









La empresa ACME Enterprise posee dos sitios de centros de datos privados en Estados Unidos, uno situado en Palo Alto y otro en Austin. Durante un proceso de mantenimiento programado o un fallo imprevisto en el sitio de Palo Alto, la empresa recupera todas las aplicaciones del sitio de Austin.
- Reasignación de la dirección IP
- Sincronización de las directivas de seguridad
- Actualización de otros servicios que utilizan direcciones IP, como el DNS y las directivas de seguridad, entre otros
Este enfoque tradicional con respecto a la recuperación ante desastres conlleva utilizar un tiempo adicional significativo para poder completar la recuperación total en el sitio de Austin. Con el objetivo de lograr una recuperación ante desastres rápida y un periodo de inactividad mínimo, ACME Enterprise decide implementar NSX Data Center 6.4.5 o una versión posterior en un entorno cross-vCenter tal y como se muestra en el siguiente diagrama de topología lógica.
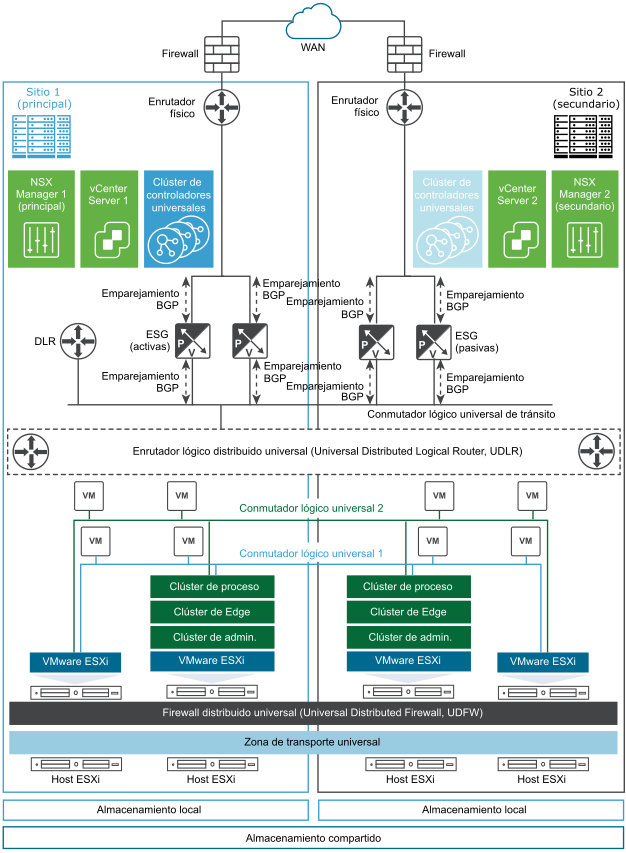
En esta topología, el sitio 1 en Palo Alto es el centro de datos (protegido) principal, y el sitio 2 en Austin es el centro de datos (de recuperación) secundario. Cada sitio tiene un único vCenter Server, que se empareja con su propio NSX Manager. A la instancia de NSX Manager del sitio 1 (Palo Alto), se le asigna al función de NSX Manager principal, mientras que a la instancia de NSX Manager del sitio 2 (Austin) se le asigna la función de NSX Manager secundario.
ACME Enterprise implementa Cross-vCenter NSX en ambos sitios en modo activo-pasivo. El 100 % de las aplicaciones (cargas de trabajo) se ejecutan en el sitio 1 de Palo Alto, mientras que el 0 % de ellas se ejecuta en el sitio 2 de Austin. Esto quiere decir que el sitio 2 está en modo pasivo o de espera de forma predeterminada.
Los dos sitios tienen sus propios clústeres de proceso, Edge y de administración, así como ESG locales. Como la salida local está deshabilitada en el UDLR, solo se implementa una única máquina virtual de control del UDLR en el sitio principal. La máquina virtual de control del UDLR se conecta al conmutador lógico de tránsito universal.
El administrador de NSX crea objetos universales que se extienden a dos dominios de vCenter del sitio 1 y el sitio 2. Las redes lógicas universales utilizan redes universales y objetos de seguridad, como conmutadores lógicos universales (Universal Logical Switches, ULS), enrutadores lógicos distribuidos (Universal Distributed Logical Routers, UDLR) y firewall distribuido universal (Universal Distributed Firewall, UDFW).
- Crea una zona de transporte universal a partir de la instancia de NSX Manager principal.
- Implementa un clúster de controladores universal con tres nodos de controladores.
- Agrega los clústeres de proceso, Edge y administración a la zona de transporte universal desde la instancia de NSX Manager principal.
- Deshabilita la salida local, habilita el protocolo de enrutamiento ECMP, así como el reinicio correcto en la máquina virtual de control del UDLR (máquinas virtuales del dispositivo de Edge).
- Configura el enrutamiento dinámico mediante BGP entre las puertas de enlace de servicios Edge (Edge Services Gateways, ESG) y las máquinas virtuales de control del UDLR.
- Deshabilita el protocolo de enrutamiento ECMP y habilita el reinicio correcto en las dos ESG.
- Deshabilita el firewall en las dos ESG porque el protocolo de enrutamiento ECMP está habilitado en las máquinas virtuales de control del UDLR y, de esta forma, se asegura de que se permita todo el tráfico.
El siguiente diagrama muestra un ejemplo de configuración de las interfaces de enlace ascendente y vínculo inferior en las ESG y los UDLR del sitio 1.
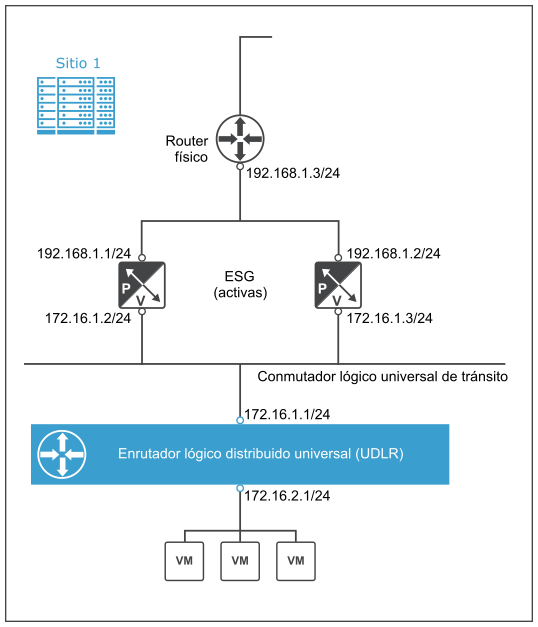
- Agrega los clústeres de proceso, Edge y administración a la zona de transporte universal desde la instancia de NSX Manager secundaria.
- Establece interfaces de vínculo inferior similares en las ESG tal y como se configuraron en las ESG del sitio 1.
- Establece una configuración de BGP similar en las ESG tal y como se configuraron en las ESG del sitio 1.
- Desactiva las ESG del sitio secundario cuando el sitio 1 está activo.
- Escenario 1: fallo programado de toda la instalación en el sitio 1
- Escenario 2: fallo imprevisto de toda la instalación en el sitio 1
- Escenario 3: conmutación por recuperación total en el sitio 1
