









You can control the behavior of the ESXi hosts and virtual machines during the remediation process. You can create a global remediation policy that applies to all clusters and standalone hosts in a vCenter Server instance. You can also set a remediation policy to a specific cluster and a standalone host.
When you run cluster and standalone host compliance checks, the Coordinator module runs a series of checks on each host to determine their state and whether some additional actions must be taken to ensure the success of the remediation operation. In case one or more hosts in the cluster and any of the standalone hosts are evaluated as non-compliant, additional checks are run on those hosts to evaluate whether they must be rebooted or put into maintenance mode. Currently, VMware provides a set of behavior controls (remediation policies) regarding the virtual machines and the hosts in a cluster or a standalone host. This set of remediation policies might change with the next vSphere release.
How Remediation Policies Overrides Work
The vSphere Lifecycle Manager provides a default global policy configuration that must be applied on each cluster and standalone host during remediation. Through the vSphere Automation REST API, you can change the global policies and create some cluster-and host-specific policies. Before remediating a cluster and standalone host, you can use the API to determine the effective global and cluster-and host-specific remediation policies. The following graphic describes how the mechanism of the policy overrides works.
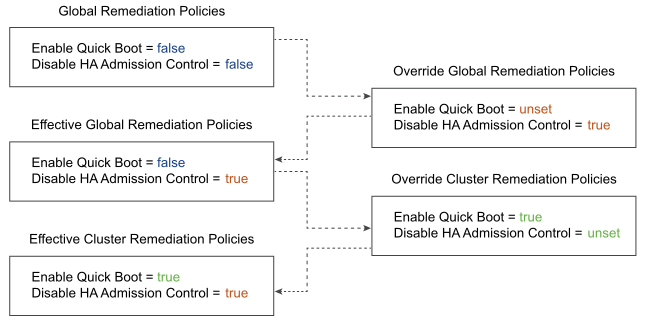
All clusters and standalone hosts in a vCenter Server instance inherit the default or the overridden global policy settings unless the global policy is explicitly overridden on a cluster and host level.
Editing Global or Cluster- and Host-Specific Remediation Policies
To view the currently set global remediation policy, use the GET https://<vcenter_ip_address_or_fqdn>/api/esx/settings/defaults/clusters/policies/apply or GET https://<vcenter_ip_address_or_fqdn>/api/esx/settings/defaults/hosts/policies/apply request. You receive a Apply.ConfiguredPolicySpec data structure that contains the settings of the global remediation policy. To edit a global remediation policy, use the PUT https://<vcenter_ip_address_or_fqdn>/api/esx/settings/defaults/clusters/policies/apply or PUT https://<vcenter_ip_address_or_fqdn>/api/esx/settings/defaults/hosts/policies/apply request and submit the respective Apply.ConfiguredPolicySpec data structure to define new values to the global policy settings. To view the effective global remediation policy settings for a cluster and host, use the GET https://<vcenter_ip_address_or_fqdn>/api/esx/settings/defaults/clusters/policies/apply/effective or GET https://<vcenter_ip_address_or_fqdn>/api/esx/settings/defaults/hosts/policies/apply/effective request. You receive the respective Effective.EffectivePolicySpec JSON object that contains the effective global policies applicable for all clusters and hosts in your vCenter Server environment.
To view the cluster- and host-specific remediation policies, use the GET https://<vcenter_ip_address_or_fqdn>/api/esx/settings/clusters/<cluster_id>/policies/apply or GET https://<vcenter_ip_address_or_fqdn>/api/esx/settings/hosts/<host_id>/policies/apply request. You receive an Apply.ConfiguredPolicySpec JSON object that contain the cluster- and host-specific policies to be applied during remediation. To change the cluster- and host-specific policy, use the PUT https://<vcenter_ip_address_or_fqdn>/api/esx/settings/clusters/<cluster_id>/policies/apply or PUT https://<vcenter_ip_address_or_fqdn>/api/esx/settings/hosts/<host_id>/policies/apply request and submit anApply.ConfiguredPolicySpec data structure to describe the cluster- and host-specific remediation policies. To view the effective cluster- and host-specific policies, use the GET https://<vcenter_ip_address_or_fqdn>/api/esx/settings/clusters/<cluster_id>/policies/apply/effective or GET https://<vcenter_ip_address_or_fqdn>/api/esx/settings/hosts/<host_id>/policies/apply/effective request. You receive the respective Effective.EffectivePolicySpec data structure that describes the effective cluster- and host-specific policies.
