









NSX-T Data Center admite la implementación multisitio donde puede administrar todos los sitios de un clúster de NSX Manager.
- Recuperación ante desastres
- Activo-activo
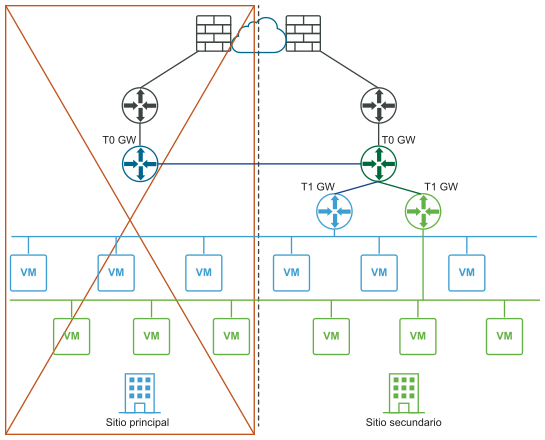
En el siguiente diagrama se muestra una implementación de recuperación ante desastres.
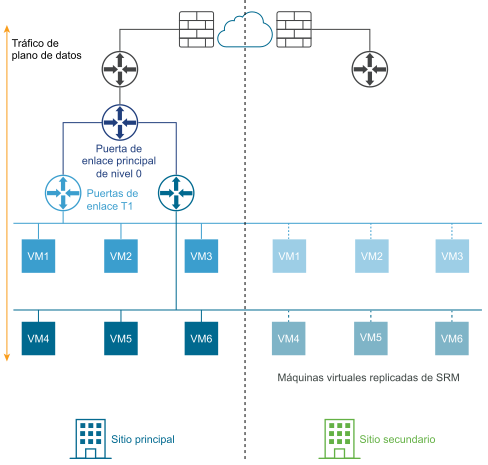
En una implementación de recuperación ante desastres, NSX-T Data Center en el sitio principal controla las redes de la empresa. El sitio secundario permanece inactivo para tomar el relevo si se produce un error grave en el sitio principal.
En el siguiente diagrama se muestra una implementación activo-activo.
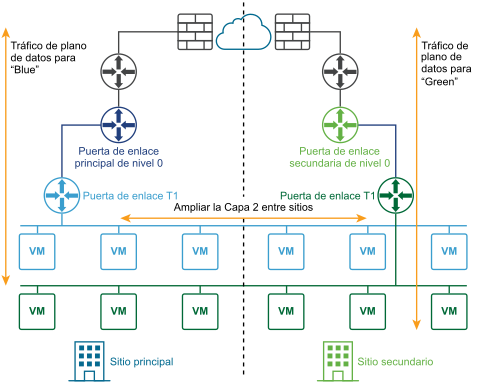
Puede implementar dos sitios para la recuperación automática o manual/por script del plano de administración y del plano de datos.
Recuperación automática del plano de administración
- Un clúster de vCenter ampliado con alta disponibilidad (HA) en todos los sitios configurados.
- Una VLAN de administración ampliada.
El clúster de NSX Manager se implementa en la VLAN de administración y se encuentra físicamente en el sitio principal. Si se produce un error en el sitio principal, vSphere HA reiniciará las instancias de NSX Manager en el sitio secundario. Todos los nodos de transporte se reconectarán automáticamente a las instancias de NSX Manager reiniciadas. Este proceso dura unos 10 minutos. Durante este tiempo, el plano de administración no está disponible, pero eso no afecta al plano de datos.
Los siguientes diagramas ilustran la recuperación automática del plano de administración.
