextKey.
-
Spaces: spaces are replaced by underscores. Example: My Context Key becomes My_Context_Key.
-
Dashes: dashes are replaced by underscores. Example: My-Context-Key becomes My_Context_Key.
Stream Retriever
Stream Retriever are components responsible to actually retrieve the Stream of data somewhere. Some Stream can be retrieving automatically instead of being run in a scheduled. Following are the different stream retriever explained in detail:
File Reader RetrieverThis Stream Retriever will read one or more files stored locally on the collector server. This retriever can go and download the files from a remote location before reading them. This Stream Retriever can retrieve Stream automatically by detecting file changing in a directory.
Template Configuration:
<file-reader read-files-in-parallel="true or false (default)"
character-encoding="optional">
<!-- CHOICE -->
<file>Single file that can be relative to the collector location</file>
<!-- OR -->
<directory file-pattern="Glob matching the files to read"
recursive="true or false (default)"
file-ordering="name-ascending (default), name-descending, mtime-ascending or mtime-descending">
Directory that can be relative to the collector location
</directory>
<!-- Optional action when closing the file -->
<file-close-action type="move, delete or exec">
<parameters>Action dependent parameters</parameters>
</file-close-action>
<!-- Optional data extractions from the file name -->
<filename-properties-extraction pattern="Regex containing groups"
extraction-required="true (default) or false flag telling if a failed extraction should be logged or not">
<!-- One or more -->
<value group="regex group">new context property name</value>
</filename-properties-extraction>
<!-- Optional process retrieving files for the configured directory -->
<retrieve-files type="ftp, sftp or local"
source-property="optional" retrieval-period="seconds"
max-file-downloads="maximum number of downloaded files (default = 25)">
<parameters>Protocol dependent parameters</parameters>
</retrieve-files>
<!-- Next components (Tranformers, Data Readers, Dataset Readers or Conditions) -->
</file-reader>
a) “file-reader” tag has following options
- “read-files-in-parallel” default is false, will allow the parsing of many files in parallel (bounded by the configuration of collecting-threads-pool-size).
- “character-encoding” will overwrite the default encoding defined in the environment settings for this Stream Retriever.
b) “file” or “directory” tags which provides the location of the files to be retrieved.
“file” tag can be used to fetch single file that can be relative to the collector location.
“directory” tag can be used to fetch files from directory that can be relative to collector location with following options:
- “file-pattern” is a glob pattern can contains wildcards such as ? and * and it can also contains multiple globs separated by |. The attribute can also be used to create wildcards for sub directories. However, since the comparison will be done on the absolute filename, the pattern must always starts with a * when specifying a directory.
- “recursive” fetch files recursively from directory, default is true
- “file-ordering” ordering of files, options:
1. name-ascending(default)
2. name-descending
3. time-ascending
4. time-descending
c) “file-close-action” tag is an optional tag which can be used to execute which action should be taken when closing the file after processing, options:
- “type” has following options
1. move: The destination directory and an optional suffix to the moved file.
2. delete: Doesn’t requires any parameter.
3. exec: The command to execute and all the parameters in separate values.
- “parameters” tag under “file-close-action” is used for each of the option above which requires parameters
d) “filename-properties-extraction” is an optional tag which can be used to extract any data from filename and update in execution context.
e) “retrieve-files” tag can be used to fetch the files from remote server, options:
- “type” has following options:
1. ftp , parameters are:
• hostString: The host string in the format hostname:port.
• username: The username.
• password: The password.
• remoteDirectory: The remote directory.
• timeout: The data timeout (in milliseconds). Timeout used when reading from the data connection. 0 means no timeout.
• connectTimeout: The connection timeout (in milliseconds). Timeout used for the connection to the underlying TCP socket. 0 means no timeout.
• readTimeout: The read timeout (in milliseconds). Timeout used when opening the socket. 0 means no timeout.
• mtimeThreshold: The time (in milliseconds) that the client will wait before downloading the file. To make sure that the file is not written anymore.
• mode: The FTP connection mode (passive or active).
• deleteRemoteFile: The flag that tells if the remote file shall be deleted after it has been retrieved. Set to true if you want to delete the file, otherwise set it to false.
2. sftp, parameters are:
• hostString: The host string in the format hostname:port.
• username: The username.
• password: The password.
• remoteDirectory: The remote directory.
• connectTimeout: The connection timeout (in milliseconds). Timeout used for the connection to the underlying TCP socket. 0 means no timeout.
• readTimeout: The read timeout (in milliseconds). This is the amount of time the read operation can be blocked before the timeout occurred. 0 means no timeout.
• mtimeThreshold: The time (in milliseconds) that the client will wait before downloading the file. To make sure that the file is not written anymore.
• deleteRemoteFile: The flag that tells if the remote file shall be deleted after it has been retrieved. Set to true if you want to delete the file, otherwise set it to false.
3. local, parameters are:
• sourceDirectory: The local directory containing the files.
• mtimeThreshold: The time (in milliseconds) that the client will wait before downloading the file. To make sure that the file is not written anymore.
• deleteRemoteFile: The flag that tells if the source file shall be deleted after it has been copied. Set to true if you want to delete the file, otherwise set it to false.
- “parameters” tag under “retrieve-files” is used for each of the type above which requires parameters
Examples:
1) In this example file “conf/request-conf.xml” content is converted as stream and forwarded to next components in chain
<data-retrieval-configuration xmlns="http://www.watch4net.com/Text-Parsing-Configuration" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.watch4net.com/Text-Parsing-Configuration ../textParsingConfiguration.xsd" xmlns:xi="http://www.w3.org/2001/XInclude">
<retrieving-period>2400s</retrieving-period>
<file-reader>
<file>conf/request-conf.xml</file>
<!-- Next components (Tranformers, Data Readers, Dataset Readers or conditions) -->
</file-reader>
2) In this example files will be transferred from remote host to local directory using sftp. Transferred files are read and converted to stream. In this example only files whose name matches specified pattern will be considered. Once file is read is deleted after operation.
<file-reader read-files-in-parallel="false">
<directory file-pattern="*_VIRTUAL_VOLUMES_PERPETUAL_MONITOR.log">w4n_vplex/@{vplex.id}/virt-volumes/cluster1/</directory>
<file-close-action type="delete" /> <!-- delete local file after parsing -->
<filename-properties-extraction pattern="(\S+)_VIRTUAL_VOLUMES_PERPETUAL_MONITOR.log">
<value group="1">DIRECTOR</value>
</filename-properties-extraction>
<retrieve-files type="sftp" retrieval-period="900s">
<parameters>@{cluster1.host}</parameters>
<parameters>@{cluster1.username}</parameters>
<parameters>@{cluster1.password}</parameters>
<parameters>/var/log/VPlex/cli/</parameters>
<parameters>60000</parameters> <!-- connectTimeout in ms -->
<parameters>120000</parameters> <!-- readTimeout in ms -->
<parameters>0</parameters> <!-- mtimeThreshold in ms -->
<parameters>false</parameters> <!-- deleteRemoteFile -->
</retrieve-files>
<!-- Next components (Tranformers, Data Readers, Dataset Readers or Conditions) -->
</file-reader>
HTTP Request Retriever
This Stream Retriever can execute a set of HTTP request on a remote host in order to create a Stream of data containing the first successful request group. Having multiple request groups is usefull when having a primary host and failover hosts. Each request group will be executed sequentially until one of the host returns a desired response.
