El rendimiento consiste en garantizar que las cargas de trabajo obtengan los recursos necesarios y la administración del rendimiento es, en gran medida, la ejecución de eliminaciones. La metodología secciona cada capa y determina si esa capa ocasiona problemas de rendimiento. Es fundamental tener una sola métrica para indicar si una capa en particular tiene un buen rendimiento o no. Esta métrica principal se denomina Indicador clave de rendimiento (Key Performance Indicator, KPI).
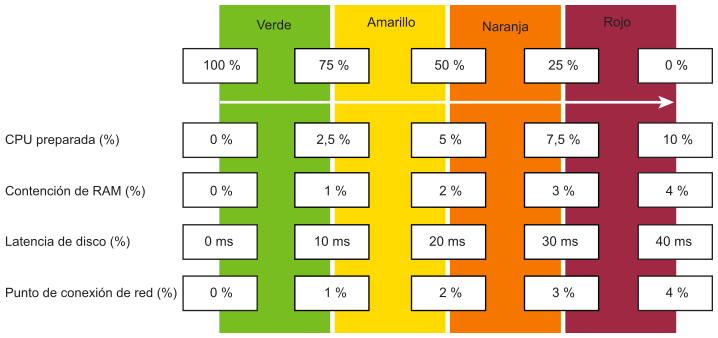
Cada métrica, como la latencia de disco, tiene cuatro rangos: verde, amarillo, naranja y rojo.
Para facilitar la supervisión, el rango se asigna entre el 0 % y el 100 %. El color verde se asigna del 75 % al 100 %, y el color rojo del 0 % al 25 %. Dividir el 100 % en cuatro intervalos iguales permite que cada rango tenga un tamaño de banda aceptable.
La técnica anterior permite combinar métricas con diferentes unidades. Cada una de ellas se asigna a la misma banda, que es un porcentaje.
La lógica para asignar correctamente una métrica a cuatro intervalos necesita cinco métricas en lugar de cuatro. Por ejemplo, para Latencia de disco:
-
Si es 41 ms, es el 0 % (aparece en rojo), ya que el límite superior del color rojo es 40 ms.
-
Si es 35 ms, es el 12,5 %, ya que se encuentra en el medio entre 30 ms y 40 ms, y aparece en color rojo.
-
Si es 30 ms, es el 25 %, ya que está en el límite entre rojo y naranja.
Una vez que cada métrica se convierte en un rango de 0 % a 100 %, se toma el promedio y no el valor máximo, para obtener la métrica de KPI. El promedio se utiliza para evitar que cualquier métrica domine el valor de KPI. Si alguna métrica es fundamental para sus operaciones, puede utilizar alertas para ella. El uso de un promedio refleja la realidad, ya que cada métrica se contabiliza por igual.
Estos paneles de control usan KPI para mostrar el rendimiento de las sesiones de Horizon en la capa de consumidor y el rendimiento total de las cargas de trabajo en la capa de infraestructura de Horizon. Estos paneles de control están diseñados para el arquitecto o el administrador principal de Horizon. Proporcionan un rendimiento general de la parte del centro de datos de escritorio como servicio.
Horizon desde el punto de vista de administración del rendimiento
Para la supervisión y la solución de problemas de rendimiento, Horizon es similar a una arquitectura de cliente/servidor, donde el cliente se encuentra a través de la red WAN. Los componentes de red y centro de datos son independientes entre sí, utilizan diferentes conjuntos de métricas y deben ser supervisados como una entidad en sí mismos. Tienen su propio conjunto de acciones de corrección. En las grandes empresas, la red es propiedad de un equipo independiente.
Por lo tanto, Management Pack for Horizon la supervisa por separado, y proporciona KPI.

El componente de cliente es el último enfoque de la supervisión del rendimiento, ya que en esencia actúa como una televisión. Muestra los píxeles transmitidos y acepta entradas simples. Asimismo, un problema con un cliente tiende a ser aislado. Sin embargo, la interrupción de la red y del centro de datos puede afectar a muchos usuarios.