Antes del desastre:
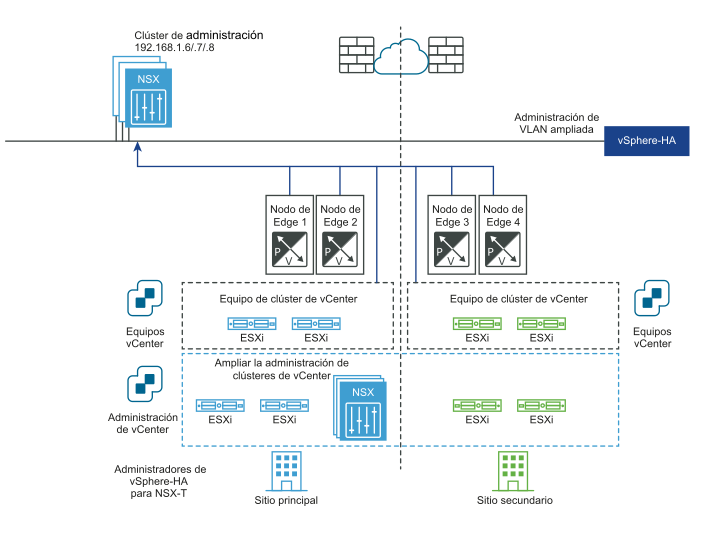
Después de la recuperación ante desastres:
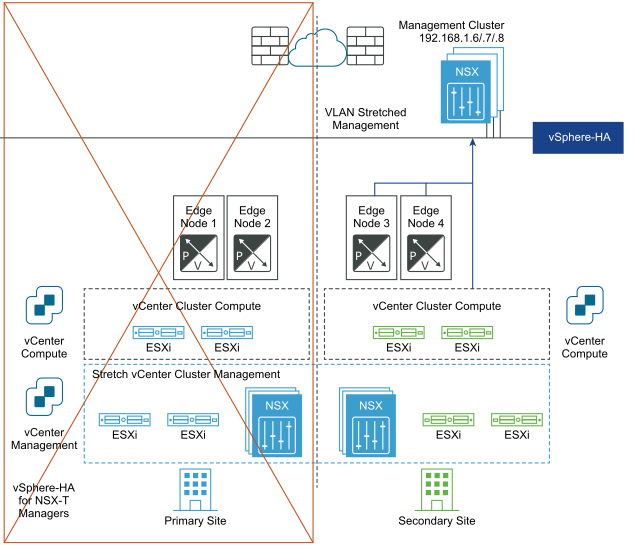
Recuperación automática del plano de datos
Para lograr la recuperación automática del plano de datos, puede configurar dominios de errores para los nodos de Edge. Puede agrupar los nodos de Edge dentro de un clúster de Edge en diferentes dominios de errores. NSX Manager colocará automáticamente cualquier nueva puerta de enlace de nivel 1 activa en el dominio de errores preferido y la puerta de enlace de nivel 1 en espera en el otro dominio. Las puertas de enlace de nivel 1 implementadas antes de la creación de dominios de errores mantienen su ubicación original del nodo de Edge, por lo que es posible que no se estén ejecutando donde desea. Para corregir su ubicación, edite el nivel 1 y seleccione manualmente los nodos de Edge para las puertas de enlace de nivel 1-Activo y nivel 1-En espera.
- La latencia máxima entre los nodos de Edge es de 10 ms.
- Si no se puede lograr el enrutamiento asimétrico norte-sur, por ejemplo si se utiliza un firewall físico en dirección norte hacia el nodo NSX Edge, entonces el modo HA de la puerta de enlace de nivel 0 deberá ser activo-en espera y el modo de conmutación por error deberá ser preferente.
- Si el enrutamiento norte-sur asimétrico es posible (por ejemplo, las dos ubicaciones son dos edificios sin ningún firewall físico entre ellos), el modo de alta disponibilidad para la puerta de enlace de nivel 0 puede ser activo-activo.
Los nodos de Edge pueden ser máquinas virtuales o sin sistema operativo. El modo de conmutación por error de la puerta de enlace de nivel 1 puede ser preferente o no preferente, pero se recomienda el uso preferente para garantizar que las puertas de enlace de nivel 0 y 1 estén en la misma ubicación.
- Mediante la API, cree dominios de errores para los dos sitios, por ejemplo FD1A-Preferred_Site1 y FD2A-Preferred_Site1. En el parámetro preferred_active_edge_services, establezca
truecomo sitio principal yfalsecomo sitio secundario.POST /api/v1/failure-domains { "display_name": "FD1A-Preferred_Site1", "preferred_active_edge_services": "true" } POST /api/v1/failure-domains { "display_name": "FD2A-Preferred_Site1", "preferred_active_edge_services": "false" } - Mediante la API, configure un clúster de Edge que haya ampliado a los dos sitios. Por ejemplo, el clúster tiene los nodos de Edge EdgeNode1A y EdgeNode1B en el sitio principal, y los nodos de Edge EdgeNode2A y EdgeNode2B en el sitio secundario. Las puertas de enlace de nivel 0-Activo y nivel 1-Activo se ejecutan en EdgeNode1A y EdgeNode1B. Las puertas de enlace de nivel 0-En espera y nivel 1-En espera se ejecutan en EdgeNode2A y EdgeNode2B.
- Usando la API, asocie cada nodo de Edge con el dominio de errores del sitio. Para obtener los datos sobre el nodo de Edge, ejecute la API
GET /api/v1/transport-nodes/<transport-node-id>. Utilice el resultado de la API GET como entrada para la APIPUT /api/v1/transport-nodes/<transport-node-id>, con la propiedad failure_domain_id configurada correctamente. Por ejemplo,GET /api/v1/transport-nodes/<transport-node-id> Response: "resource_type": "TransportNode", "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... } PUT /api/v1/transport-nodes/<transport-node-id> { "resource_type": "TransportNode", "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... "failure_domain_id": "<UUID>", } - Con la API, configure el clúster de Edge para asignar nodos en función del dominio de errores. Para obtener los datos sobre el clúster de Edge, ejecute la API
GET /api/v1/edge-clusters/<edge-cluster-id>. Utilice el resultado de la API GET como entrada para la APIPUT /api/v1/edge-clusters/<edge-cluster-id>, con la propiedad adicional allocation_rules configurada correctamente. Por ejemplo,GET /api/v1/edge-clusters/<edge-cluster-id> Response: { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... } PUT /api/v1/edge-clusters/<edge-cluster-id> { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... "allocation_rules": [ { "action": { "enabled": true, "action_type": "AllocationBasedOnFailureDomain" } } ], } - Cree las puertas de enlace de nivel 0 y nivel 1 mediante la interfaz de usuario de NSX Manager o la API.
