









Referencia de variable del archivo de configuración
Esta referencia enumera todas las variables que puede especificar para proporcionar opciones de configuración del clúster a la CLI de Tanzu.
Para establecer estas variables en un archivo de configuración YAML, deje un espacio entre los dos puntos (:) y el valor de la variable. Por ejemplo:
CLUSTER_NAME: my-cluster
El orden de líneas en el archivo de configuración no importa. Las opciones se presentan aquí en orden alfabético. Además, consulte la sección Precedencia del valor de configuración a continuación.
Variables comunes para todas las plataformas de destino
En esta sección se enumeran las variables que son comunes a todas las plataformas de destino. Estas variables pueden aplicarse a clústeres de administración, clústeres de carga de trabajo o ambos. Para obtener más información, consulte Configurar información básica sobre la creación de clústeres de administración en Crear un archivo de configuración de del clúster de administración.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
APISERVER_EVENT_RATE_LIMIT_CONF_BASE64 |
✔ | ✔ | Solo clústeres basados en clases. Habilita y configura un controlador de admisión EventRateLimit para moderar el tráfico al servidor de la API de Kubernetes. Para establecer esta propiedad, cree un archivo de configuración EventRateLimit config.yaml como se describe en la documentación de Kubernetes y, a continuación, conviértalo en un valor de cadena ejecutando base64 -w 0 config.yaml |
CAPBK_BOOTSTRAP_TOKEN_TTL |
✔ | ✖ | Opcional; el valor predeterminado es 15m, 15 minutos. El valor de TTL del token de arranque utilizado por kubeadm durante las operaciones de inicialización del clúster. |
CLUSTER_API_SERVER_PORT |
✔ | ✔ | Opcional; el valor predeterminado es 6443. Esta variable se ignora si habilita NSX Advanced Load Balancer (vSphere); para anular el puerto predeterminado del servidor de la API de Kubernetes para las implementaciones con NSX Advanced Load Balancer, establezca VSPHERE_CONTROL_PLANE_ENDPOINT_PORT. |
CLUSTER_CIDR |
✔ | ✔ | Opcional; el valor predeterminado es 100.96.0.0/11. El rango de CIDR que se utilizará para los pods. Cambie el valor predeterminado solo si el rango predeterminado no está disponible. |
CLUSTER_NAME |
✔ | ✔ | Este nombre debe cumplir con los requisitos del nombre de host de DNS, tal como se describe en RFC 952 y debe modificarse en RFC 1123 y debe tener un máximo de 42 caracteres. Para los clústeres de carga de trabajo, este ajuste se reemplaza por el argumento de CLUSTER_NAME pasado a tanzu cluster create.Para los clústeres de administración, si no especifica CLUSTER_NAME, se genera un nombre único. |
CLUSTER_PLAN |
✔ | ✔ | Obligatorio. Establézcalo en dev, prod o un plan personalizado, tal como se ejemplifica en New Plan nginx.El plan dev implementa un clúster con un solo nodo de plano de control. El plan prod implementa un clúster de alta disponibilidad con tres nodos de plano de control. |
CNI |
✖ | ✔ | Opcional; el valor predeterminado es antrea. Interfaz de red de contenedor. No reemplace el valor predeterminado para los clústeres de administración. Para los clústeres de carga de trabajo, puede establecer CNI en antrea, calico o none. La opción calico no es compatible con Windows. Para obtener más información, consulte Implementar un clúster con una CNI no predeterminada. Para personalizar la configuración de Antrea, consulte Configuración de CNI de Antrea a continuación. |