Los tres procesos de solución de problemas de rendimiento
Los tres procesos diferenciados de la administración del rendimiento son los siguientes:
-
Planificación. Aquí es donde se establece el objetivo de rendimiento. Cuando diseñó esa instancia de vSAN, ¿cuántos milisegundos de latencia de disco tuvo en cuenta? 10 ms medidos a nivel de máquina virtual (no a nivel de vSAN) es un buen comienzo.
-
Supervisión. Aquí es donde se compara el valor planificado frente al real. ¿La realidad coincide con el rendimiento que se supone que debía tener la arquitectura? Si no es así, debe solucionarlo.
-
Solución de problemas. Esto se hace cuando la realidad es peor que lo que se planificó, y no cuando se produce una queja. No querrá dedicarle tiempo a la solución de problemas, por lo que se recomienda que lo haga de forma proactiva.

Las dos métricas de administración de rendimiento
El contador principal de rendimiento es la contención . La mayoría de los clientes se fijan en el uso, porque temen que, si es alto, se pueda producir un problema. Ese problema es la contención. Esta se manifiesta de distintas maneras. Puede ser poner en cola, latencia, descartar, anular o cambiar de contexto.
No se deben confundir los indicadores de uso muy alto con un problema de rendimiento. Solo porque un host ESXi esté experimentando aumentos, compresión e intercambio, no significa que la máquina virtual tenga problemas de rendimiento de memoria. El rendimiento del host se mide según la eficacia del servicio que ofrece a sus máquinas virtuales. Aunque está relacionada con el uso de ESXi, la métrica de rendimiento no se basa en el uso. Se basa en las métricas de contención.
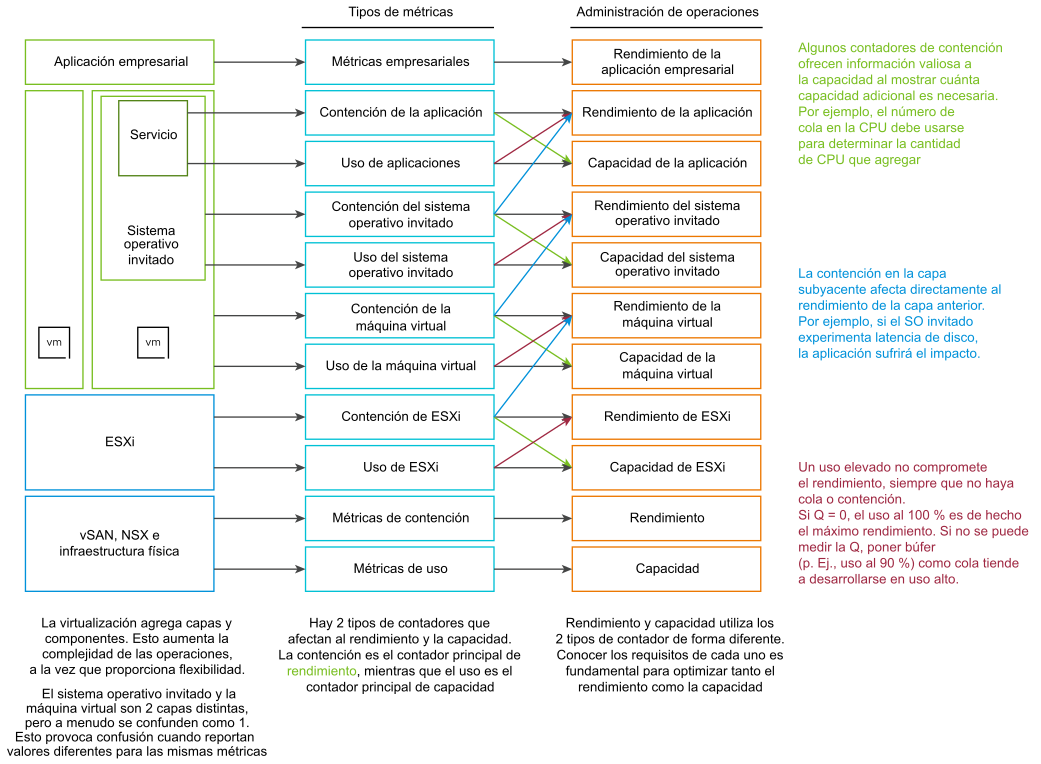
Es posible que las máquinas virtuales del clúster estén experimentando un bajo rendimiento al tiempo que el uso del clúster es bajo. Una razón principal es que el uso del clúster se enfoca en la capa de proveedor (ESXi), mientras que el rendimiento se centra en un consumidor individual (máquina virtual).