Template Configuration:
<remote-command run-commands-in-parallel="true or false (default)" character-encoding="optional">
<primary-connection commands-file="Optional defined commands file">
<host>Hostname or IP address</host>
<port>Optional port, will be using the protocol default one when not present</port>
<binding-address>Optional source binding address</binding-address>
<!-- CHOICE -->
<ssh-connection use-multiplexed-session="true or false (default)" connection-timeout="Optional connection timeout in seconds (Default is 5)">
<!-- CHOICE -->
<user-pass-authentication>
<username></username>
<password></password>
</user-pass-authentication>
<!-- OR -->
<keyboard-interactive-authentication>
<username></username>
<password></password>
</keyboard-interactive-authentication>
<!-- OR -->
<public-key-authentication username="The username"
password="Optional PEM file password">
Location of the PEM file
</public-key-authentication>
<!-- CHOICE -->
<session-connection use-pty="true or false (default)" />
<!-- OR -->
<shell-connection>Prompt character (or regex) finder
</shell-connection>
</ssh-connection>
<!-- OR -->
<telnet-connection prompt-character="Prompt character (or regex) finder"
connection-timeout="Optional connection timeout in seconds (Default is 5)">
<credentials>
<username></username>
<password></password>
</credentials>
</telnet-connection>
<!-- OR -->
<winrm-connection use-https="Use secure connection (Default = false)"
disable-ssl- validation="Disable SSL validation (Default = false)">
<path>Optional path of the directory on the remote host containing
the scripts (Default = /wsman)
</path>
<credentials>
<username></username>
<password></password>
</credentials>
<timeout>The maximum amount of time an operation can take (Default =
60s)</timeout>
</winrm-connection>
</primary-connection>
<!-- Optional list -->
<failover-connections>Same as primary connection</failover-connections>
<!-- Zero or more -->
<commands type="defined or custom">The command to run</commands>
<!-- Zero or more -->
<dynamic-scripts-locations file-pattern="Glob matching the files to read"
file-ordering="name
-ascending (default), name-descending, mtime-ascending or mtime-descending"
recursive="true or
false (default)"
include-context-properties-with-prefix="Optional prefix for context properties
to include as arguments"
os-type="windows or unix (default)">
Directory that can be relative to the collector location
</dynamic-scripts-locations>
<!-- Optional next components (Tranformers, Data Readers, Dataset Readers
or Conditions) -->
</remote-command>
a. “remote-command” tag has following options:
- “run-commands-in-parallel” default is false, will allow running multiple commands in parallel (bounded by the configuration of collecting-threads-pool-size).
- “character-encoding” will overwrite the default encoding defined in the environment settings for this Stream Retriever
b. “primary-connection” tag will have details of command to be executed on remote host
- “commands-file” is a property where we can define commands to be executed before execution of required command output, ex: Setting environment variables required.
- “host” tag will be used to define hostname or ip address of remote host.
- Optional “port” tag will be used to define the port where service is running.
- Optional “binding-address” tag will be used to define the source binding address.
- “ssh-connection” or “telnet-connection” or “winrm-connection”tags will be used to define the mechanism to execute commands on remote host.
1. “ssh-connection” tag defines ssh connection details and other option
• “use-multiplexed-session” default false. Will executed each command in the same TCP connection.
• “connection-timeout” default 5.
• “user-pass-authentication” or “keyboard-interactive-authentication” or “public-key-authentication” tags are used for authentication.
• “session-connection” or “shell-connection” used define type of connection. The difference between a SSH session connection and a SSH shell connection is that a session is a controlled environment with an input, output and error Stream while a shell emulates someone typing on a terminal. It’s recommended to use a session connection unless the device is not supporting it.
2. “telnet-connection” tag defines telnet connection details and other option
• “prompt-character” Prompt character or regex to match the prompt
• “connection-timeout” default 5.
• “credentials” tag is used provide credentials to authenticate remote host.
3. “winrm-connection” tag defines windows remote management connection details and other option
• “use-https” default false
• “disable-ssl-validation” default false
• “path” default “/wsman” Optional path of the directory on the remote host containing the scripts.
• “credentials” tag is used provide credentials to authenticate remote host.
• “timeout” default 60s
i. Optional list of “failover-connections” tag used to define failover connection details
j. Zero or more “commands” tag can be used run a specific command
- “type” has 2 options
1. defined : if command is defined ex: linux command ls
2. custom: custom command or a script
k. Zero or more “dynamic-scripts-locations” tag can be will search for one or multiple scripts to execute on the remote hosts. The scripts must already be present on the remote host and the file structure must be the same on the remote host as it is on the local one. This option is normally used with File Transfer which is explained later.
- “file-pattern” can be used to filter files by glob patterns. Glob can contains wildcards such as ? and * and it can also contains multiple globs separated by j. The attribute can also be used to create wildcards for sub directories. However, since the comparison will be done on the absolute filename, the pattern must always starts with a * when specifying a directory.
- “file-ordering” can be used to define the order of execution
- “recursive” can be used to get the file from sub directories
- “include-context-properties-with-prefix” can be used to prefix for context properties to include as arguments. Will allow dynamic arguments to be used in the remote commands. The prefix will be removed from the argument name and each argument will be formatted as –argumentName ”argumentValue”.
- “os-type” default Unix, Option windows or unix. Will defined the right file separator to use when normalizing script files found on a recursive search only.
Examples:
1) In this example a defined command will be executed using “ssh-connection” , before running command all commands in file “commands-file="conf/parsers/vnxfile-commands.xml” will be executed.
<remote-command name="Retrieve deduplicated File Systems from CLI">
<primary-connection commands-file="conf/parsers/vnxfile-commands.xml">
<host>@{csactive}</host>
<ssh-connection>
<keyboard-interactive-authentication>
<username>@{filesshusername}</username>
<password>@{filepassword}</password>
</keyboard-interactive-authentication>
<session-connection />
</ssh-connection>
</primary-connection>
<commands type="defined">fs_dedupe</commands>
<!-- Optional next components (Tranformers, Data Readers, Dataset Readers
or Conditions) -->
</remote-command>
The contents of file conf/parsers/vnxfile-commands.xml as follows which follows the definition defined in commandDefinition.xsd
<command-definition
xmlns="http://www.watch4net.com/Text-Parsing-Configuration" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.watch4net.com/Text-Parsing-Configuration ./commandDefinition.xsd ">
<commands>
<name>Set NAS_DB</name>
<command>export NAS_DB=/nas;</command>
</commands>
<commands>
<name>nas_replicate</name>
<command>cd ./@{srmdirectory};./vnxfile-nas_replicate.sh</command>
</commands>
</command-definition>
4. Local Command Retriever
This Stream Retriever can execute a given set of commands locally in order to create a Stream or data containing the first successful command output.
Template Configuration:
<local-command data-timeout="(Default = 15s)"
command-timeout="(Default = 1m)" character- encoding="optional"
wait-for="(Default = false)">
<primary-command>
<command>The command to run</command>
<!-- Optional list -->
<arguments>Optional arguments for the command</arguments>
<!-- Optional list -->
<environment-variables key="The key associated to this value">The value of the environment variable
</environment-variables>
<!-- Optional list -->
<update-context-properties
key="Name of the key to set/update in the context">The value to set in the context. This can be a contextualized key.
