









For implementation reasons, a virtual machine tracks CPU and memory resources slightly differently. CPU resources, including NUMA, indicate virtualization overhead, shown with vm. prefix. Memory resources are broken out by guest memory, shown with guest. prefix, and by overhead memory, with ovhd. prefix. Future implementations may add additional metrics.
This example shows various CPU and memory statistics:
$ vmware-toolbox-cmd stat raw text resources vm.cpu.reserved = 4798 vm.cpu.limit = 11995 vm.cpu.used = 224057517 vm.cpu.contention.cpu = 65606184 vm.cpu.contention.mem = 1488848 vm.numa.local = 1837248 vm.numa.remote = 0 guest.mem.reserved = 204800 guest.mem.limit = 1536000 guest.mem.mapped = 1810144 guest.mem.consumed = 1521680 guest.mem.swapped = 3236 guest.mem.ballooned = 27104 guest.mem.swapIn = 3416 guest.mem.swapOut = 6588 ovhd.mem.swapped = 0 ovhd.mem.swapIn = 0 ovhd.mem.swapOut = 0
vm.cpu.reserved – (static) MHz of current CPU type reserved. Covers all virtual CPU plus overheads, so for example a 2 virtual CPU machine would need 2x host.cpu.processorMHz to be fully reserved. Overheads are insignificant except during transient conditions such as taking a backup snapshot or during a vMotion. Default 0.
vm.cpu.limit – (static) MHz that the virtual machine will not exceed. Default –1 means unlimited.
vm.cpu.used – (cumulative) microseconds of CPU time used by this virtual machine. Equivalent to esxtop %USED. See Comparison to esxtop for details.
vm.cpu.contention.cpu = (cumulative) CPU time the virtual machine could have run, but did not run due to CPU contention. This metric includes time losses due to hypervisor factors, such as overcommit. Specific sources of contention vary widely from release to release. See Comparison to esxtop for details about calculating CPU contention.
vm.cpu.contention.mem – (cumulative) CPU time the virtual machine could have run, but did not run due to memory contention. This metric includes losses due to swapping. Equivalent to esxtop %SWPWT.
vm.numa.local – (instantaneous) KB of memory currently local, sum across the VM’s NUMA nodes.
vm.numa.remote – (instantaneous) KB of memory currently remote, sum across the VM’s NUMA nodes.
guest.mem.reserved – (static) KB of memory reserved for the guest OS. This indicates memory that will never be ballooned or swapped. Default is 0.
guest.mem.limit – (static) KB of memory the guest must operate within. Default –1 means unlimited.
guest.mem.mapped – (instantaneous) KB of memory currently mapped into the guest; that is, memory the guest can access with zero read latency. This metric represents memory use from a guest perspective.
guest.mem.consumed – (instantaneous) KB of memory used to provide current mapped memory. This might be lower than mapped due to ballooning, memory sharing, or future optimizations. This metric represents memory use from a host perspective. The difference between guest.mem.mapped and guest.mem.consumed is additional memory made available due to hypervisor optimizations.
guest.mem.swapped – (instantaneous) KB of memory swapped to disk. A fully reserved virtual machine should never see memory swapped out in steady-state usage. Transient conditions, such as resume from memory-included snapshot, might show some swap usage.
guest.mem.ballooned – (instantaneous) KB of memory deliberately copied on write (COWed) to zero in the guest OS, to reduce memory usage.
guest.mem.swapIn – (cumulative) KB of memory swapped in for the current session.
guest.mem.swapOut – (cumulative) KB of memory swapped out for the current session.
ovhd.mem.swapped – (instantaneous) KB of overhead memory currently swapped.
ovhd.mem.swapIn – (cumulative) KB of overhead memory swapped in for the current session.
ovhd.mem.swapOut – (cumulative) KB of overhead memory swapped out for the current session.
Expected values for some of the statistics:
vm.cpu.contention.mem – usually < 1%, anything greater indicates memory overcommit.
vm.cpu.contention.cpu – < 5% of incremental time during undercommit, < 50% of incremental time at normal levels of overcommit (vSphere is tuned to perform best when somewhat overcommitted).
When contention is < 5%, performance will be deterministic but the host is not fully used.
When contention is between 5% and 50%, the host is becoming fully used (maximum CPU throughput) but individual virtual machines might see less deterministic performance.
vm.numa.local – Expected to match guest.memory.mapped. Transient conditions such as NUMA rebalance can cause this to temporarily decrease, then return to normal as memory is migrated.
vm.numa.remote – Expected to be approximately zero in non-overcommitted scenarios.
guest.mem.mapped – Expected to equal configured guest memory; might be smaller if virtual machine has yet to access all its memory.
guest.mem.consumed – Expected to be approximately equal to configured guest memory; will be smaller if host memory is overcommitted.
guest.mem.swapped – Expected to be zero. Non-zero indicates non-graceful memory overcommit.
guest.mem.ballooned – Expected to be zero. Non-zero indicates graceful memory overcommit.
ovhd.mem.swapped – Expected to be zero. Non-zero indicates memory overcommit.
Equations for CPU and memory metrics:
session uptime = vm.cpu.used + vm.cpu.contention.cpu + vm.cpu.contention.mem + CPU idle time
configured memory size = guest.mem.mapped + guest.mem.swapped + (memory not yet touched)
configured memory size = vm.numa.local + vm.numa.remote (another formula for arriving at the same statistic above)
guest.mem.mapped = guest.mem.consumed + guest.mem.ballooned + (other copy-on-write sources)
Comparison to esxtop
Individual reasons for lack of vCPU progress are available to vSphere administrators (using either esxtop or the vSphere API) but are hidden from the guest OS to preserve isolation between the virtual machine and the configuration of the infrastructure it runs upon. The guest OS sees only an aggregate metric.
vm.cpu.used is equivalent to the esxtop statistic %USED for a virtual machine.
vm.cpu.contention.cpu is equivalent to (%RDY – %MLMTD) + %MLMTD + %CSTP + %WAIT + (%RUN – %USED)
(%RDY – %MLMTD) represents time the guest OS could not run due to host CPU overutilization. Note that %RDY includes %MLMTD, which is why it is subtracted before being added.