CONTROLPLANE_CERTIFICATE_ROTATION_ENABLED |
✔ | ✔ | Opcional; el valor predeterminado es false. Establézcalo en true si desea que los certificados de máquina virtual del nodo de plano de control se renueven automáticamente antes de que caduquen. Para obtener más información, consulte Renovación automática de certificados del nodo de plano de control. |
CONTROLPLANE_CERTIFICATE_ROTATION_DAYS_BEFORE |
✔ | ✔ | Opcional; el valor predeterminado es 90. Si CONTROLPLANE_CERTIFICATE_ROTATION_ENABLED es true, establezca el número de días antes de la fecha de caducidad del certificado para renovar automáticamente los certificados del nodo de clúster. Para obtener más información, consulte Renovación automática de certificados del nodo de plano de control. |
ENABLE_AUDIT_LOGGING |
✔ | ✔ | Opcional; el valor predeterminado es false. Registros de auditoría para el servidor de API de Kubernetes. Para habilitar el registro de auditoría, establézcalo en true. Tanzu Kubernetes Grid escribe estos registros en /var/log/kubernetes/audit.log. Para obtener más información, consulte Registros de auditoría.Habilitar la auditoría de Kubernetes puede provocar volúmenes de registro muy altos. Para gestionar esta cantidad, VMware recomienda utilizar un reenviador de registros como Fluent Bit. |
ENABLE_AUTOSCALER |
✖ | ✔ | Opcional; el valor predeterminado es false. Si está establecido en true, debe establecer variables adicionales en la tabla Escalador automático de clústeres a continuación. |
ENABLE_CEIP_PARTICIPATION |
✔ | ✖ | Opcional; el valor predeterminado es true. Establézcalo en false para no participar en el programa de mejora de la experiencia de cliente VMware. También puede participar o no en el programa después de implementar el clúster de administración. Para obtener más información, consulte Participar o no en VMware CEIP en Gestionar participación en CEIP y Programa de mejora de la experiencia de cliente ("CEIP"). |
ENABLE_DEFAULT_STORAGE_CLASS |
✖ | ✔ | Opcional; el valor predeterminado es true. Para obtener información sobre las clases de almacenamiento, consulte Almacenamiento dinámico. |
ENABLE_MHC etc. |
✔ | ✔ | Opcional; consulte Comprobaciones de estado de máquina a continuación para obtener el conjunto completo de variables MHC y saber cómo funcionan.Para los clústeres de carga de trabajo creados por vSphere with Tanzu, establezca ENABLE_MHC en false. |
IDENTITY_MANAGEMENT_TYPE |
✔ | ✖ | Opcional; el valor predeterminado es none.Para clústeres de administración: Establezca |
INFRASTRUCTURE_PROVIDER |
✔ | ✔ | Obligatorio. Establézcalo en vsphere, aws, azure o tkg-service-vsphere. |
NAMESPACE |
✖ | ✔ | Opcional; el valor predeterminado es default, para implementar clústeres de carga de trabajo en un espacio de nombres denominado default. |
SERVICE_CIDR |
✔ | ✔ | Opcional; el valor predeterminado es 100.64.0.0/13. El rango de CIDR que se utilizará para los servicios de Kubernetes. Cambie este valor solo si el rango predeterminado no está disponible. |
Proveedores de identidades: OIDC
Si establece IDENTITY_MANAGEMENT_TYPE: oidc, establezca las siguientes variables para configurar un proveedor de identidad de OIDC. Para obtener más información, consulte Configurar la administración de identidades en Crear un archivo de configuración del clúster de administración.