</update-context-properties>
</primary-command>
<!-- Optional list -->
<failover-commands exit-code="Optional exit code filtering">
Same as primary command
</failover
-commands>
<!-- Next components (Tranformers, Data Readers, Dataset Readers or Conditions) -->
</local-command>
a. “local-command” tag has following options:
- “data-timeout” default 15s, maximum amount of time a command can take before returning a readable stream of data
- “command-timeout” default 1m, maximum amount of time a command can take before returning a readable stream of data
- “character- encoding” will overwrite the default encoding defined in the environment settings for this Stream Retriever
- “wait-for” will wait for the command to finish completely before processing the next component. When using this option, it’s also possible to trigger the failover commands on specific exit values. The possible format for exit-code are:
1. Specific list of codes: -2,1,3,10,...
2. Inclusive/Inclusive range of codes: [1;5]
3. Inclusive/Exclusive range of codes: [1;5[
4. Exclusive/Inclusive range of codes: ]1;5]
5. Exclusive/Exclusive range of codes: ]1;5[
6. Any error when not specified
Warning: Note that using wait-for will WARNING: have the side-effect to buffer all the output of the running command in the heap of the java application. Using high output scripts can potentially bust the heap and crashes the application. In such case, you can increase the heap memory of the java application.
Examples:
1) In this example command “ls –la” will be executed and output is retrieved as stream and passed to next components in chain
<local-command data-timeout="5m" command-timeout="10m">
<primary-command>
<command>ls</command>
<arguments>-la</arguments>
</primary-command>
<!-- Next components (Tranformers, Data Readers, Dataset Readers or Conditions) -->
</local-command>
5. Static Retriever
This Stream Retriever creates a static output from either a template file or a given content. The result will produce a Stream by default, but can also be used to update Execution Context properties. When producing properties, the output must contains one propertyName=propertyValue per line. Furthermore, when using a FTL file, all the current context properties will be passed as variables. If some context keys contains dashes (’-’), don’t forget to quote them when used in the FTL file (.vars[”varname-with-dash”]).
Template Configuration:
<static-retriever context-update="Optional true of false (default)"
character-encoding="optional">
<!-- CHOICE -->
<ftl-file>The path of the target template file</ftl-file>
<!-- OR -->
<content>The static content</content>
<!-- Optional and only when updating the context -->
<release id="ID of the release" />
<!-- Optional next components (Stream Retrievers, Tranformers, Data Readers, Dataset Readers or Conditions) -->
</static-retriever>
a. “static-retriever” tag has following options:
- “context-update” default false, if true will update the execution context with properties from content. But output stream must contains one propertyName=propertyValue per line
- “character- encoding” will overwrite the default encoding defined in the environment settings for this Stream Retriever
b. “ftl-file” or “content” tags are used to create stream out of static content
c. Optional “release” tag is used to relase the data to data-listners by updating context, Only used when “context-update” is true.
Examples:
1) In this example a property value from execution context is extracted and passed on to next components in chain
<static-retriever context-update="false" character-encoding="utf8">
<content>@{URL}</content>
<!-- Optional next components (Stream Retrievers, Tranformers, Data Readers, Dataset Readers or Conditions) -->
</static-retriever>
2) In this example we are passing ftl file which will create the stream and update the context and release the data to data-listner to create rawvalue.
<static-retriever context-update="true">
<ftl-file>conf/aggregation-data.freemarker
</ftl-file>
<context-conditional-filter>
<!-- Only release if there is no PacketFault -->
<when test="packetfault != 'error'">
<release id="CELERRA-SYSTEM" />
</when>
</context-conditional-filter>
</static-retriever>
aggregation-data.freemarker content :
OpenedAt=${((OpenedAt?datetime("MM/dd/yyyy HH:mm:ss")?long / 1000)?floor + tsoffset?number)?c}
sourceip=${source_ip}
JMS Listener Retriever
This Stream Retriever creates a Stream from a received JMS message content. This Stream Retriever can only be used when running in automatic retrieval. This means that the JMS Listener Retriever can only be used as the first Stream Retriever in the chain and not as one of the internal link. The usage of this Stream Retriever requires a good understanding of Java and JMS since classes’ reference are required.
Template Configuration:
<jms-listener>
<url>The URL of the JMS Publisher</url>
<credentials>
<username></username>
<password></password>
</credentials>
<context factory="The JMS Context Factory Java class" name="Optional JMS specific context">
<client-id>The topic Client ID</client-id>
<!-- Optional list -->
<connection-options key="Option key">
JMS context class specific connection options
</connection-options>
<topic-factory>The Topic factory Java class</topic-factory>
<!-- One or more -->
<topics name="Topic name" filter="Optional topic filter" />
<!-- Choice of a Stream Retriever or a next component -->
</jms-listener>
a. “url” tag is used to provide the jms url.
b. “credentials” tag is used to provide credentials for authentication.
c. “context” tag includes all jms related configuration
- “factory” property is used to define JMS context factory java class.
d. “client-id” tag used to define topic client id.
e. Optional List of “connection-options” tag is used to provide the different options for connection ex: timeout.
f. “topic-factory” tag is used to define the topic factory Java class.
g. One or more “topics” tag is used to define topics.
Example:
1) In this example we are pulling data from alcatel-sam using jms
<data-retrieval-configuration
xmlns="http://www.watch4net.com/Text-Parsing-Configuration" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.watch4net.com/Text-Parsing-Configuration ../../src/conf/com/watch4net/apg/ubertext/textParsingConfiguration.xsd"
xmlns:xi="http://www.w3.org/2001/XInclude">
<automatic-retrieving />
<jms-listener>
<url>jnp://@{host}:@{jmsport}</url>
<credentials>
<username>@{username}</username>
<password>@{password}</password>
</credentials>
<context name="external/5620SamJMSServer" factory="org.jnp.interfaces.NamingContextFactory" />
<client-id>@{clientId}</client-id>
<connection-options key="java.naming.factory.url.pkgs">org.jboss.naming:org.jnp.interfaces
</connection-options>
<connection-options key="jnp.disableDiscovery">true</connection-options>
<connection-options key="jnp.timeout">60000</connection-options>
<topic-factory>SAMConnectionFactory</topic-factory>
<topics name="5620-SAM-topic-xml"
filter="ALA_clientId in ('@{clientId}', '') and MTOSI_objectType = 'FileAvailableEvent'" />
<!-- Choice of a Stream Retriever or a next component -->
</jms-listener>
</data-retrieval-configuration>
HTTP Listener Retriever
This Stream Retriever creates a Stream from a received HTTP Entity content. This Stream Retriever can only be used when running in automatic retrieval. This means that the HTTP Listener Retriever can only be used as the first Stream Retriever in the chain and not as one of the internal link. The usage of this Stream Retriever requires a basic understanding of URI pattern. You could also use wild card based URI to define generic URI pattern like /module/*.
Template Configuration:
<http-listener character-encoding="optional">
<port>Port number on which the HTTP Listener needs to be configured to
listen.</port>
<pattern>URI pattern to be configured to listen for incomming requests.
</pattern>
<!-- Next components (Tranformers, Data Readers, Dataset Readers or Conditions) -->
</http-listener>
a. “port” is used to configure port on which http listener needs to be configured.
b. “pattern” URI pattern to be configured to listen for incoming requests.
Example:
1) In this example http-listner listens to configured port and matches the URI to configured pattern. All matched URI stream is forwarded to next components.
<http-listener character-encoding="UTF-8">
<port>8080</port>
<pattern>/abc/def</pattern>
</http-listener>
File Transfer
This Stream Retriever differ from any other Stream Retriever since it’s not actually creating any Stream of data. Its responsibility is to send files to a remote location. Then, it can start a real chain of components or not. At least one files or directories must be defined. The Stream Collector is not responsible for tempered remote files.
