









El servicio de escalador automático de VMware Cloud on AWS supervisa el estado de la infraestructura de SDDC, detecta errores incipientes y reales, y corrige automáticamente la infraestructura reemplazando los hosts antes o después de que se produzca un error.
La infraestructura de AWS es confiable, pero los errores son ineludibles incluso en la infraestructura más fiable. El pilar Fiabilidad del marco de la arquitectura de AWS analiza sus principios de diseño para la fiabilidad en la nube. VMware Cloud on AWS amplía estos principios abstrayendo la infraestructura subyacente y aprovechando las capacidades de análisis predictivo de errores de vCenter Server y ESXi para proporcionar una corrección reactiva cuando se producen errores y una corrección predictiva que puede evitar que los errores afecten a las cargas de trabajo.
Arquitectura de alto nivel de corrección automática
- AWS envía a VMware información de nivel de host, especialmente los eventos de mantenimiento planificado de AWS. El servicio de escalado automático recibe estas notificaciones y corrige automáticamente cualquier problema dentro del SDDC.
- Un servicio de supervisión en el nivel de SDDC recibe notificaciones de los componentes subyacentes de VMware Cloud on AWS.
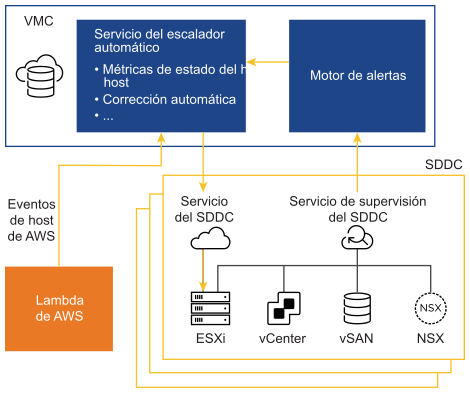
Corrección reactiva
La corrección automática reactiva supervisa los errores de hardware y software e intenta corregir los problemas de varias maneras. La corrección automática es un proceso interno y está en constante evolución. Los usuarios de VMware Cloud on AWS no tienen acceso al flujo de trabajo ni a su configuración, pero como ayuda para comprenderlo mejor, a continuación se ofrece una descripción general de alto nivel de los pasos involucrados actualmente.
- 1: Supervisar
- VMware Cloud on AWS supervisa continuamente el estado de todos los hosts del SDDC. Cuando se detecta un error, se envía un evento a la corrección automática.
- 2: Esperar eventos transitorios
- Algunos de los errores detectados pueden ser temporales. Por ejemplo cuando el sistema de supervisión no puede comunicarse con un host debido a un problema de conectividad temporal. La corrección automática espera 5 minutos para determinar si el problema es temporal. Si es así, la corrección automática vuelve sin tomar ninguna medida.
- 3: Agregar un host
- Si el error no se soluciona después de 5 minutos, la corrección automática comienza a agregar un host al SDDC. La adición de un host de forma preventiva garantiza que el host esté disponible si es necesario. Tenga en cuenta que no se le facturará este host hasta que reemplace un host defectuoso en el SDDC.
- 4: Determinar el tipo de error y tomar medidas
- Los hosts pueden fallar por diferentes motivos y requieren una acción diferente. Por ejemplo, un error de disco de vSAN en un host que aún está conectado a un vCenter Server puede corregirse mediante un reinicio flexible, mientras que un host PSOD requiere un reinicio completo.
- 5: Comprobar el estado del host
- El siguiente paso consiste en comprobar si la acción de corrección ha corregido el host. Si el host con errores se encuentra en buen estado después de un reinicio flexible o completo, la corrección automática evita otras interrupciones en el SDDC. Recopila y realiza cualquier otra acción necesaria y elimina el nuevo host que se agregó previamente en el paso 3.
- 6: Reemplazar host
- Si no se puede reactivar el host con errores, el escalado automático quita el host con errores y lo reemplaza por el host que se agregó en el paso 3. Se activan vSphere HA y vSAN y se asocian al nuevo host etiquetas de directivas de computación.
Corrección preventiva
- Se agrega un nuevo host al clúster. Las etiquetas se copian en este nuevo host desde el host que se va a reemplazar.
- El host con errores se coloca en modo de mantenimiento con una reubicación de datos completa. Esto mueve de forma no disruptiva cualquier máquina virtual o datos de vSAN a otros hosts dentro del clúster.
- El host con errores se retira del clúster.
Eventos del escalador automático
Cuando el servicio del escalador automático recibe un evento de error, determina el tipo de error y después realiza la acción adecuada. El registro de actividad del SDDC incluye toda actividad del escalador automático, pero no muestra el evento de error que activó la actividad.
- Eventos de vCenter Server
-
- Se activa un evento para comprobar el estado de conexión del host.
- Se activa un evento cuando el host ESXi está desconectado o no responde.
- Eventos de DAS
-
- Eventos de vSphere HA: se crea un evento cuando no hay comunicación con el nodo principal o HA está inactivo. (FDM)
- Cuando un host se vuelve inactivo, el sistema HA informa de un error de host.
- vSAN eventos
-
- Cuando se produce un error de disco en los hosts.
- Cuando el host de vSAN está desconectado.
- Eventos de EDRS (sin errores)
- Actualización: deshabilite EDRS. Las actividades de mantenimiento requieren con frecuencia un host adicional; estos hosts se agregan como parte del evento de mantenimiento. Se deshabilita EDRS durante todo el mantenimiento planificado para evitar que estas actividades activen eventos de escalado vertical/horizontal.
- Eventos de AWS
-
- Eventos de mantenimiento planificado. Notificación de AWS que indica que se ha detectado un problema de estado de la instancia y que se debe reubicar la instancia.
- Panel de control de estado personal (PHD). Un flujo de eventos que proporciona información sobre varios componentes de hardware y permite a VMware detectar errores de hardware de forma preventiva.
- Comprobación del estado del sistema. Supervisa el estado de los sistemas de AWS que sirven de soporte para la instancia. Esta comprobación notifica los problemas que solo AWS puede solucionar. En muchos casos, estos problemas son transitorios y no se requiere tomar ninguna medida.
- Comprobación del estado de la instancia. Supervisa el software y la configuración de red de cada instancia. Esta comprobación supervisa la disponibilidad de la instancia mediante la emisión de solicitudes ARP periódicas a la NIC. Además de generar informes sobre la disponibilidad de instancias en la capa EC2. Las comprobaciones de estado de la instancia supervisan el uso del hardware subyacente y notifican problemas de red, agotamiento de memoria, sistema de archivos dañado, errores de kernel, etc. A diferencia de las comprobaciones de estado del sistema, las comprobaciones de estado de la instancia requieren la intervención de VMware para resolverse.
- Eventos de SDDC
- Estado de host de vCenter Server.