Tanzu Kubernetes Grid se integra con OIDC mediante Pinniped como se describe en Acerca de la administración de identidades y acceso.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
CERT_DURATION |
✔ | ✖ | Opcional; el valor predeterminado es 2160h. Establezca esta variable si configura Pinniped para que usen certificados autofirmados administrados por cert-manager. |
CERT_RENEW_BEFORE |
✔ | ✖ | Opcional; el valor predeterminado es 360h. Establezca esta variable si configura Pinniped para que usen certificados autofirmados administrados por cert-manager. |
OIDC_IDENTITY_PROVIDER_CLIENT_ID |
✔ | ✖ | Obligatorio. El valor de client_id que obtiene del proveedor de OIDC. Por ejemplo, si su proveedor es Okta, inicie sesión en Okta, cree una aplicación Web y seleccione las opciones de credenciales del cliente para obtener una client_id y secret. Esta configuración se almacenará en un secreto al que hará referencia OIDCIdentityProvider.spec.client.secretName en el recurso personalizado de Pinniped OIDCIdentityProvider. |
OIDC_IDENTITY_PROVIDER_CLIENT_SECRET |
✔ | ✖ | Obligatorio. El valor de secret que obtiene del proveedor de OIDC. No aplique la codificación Base64 a este valor. |
OIDC_IDENTITY_PROVIDER_GROUPS_CLAIM |
✔ | ✖ | Opcional. El nombre de la notificación de grupos. Esto se utiliza para establecer un grupo de usuarios en la notificación de token de Web (JWT) JSON. El valor predeterminado es groups. Este ajuste se corresponde con OIDCIdentityProvider.spec.claims.groups en el recurso personalizado de Pinniped OIDCIdentityProvider. |
OIDC_IDENTITY_PROVIDER_ISSUER_URL |
✔ | ✖ | Obligatorio. La dirección IP o DNS del servidor de OIDC. Este ajuste se corresponde con OIDCIdentityProvider.spec.issuer en el Pinniped custom resource. |
OIDC_IDENTITY_PROVIDER_SCOPES |
✔ | ✖ | Obligatorio. Una lista separada por comas de ámbitos adicionales para solicitar en la respuesta del token. Por ejemplo, "email,offline_access". Este ajuste se corresponde con OIDCIdentityProvider.spec.authorizationConfig.additionalScopes en el recurso personalizado de Pinniped OIDCIdentityProvider. |
OIDC_IDENTITY_PROVIDER_USERNAME_CLAIM |
✔ | ✖ | Obligatorio. El nombre de la notificación de nombre de usuario. Esto se utiliza para establecer el nombre de usuario en la notificación de JWT. En función del proveedor, introduzca notificaciones como user_name, email o code. Este ajuste se corresponde con OIDCIdentityProvider.spec.claims.username en el recurso personalizado de Pinniped OIDCIdentityProvider. |
OIDC_IDENTITY_PROVIDER_ADDITIONAL_AUTHORIZE_PARAMS |
✔ | ✖ | Opcional. Agregue parámetros personalizados para enviarlos al proveedor de identidad de OIDC. En función del proveedor, es posible que estas notificaciones deban recibir un token de actualización del proveedor. Por ejemplo, prompt=consent. Separe los distintos valores con comas. Este ajuste se corresponde con OIDCIdentityProvider.spec.authorizationConfig.additionalAuthorizeParameters en el recurso personalizado de Pinniped OIDCIdentityProvider. |
OIDC_IDENTITY_PROVIDER_CA_BUNDLE_DATA_B64 |
✔ | ✖ | Opcional. Un paquete de CA con codificación Base64 para establecer TLS con los proveedores de identidad de OIDC. Este ajuste se corresponde con OIDCIdentityProvider.spec.tls.certificateAuthorityData en el recurso personalizado de Pinniped OIDCIdentityProvider. |
SUPERVISOR_ISSUER_URL |
✔ | ✖ | No modificar. Esta variable se actualiza automáticamente en el archivo de configuración cuando se ejecuta el comando tanzu cluster create command. Esta opción se corresponde con JWTAuthenticator.spec.audience en el recurso personalizado JWTAuthenticator y FederationDomain.spec.issuer en el recurso personalizado FederationDomain Pinniped. |
SUPERVISOR_ISSUER_CA_BUNDLE_DATA_B64 |
✔ | ✖ | No modificar. Esta variable se actualiza automáticamente en el archivo de configuración cuando se ejecuta el comando tanzu cluster create command. Este ajuste se corresponde con JWTAuthenticator.spec.tls.certificateAuthorityData en el recurso personalizado de Pinniped JWTAuthenticator. |
Proveedores de identidades - LDAP
Si establece IDENTITY_MANAGEMENT_TYPE: ldap, establezca las siguientes variables para configurar un proveedor de identidad de LDAP. Para obtener más información, consulte Configurar la administración de identidades en Crear un archivo de configuración del clúster de administración.