Template Configuration:
<file-transfer>
<!-- Optional list -->
<files executable-files="true or false" always-full-transfer="true or false (default)"
delete - source-files="true or false (default)">
Single file that can be relative to the collector location
</files>
<!-- Optional list -->
<directories file-pattern="Glob matching the files to send"
recursive="true or false (default)" executable-files="true or false"
always-full-transfer="true or false (default)" delete-
source-files="true or false (default)">
Directory that can be relative to the collector location
</directories>
<!-- CHOICE -->
<local-destination>Local directory</local-destination>
<!-- OR -->
<sftp-destination>
<host>Hostname or IP address</host>
<port>Optional port, will be using 22 when not present</port>
<binding-address>Optional source binding address</binding-address>
<destination>Optional destination under the user home</destination>
<!-- CHOICE -->
<user-pass-authentication>
<username></username>
<password></password>
</user-pass-authentication>
<!-- OR -->
<keyboard-interactive-authentication>
<username></username>
<password></password>
</keyboard-interactive-authentication>
<!-- OR -->
<public-key-authentication username="The username"
password="Optional PEM file password">
Location of the PEM file
</public-key-authentication>
</sftp-destination>
<!-- OR -->
<ftp-destination mode="passive (default) or active"
os-type="windows or unix (default)">
<host>Hostname or IP address</host>
<port>Optional port, will be using 21 when not present</port>
<binding-address>Optional source binding address</binding-address>
<destination>Optional destination under the user home</destination>
<credentials>
<username></username>
<password></password>
</credentials>
</ftp-destination>
<!-- OR -->
<winrm-destination use-https="Use secure connection (Default = false)"
disable-ssl-validation="Disable SSL validation (Default = false)">
<host>Hostname or IP address</host>
<port>Optional port, will be using default HTTP (5985) and HTTPS
(5986) when not present</port>
<path>Optional path of the directory on the remote host containing the
scripts (default: /wsman)</path>
<credentials>
<username></username>
<password></password>
</credentials>
<timeout>The maximum amount of time an operation can take (Default =
60s)</timeout>
</winrm-destination>
<!-- Optional next Stream Retriever -->
</file-transfer>
a. Optional List of “files” tag is used to define the files to be transferred to remote host
- “executable-files” property is used to mark file is an executable
- “always-full-transfer” default false, when set to false, they will be transferred only when the Stream Collector is starting and then only when they are modified locally.
- “delete-source-files” default false, if true will delete the file at source after transfer
b. Optional List of “directories” tag is used to define the files in a directory to be transferred to remote host.
- “file-pattern” property is used to define glob pattern for file names to be transferred. The file-pattern glob can contains wildcards such as ? and * and it can also contains multiple globs separated by j. The attribute can also be used to create wildcards for sub directories. However, since the comparison will be done on the absolute filename, the pattern must always starts with a * when specifying a directory
- “recursive” property is used to define to go to subdirectories recursively.
- “executable-files” property is used to mark file is an executable
- “always-full-transfer” default false, when set to false, they will be transferred only when the Stream Collector is starting and then only when they are modified locally.
- “delete-source-files” default false, if true will delete the file at source after transfer
c. “local-destination” or “sftp-destination” or “ftp-destination” or “winrm-destination” tags can be used to define the transfer mode of the file.
- “local-destination” tag is used to transfer the files locally.
- “sftp-destination” tag is used to transfer the files to remote host using sftp
- “ftp-destination” tag is used to transfer the files to remote host using ftp
- “winrm-destination” ” tag is used to transfer the files to remote host using winrm
Examples:
1) In this example we are transferring 2 files to a remote host using sftp
<file-transfer
name="Copy scripts to remote host">
<files executable-files="true" always-full-transfer="true">conf/parsers/replicate.sh
</files>
<!-- startStats.pl used later to collect server_stats metrics -->
<files executable-files="true" always-full-transfer="true">conf/parsers/startStats.pl
</files>
<sftp-destination>
<host>@{host}</host>
<destination>@{destination_dir}</destination>
<keyboard-interactive-authentication>
<username>@{user}</username>
<password>@{pwd}</password>
</keyboard-interactive-authentication>
</sftp-destination>
<!-- Optional next Stream Retriever -->
</file-transfer>
Transformer
Transformer are components that will take the incoming Stream of data to either transform it to a new Stream for the next components or apply complex data extraction transformation.
XSL Stream Transformer
This Transformer will take an incoming Stream expected to be XML and send it to a XSL file in order to create a new outgoing Stream. Forcing the conversion to XML is only required when the incoming Stream is not a valid XML. When set the text will be enclosed with <W4N>. Every Execution Context entry will be passed as parameters in the XSL and their name will be normalized in order to be valid (each spaces and dashes will be replaced by an underscore and if the key starts with a digit, it will be prefixed by an underscore). Furthermore, the working directory of the Stream Collector will be passed under the WORKING DIR parameter.
Template configuration:
<xsl-stream-transformer convert-stream-to-xml="true or false (default)"> <xsl-file>Location of the XSL file</xsl-file> <!-- CHOICE --> <!-- Next component (Tranformer, Data Reader or Dataset Reader) --> <!-- OR --> <!-- Next Stream Retriever --> </xsl-stream-transformer> a. “xsl-stream-transformer” tag has following property - “convert-stream-to-xml” default false, this should be true when the incoming Stream is not a valid XML. When set the text will be enclosed with <W4N>. b. “xsl-file” relative path of the xsl file which is used for transformation. Example: 1) In this example a stream is passed to xsl file which will reformat the stream and forward to next components. <xsl-stream-transformer> <xsl-file>conf/xsl/parse-auth-tokens.xsl</xsl-file> <!-- CHOICE --> <!-- Next component (Tranformer, Data Reader or Dataset Reader) --> <!-- OR --> <!-- Next Stream Retriever --> </xsl-stream-transformer>
XSL Context Transformer
This Transformer will take an incoming Stream expected to be XML and send it to a XSL file in order extract new properties for the Execution Context. Forcing the conversion to XML is only required when the incoming Stream is not a valid XML. When set the text will be enclosed with <W4N>. Every Execution Context entry will be passed as parameters in the XSL and their name will be normalized in order to be valid (each spaces and dashes will be replaced by an underscore and if the key starts with a digit, it will be prefixed by an underscore). Furthermore, the working directory of the Stream Collector will be passed under the WORKING DIR parameter. The output of the transformation must be one property per line formatted as propertyName=propertyValue.
Template configuration:
<xsl-context-transformer convert-stream-to-xml="true or false (default)">
<xsl-file>Location of the XSL file</xsl-file>
<!-- Optional -->
<release id="ID of the release" />
<!-- Optonal next Stream Retrievers -->
</xsl-context-transformer>
a. “xsl-context-transformer” tag has following property
- “convert-stream-to-xml” default false, this should be true when the incoming Stream is not a valid XML. When set the text will be enclosed with <W4N>.
b. “xsl-file” relative path of the xsl file which is used for transformation.
c. Optional “release” tag can be used if we have to release the execution context data to data-listeners to create rawvalue.
Example:
1) In this example an incoming data is converted in to a context variable.
