









El panel de control Contención del clúster es el panel de control principal para el rendimiento del clúster de vSphere. Está diseñado para administradores o arquitectos de VMware. Se puede utilizar tanto para la supervisión como para la solución de problemas. Una vez que haya determinado que existe un problema de rendimiento, utilice el panel de control Uso del clúster para comprobar si la contención se debe a un uso elevado.
Consideraciones de diseño
Este panel de control se utiliza como parte del procedimiento operativo estándar (SOP). Está diseñado para su uso diario, por lo que las vistas se configuran para mostrar los datos de las últimas 24 horas. El panel de control proporciona métricas de rendimiento para las máquinas virtuales en el centro de datos seleccionado.
El uso del clúster no se muestra en el panel de control Contención del clúster. Debe separar los dos conceptos: uso y contención. El rendimiento y la capacidad son diferentes conceptos que administran dos equipos independientes. La CPU y la memoria también se muestran por separado. Puede tener un problema con uno y ningún problema en el otro. La CPU es más habitual, ya que la memoria tiende a tener una proporción de sobreasignación más baja.
Para ver las consideraciones de diseño comunes entre todos los paneles de control de administración de rendimiento, consulte Paneles de control de rendimiento.
Cómo usar el panel de control
- Rendimiento medio del clúster (%)
- Este es el principal KPI de toda la IaaS. Describe cómo se realiza la IaaS cada 5 minutos, lo que le ofrece la vista de tendencia del rendimiento general.
- La métrica es simplemente el promedio de las métricas KPI / rendimiento (%) del clúster. Esta métrica de rendimiento, a su vez, calcula el promedio de la métrica Rendimiento de la máquina virtual / Número de KPI que no se han cumplido de todas las máquinas virtuales en ejecución en el clúster. Por lo tanto, el valor 100 % indica que cada máquina virtual en ejecución del clúster está bien atendida.
- Dado que este KPI tiene en cuenta cada máquina virtual en ejecución en su entorno, el número debe ser estable. Una analogía en la vida real sería el índice del mercado de valores. A pesar de que cada acción puede presentar una gran volatilidad de manera individual, el índice general debe permanecer relativamente estable en periodos de 5 minutos.
- El movimiento relativo de la métrica es tan importante como el valor absoluto de la métrica. Es posible que el número absoluto no sea lo más alto que desea que sea, pero si no hay quejas en un periodo largo de tiempo, no hay justificación empresarial urgente para mejorarlo.
- Rendimiento de los clústeres
- Enumera todos los clústeres, organizados por el clúster de menor ejecución en la última semana. Puede cambiar este periodo de tiempo.
- El peor rendimiento muestra el número más bajo del periodo de tiempo. A medida que VMware Aria Operations recopila datos cada 5 minutos, hay 12 x 24 x 7 = 2016 puntos de datos en una semana. Esta columna muestra el peor punto entre los 2016 puntos de datos.
- Un número único entre 2016 puntos de datos puede ser un valor atípico que en ocasiones se debe complementar con otro número. Una opción lógica es el promedio de estos números. Para que el rendimiento promedio sea bajo, muchos de los criterios deben ser bajos. En el caso de esperar el promedio, se produce un retraso en las operaciones y se aumentan las quejas. Para la supervisión del rendimiento, el percentil 95º es un resumen mejor que el promedio.
- El clúster debería funcionar a un 100 % y realizar sus funciones según lo planificado.
- Seleccione un clúster de la tabla.
- Todos los gráficos de estado muestran el KPI del clúster seleccionado.
- En el caso del rendimiento, es importante mostrar la profundidad y el alcance de los problemas de rendimiento. Un problema que afecte a una o dos máquinas virtuales requiere una solución de problemas diferente a un problema que afecta a todas las máquinas virtuales del clúster.
- La profundidad se muestra al notificar el peor de los contadores de la máquina virtual. Por lo tanto, se muestra el valor más alto de la disponibilidad de CPU de la máquina virtual, la contención de la memoria de la máquina virtual y la latencia de disco de la máquina virtual entre todas las que se están ejecutando. Si el peor número es bueno, no necesitará comprobar el resto de las máquinas virtuales.
- Un clúster de gran tamaño con miles de máquinas virtuales puede tener una sola máquina virtual que experimente un rendimiento deficiente, mientras que el 99,9 % de la población de la máquina virtual es correcto. Es posible que el contador de profundidad no informe de que la mayoría de las máquinas virtuales están bien. Solo informa de las que presentan peores resultados. Aquí es donde se incluyen los contadores de alcance.
- Los contadores de alcance indican el porcentaje de la población de máquinas virtuales que está experimentando un problema de rendimiento. El umbral se establece como estricto, ya que el objetivo consiste en proporcionar una advertencia temprana y activar las operaciones proactivas.
Puntos que se deben tener en cuenta
Es posible que las máquinas virtuales del clúster estén experimentando un bajo rendimiento al tiempo que el uso del clúster es bajo. Una razón principal es que el uso del clúster se encuentra en la capa de proveedor (ESXi), mientras que el rendimiento se centra en el consumidor individual (máquina virtual). En la siguiente tabla, se muestran varios motivos posibles. 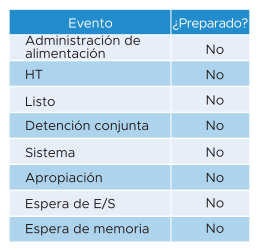
Desde el punto de vista de administración del rendimiento, el clúster de vSphere es el bloque de creación lógico más pequeño de los recursos. A pesar de que el grupo de recursos y la afinidad de host de máquina virtual pueden proporcionar una unidad de menor tamaño, son operaciones complejas y no pueden ofrecer la calidad prometida de servicio de la IaaS. El grupo de recursos no puede proporcionar una clase de servicio diferenciada. Por ejemplo, su SLA establece que Gold es dos veces más rápido que Silver, ya que se carga a un ritmo 200 % superior. El grupo de recursos puede conceder a Gold dos veces más recursos compartidos. No se puede determinar de primeras si esos recursos compartidos adicionales se traducen en la mitad de la preparación de la CPU.
Algunas opciones de configuración, tales como el nivel de automatización de DRS y la presencia de muchos grupos de recursos, pueden afectar al rendimiento. Considere la posibilidad de añadir un widget de propiedad para mostrar la propiedad pertinente de un clúster seleccionado y un widget de relación para mostrar los grupos de recursos.
Para un entorno de gran tamaño con varios clústeres, añada una agrupación para que la lista sea más fácil de administrar. Realice una agrupación por clase de servicio para que pueda centrarse mejor en los clústeres críticos.
