









El libro de ruta de comprobación de estado de VMware Integrated OpenStack CLI abarca los casos y procedimientos de viocli check health para solucionar los problemas notificados.
Puede ejecutar cualquiera de las siguientes soluciones para los problemas notificados en viocli check health:
El nodo no está listo
- Para obtener el estado del nodo, ejecute el comando
osctl get node.osctl get node NAME STATUS ROLES AGE VERSION controller-dqpzc8r69w Ready openstack-control-plane 17d v1.17.2+vmware.1 controller-lqb7xjgm9r Ready openstack-control-plane 17d v1.17.2+vmware.1 controller-mvn5nmdrsp Ready openstack-control-plane 17d v1.17.2+vmware.1 vxlan-vm-111-161.vio-mgmt.eng.vmware.com Ready master 17d v1.17.2+vmware.1
- Reinicie el servicio kubelet en el
not ready nodecon el siguiente comando:viosshcmd ${not_ready_node} 'sudo systemctl restart kubelet' - Para volver a comprobar el estado de este problema, ejecute
viocli check health -n kubernetes.
Nodo con dirección IP duplicada
Para obtener más información sobre el nodo con una dirección IP duplicada, consulte Artículo 82608 de la base de conocimientos.
Para volver a comprobar el estado de este problema, ejecute viocli check health -n kubernetes.
Nodo en mal estado
- Ejecute
osctl describe node <node>para obtener el estado del nodo.Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- NetworkUnavailable False Sat, 05 Jun 2021 10:47:53 +0000 Sat, 05 Jun 2021 10:47:53 +0000 CalicoIsUp Calico is running on this node MemoryPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasNoDiskPressure kubelet has no disk pressure PIDPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasSufficientPID kubelet has sufficient PID available Ready True Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:32 +0000 KubeletReady kubelet is posting ready status
- Si el estado de
NetworkUnavailable,MemoryPressure,DiskPressureoPIDPressurees true, el nodo de Kubernetes tiene un estado anómalo. Por lo tanto, debe comprobar el estado del sistema y el uso de recursos del nodo con estado anómalo. - Para volver a comprobar el estado de este problema, ejecute
viocli check health -n kubernetes.
Nodo con uso elevado de disco
- Inicie sesión en el nodo que notifica un uso elevado de disco.
#viossh ${node} - Compruebe el uso de disco con
df -h. - Elimine los archivos no utilizados en el nodo.
- Para volver a comprobar el estado de este problema, ejecute
viocli check health -n kubernetes.
Evicted, póngase en contacto con el soporte técnico de VMware para recuperarlos.
- Inicie sesión en el nodo con uso elevado de Inode.
#viossh ${node} - Compruebe el uso del Inode con
df -i /. - Elimine los archivos no utilizados en el nodo.
- Para volver a comprobar el estado de este problema, ejecute
viocli check health -n kubernetes.
Nodo con instantánea
- Inicie sesión en vCenter y elimine las instantáneas tomadas para los nodos del controlador de VMware Integrated OpenStack.
- Si notifica un error No se ha podido conectarse a vCenter, debe comprobar la información de conexión de vCenter en VMware Integrated OpenStack.
- Para volver a comprobar el estado de este problema, ejecute
viocli check health -n kubernetes.
No se puede resolver el FQDN
- En el nodo de administración de VMware Integrated OpenStack, compruebe la resolución de DNS con los siguientes comandos:
#viosshcmd ${node_name} -c "nslookup ${reported_host}" #toolbox -c "dig $host +noedns +tcp" - Si se produjo un error, compruebe el servidor DNS configurado en VMware Integrated OpenStack /etc/resolve.conf del nodo.
- Para volver a comprobar el estado de este problema, ejecute
viocli check health -n connectivity.
NTP no sincronizado en el nodo
Para obtener más información sobre un nodo NTP, consulte Artículo 78565 de la base de conocimientos. Para volver a comprobar el estado de este problema, ejecute viocli check health -n connectivity.
LDAP inaccesible
Compruebe la conexión de los nodos de VMware Integrated OpenStack con el servidor LDAP especificado y asegúrese de que la configuración de LDAP (usuario, credenciales) de VMware Integrated OpenStack sea correcta. Para volver a comprobar el estado de este problema, ejecute viocli check health -n connectivity.
vCenter inaccesible
En el caso de que vCenter esté inaccesible, compruebe la conexión de los nodos de VMware Integrated OpenStack con la instancia de vCenter especificada y asegúrese de que la configuración de vCenter (usuario, credenciales) en VMware Integrated OpenStack sea correcta. Para volver a comprobar el estado de este problema, ejecute viocli check health -n connectivity.