%MLMTD represents time the guest OS did not run due to administrator-configured resource limits. ESXi 6.0 and earlier did not add %MLMTD to this computation, but this is fixed in ESXi 6.5.
%CSTP represents time the guest OS could not run due to uneven vCPU progress.
%WAIT represents time the guest OS could not run due to hypervisor overheads.
(%RUN – %USED) corrects for any frequency scaling of the host CPU.
vm.cpu.contention.mem is equivalent to %SWPWT.
See https://communities.vmware.com/docs/DOC-9279 for details about esxtop.
Note on nominal CPU speed and CPU metrics
The host.cpu.processorMHz metric (in the host section) reports a nominal speed, and the virtual machine CPU metrics are normalized to the processorMHz metric. Actual processor speed might be higher or lower depending on host power management.
A virtual machine can see vm.cpu.used exceed wall clock time due to Turbo Boost, or can see vm.cpu.used lag wall clock time due to power saving modes used in conjunction with idle guests. Actual processor speed is not available to the guest OS, but is expected to be close to nominal clock speed when the guest OS is active. See http://www.vmware.com/files/pdf/techpaper/hpm-perf-vsphere55.pdf for more information about vSphere host power management.
Normalizing CPU metrics to nominal CPU speed allows the guest OS to avoid dependence on host power management settings.
Note on vm.cpu.contention.cpu
Using the Extended Guest Statistics discussed in this section, you can obtain a contention ratio by comparing contention time to actual time for a particular time interval. As contention time is reported as a sum across VCPUs, and wall time is reported for the entire virtual machine, the wall time must be scaled up by the number of VCPUs to normalize contention to a 0-100% range.
Contention% = 100 * (contention_T2 – contention_T1) / (VCPUs * (time_T2 – time_T1))
The vm.cpu.contention.cpu metric is similar to “stolen time” returned by VMGuestLib_GetCpuStolenMs (see Accessor Functions for Virtual Machine Data), except “stolen time” excludes time the virtual machine did not run due to configured resource limits. Comparing this value to esxtop requires denormalizing the contention ratio, because esxtop reports a sum of percentages across VCPUs. So:
((%RDY – %MLMTD) + %MLMTD + %CSTP + %WAIT + (%RUN – %USED)) ~= Contention% * VCPUs
Due to sample aliasing where in-guest time samples and esxtop time samples do not occur simultaneously, instantaneous esxtop values will not match instantaneous in-guest statistics. Longer time samples or averaging values collected over time will produce more comparable results.
A contention value of < 5% is normal “undercommit” operating behavior, representing minor hypervisor overheads. A contention value > 50% is “excess overcommit” and indicates CPU resource starvation – the workload would benefit from additional CPUs or migrating virtual machines to different hosts. A contention value between 5% and 50% is “normal overcommit” and is more complicated. The goal of this metric is to allow direct measurement of the performance improvement that can be obtained by adding CPU resources.
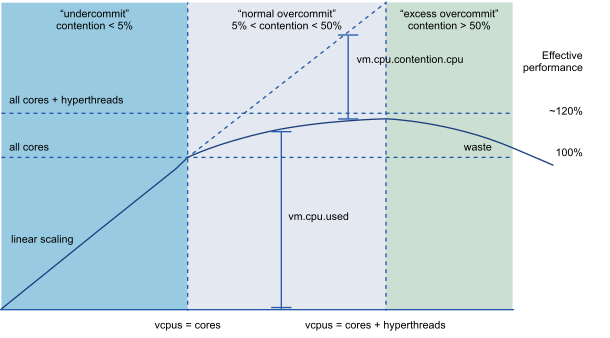
VMware best practices describe the available CPU capacity of an ESXi host as equal to the number of cores (not including hyperthreads). A 16 core host with 2.0GHz processors has 16 cores * 2000 MHz/core = 32000 MHz available compute capacity. When actual usage is below that calculated capacity, the hypervisor is considered “under committed” – the hypervisor is scaling linearly with load applied, and is wasting capacity.
As actual usage exceeds available compute capacity, the hypervisor begins utilizing hyperthreads for running virtual machines to keep performance degradation graceful. Maximum aggregate utilization occurs during this “normal overcommit” (between 5% and 50% contention) where each virtual machine sees somewhat degraded performance but overall system throughput still increases. In this “normal overcommit” region, adding load still improves overall efficiency, though at a declining rate. Eventually, all hyperthreads are fully used. Efficiency peaks and starts to degrade; this “excess overcommit” (>50% contention) indicates the workload would be more efficient if spread across more hosts for better throughput.
One specific scenario deserves special mention: the “monster VM” that attempts to give a single VM all available compute capacity. A VM configured to match the number of host cores (not including hyperthreads) will peak at the capacity of those cores (with < 5% contention) but at a performance about 20% lower than an equivalent physical machine utilizing all cores and hyperthreads. A VM configured to match the number of host threads (2x host cores) will peak at a performance level more analogous to a physical machine, but will show about 40% contention (the upper end of “normal overcommit”) running half the cores on hyperthreads. This contention metric indicates the load would run better on a larger host with additional cores, so it is technically “overcommitted” even though performance is better than a hypervisor running at full commit. This behavior is expected when attempting to run maximally sized virtual machines.