Input Strem:
<class>
<name>UnitaryComputerSystem</name>
<attribute>Certification</attribute>
<attribute>DisplayName</attribute>
<attribute>Description</attribute>
<relationship>ConnectedVia</relationship>
<relationship>ComposedOf</relationship>
<metric>NumberOfInterfaces</metric>
<metric>NumberOfIPs</metric>
</class>
Transformer:
<xsl-context-transformer>
<xsl-file>conf/xsl/parse-conf-file.xsl</xsl-file>
<!-- Optional -->
<release id="ID of the release" />
<!-- Optonal next Stream Retrievers -->
</xsl-context-transformer>
parse-conf-file.xsl:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="2.0">
<xsl:output method="text" indent="no" name="text"/>
<xsl:template match="/">
<xsl:result-document format="text">
<xsl:for-each select="//class">
<xsl:value-of select = "'ATTRIBUTES='"/>
<xsl:value-of select = "concat('CreationClassName','	')"/>
<xsl:for-each select="./attribute">
<xsl:value-of select = "concat(text(),'	')"/>
</xsl:for-each>
<xsl:value-of select = "'
'"/>
<xsl:value-of select = "'RELATIONSHIPS='"/>
<xsl:for-each select="./relationship">
<xsl:value-of select = "concat(text(),'	')"/>
</xsl:for-each>
<xsl:value-of select = "'
'"/>
<xsl:value-of select = "'METRICS='"/>
<xsl:for-each select="./metric">
<xsl:value-of select = "concat(text(),'	')"/>
</xsl:for-each>
</xsl:for-each>
</xsl:result-document>
</xsl:template>
</xsl:stylesheet>
JSON to XML Transformer
This Transformer takes an incoming JSON Stream and transforms it into an XML stream. The missing XML tags from the JSON stream will be added under generic names with their corresponding index.
{"list":[{"key":"value"}, ["value0", "value1"], "other-value"]} =>
<W4N>
<list>
<OBJECT index="0">
<key>value</key>
</OBJECT>
<ARRAY index="0">
<VALUE index="0">value0</VALUE>
<VALUE index="1">value1</VALUE>
</ARRAY>
<VALUE index="0">other-value</VALUE>
</list>
</W4N>
Template configuration:
<json-to-xml-transformer include-json-name="Optional true or false (default = false)">
<!-- Next components (Tranformers, Data Readers or Stream Retrievers) -->
</json-to-xml-transformer>
a. “json-to-xml-transformer” has following options:
- “include-json-name” default false, will come handy if there’s still a need for the raw element name. Having this attribute will add an attribute jsonname to every generated tag containing the original name. It will significantly increase the size of the resulting Stream so it should be used only when necessary.
Encoding/Decoding Transformer
This Transformer takes the incoming Stream and encode it or decode it to some other form. The available format is base64.
Template configuration:
<encoding-decoding-stream-transformer encode="false"> <base64 /> <!-- Optional next components (Stream Retrievers, Tranformers, Data Readers, Dataset Readers or Conditions) --> </encoding-decoding-stream-transformer> a. “encoding-decoding-stream-transformer” has following option: - “encode” if true will encode the stream else decode.
Stream Merger Transformer
<stream-merger-transformer
include-incoming-stream="true or false (default)">
<merge-output-of>
<!-- Optional list -->
<skip-output-of>Stream Handler name for which the output is not
desired (typically readers)
</skip-output-of>
<!-- List of simple Stream Retrievers or complex chain ending with a StreamRetriever -->
</merge-output-of>
<!-- Next components that will consume the merged stream (Stream Retrievers, Tranformers, Data Readers, Dataset Readers or Conditions) -->
</stream-merger-transformer>
a. “stream-merger-transformer” tag has following options:
- “include-incoming-stream” default false, if true incoming stream is considered for merging.
b. “merge-output-of” the stream generated under this tags are merged.
- “skip-output-of” Any stream handlers whose output should be skipped from using then this tag should be used.
Example:
1) In this example we are merging stream from “static-retriever” and “remote-command”. After merging this merged stream will be forwarded next component in chain.
<stream-merger-transformer>
<merge-output-of>
<static-retriever>
<content>Some static content=</content>
</static-retriever>
<remote-command name="execute remote cmd">
<primary-connection>
<host>@{hostip}</host>
<ssh-connection>
<keyboard-interactive-authentication>
<username>@{username}</username>
<password>@{password}</password>
</keyboard-interactive-authentication>
<session-connection />
</ssh-connection>
</primary-connection>
<commands type="defined">hostname</commands>
</remote-command>
</merge-output-of>
<!-- Next components that will consume the merged stream (Stream Retrievers,Tranformers, Data Readers, Dataset Readers or Conditions) -->
</stream-merger-transformer>
Data Reader
Data Reader are components that will read the incoming Stream in order to extract Execution Context data from it. 1. Text Reader This Data Reader will read the content of the Stream as text character per character until the desired zone if found and then extract Execution Context data from this zone. It can also be used to extract a new Stream by selecting a determined portion of a text. Be aware that until the start of the zone is found, the previous content will be present in memory and more importantly, since the search is done character per character, using this Data Reader to skip the beginning of a text is not a good idea. It should only be used when the desired text is near the beginning of the Stream. Lastly, the delimited zone will also be materialized in memory once found so it must be taken in to account when reading a big portion of a text.
When not using the first choice, all the Stream will be considered as desired and then materialized. Be aware that using a single character regex is far more performant that a complex one. When using multiple character regexes, they will automatically be configured to match complex content (no need to add .* before or after the regex) and the searched characters will also be present in the extracted zone content. Template Configuration:
<text-reader reset-stream-after-used="true or false (default)"> <!-- OPTIONAL CHOICE --> <everything-up-to inclusive="true (default) or false">Ending regex </everything-up-to> <!-- OR --> <start-at>Starting regex</start-at> <!-- CHOICE --> <up-to-end /> <!-- OR --> <end-at-line-end /> <!-- OR --> <end-at inclusive="true (default) or false">Ending regex</end-at> <!-- Optional list --> <extractions pattern="Regex containing groups" extraction-required="true (default) or false flag telling if a failed extraction should be logged or not"> <!-- One or more --> <value group="regex group">new context property name</value> </extractions> <!-- Optional --> <release id="ID of the release" /> <!-- Optional next components (Tranformers, Data Readers, Dataset Readers or Conditions) --> <!-- Optional next Stream Retriever --> </text-reader> a. “text-reader” tag has following options” - “reset-stream-after-used” default false, should be used only when sibling Stream Handling Components must work with the Stream in a different way. b. Optional “everything-up-to” or “start-at” tags can be used to define regex pattern to fetch data. c. “up-to-end” or “end-at-line-end” or “end” tags can be used to define regex pattern to fetch data. d. Optional List “extractions” can be used to extract required fields from matched pattern and update execution context. e. Optional “release” tag is used to release execution context data to data-listener. Examples: 1. In this example we are fetching data which has “NEXT_MARKER” at the beginning and ends with “\n”. We are extracting value after “NEXT_MARKER” and assigning it to execution context variable. <text-reader> <start-at>NEXT_MARKER</start-at> <end-at-line-end /> <extractions pattern="^NEXT_MARKER=(.+)$"> <value group="1">NEXT_VM_MARKER</value> </extractions> <!-- Optional next components (Tranformers, Data Readers, Dataset Readers or Conditions) --> <!-- Optional next Stream Retriever --> </text-reader>
XML Reader
This Data Reader will read the content of the Stream expected to be in XML with some XPath queries in order to extract Execution Context data from this document. Be aware that the whole document must be materialized in order to run the XPath queries and all namespaces are removed. Finally, it’s allowed to use contextualization in the XPath expressions.