Si se produce un error de sitio principal completo, el nivel 0 en espera y el nivel 1 en espera en el sitio secundario asumirán el control y se convertirán automáticamente en las nuevas puertas de enlace activas.
Los siguientes diagramas muestran la recuperación automática del plano de datos.
Antes del desastre:

Después de la recuperación ante desastres:
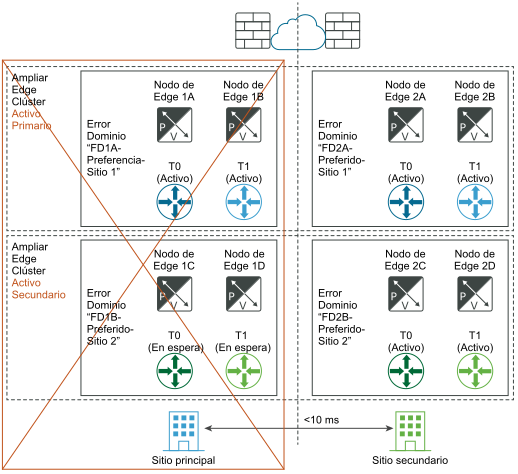
Si se produce un error en uno de los nodos de Edge en el sitio principal y no en el sitio completo, es importante tener en cuenta que se aplica el mismo principio. Por ejemplo, en el diagrama "Antes del desastre", supongamos que el nodo de Edge 1B aloja el nivel 1 azul activo y que el nodo de Edge 2B aloja el nivel 1 azul en espera. Si se produce un error en el nodo de Edge 1B, el nivel 1 azul en espera en el nodo de Edge 2B asumirá el control y se convertirá en la nueva puerta de enlace activa de nivel 1 azul.
Recuperación manual/por script del plano de administración
- DNS para NSX Manager con un TTL corto (por ejemplo, 5 minutos).
- Copia de seguridad de NSX Manager continua.
No se requiere vSphere HA ni una VLAN de administración ampliada. NSX-T Data Center Managers deben estar asociados a un nombre DNS con un TTL corto. Todos los nodos de transporte (hipervisores y nodos de Edge) deben conectarse a NSX Manager usando su nombre DNS. Para ahorrar tiempo, opcionalmente puede preinstalar un clúster de NSX Manager en el sitio secundario.
- Cambie el registro DNS para que el clúster de NSX Manager tenga diferentes direcciones IP.
- Restaure el clúster de NSX Managera partir de una copia de seguridad.
- Conecte los nodos de transporte al nuevo clúster de NSX Manager.
En los siguientes diagramas se muestra la recuperación manual/por script del plano de administración.
Antes del desastre:

Después del desastre:
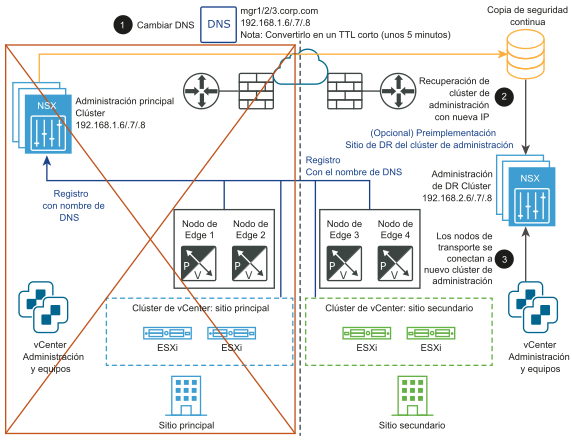
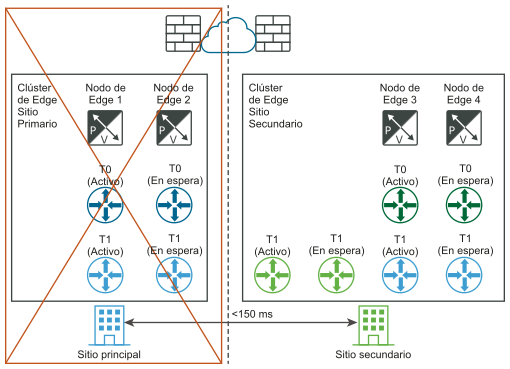
Recuperación manual/por script del plano de datos
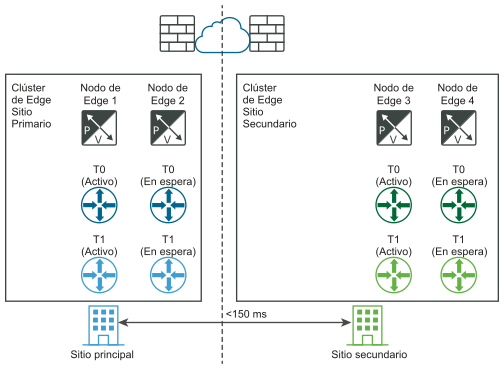
Requisito: La latencia máxima entre los nodos de Edge es de 150 ms.