NSX inaccesible
Para NSX inaccesible, compruebe la conexión de los nodos de VMware Integrated OpenStack al servidor de NSX especificado y asegúrese de que la configuración de NSX (usuario, credenciales) sea correcta. Para volver a comprobar el estado de este problema, ejecute viocli check health -n connectivity.
- Debe tener preparados todos los requisitos previos enumerados en el documento Integrar VMware Integrated OpenStack con vRealize Log Insight.
- Para volver a comprobar el estado de este problema, ejecute
viocli check health -n connectivity.
- Asegúrese de que el servidor DNS se pueda comunicar con la red de acceso a la API de VMware Integrated OpenStack.
- Debe tener preparados todos los requisitos previos enumerados en el documento Habilitar el componente Designate.
- Para volver a comprobar el estado de este problema, ejecute
viocli check health -n connectivity.
Partición de red incorrecta en nodo rabbitmq
- Para forzar la recreación del nodo
rabbitmq, ejecute en el nodo de administración de VMware Integrated OpenStack.#osctl delete pod ${reported_rabbitmq_node} - Para volver a comprobar el estado de este problema, ejecute
viocli heath check -n rabbitmq.
Problema del clúster WSREP
viocli get deployment es En ejecución, póngase en contacto con el soporte de VIO. De lo contrario, siga las instrucciones que aparecen a continuación.
- Ejecute el siguiente comando desde el nodo de VMware Integrated OpenStack Manager:
#kubectl -n openstack exec -ti mariadb-server-0 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;" #kubectl -n openstack exec -ti mariadb-server-1 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;" #kubectl -n openstack exec -ti mariadb-server-2 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;"
- Si la salida
wsrep_cluster_sizedemariadb-server-xno es 3, vuelva a crear el nodomariadbcon:#kubectl -n openstack delete pod mariadb-server-x
- Si se observa un gran vacío de
wsrep_last_commitedentre los tres nodos, reinicie el nodo o nodosmariadbcon un número menor conwsrep_last_committed.#kubectl -n openstack delete pod mariadb-server-x
- Para volver a comprobar el estado de este problema, ejecute
viocli check health -n mariadb.
Tablas grandes en la base de datos de OpenStack
nova.instancesConsulte el artículo de la base de conocimientos 83768.
glance.imagesHay trabajos cron habilitados de forma predeterminada para purgar automáticamente los registros eliminados por software en la base de datos de Glance.
Compruebe si el trabajo cron de purga de base de datos está habilitado y funciona correctamente.
viocli update glance jobs: db_purge: age_in_days: 60 max_rows: 1000 db_purge_images: age_in_days: 60 max_rows: 1000 manifests: cron_job_db_purge: true cron_job_db_purge_images: truecron_job_db_purgese utiliza para habilitar la purga de tablas de Glance de la base de datos, excepto la tabla "image".cron_job_db_purge_imagesse utiliza para habilitar la purga de la tabla "image" de Glance de la base de datos.--age_in_days NUMsolo purga las filas que se han eliminado durante más de NUM días. El valor predeterminado es de 30 días.--max_rows NUMpurga un máximo de NUM filas de cada tabla. El valor predeterminado es 100.cinder.volumesycinder.volume_attachmentPasos manuales para purgar la base de datos de Cinder
- Copia de seguridad de la base de datos de Cinder.
osctl exec -ti mariadb-server-0 -- mysqldump --defaults-file=/etc/mysql/admin_user.cnf -R cinder > /tmp/cinder_backup.sql
- Inicie sesión en el pod cinder-api-xxxxx.
osctl exec -ti deploy/cinder-api bash
- Limpie la base de datos de Cinder.
cinder-manage db purge 60
Nota:uso del comando: cinder-manage db purge
age_in_days.argumentos posicionales:
age_in_dayspurga filas eliminadas anteriores a la antigüedad en días.Es posible que deba ajustar
age_in_dayspara limpiar más registros eliminados por software en la base de datos de Cinder.
Hay demasiados recursos de red heredados en el plano de control
Para obtener una solución, consulte Error al habilitar Ceilometer cuando hay 10k redes de tenants de Neutron en las Notas de la versión de VMware Integrated OpenStack 7.1.
