









With the introduction of continuous availability in vRealize Operations 8, there have been several frequently asked questions. This section is to help increase awareness and knowledge about continuous availability.
- How is the data stored in analytics nodes?
-
When an object is discovered, vRealize Operations determines which node to keep the data, then copies (duplicates) the data to its pair node in the other fault domain. Every object is stored in two analytics nodes (node pairs) across the fault domains and they are always synchronized.
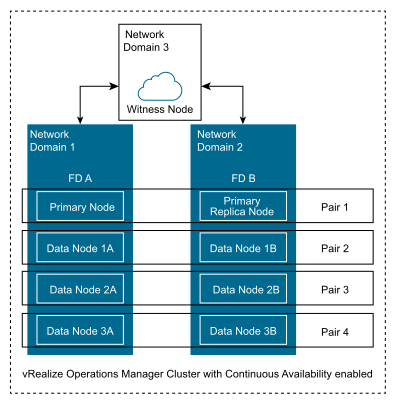
As an example, vRealize Operations has eight analytics nodes, CA is enabled, and as a result each fault domain has four analytics nodes (see above diagram).
When a new object is discovered, vRealize Operations decides to store the data in “Data Node 2B” (primary) and automatically a copy of the data will be saved in “Data Node 2A” (secondary).
If somehow “FD A” becomes unavailable, then “primary” data from “Data Node 2B” will be used.
If somehow “FD B” becomes unavailable, then “secondary” data from “Data Node 2A” will be used.
- Which situations break a continuous availability cluster? Simultaneously losing the primary node or primary replica node and data nodes, or two or more data nodes in both fault domains, are not supported.
-
Each analytics node from fault domain 1 has its node pair in fault domain 2 or vice versa.
Using the previously mentioned example, we will have four node pairs:
Primary + Replica Node
Data Node 1A (FD A) + Data Node 1B (FD B)
Data Node 2A (FD A) + Data Node 2B (FD B)
Data Node 3A (FD A) + Data Node 3B (FD B)
The two nodes of each node pair are always synchronized and storing the same data. Hence, the cluster continues to function without data loss while one node from all node pairs is available.
- What happens if one data node from one of the fault domains becomes unavailable?
- The cluster will be in a degraded state but continue to operate when one node becomes unavailable in either fault domain. There will be no data loss. The data node must be repaired or replaced so the cluster does not remain in a degraded state.
- Will the cluster break if two data nodes in fault domain 1 and the primary replica node in fault domain 2 are lost?
- In this example, the cluster will continue to work without data loss. If one analytics node from each node pair is still available, there will be no data loss.
- What happens if an entire fault domain becomes unavailable?
-
The cluster will be in a degraded state but continue to operate when an entire fault domain becomes unavailable. There will be no data loss. The fault domain must be repaired and brought online so the cluster does not remain in a degraded state.
It the fault domain is unrecoverable, it is possible to replace the entire fault domain with newly deployed nodes. From the admin UI, only the primary replica node can be replaced. If the entire fault domain for the primary node is lost, you will need to wait until the primary node failover occurs and the primary replica node has been promoted as the new primary node.
- What is the proper process to re-add a failed node to a fault domain? How long will it take to sync up?
- The recommended procedure to re-add a failed node is to use the "Replace nodes of cluster" functionality within the admin UI. Once the replacement node has been added, the data will be synced. The sync time strongly depends on the object count, historical period of the objects, network bandwidth, and the load on the cluster.
- What happens when network latency between fault domains exceeds 20 ms? How long can vRealize Operations tolerate extended latency?
- Adhering to latency requirements is necessary to achieve optimal performance. The latency between fault domains should be < 10 ms, with peaks up to 20 ms during 20 sec intervals. For more information about network latency guidelines, see the KB article vRealize Operations Manager Sizing Guidelines (KB 2093783).
- When network latency between fault domains goes above “20 ms during 20 sec intervals” for some period, but then recovers back to under 10 ms, how long does it take to resynchronize?
