









ETSI classifies NFV workloads into three categories: management, control, and data plane. Based on experience deploying vCloud NFV in various CSP networks, data plane workloads are further divided into intensive workloads, and workloads that behave as management and control plane workloads. The latter class of data plane workloads have been proven to function well on the vCloud NFV platform, as has been described in this reference architecture. Further information regarding these workloads is provided in the VNF Performance in Distributed Deployments section of this document. For data plane intensive VNFs hosted on the vCloud NFV platform, specific design considerations are provided in the following section of this document.
ETSI classifies NFV workloads into three categories: management, control, and data plane. Based on experience deploying vCloud NFV in various CSP networks, data plane workloads are further divided into intensive workloads, and workloads that behave as management and control plane workloads. The latter class of data plane workloads have been proven to function well on the vCloud NFV platform, as has been described in this reference architecture. Further information regarding these workloads is provided in the VNF Performance in Distributed Deployments section of this document. For data plane intensive VNFs hosted on the vCloud NFV platform, specific design considerations are provided in the following section of this document.
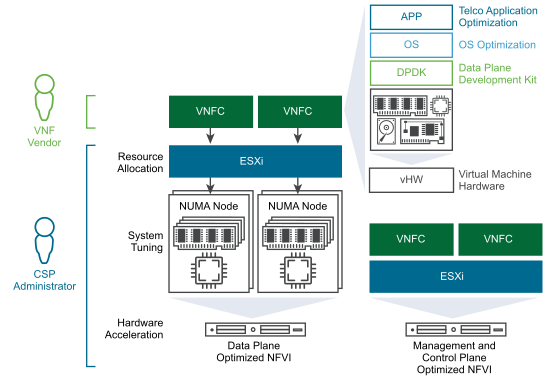
Data Plane Intensive Design Framework
Two parties are involved in the successful deployment and operations of a data plane intensive VNF: the VNF vendor and the NFVI operator. Both parties must be able to understand the performance requirements of the VNF, and share an understanding of the VNF design. They must also be willing to tune the entire stack from the physical layer to the VNF itself, for the demands data plane intensive workloads place on the system. The responsibilities of the two parties are described as follows:
Virtual Network Function Design and Configuration. The vendor supplying the VNF is expected to tune the performance of the VNF components and optimize their software. Data plane intensive workloads benefit from the use of a Data Plane Development Kit (DPDK) to speed up VNFC packet processing and optimize the handling of packets off loading to the virtual NIC. Use of the VMware VMXNET3 paravirtualized network interface card (NIC) is a best practice VNF design for performance demanding VNFs. VMXNET3 is the most advanced virtual NIC on the VMware platform and has been contributed to the Linux community, making it ubiquitous in many Linux distributions.
Once the VNF is created by its supplier, there are several VNFC level configurations that are essential to these types of workloads. Dedicated resource allocation, for the VNFC and the networking-related processes associated with it, can be configured and guaranteed through the use of two main parameters: Latency Sensitivity and System Contexts. Both parameters are discussed in detail in a separate white paper.
Another aspect essential to the performance of a data plane intensive VNF is the number of virtual CPUs required by the VNFC. Modern multiprocessor server architecture is based on a grouping of resources, including memory and PCIe cards, into Non-Uniform Memory Access (NUMA) nodes. Resource usage within a NUMA node is fast and efficient. However, when NUMA boundaries are crossed, due to the physical nature of the QPI bridge between the two nodes, speed is reduced and latency increases. VNFCs that participate in the data plane path are advised to contain the virtual CPU, memory, and physical NIC associated with them to a single NUMA node for optimal performance.
NFVI Design Considerations. Once the VNFs are tuned for performance, the underlying physical and virtual infrastructure must be prepared with data plane intensive workloads in mind. The modular nature of the vCloud NFV platform facilitates the construction of an NFVI aimed at data plane intensive workloads, while still using the same VIM and FCAPS components used elsewhere in the architecture. The same VIM and FCAPS components are employed for the building of a data plane intensive NFVI and in the governing of management and control plane VNFs.
Data plane intensive VNFs tend to serve a central role in a CSP network: as a Packet Gateway in a mobile core deployment, a Provider Edge router (PE) in an MPLS network, or a media gateway in an IMS network. As a result, these VNFs are positioned in a centralized location in the CSP network: the data center. With their crucial role, these VNFs are typically static and are used by the central organization to offer services to a large customer base. For example, a virtualized Packet Gateway in a mobile core network will serve a large geographical region as the central termination point for subscriber connections. Once the VNF is deployed, it is likely to remain active for a long duration, baring any NFVI life cycle activities such as upgrades or other maintenance.
This aggregation role translates into a certain sizing requirement. The VNFs must serve many customers, which is the reason for their data plane intensive nature. Such VNFs include many components to allow them to be scaled and managed. These components include at a minimum an OAM function, packet processing functions, VNF-specific load balancing, and often log collection and monitoring. Individual components can also require significant resources to provide large scale services.
The central position of these VNFs, their sizeable scale, and their static nature, all suggest that dedicated resources are required to achieve their expected performance goals. These dedicated resources begin with hosts using powerful servers with high performing network interface cards. The servers are grouped together into a cluster that is dedicated to data plane intensive workloads. Using the same constructs introduced earlier in this document, the data plane intensive cluster is consumed by vCloud Director and is made into a PvDC. VNFs are then onboarded into the vCloud Director catalog for deployment.
To be able to benefit from virtual machine specific configuration such as Latency Sensitivity, the allocation model configured for use by tenants in the data plane intensive workload OvDC is Reservation Pool. The Reservation Pool allocation model allows VNFs to be configured with the CPU reservation set to maximum, removing any CPU usage limits. The same applies to the memory reservation and limit. Both configurations are prerequisites to using the Latency Sensitivity feature, which is the prerequisite for using the System Contexts feature.
NUMA affinity is ensured by combining VNFC specific configuration and the distributed resource scheduler, vSphere DRS. The NUMA affinity parameter should be configured in the Virtual Machine Advanced Parameters. Then, with the use of VM anti-affinity rules, vSphere DRS will place the virtual machines into an empty NUMA node.
With the architecture provided in this section, data plane intensive workloads are ensured the resources they require, to benefit from platform modularity while meeting carrier grade performance requirements. Specific configuration and VNF design guidelines are detailed in a performance white paper on the subject.
VNF Performance in Distributed Deployments
Much networking industry discussion is centered around distributed NFV deployments, in preparation for 5G mobile communications and supporting NFV use cases for SD-WAN and virtual CPE. In such cases, the NFVI must have a minimal footprint since the telecommunications point of presence (POP), or the enterprise, is constrained in rack space, cooling space, and power. In such use cases, achieving the most performance out of a limited set of resources is imperative to meet service quality requirements and maintain the cost efficiency of the service.
The same recommendations provided in the Data Plane Intensive Design Framework section of this document are also applicable to such distributed deployments. With the data plane performance oriented configurations described previously, VNF components can be tuned to deliver optimal traffic forwarding. Due to the limited resources available in such scenarios, it is imperative that the VNF is also designed for such deployments, providing a distributed architecture that places the applicable function close to the subscriber and aggregates other functions in central locations.