Tanzu Kubernetes Grid se integra con LDAP mediante Pinniped como se describe en Acerca de la administración de identidades y acceso. Cada una de las variables a continuación corresponde a un ajuste de configuración en el recurso personalizado de Pinniped LDAPIdentityProvider. Para obtener una descripción completa de estos ajustes e información sobre cómo configurarlos, consulte LDAPIdentityProvider en la documentación de Pinniped.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
| Para la conexión con el servidor LDAP: | |||
LDAP_HOST |
✔ | ✖ | Requerido. La dirección IP o DNS del servidor LDAP. Si el servidor LDAP está escuchando en el puerto predeterminado 636, que es la configuración segura, no es necesario especificar el puerto. Si el servidor LDAP está escuchando en un puerto diferente, proporcione la dirección y el puerto del servidor LDAP, con el formato “host:port”. Este ajuste se corresponde con LDAPIdentityProvider.spec.host en el recurso personalizado de Pinniped LDAPIdentityProvider. |
LDAP_ROOT_CA_DATA_B64 |
✔ | ✖ | Opcional. Si utiliza un endpoint de LDAPS, pegue el contenido codificado en Base64 del certificado del servidor LDAP. Este ajuste se corresponde con LDAPIdentityProvider.spec.tls.certificateAuthorityData en el recurso personalizado de Pinniped LDAPIdentityProvider. |
LDAP_BIND_DN |
✔ | ✖ | Requerido. El DN de una cuenta de servicio de aplicaciones existente. Por ejemplo, “cn=bind-user,ou=people,dc=example,dc=com”. El conector utiliza estas credenciales para buscar usuarios y grupos. Esta cuenta de servicio debe tener al menos permisos de solo lectura para realizar las consultas configuradas por las otras opciones de configuración de LDAP_*. Se incluye en el secreto de spec.bind.secretName en el recurso personalizado de Pinniped LDAPIdentityProvider. |
LDAP_BIND_PASSWORD |
✔ | ✖ | Requerido. La contraseña de la cuenta del servicio de aplicaciones establecida en LDAP_BIND_DN. Se incluye en el secreto de spec.bind.secretName en el recurso personalizado de Pinniped LDAPIdentityProvider. |
| Para la búsqueda de usuarios: | |||
LDAP_USER_SEARCH_BASE_DN |
✔ | ✖ | Requerido. El punto desde el que se inicia la búsqueda de LDAP. Por ejemplo, OU=Users,OU=domain,DC=io. Este ajuste se corresponde con LDAPIdentityProvider.spec.userSearch.base en el recurso personalizado de Pinniped LDAPIdentityProvider. |
LDAP_USER_SEARCH_FILTER |
✔ | ✖ | Opcional. Un filtro opcional que utilizará la búsqueda de LDAP. Este ajuste se corresponde con LDAPIdentityProvider.spec.userSearch.filter en el recurso personalizado de Pinniped LDAPIdentityProvider. A partir de TKG v2.3, al crear un clúster de administración o actualizar el secreto del paquete Pinniped para un clúster de administración existente, debe utilizar el formato Pinniped para este valor. Por ejemplo, &(objectClass=posixAccount)(uid={}). |
LDAP_USER_SEARCH_ID_ATTRIBUTE |
✔ | ✖ | Opcional. El atributo LDAP que contiene el identificador del usuario. El valor predeterminado es dn. Este ajuste se corresponde con LDAPIdentityProvider.spec.userSearch.attributes.uid en el recurso personalizado de Pinniped LDAPIdentityProvider. |
LDAP_USER_SEARCH_NAME_ATTRIBUTE |
✔ | ✖ | Requerido. El atributo LDAP que contiene el nombre del usuario. Por ejemplo, mail. Este ajuste se corresponde con LDAPIdentityProvider.spec.userSearch.attributes.username en el recurso personalizado de Pinniped LDAPIdentityProvider. |