Template Configuration:
<xml-reader reset-stream-after-used="true or false (default)"> <!-- One or more --> <extractions xpath-expression="XPath expression" result-type="string, number or node (default)">new context property name</extractions> <!-- Optional --> <release id="ID of the release" /> <!-- Optional next Stream Retrievers or Conditions --> </xml-reader> a. “xml-reader” tag has following option: - “reset-stream-after-used” default false, should be used only when sibling Stream Handling Components must work with the Stream in a different way. b. One or more “extractions” tag is used to extract the xapth value and update it in to execution context. Following options are available with this tag. - “xpath-expression” xpath expression whose value to be fetched - “result-type” default node, will specify what is the expected result type of the XPath query is. When using XSLT functions, it will normally be string or number (the latest will convert the expected result as a decimal value as opposed to String which would output the result as is). When the XPath leads to a normal node inside the document, the default node should be used. c. Optional “release” tag is used to release execution context data to data-listener. Examples: 1) In this example we are fetching context variable data <xml-reader> <extractions xpath-expression="if (/OBJECT/status = 'enabled' and /OBJECT/state = 'up') then (100) else (0)" result-type="string">Availability</extractions> <extractions xpath-expression="/OBJECT/current_workload">CurrentWorkload</extractions> <extractions xpath-expression="/OBJECT/running_vms">RunningVMs</extractions> <extractions xpath-expression="/OBJECT/vcpus">TotalVCpus</extractions> <!-- Optional next Stream Retrievers or Conditions --> </xml-reader>
Dataset Reader
Dataset Reader are components that will read the incoming Stream until a desired dataset start is found in order to send them one by one to the next components. The vision of the next component will only be one (or more depending on the configuration) dataset.
Text Dataset
This Dataset Reader will read the content of the Stream as text character per character until the desired dataset is found and then delegate the Stream reading to the next elements so that no materialization is required.Template Configuration:
<text-dataset parse-datasets-in-parallel="true or false (default)" skip-content-before-first- split="true or false (default)" include-loop-split-in-dataset="true of false (default)"> <loop-on>Dataset regex</loop-on> <!-- Next components (Tranformers, Data Readers, Dataset Readers or Conditions) --> </text-dataset> a. “text-dataset” tag has following options: - “parse-datasets-in-parallel” default false, will allow the subsequent chain of Stream Handling Components to be run in parallel for each dataset. This can be a good way to speed up the chain if the next elements contains other Stream Retriever. Be aware that using this option requires that each parsed dataset to be materialized in memory - “skip-content-before-first-split” default false, will let the Dataset Reader know that the content before the first occurrence of the dataset delimiter should not be considered as a dataset and can simply be dropped. - “include-loop-split-in-dataset” default false, will let the Dataset Reader know that the delimiter should be included in the in the resulting datasets. b. “loop-on” tag is used to define data set regex on which we have to loop on and send it to next components. Example: 1) In this example we are parsing incoming stream upon “\n” an each parsed data is passed to next component separately. <text-dataset> <loop-on>\n</loop-on> <!-- Next components (Tranformers, Data Readers, Dataset Readers or Conditions) --> </text-dataset>
Regex Dataset
This Dataset Reader will read the content of the Stream as text until the desired dataset is found and then delegate the Stream reading to the next elements so that no materialization is required. Unlike the original text-dataset, it doesn’t read the incoming stream character by character and is able to fully understand any regex symbols including the real end of string ($). It also is far more performant, but keep in mind that you need to know the implication of greediness and laziness to make a good use of this component.
Template configuration:
<regex-dataset parse-datasets-in-parallel="true or false (default)" skip-content-before-first- split="true or false (default)" include-loop-split-in-dataset="true of false (default)"> <loop-on>Dataset regex</loop-on> <!-- Next components (Tranformers, Data Readers, Dataset Readers or Conditions) --> </regex-dataset> a. “regex-dataset” tag has following options: - “parse-datasets-in-parallel” default false, will allow the subsequent chain of Stream Handling Components to be run in parallel for each dataset. This can be a good way to speed up the chain if the next elements contains other Stream Retriever. Be aware that using this option requires that each parsed dataset to be materialized in memory - “skip-content-before-first-split” default false, will let the Dataset Reader know that the content before the first occurrence of the dataset delimiter should not be considered as a dataset and can simply be dropped. - “include-loop-split-in-dataset” default false, will let the Dataset Reader know that the delimiter should be included in the in the resulting datasets. b. “loop-on” tag is used to define data set regex on which we have to loop on and send it to next components. Example: 1) In this example regex-dataset will get the required data stream by matching provided regex. <regex-dataset parse-datasets-in-parallel="true" skip-content-before-first-split="true"> <loop-on>NEXT_MARKER.*\n</loop-on> <!-- Next components (Tranformers, Data Readers, Dataset Readers or Conditions) --> </regex-dataset>
XML Dataset
This Dataset Reader will read the content of the Stream as XML content and will delegate the Stream reading to the next elements for each dataset tag so that no materialization is required. Be aware that compared to other XML XPath engine, streaming XPath search are slower when forcing a search from the root (Starting with ’/’). So unless there’s a real restriction for that, it’s recommended to search without restriction (Starting with ’//’ or directly by an element name). Furthermore, no lookahead, backward, index expressions or namespace restriction are supported. However, conjunctive node expressions are supported (expressions separated by ’j’). The only selector that can be used is attributes value comparison on the elements.
Example:
<xpath>/first/second[@attr='value']/third[@isPresent]/fourth[@attr1='value'][@attr2IsPresent]</xpath>
Having datasets that are triggering on the same element will have unpredictable results (only one of them will be triggered). Having overlapping datasets as siblings will have the result of the internal dataset to never actually trigger. When having more than one element per dataset, the wrapping element-name they will used for the tag enclosing the datasets.
Template configuration:
<xml-dataset parse-datasets-in-parallel="true or false (default)"> <!-- One or more --> <datasets element-per-dataset="Optional count of desired element per dataset" wrapping- element-name="Optional wrapping element name" share-extracted-data="true of false (default)" strip-xml-tag="true of false (default)"> <!-- CHOICE --> <xpath>XPATH query to the desired element</xpath> <!-- OR --> <qname namespace-uri="optional namespace URI">Single element name</qname> <!-- Next components (Tranformers, Data Readers, Dataset Readers or Conditions) --> </datasets> </xml-dataset> a. “xml-dataset” tag has following options: - parse-datasets-in-parallel” default false, will allow the subsequent chain of Stream Handling Components to be run in parallel for each dataset. This can be a good way to speed up the chain if the next elements contains other Stream Retriever. Be aware that using this option requires that each parsed dataset to be materialized in memory. b. One or more “datasets” tag is used to define xpath data set to extract data from incoming stream - “element-per-dataset” Optional count of desired element per dataset - “wrapping-element-name” will used for the tag enclosing the datasets. When not defined, <W4N>will be used. - “share-extracted-data” default false, only be used when the dataset is found only once in the input and contains general information that should be extracted for every other dataset (Ex: A XML document containing an information header followed by a list of devices. In this case, the header should be considered as a shared dataset). - “strip-xml-tag” default false, only be used when the dataset is containing text data that will be sent either in a Regex Dataset, Text Dataset, Text Reader or Table Dataset since it will remove all the XML elements, attributes and other reference to keep only the text related content. - “xpath” or “qname” is used to extract the required data • “xpath” is used to define XPATH query to the desired element. • “qname” is used to extract by using element name, an optional “namespace-uri” property can be used to define namespace where to look for the element. Example: 1) In this example xapth “/W4N/hypervisors/OBJECT” is extracted from incoming stream and forwarded to next components <xml-dataset parse-datasets-in-parallel="true"> <datasets> <xpath>/W4N/hypervisors/OBJECT</xpath> <!-- Next components (Tranformers, Data Readers, Dataset Readers or Conditions) --> </datasets> </xml-dataset>
Table Dataset
This Dataset Reader will read the content of the Stream line by line as a form of table (normally CSV) by first searching the table header and then extracting the content of each line.