Los nodos de Edge pueden ser máquinas virtuales o nativos. Las puertas de enlace de nivel 0 en cada ubicación pueden ser activas-en espera o activas-activas. Puede instalar máquinas virtuales de nodo de Edge en diferentes instancias de vCenter Server. No se necesita vSphere HA.
- Para todo el nivel 1 en el sitio principal (azul), actualice la configuración del clúster de Edge para que sea el sitio del clúster de Edge secundario.
- Para todos los niveles 1 del sitio principal (azul), vuelva a conectarlos al nivel 0 secundario (verde).
En los siguientes diagramas se muestra la recuperación manual o generada por script del plano de datos con las vistas de red lógica y física.
Antes del desastre (vistas lógicas y físicas):
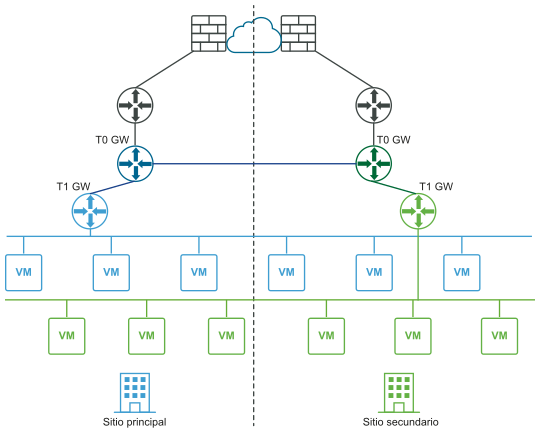
Después del desastre (vistas lógicas y físicas):
Requisitos para implementaciones multisitio
- El ancho de banda debe ser 1 Gbps como mínimo y la latencia (RTT) debe ser inferior a 150 ms.
- Establezca el valor de MTU en 9000. Debe ser al menos 1600.
- Con recuperación automática del plano de administración con administración de VLAN ampliada entre sitios. vSphere HA en todos los sitios para máquinas virtuales de NSX Manager.
- Con recuperación manual/por script del plano de administración con administración de VLAN extendida entre sitios. VMware SRM para máquinas virtuales de NSX Manager.
- Con recuperación manual/por script del plano de administración sin administración de VLAN extendida entre sitios.
- Copia de seguridad de NSX Manager continua.
- NSX Manager se debe configurar para usar el FQDN.
- Si se debe utilizar el mismo proveedor de Internet cuando las direcciones IP públicas se exponen a través de servicios como NAT o el equilibrador de carga.
- Recuperación automática del plano de administración
- La latencia máxima entre ubicaciones es de 10 ms.
- El modo HA para la puerta de enlace de nivel 0 debe estar activo-en espera, y el modo de conmutación por error debe ser preferente para garantizar que no se produzca un enrutamiento asimétrico.
- El modo de alta disponibilidad para la puerta de enlace de nivel 0 puede ser activo-activo si el enrutamiento asimétrico es aceptable (por ejemplo, diferentes edificios en una región metropolitana).
- Con recuperación manual/por script del plano de administración
- La latencia máxima entre ubicaciones es de 150 ms.
- CMS debe admitir un complemento de NSX-T Data Center. En esta versión, VMware Integrated OpenStack (VIO) y vRealize Automation (vRA) cumplen este requisito.
Limitaciones
- Sin capacidades de salida local. Todo el tráfico norte-sur debe realizarse dentro de un sitio.
- El software de recuperación ante desastres de equipos debe admitir NSX-T Data Center (por ejemplo, VMware Site Recovery Manager 8.1.2 o una versión posterior).
- Al restaurar NSX Manager en un entorno de varios sitios, haga lo siguiente en el sitio secundario/principal:
- Una vez que el proceso de restauración se pausa en el paso AddNodeToCluster, antes de agregar nodos de Manager deberá eliminar la VIP existente y establecer la nueva dirección IP virtual desde la página de la interfaz de usuario .
- Agregue nodos nuevos a un clúster de un nodo restaurado después de las actualizaciones de la VIP.