Desde el punto de vista de administración del rendimiento, el clúster de vSphere es el bloque de creación lógico más pequeño de los recursos. A pesar de que el grupo de recursos y la afinidad de host de máquina virtual pueden proporcionar una unidad de menor tamaño, son operaciones complejas y no pueden ofrecer la calidad prometida del servicio de IaaS. El grupo de recursos no puede proporcionar una clase de servicio diferenciada. Por ejemplo, su SLA establece que el escritorio premium es dos veces más rápido que el regular, ya que se carga al 200 %. El grupo de recursos puede conceder al escritorio premium dos veces más recursos compartidos. Esos recursos compartidos adicionales que se traducen en la mitad de la preparación de la CPU no se pueden determinar de antemano.
Profundidad y alcance
La supervisión proactiva requiere información de más de un punto de vista. Si un usuario sufre un problema de rendimiento, se deben formular las siguientes preguntas:
-
¿Cómo es de grave? Evalúe la profundidad del problema.
-
¿A cuántos usuarios afecta? Evalúe el alcance del problema.
La respuesta a la segunda pregunta afecta el curso de la solución de problemas. ¿El incidente es aislado o generalizado? Si es aislado, examine el objeto afectado más detenidamente. Si se trata de un problema generalizado, examine las áreas comunes (por ejemplo, clústeres, almacenes de datos, grupos de recursos y hosts) que se comparten con el objeto afectado.

¿Se dio cuenta de que no preguntamos cuál es el rendimiento promedio? Esto se debe a que, en este caso, es demasiado tarde para el promedio. Para cuando el rendimiento promedio sea malo, seguramente la mitad de la población ya estará afectada.
Count() funciona mejor que Percentage() cuando el recuento de miembros es grande. Por ejemplo, en un entorno de VDI con 100 000 usuarios, 5 usuarios afectados representan el 0,005 %. Es más fácil supervisar utilizando el recuento, ya que es algo más cercano a la realidad.
Flujos generales
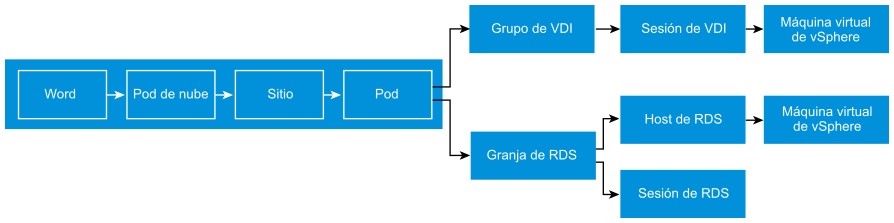
Los paneles de control de Management Pack for Horizon no están diseñados de manera aislada. Forman un flujo y pasan el contexto a medida que explora más en profundidad. El siguiente ejemplo muestra cómo se puede profundizar desde la vista general hacia abajo hasta la máquina virtual subyacente que admite una sesión. El primer panel de control cubre todos los pods del Entorno de Horizon. A partir de él, puede profundizar hacia una granja RDS o un grupo de VDI. Dentro de cada rama, puede profundizar en la sesión individual.
Consideración de diseño
Todos los paneles de control de rendimiento comparten los mismos principios de diseño. Se diseñan intencionadamente para que sean similares, ya que resultaría confuso si todos los paneles de control fueran distintos. Los paneles de control tienen el mismo objetivo
y están diseñados de arriba a abajo, con las secciones Resumen y Detalles.
-
Por lo general, la sección Resumen se encuentra en la parte superior del panel de control. Ofrece la visión general.
-
La sección Detalles se encuentra debajo de la sección Resumen. Le permite profundizar en un objeto específico. Por ejemplo, si se trata del rendimiento de una máquina virtual, puede ver los detalles de rendimiento de una máquina virtual específica.
La sección Detalles también está diseñada con cambio de contexto rápido, para que pueda comprobar el rendimiento de varios objetos durante la solución de problemas de rendimiento. Por ejemplo, el panel de control de rendimiento del host de RDS le ofrece toda la información específica del host de RDS y le permite ver los KPI sin cambiar de pantalla. Puede moverse de un host RDS a otro y ver los detalles sin tener que abrir varias ventanas.