OpenStack Keystone no funciona correctamente
- Debe intentar iniciar sesión para OpenStack desde el cuadro de herramientas como usuario administrador e intentar ejecutar comandos como
openstack user listyopenstack user show. Si se produce un error en el inicio de sesión, recopile y compruebe los mensajes de error de los registros de Keystone. - Obtenga la lista del pod keystone-api:
#osctl get pod | grep keystone-api
- Recopile los registros:
#osctl logs keystone-api-xxxx -c keystone-api >keystone-api-xxxx.log
- Para comprobar el estado de este problema, ejecute
viocli check health -n keystone.
ID de red en blanco en la base de datos de Neutron
Para obtener una solución, consulte Artículo 76455 de la base de conocimientos. Para comprobar el estado de este problema, ejecute viocli check health -n neutron.
Referencia de vCenter incorrecta en Neutron
- Obtenga el nombre de
viocluster.Si se devuelveosctl get viocluster
viocluster1, continúe con el siguiente paso. De lo contrario, se trata de una falsa alarma. Póngase en contacto con el soporte técnico de VMware para obtener una solución permanente. - Obtenga la configuración
vioclusterde vCenter.# osctl get viocluster viocluster1 -oyaml
- Haga una copia de seguridad de la configuración de Neutron.
osctl get neutron -oyaml > neutron-<time-now>.yml
- Edite el CR de Neutron
cmd:osctl edit neutron neutron-xxxy después cambie la especificación de CR reemplazando la referencia de vCenter que se encuentra en el paso 1.spec: conf: plugins: nsx: dvs: dvs_name: vio-dvs host_ip: .VCenter:vcenter812:spec.hostname <---- change the vcenter instance to viocluster refered host_password: .VCenter:vcenter812:spec.password <---- same above host_username: .VCenter:vcenter812:spec.username <---- insecure: .VCenter:vcenter812:spec.insecure <---- - Para comprobar el estado de este problema, ejecute
viocli check health -n neutron.
- Obtenga el pod para Nova.
osctl get pod | grep nova
Compruebe si el pod de Nova no está en estado En ejecución.
- Elimine el pod con:
osctl delete pod xxx.Espere al nuevo pod hasta que su estado sea En ejecución.
- Para comprobar el estado de este problema, ejecute
viocli check health -n nova.
Servicio Nova obsoleto
