Si se produce un error en el servicio de base de datos principal, puede activar VMware Cloud Director para que realice una conmutación por error automática a una nueva base de datos principal.
Con la conmutación por error automática, ya no es necesario que un administrador inicie la acción de conmutación por error cuando el servicio de base de datos principal no puede realizar sus funciones por algún motivo. De forma predeterminada, el modo de conmutación por error se establece como manual. Puede establecerlo como automático o como manual mediante la API del dispositivo de VMware Cloud Director. Consulte la Referencia del esquema de la API del dispositivo de VMware Cloud Director.
Automatic. Consulte
API del dispositivo de VMware Cloud Director. El modo de conmutación por error predeterminado para las celdas nuevas es
Manual. Si el modo de conmutación por error es incoherente en los nodos de un clúster, se establece en
Indeterminate en dicho clúster. El modo
Indeterminate puede producir estados de clúster incoherentes entre los nodos y los nodos que siguen una celda principal anterior. Para ver el modo de conmutación por error del clúster, consulte
Ver el estado del clúster y el modo de conmutación por error del dispositivo de VMware Cloud Director.
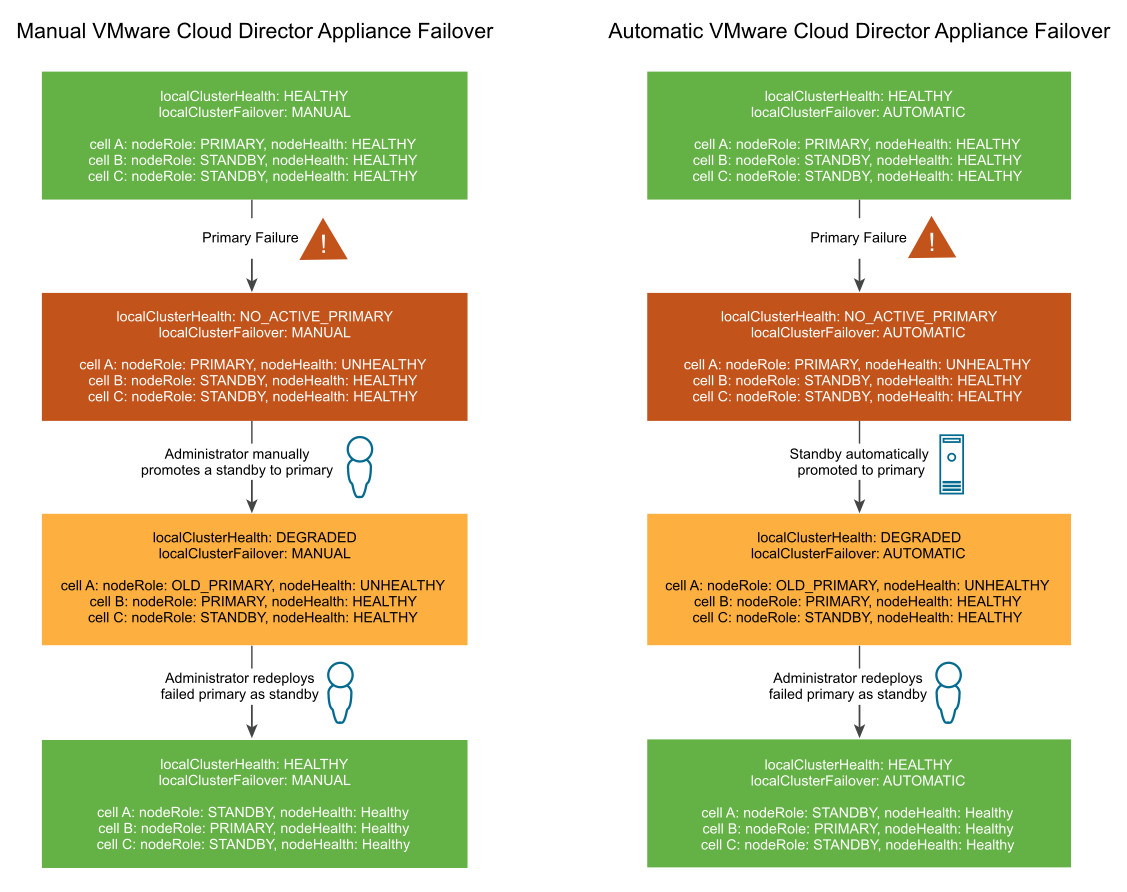
Si el entorno tiene al menos dos celdas en espera activas, una conmutación por error de la base de datos se inicia automáticamente en caso de que se produzca un error de base de datos principal. Tras la conmutación por error, debe haber al menos una celda en espera activa para que se pueda actualizar la nueva base de datos principal. En circunstancias normales, la implementación del dispositivo de VMware Cloud Director precisa de al menos dos celdas en espera activas en todo momento. Si solo hay una celda en espera activa durante un breve período de tiempo (por ejemplo, si se produce un error en la base de datos principal y se promociona una de las celdas en espera), debe reemplazarse la base de datos principal anterior en la que se produjo el error por otra celda en espera nueva lo antes posible.
Cuando hay una base de datos principal activa y al menos dos celdas en espera activas, se considera que el clúster tiene el estado Healthy. Cuando hay una base de datos principal activa y solo una celda en espera activa, el clúster cambia al estado Degraded. Si se produce otro error de base de datos mientras el clúster está en el estado Degraded, la base de datos principal no se puede actualizar hasta que se conecte otra celda en espera. Cuando esto ocurre, VMware Cloud Director no está disponible porque no se puede actualizar la base de datos con las celdas de VMware Cloud Director hasta que hay al menos una celda en espera activa para procesar una replicación por secuencias desde la base de datos principal. Que el clúster esté en estado Healthy o Degraded es independiente de si se activa la conmutación por error manual o automática.
Después de un error en la base de datos principal, el estado de la principal es No_Active_Primary. Para una conmutación por error manual del dispositivo de VMware Cloud Director, el administrador debe promocionar manualmente una instancia en espera a principal y volver a implementar la instancia principal con errores como en espera. Para la conmutación por error automática del dispositivo, VMware Cloud Director promociona automáticamente una instancia en espera a principal, y el administrador vuelve a implementar manualmente la instancia principal con errores como en espera.