- High latency does not mean that synchronization has stopped. When an object is discovered, vRealize Operations will decide which node needs to keep the data (primary), then a second copy of the data will go to its node pair (secondary). Every object is stored in two analytics nodes (pairs) across both fault domains. Synchronization is an ongoing process where the secondary node is periodically syncs with the primary node. Synchronization is performed based on last synced timestamps of the primary and secondary nodes. Hence, there is no synchronization data queue in vRealize Operations.
- What is the actual witness node tolerance to missed polls?
- Witness node operations are not poll based. The witness node interacts only when one of the nodes is not able to communicate (after various checks) with nodes from the other fault domain.
- At what point in time will the primary node and primary replica node failover?
- The failover occurs only when the primary node is no longer accessible or not alive.
- When is the primary replica node promoted to the primary node?
-
The primary replica node is promoted to the primary node in only two cases:
- When the existing primary node is down.
- The associated fault domain is down/offline.
- When the original primary node returns online, does it resume primary control? How does the data get synchronized?
- When operations return to normal, with both primary node and primary replica node online, the newly promoted primary node (formerly primary replica node) remains the new primary node and the new primary replica (formerly primary node) gets synced with the new primary node.
- What happens if connectivity between fault domains is completely interrupted, but then recovers?
- If communications between the fault domains is completely interrupted for several minutes, then one of the fault domains will automatically go offline. After the network interruption is restored, admin user needs to manually bring the fault domain online which will begin the data synchronization.
- What happens to the fault domains when the witness node becomes unavailable?
-
While both fault domains are healthy and communicating with each other, the unavailability of the witness node will have no effect on the cluster; vRealize Operations will continue to function. If there is a communication issue between the fault domains, three situations could occur:
- Witness node is accessible from both fault domains – witness will bring one fault domain offline based on site health.
- Witness node is accessible from one fault domain only – The other fault domain will go offline automatically.
- Witness node is not accessible from both fault domains – Both fault domains will go offline.
- When the offline fault domain becomes available again, will the fault domains synchronize all data collected during the communication outage?
- The collected data is synchronized immediately once connectivity to the fault domain is restored and synchronized to capture all missed data.
- What happens when an analytics node is not able to communicate to analytics nodes in the other fault domain?
- If an analytics node is not able to communicate with all nodes from the other fault domain nor the witness node, it will go offline automatically. All nodes or entire fault domain that were taken offline automatically should be brought back online by the Admin user manually after ensuring that all communication issues have been resolved.
- If the maximum number of nodes in a standard cluster is 10 extra-large nodes, which supports 440,000 objects, why is the maximum number of nodes in continuous availability more with 12 extra-large nodes, which supports 264,000 objects?
- The 12 extra-large nodes are supported only in a continuous availability cluster and references a maximum of six extra-large nodes across two separate fault domains. This permits an increase to the number of nodes over a standard cluster and allows for collection for a greater number of objects.
- Is a load balancer supported with Continuous Availability?
- Yes, for more information about load balancer configuration, see vRealize Operations Load Balancing Configuration guide available under Resources in the vRealize Operations Manager Documentation page.
- The documentation states, “When CA is enabled, the replica node can take over all functions that the primary node provides, in case of a primary node failure. The failover to the replica is automatic and requires only two to three minutes of vRealize Operations downtime to resume operations and restart data collection.”
- During testing, by disconnecting the network interface on the primary node, the switchover to the new primary worked within 5 minutes, you get kicked out of the product UI or get strange errors.
- The stated two or three minutes are approximate medium values, so 5 minutes is acceptable.
- When the primary node is connected to the network again after a failover, what is the recommended procedure to return the original primary node to the primary role?
- It is not necessary to roll back the primary replica node to the primary node role or vice versa. If you still want to restore the old primary node to the primary role, then use “Take Node Offline/Online” on the new primary node or its fault domain (where the original primary node resides)