Para obtener información sobre un servicio Nova obsoleto, consulte Artículo 78736 de la base de conocimientos. Para comprobar el estado de este problema, ejecute viocli check health -n nova.
- Inicie sesión en el cuadro de herramientas e intente encontrar y eliminar el servicio redundante de Nova y algún servicio de Nova sin endpoints.
# openstack catalog list

# openstack service list

- Encuentre el servicio nova en uso.
# openstack endpoint list |grep nova
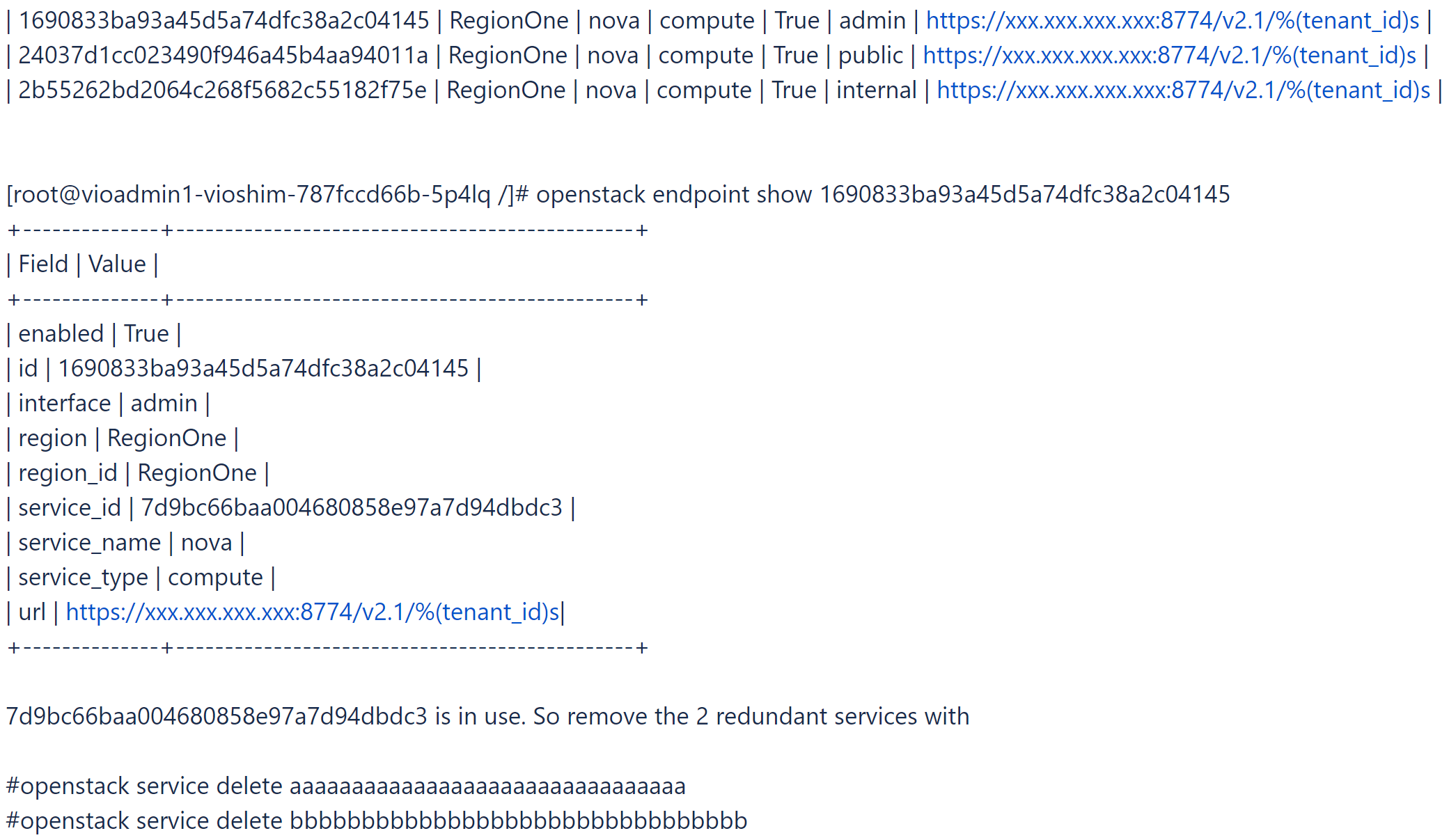
- Para comprobar el estado de este problema, ejecute
viocli check health -n nova.
Algunos pods de proceso para Nova no dejan de reiniciarse porque se agota el tiempo de espera del inicio
Esta alarma indica que el estado de algunos pods de proceso para Nova puede ser incorrecto. Póngase en contacto con el soporte técnico de VMware para obtener una solución. Para comprobar el estado del problema, ejecute viocli check health -n nova.
Almacén de datos de Glance inaccesible
- Obtenga la lista de servicios de Glance.
osctl get glance
- Obtenga la información del almacén de datos de Glance.
osctl get glance $glance-xxx -o yaml
- Busque la información de conexión del almacén de datos.
spec: conf: backends: vmware_backend: vmware_datastores: xxxx vmware_server_host: xxxx vmware_server_password: xxxx vmware_server_username: .xxxx - Si la información no es correcta, compruebe la conexión de vCenter y el almacén de datos y actualícela con
osctl update glance $glance-xxxsegún corresponda. - Para comprobar el estado de este problema, ejecute
viocli check health -n glance.
Imágenes de Glance con un formato de ubicación incorrecto
El mensaje indica que algunas de las imágenes de Glance tienen un formato de ubicación incorrecto. Póngase en contacto con el soporte técnico de VMware para obtener una solución. Para comprobar el estado del problema, ejecute viocli check health -n glance.
Servicios de Cinder inactivos
- Obtenga el pod de Cinder.
osctl get pod | grep cinder | grep -v Completed
Compruebe si el pod de Cinder no está en estado En ejecución.
- Elimine el pod con:
osctl delete pod xxx.Espere al nuevo pod hasta que su estado se muestre como En ejecución.
- Para comprobar el estado de este problema, ejecute
viocli check health -n cinder.
- Inicie sesión en el pod
cinder-volume.#osctl exec -ti cinder-volume-0 bash
- Compruebe y enumere los servicios de Cinder obsoletos.