<table-dataset> <table-start>Regex of the headers line</table-start> <!-- table-end tag is optional --> <table-end>Regex matching the line following the last line of data </table-end> <column-separator skip-empty-columns="true of false (default)">The column separator character</column-separator> <!-- value-quoting tag is optional --> <value-quoting escape="Optional character that is used to escape the value quoting">Character used to determine quoting.</value-quoting> <!-- Optional --> <release id="ID of the release" /> <!-- Optional next components (Conditions or Stream Independant Handlers) --> </table-dataset> a. “table-start” tag is used to define regex of the headerline b. Optional “table-end” tag is used to define regex matching the line following the last line of data c. “column-separator” tag is used to define column separator character - “skip-empty-columns” default false, if true will skip empty columns. Skipping empty columns is required when the input comes in a beautify format with aligned columns normally using a space as separator. d. Optional “value-quoting” tag is used to specify the character used for quoting. The value determines the quoting character, whereas the escape specifies the character to escape the quoting and nullify its effect, most of the time it is the backslash character. For example, defining escape as \and the quoting character as”, will allow fields to look like this: “This field column contains \”quotes\””,”second field”. e. Optional “release” tag is used to release execution context data to data-listener. Examples: 1) In this example we get the values in columns which are tab(	) separated. <table-dataset> <table-start>Availability	avzone	created	device</table-start> <column-separator>	</column-separator> <!-- Optional next components (Conditions or Stream Independant Handlers) --> </table-dataset>
Conditional Filter
Conditional Filter are components that will take a different Stream Handling Components branch depending on an Execution Context properties value or Stream content. In order to make their decision when working on the Execution Context, the Conditional Filter use JEXL expressions. All the current Execution Context properties will be passed in the JEXL context and will be available as variables in the expression. Refer to JEXL Normalization section for the normalization of variables name.
Context Conditional Filter
This Conditional Filter allows you to have different execution path according to some boolean condition. This will use the execution path of the first when condition that matched, and will fall back to the otherwise case if none matched. This is similar to if else condition check in any programming language.
Template Configuration:
<context-conditional-filter>
<!-- One or more -->
<when test="Jexl expression to test against the context variables">
<!-- Optional -->
<release id="ID of the release" />
<!-- Optional next components (Stream Retrievers, Tranformers, Data Readers,
Dataset Readers or Conditions) -->
</when>
<!-- optional fallback case when no condition matched -->
<otherwise>
<!-- Optional -->
<release id="ID of the release" />
<!-- Optional next components (Stream Retrievers, Tranformers, Data Readers,
Dataset Readers or Conditions) -->
</otherwise>
</context-conditional-filter>
a. “when” tag is used to define condition and flow
- “test” Jexl expression to test against the context variables
b. “otherwise” tag is used to define the flow when “when” condition is not satisfied.
Example:
1) In this example we check if URL variable in execution context is empty and starts with “http” before sending a request.
<context-conditional-filter>
<when test="URL != null &&URL.startsWith('http')">
<!-- Optional next components (Stream Retrievers, Tranformers, Data Readers,
Dataset Readers or Conditions) -->
</when>
</context-conditional-filter>
Context Value Iteration
This Conditional Filter will execute a Stream Handling Components branch as long as a condition is met or until the max loop counter is reached. This is same as while loop in programming.
Template configuration:
<context-value-iteration>
<!-- CHOICE -->
<iterator-loop-reference>Reference to an ID of a previously created
Context Value Iteration loop
</iterator-loop-reference>
<!-- OR -->
<id>ID of the Context Value Iteration loop</id>
<!-- Optional -->
<max-loop-counter>Optional max occurrence per context to prevent
infinite loop. Default is 50
</max-loop-counter>
<!-- One or more -->
<while test="Jexl expression to test">
<!-- Next components (Stream Retrievers, Tranformers, Data Readers, Dataset Readers or Conditions) -->
</while>
</context-value-iteration>
a. “iterator-loop-reference” or “id” tags are used to define the iteration
- “iterator-loop-reference” tag is used to define Reference to an ID of a previously created Context Value Iteration loop.
- “id” tag is used to define ID for context value iteration loop
b. Optional “max-loop-counter” tag is used to define Optional max occurrence per context to prevent infinite loop. Default is 50
c. “while” tag is used to define condition of the iteration
- “test” Jexl expression to test
Example:
1) In this example on an incoming stream we check condition for “NEXT_VM_MARKER” if it matches the we process the stream and update the NEXT_VM_MARKER and same loop will be repeated until condition is failed.
<context-value-iteration xmlns="http://www.watch4net.com/Text-Parsing-Configuration" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.watch4net.com/Text-Parsing-Configuration ../textParsingConfiguration.xsd">
<id>GET-OPENSTACK-VMS</id>
<max-loop-counter>100</max-loop-counter>
<while test="NEXT_VM_MARKER != '&marker='">
<!-- Next components (Stream Retrievers, Tranformers, Data Readers, Dataset Readers or Conditions) -->
<text-reader>
<start-at>NEXT_MARKER</start-at>
<end-at-line-end/>
<extractions pattern="^NEXT_MARKER=(.+)$">
<value group="1">NEXT_VM_MARKER</value>
</extractions>
<context-value-iteration>
<iterator-loop-reference>GET-OPENSTACK-VMS</iterator-loop-reference>
</context-value-iteration>
</text-reader>
</while>
</context-value-iteration>
Stream Conditional Filter
This Conditional Filter will skip unwanted lines of a text Stream in a performant way without any processing on them. Each line of the text will be read and discarded until a condition matches.
Template Configuration:
<stream-conditional-filter> <!-- One or more --> <when line-matches="Pattern to match in order to stop the skip"> <!-- Optional next components (Stream Retrievers, Transformers, Data Readers, Dataset Readers or Conditions) --> </when> <!-- optional fallback case when no condition matched --> <otherwise> <!-- Optional condition that will always be true --> <!-- Optional next components (Stream Retrievers, Transformers, Data Readers, Dataset Readers or Conditions) --> </otherwise> </stream-conditional-filter> a. “when” tag is used to define condition and flow - “line-matches” Pattern to match in order to stop the skip. b. “otherwise” tag is used to define the flow when “when” condition is not satisfied.
Custom Stream handling components
There’s an extension available in the Stream Collector to create your own Stream Handling Components. Be aware that it requires a good understanding of Object Oriented Java development and no support will be offered for those Stream Handling Components and using and IDE is recommended. Finally, the class CustomStreamHandlerUtils offer multiple utilities such as parameters parsing to work with you own Stream Handling Components. If the data needs to be released to data-listeners the make sure the overridden function “isReleaserSupported” should return true. Following is the skeleton for same:
public class <The name of your Stream Handler> extends AbstractSimpleStreamHandler<CustomStreamHandlerConfig> implements<either StreamRetriever, DataReader, ConditionalHandleror Transformer>{
/**
* Constructor.
*
* @param config
* The handler configuration
* @param environmentSettings
* The environment settings
* @throws StreamHandlerException
* Error during configuration
*/
public<The name of your Stream Handler>(CustomStreamHandlerConfig config, EnvironmentSettings environmentSettings)throws StreamHandlerException
{
super(config, environmentSettings);
// Rest of the configuration. Stream Handlers are meant to be stateless since they are used in a multithreaded environment!
}
/**
* Execute a step of the StreamHandler.