Desde la perspectiva de la interfaz de usuario, el panel de control utiliza una visualización progresiva para minimizar la sobrecarga de información y garantizar que la página web se cargue rápidamente. Siempre que la sesión del navegador permanezca activa, recordará la última selección.
Color como significado
El panel de control utiliza colores para transmitir los significados, ya que se utilizan umbrales diferentes.
| Contador | Umbral utilizado |
|---|---|
| KPI | Verde: 75 % - 100 % Amarillo: 50 % - 75 % Naranja: 25 % - 50 % Rojo: 0 % - 25 % En consecuencia, los conjuntos de umbrales son 25 %, 50 % y 75 %. |
| Recuento de elementos en rojo. Por ejemplo, el recuento de sesiones de VDI con KPI en rojo. |
Se espera que sea 0 en todo momento, ya que no debería haber sesiones de VDI con un valor de KPI que se encuentre en el rango de color rojo. En consecuencia, los conjuntos de umbrales son 1, 2 y 3. Si desea que aparezca el color rojo cuando el recuento es 1, puede establecerlo en 0,1, 0,2 o 1. |
Se espera que los números que se muestran estén en la zona verde (75 % - 100 %). El valor promedio puede no ser 100 %, pero intente que esté en el rango verde.
Tabla como información
Una tabla es simplemente una lista, donde cada fila representa un objeto y cada columna muestra un valor único. En esta lista se enumeran cientos de filas, y se proporciona la capacidad de filtrar y ordenar. Los valores de cada celda también pueden tener un código de color.
La tabla es adecuada para los detalles. Sin embargo, dado que es un resumen, el problema principal es cómo ofrecer información a lo largo del tiempo, ya que cada celda solo puede tener un valor. ¿Cómo se proporciona información de lo que ocurrió en el pasado? Por ejemplo, ¿cómo se ve el rendimiento de la última semana? Hay miles de puntos de datos en los últimos siete días, ¿cuál elegimos?
Existen algunas opciones posibles en VMware Aria Operations 8.2
-
El número actual. Resulta útil mostrar la situación presente. Sin embargo, esto no muestra lo que ocurrió hace cinco minutos.
-
El promedio del período. El promedio es un indicador atrasado. Para cuando el promedio es malo, es probable que cerca del 50 % de la cantidad total no esté en buen estado.
-
El peor valor del período. Esto puede ser muy extremo, ya que solo se toma un valor máximo. En algunos casos, un solo número entre cientos de puntos de datos puede ser un valor atípico. Es ideal para la detección del valor máximo, pero debe complementarse.
-
El percentil 95º. Este es un buen punto medio entre el promedio y el peor valor. Para la supervisión del rendimiento, el percentil 95º es un resumen mejor que el promedio.
Use los números del percentil 95º y del peor valor juntos, empezando por el percentil 95º. Si los números son muy distantes, quiere decir que el peor valor es probablemente un valor atípico.
Para una mayor visibilidad, considere la posibilidad de agregar un percentil 98º para complementar el percentil 95º y el peor valor.
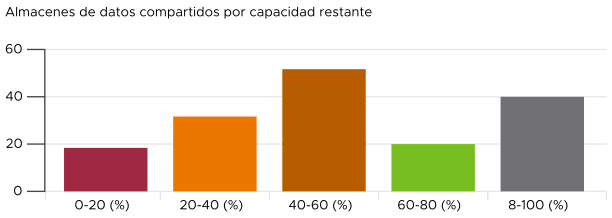
Gráfico de barras como información
Los gráficos de distribución adoptan muchas formas, entre las que el gráfico de barras es una de las más conocidas. Se puede utilizar para proporcionar información sobre conjuntos de datos de gran tamaño. Por ejemplo, los almacenes de datos compartidos de vSphere se muestran por su capacidad restante. Se clasifican en cinco depósitos, de la menor capacidad restante a la más alta. A cada depósito se le asigna un color para transmitir un significado. La capacidad superior al 80 % recibe el color gris, ya que una gran cantidad de capacidad sin utilizar indica un desperdicio de recursos.