#cinder-manage service list
Por ejemplo:#cinder-manage service list
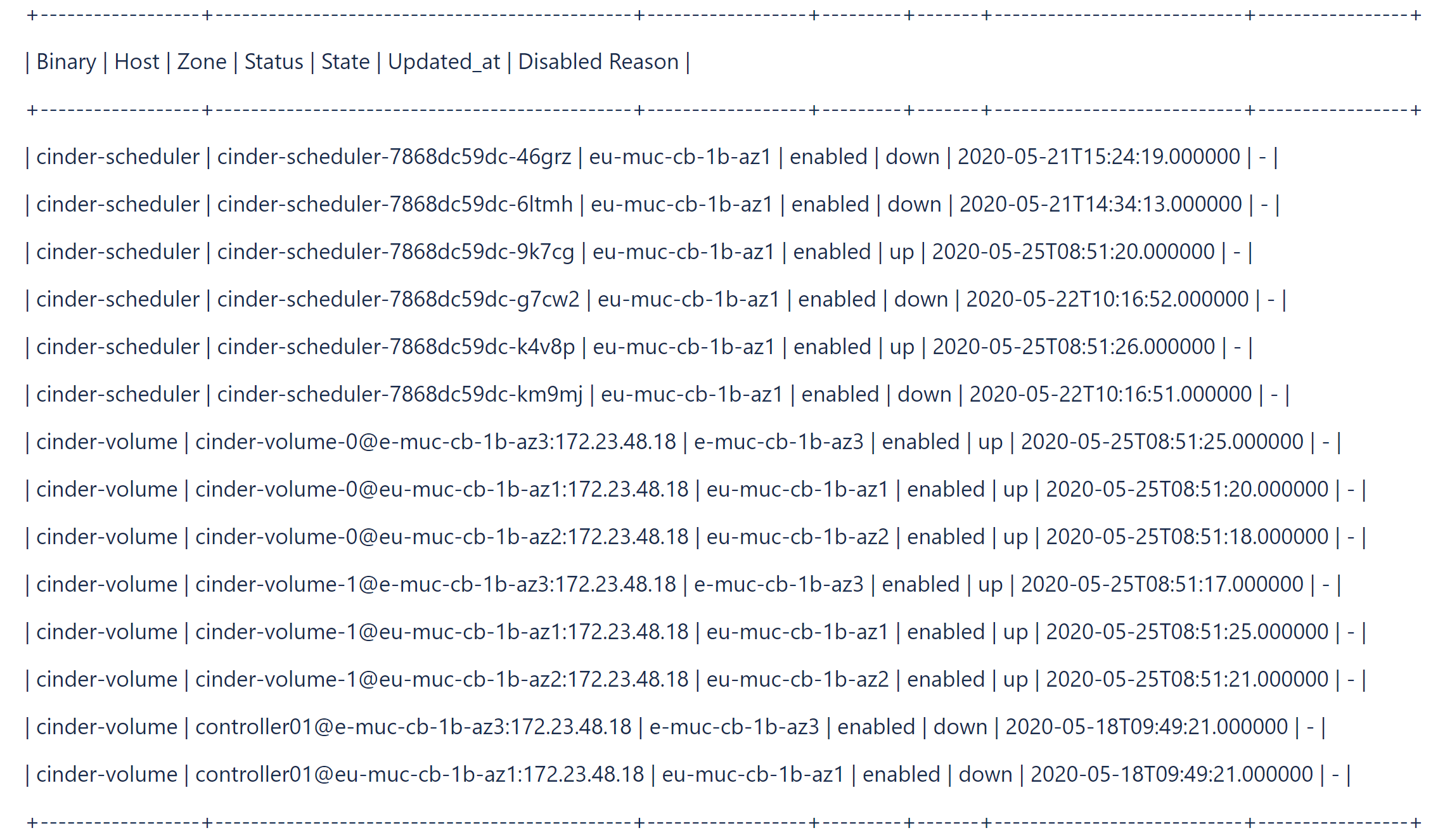
- Elimine los servicios de Cinder obsoletos mediante el comando
cinder-manageen el podcinder-volume.# cinder-manage service remove cinder-scheduler cinder-scheduler-7868dc59dc-km9mj # cinder-manage service remove cinder-volume controller01@e-muc-cb-1b-az3:172.23.48.18
- Para comprobar el estado de este problema, ejecute
viocli check health -n cinder.
- Para instalar el comando necesario en el nodo de administración de VMware Integrated OpenStack, ejecute
tdnf install xxx. - Para comprobar el estado de este problema, ejecute
viocli check health -n basic.
Lista de nodos de Kubernetes vacía o nodo inaccesible
Ejecute osctl get nodes desde el nodo de administración de VMware Integrated OpenStack y compruebe si puede capturar la salida correcta. Para comprobar el estado de este problema, ejecute viocli check health -n basic.