*
* @param step
* The incoming StreamHandlerStep info
* @return The resulting StreamHandlerStep. The following behavior must be respected:
* <ul>
* <li>
* Returning null is only allowed for a ForkingStreamHandler when no more fork
* is available. Any other StreamHandler will generate StreamHandlerJob
* error if producing a null StreamHandlerStep.
* <li>
* Returning a StreamHandlerStep with a null Stream is allowed but will
* * generate errors if the next StreamHandler is not a StreamIndependantHandler.</li>
* </ul>
* @throws StreamHandlerException
* Error
*/
public StreamHandlerStep execute(StreamHandlerStep step) throws StreamHandlerException {
// The work is done here. Carefull to not leak. If some resources are created (files,
//processes, connections, ...), they must be set as execution data or sharable resources in the
//execution!
}
/**
* Validate that the uncontextualizable fields aren't configured with context reference.
*
* @param config
* The handler configuration
* @throws StreamHandlerException
* Presence of contextualized fields
*/
protected void validateUncontextualizableFields(CustomStreamHandlerConfig config) throws
StreamHandlerException {
// Just to verify from the start if some non contextualizable fields contains contexts
//references
}
}
Finally, here’s how to use your custom Stream Handling Components in the configuration
<custom-stream-handler>
<class>Fully qualified class name</class>
<single-params key="paramName">param value</single-params>
<multiple-params key="paramsName">
<value>value1</value>
<value>value2</value>
</multiple-params>
<!-- Next Elements -->
</custom-stream-handler>
a. “class” Fully qualified custom class name
b. “single-params” or “multiple-params” to pass the arguments to custom stream handler.
Example:
1) In this example we are calling a function on smarts server using http query, and process the data which is in some proprietary format.
Following is the Java code:
public class SmartsFastDXATransformer extends AbstractSimpleStreamHandler<CustomStreamHandlerConfig> implements DataReader{
public static String UNIQUE_PREFIX = "~@|";
public static String PROP_TAG = "+";
public static String REL_TAG = "~@R";
public static String METRIC_TAG = "~@M";
public SmartsFastDXATransformer(CustomStreamHandlerConfig config,
EnvironmentSettings environmentSettings) throws StreamHandlerException {
super(config, environmentSettings);
}
/**
* {@inheritDoc}
*/
@Override
protected void validateUncontextualizableFields(CustomStreamHandlerConfig config) throws StreamHandlerException {
// TODO Auto-generated method stub
}
/**
* {@inheritDoc}
*/
@Override
protected StreamHandlerStep execute(StreamHandlerStep step) throws StreamHandlerException {
ExecutionContext context = step.getExecution().getContext();
String props = "Name\t"+context.getContextValue("ATTRIBUTES");
String relations = context.getContextValue("RELATIONSHIPS");
String metrics = context.getContextValue("METRICS");
String[] propNames = props.split("\t");
String[] relNames = null;
String[] metricNames = null;
if ("".equals(relations)) {
relNames = new String[0];
}
else {
relNames = relations.split("\t");
}
if ("".equals(metrics)) {
metricNames = new String[0];
}
else {
metricNames = metrics.split("\t");
}
String line = step.getStream().toTextStream().getText();
//System.out.println(line);
String[] propValues = line.split("\t");
//Update attributes to context
int i = 0;
for (String propName : propNames) {
String propVal = "";
if (propValues[i].contains(UNIQUE_PREFIX)) {
propVal = propValues[i].substring(propValues[i].indexOf(UNIQUE_PREFIX)+4);
} else {
propVal = propValues[i];
}
StringBuilder parmaData = new StringBuilder();
if ("CreationClassName".equals(propName)) {
parmaData.append("CreationClassName");
} else {
//Marking as dynamic property
parmaData.append(PROP_TAG+propName);
}
parmaData.append("="+propVal);
StreamHandlerUtils.updateContext(step.getExecution(), parmaData.toString());
//System.out.println(parmaData);
i++;
}
//Update Relationships to context
for (String relName : relNames) {
String relMeta = propValues[i];
int relCount = Integer.valueOf(relMeta.substring(relMeta.indexOf(UNIQUE_PREFIX) + 4));
i++;
if (relCount > 0) {
//Marking as Dynamic relationship
StringBuilder parmaData = new StringBuilder(REL_TAG+relName+"= ");
for (int j = 0; j < relCount; j++) {
parmaData.append(propValues[i]+"|");
i++;
}
StreamHandlerUtils.updateContext(step.getExecution(), parmaData.toString());
//System.out.println(parmaData);
}
}
//Update Metric to context
for (String metricName : metricNames) {
String metricVal = "";
if (propValues[i].contains(UNIQUE_PREFIX)) {
metricVal = propValues[i].substring(propValues[i].indexOf(UNIQUE_PREFIX)+4);
} else {
metricVal = propValues[i];
}
StringBuilder metricData = new StringBuilder();
//Marking as dynamic property
metricData.append(METRIC_TAG+metricName);
metricData.append("="+metricVal);
StreamHandlerUtils.updateContext(step.getExecution(), metricData.toString());
//System.out.println(parmaData);
i++;
}
super.releaseData(step.getExecution());
return new StreamHandlerStep(step.getExecution());
}
/**
* {@inheritDoc}
*/
@Override
@SuppressWarnings("unchecked")
public Class<? extends AbstractConfigBasedStreamHandler<?>>[] getSupportedNextElements() {
return (Class<? extends AbstractConfigBasedStreamHandler<?>>[]) new Class<?>[] { SmartsFastDXATransformer.class };
}
/**
* {@inheritDoc}
*/
// This should be true if we are releasing data from this handler
@Override
protected boolean isReleaserSupported(CustomStreamHandlerConfig config) {
return true;
}
}
Following is the xml configuration:
<custom-stream-handler>
<class>com.emc.custom.SmartsFastDXATransformer</class>
<!-- Next Elements -->
</custom-stream-handler>
End to end use case example:
In this section let us take a use case from stream collector and build entire flow for a Cisco ACI setup.
Create templates for the following in the collector-package/templates directory
-
collector-manager
-
conf
-
Collecting.xml.ftl
-
unix-service.properties.ftl
-
-
-
kafka-connector
-
conf
-
kafka-connector.xml.ftl
-
-
-
stream-collector
-
requests
-
aci-bd-epg.xml.ftl
-
aci-bridge-domain.xml.ftl
-
aci-bridge-domain-health.xml.ftl
-
aci-card-port.xml.ftl
-
aci-cards.xml.ftl
-
aci-chassis.xml.ftl
-
aci-chassis-health.xml.ftl
-
aci-contract.xml.ftl
-
aci-contract-cons-epg.xml.ftl
-
-
aci-discover-requests.xml.ftl
-
aci-fabric-monitor.xml.ftl
-
aci-port-monitor.xml.ftl
-
context-aci.xml.ftl
-
discovery-cisco-aci.xml.ftl
-
metric-cisco-aci.xml.ftl
-
monitoring-cisco-aci.xml.ftl
-
-
variable-handling-filter
-
conf
-
vhf-aci.xml
-
vhf-property-refactor.xml
-
-
-
Config.json - sample json for input
-
Config_input_schema.json- json schema for collector input.
Create the following files in the collector-package directory
-
meta_en.properties - metadata info for the Collectors.
-
questions.txt - defined user configured parameters for the collectors
-
questions_en.properties-- display values / description for Questions.txt
-
spb.properties-- versions and dependent modules along with respective versions
-
default.txt -default values for user configurable parameter
The Required Files Examples are available in the SDK under Example Directory - examples/custom_stream.