Remediation Policy Options for Clusters
| Property | Description |
|---|---|
| disable_dpm | Deactivate the VMware Distributed Power Management (DPM) feature for all clusters or for a specific cluster. DPM monitors the resource consumption of the virtual machines in a cluster. If the total available resource capacity of the hosts in a cluster is exceeded, DPM powers off (or recommends powering off) one or more hosts after migrating their virtual machines. When resources are considered underutilized and capacity is needed, DPM powers on (or recommends powering on) hosts. Virtual machines are migrated back to these hosts. During the cluster remediation, the vSphere Lifecycle Manager cannot wake up and remediate hosts that are automatically put into a stand-by mode by DPM. These hosts stay non-compliant when DPM turns them on. The vSphere Distributed Resource Scheduler (DRS) is unable to migrate virtual machines to the hosts which are not remediated with the desired state for the cluster. To deactivate DPM during the cluster remediation, set true to the disable_dpm property. By default, the vSphere Lifecycle Manager temporarily deactivates DPM and turns on the hosts to complete the remediation. DPM is enabled again when the cluster remediation finishes. |
| disable_hac | Deactivate the vSphere HA admission control. vSphere HA uses admission control to ensure that a cluster has sufficient resources to guarantee the virtual machines recovery when a host fails. If vSphere HA admission control is enabled during remediation, putting a cluster into maintenance mode fails because vMotion cannot migrate virtual machines within the cluster for capacity reasons. To allow the vSphere Lifecycle Manager to temporary deactivate vSphere HA admission control, set true to the disable_hac property. By default, the vSphere HA admission control is enabled because DRS should be able to detect issues with the admission control and deactivate it to allow the remediation to complete. |
| evacuate_offline_vms | Migrate the suspended and powered off virtual machines from the hosts that must enter maintenance mode to other hosts in the cluster. To enable this remediation policy, set true to the evacuate_offline_vms property. By default, this setting is deactivated in the global remediation policy. |
| failure_action | Specify what actions vSphere Lifecycle Manager must take if a host fails to enter maintenance mode during the remediation. To configure this policy on a global or cluster-specific level, set the properties of the Apply.FailureAction data structure. You can set the number of times that vSphere Lifecycle Manager tries to put a host into maintenance mode and the delay between the tries. When the threshold is reached and the host failed to enter maintenance mode, the cluster remediation fails. By default, vSphere Lifecycle Manager tries to put a host into maintenance mode three times with a five minute delay between each try before the cluster remediation fails. |
| enforce_hcl_validation | Prevents the remediation of vSAN clusters if vSphere Lifecycle Manager reports hardware compatibility issues during the hardware compatibility check performed as part of the remediation pre-check or the remediation tasks of the cluster.If you leave the enforce_hcl_validation property unset, detected hardware issues are reported as warnings and do not prevent the remediation of the vSAN cluster. |
| parallel_remediation_action | Enable simultaneous remediation of all hosts that are in maintenance mode with in the cluster. Submit the Apply.ParallelRemediationAction data structure to indicate the maximum number of hosts that can be remediated in parallel.
Note: If the hosts have
NSX virtual distributed switches that are ready to be migrated to vSphere Distributed Switches, you must manually set the maximum number of parallel remediations to no more than 4. In cases when host switch migration is needed, if more than 4 hosts are remediated in parallel, the remediation might fail, because the host switch migration takes more time than the time
vSphere Lifecycle Manager needs to complete the parallel remediation.
|
| pre_remediation_power_action | Specify how the power state of the virtual machines must change before the host enters maintenance mode. If DRS is not enabled on a cluster or the automation level of a DRS cluster is not set to fully automated, the Coordinator module fails to remediate the cluster if the remediation requires a reboot or maintenance mode. You can set a policy that powers off or suspends the virtual machines on hosts that must be rebooted or must enter maintenance mode during remediation. The DRS takes care of changing the power state of the virtual machines when the host enters and exits maintenance mode.
To set a policy for the power state of the virtual machines during the remediation,
submit the Apply.ConfiguredPolicySpec.PreRemediationPowerAction enumerated type and set one of the following values:
|
| enable_quick_boot | Reduce the reboot time of an ESXi host by skipping all the hardware initialization processes and restarting only the hypervisor. This policy is applicable only if the host platform supports the Quick Boot feature. To enable the Quick Boot feature on the hosts during the remediation, set true to the enable_quick_boot property. By default, this policy is deactivated. |
Remediation Policy Options for Standalone Hosts
| Property | Description |
|---|---|
| enable_quick_boot | Optimize the host patching and upgrade operations by reducing the reboot time of an ESXi host. Since the patching and upgrading operations do not affect the hardware of the host, the hardware initialization processes can be skipped. This policy is applicable only if the host platform supports the Quick Boot feature. For more information about which hosts are Quick Boot compatible, see the following KB article https://kb.vmware.com/s/article/52477. |
| pre_remediation_power_action | Specify how the power state of the virtual machines must change before the standalone host enters maintenance mode. You can choose between the following power actions:
|
| failure_action | Specify what actions vSphere Lifecycle Manager must take if a standalone host fails to enter maintenance mode during the remediation. You can set the number of times that vSphere Lifecycle Manager tries to put a standalone host into maintenance mode and the delay between the tries. When the threshold is reached and the standalone host failed to enter maintenance mode, the host remediation fails. |