No hay ningún pod en ejecución
Ejecute osctl get pod |grep xxx desde el nodo de administración de VMware Integrated OpenStack y compruebe si puede capturar algún pod en ejecución desde la salida. Para comprobar el estado de este problema, viocli check health -n basic.
Pod inaccesible
Ejecute el comando bash osctl exec -it $pod_name desde el nodo de administración de VMware Integrated OpenStack y compruebe si puede iniciar sesión en el pod. Para comprobar el estado de este problema, ejecute viocli check health -n basic.
Ejecutar comando en un pod
Compruebe el archivo de registro /var/log/viocli_health_check.log para obtener información detallada e intente volver a ejecutar el comando desde el nodo de administración de VMware Integrated OpenStack. Para comprobar el estado de este problema, ejecute viocli check health -n basic.
- Inicie sesión en el cuadro de herramientas y ejecute algunos comandos OpenStack, por ejemplo
openstack catalog list, y compruebe si el comando puede capturar el retorno correcto. - Para obtener más mensajes, agregue la opción debug. Por ejemplo:
openstack catalog list --debug
- Para comprobar el estado de este problema, ejecute
viocli check health -n basic.
- Obtenga la contraseña de administrador de OpenStack y compárela con
OS_PASSWORD.osctl get secret keystone-keystone-admin -o jsonpath='{.data.OS_PASSWORD} - Si no hay ningún valor almacenado en
keystone-keystone-admin, actualícelo conosctl edit secret keystone-keystone-admin. - Para comprobar el estado de este problema, ejecute
viocli check health -n basic.
El clúster de vCenter está sobrecargado o los hosts están bajo presión
Compruebe los hosts de vCenter para el plano de control de VIO y agregue más recursos, o bien limpie algunas instancias no utilizadas para aliviar la presión sobre los recursos.
- Compruebe el registro /var/log/viocli_health_check.log y busque el último mensaje de
check_vio_cert_expirepara saber hace cuánto tiempo caducó el certificado o cuándo va a caducar. - Para actualizar el certificado, siga Actualizar certificado para VMware Integrated OpenStack.
- Para volver a comprobar el estado del problema, ejecute
viocli check health -n connectivity.
El certificado de LDAP caducó o está a punto de caducar
- Compruebe el registro /var/log/viocli_health_check.log y busque el último mensaje de
check_ldap_cert_expirepara saber hace cuánto tiempo caducó el certificado o cuándo va a caducar. - Para actualizar el certificado, siga Actualizar certificado para servidor LDAP.
Nota: Si no hay ningún LDAP configurado, aparecerá el mensaje de registro
No LDAP Certificate foundy se omite la comprobación. - Para volver a comprobar el estado del problema, ejecute
viocli check health -n connectivity.
El certificado de vCenter caducó o está a punto de caducar
- Compruebe el registro /var/log/viocli_health_check.log y busque el último mensaje de
check_vcenter_cert_expirepara saber hace cuánto tiempo caducó el certificado o cuándo va a caducar. - Para actualizar el certificado, siga Configurar VMware Integrated OpenStack con certificado de NSX-T o vCenter actualizado.
Nota: Si la instancia de vCenter está configurada para usar una conexión no segura, aparece el mensaje de registro
Use insecure connectiony se omite la comprobación. - Para volver a comprobar el estado del problema, ejecute
viocli check health -n connectivity.
El certificado de NSX caducó o está a punto de caducar
- Compruebe el registro /var/log/viocli_health_check.log y busque el último mensaje de
check_nsx_cert_expirepara saber hace cuánto tiempo caducó el certificado o cuándo va a caducar. - Para actualizar el certificado, siga Configurar VMware Integrated OpenStack con certificado de NSX-T o vCenter actualizado.
Nota: Si la instancia de NSX está configurada para usar una conexión no segura, aparece el mensaje de registro
Use insecure connectiony se omite la comprobación. - Para volver a comprobar el estado del problema, ejecute
viocli check health -n connectivity.
Servicio xxx detenido
Ejecute viocli start xxx para iniciar el servicio. Para comprobar el estado de este problema, ejecute viocli check health -n lifecycle_manager.
- Compruebe el registro /var/log/viocli_health_check.log y busque el último mensaje de
check_cluster_workload, que proporciona un uso detallado de los recursos. - Solucione los problemas de recursos notificados y ejecute
viocli check health -n kubernetespara volver a comprobar el estado.