| Para la búsqueda de grupos: | |||
LDAP_GROUP_SEARCH_BASE_DN |
✔ | ✖ | Opcional. El punto desde el que se inicia la búsqueda de LDAP. Por ejemplo, OU=Groups,OU=domain,DC=io. Cuando no se establece, se omite la búsqueda de grupos. Este ajuste se corresponde con LDAPIdentityProvider.spec.groupSearch.base en el recurso personalizado de Pinniped LDAPIdentityProvider. |
LDAP_GROUP_SEARCH_FILTER |
✔ | ✖ | Opcional. Un filtro opcional que utilizará la búsqueda de LDAP. Este ajuste se corresponde con LDAPIdentityProvider.spec.groupSearch.filer en el recurso personalizado de Pinniped LDAPIdentityProvider. A partir de TKG v2.3, al crear un clúster de administración o actualizar el secreto del paquete Pinniped para un clúster de administración existente, debe utilizar el formato Pinniped para este valor. Por ejemplo, &(objectClass=posixGroup)(memberUid={}). |
LDAP_GROUP_SEARCH_NAME_ATTRIBUTE |
✔ | ✖ | Opcional. El atributo LDAP que contiene el nombre del grupo. El valor predeterminado es dn. Este ajuste se corresponde con LDAPIdentityProvider.spec.groupSearch.attributes.groupName en el recurso personalizado de Pinniped LDAPIdentityProvider. |
LDAP_GROUP_SEARCH_USER_ATTRIBUTE |
✔ | ✖ | Opcional. El atributo del registro de usuario que se utiliza como el valor del atributo de pertenencia del registro de grupo. El valor predeterminado es dn. Este ajuste se corresponde con LDAPIdentityProvider.spec.groupSearch.userAttributeForFilter en el recurso personalizado de Pinniped LDAPIdentityProvider. |
LDAP_GROUP_SEARCH_SKIP_ON_REFRESH |
✔ | ✖ | Opcional. El valor predeterminado es false. Cuando se establece en true, las pertenencias a grupos de un usuario solo se actualizan al principio de la sesión diaria del usuario. Configurar LDAP_GROUP_SEARCH_SKIP_ON_REFRESH en true no se recomienda y solo se debe realizar cuando, de lo contrario, no sea posible hacer que la consulta de grupo sea lo suficientemente rápida como para ejecutarse durante las actualizaciones de la sesión. Este ajuste se corresponde con LDAPIdentityProvider.spec.groupSearch.skipGroupRefresh en el recurso personalizado de Pinniped LDAPIdentityProvider. |
Configuración de nodos
Configure los nodos de trabajo y plano de control, así como el sistema operativo que ejecutan las instancias de nodo. Para obtener más información, consulte Configurar ajustes del nodo en Crear un archivo de configuración del clúster de administración.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
CONTROL_PLANE_MACHINE_COUNT |
✔ | ✔ | Opcional. Implemente un clúster de carga de trabajo con más nodos de plano de control que los planos dev y prod definidos de forma predeterminada. El número de nodos del plano de control que especifique debe ser impar. |
CONTROL_PLANE_NODE_LABELS |
✔ | ✔ | Solo clústeres basados en clases. Asigne etiquetas persistentes personalizadas a los nodos del plano de control, por ejemplo CONTROL_PLANE_NODE_LABELS: ‘key1=value1,key2=value2’. Para configurar esta opción en un clúster heredado basado en planes, utilice una superposición de ytt como se describe en Etiquetas de nodo personalizadas.Las etiquetas de nodo de trabajo se establecen en su grupo de nodos como se describe en Administrar grupos de nodos de diferentes tipos de máquina virtual. |
CONTROL_PLANE_NODE_NAMESERVERS |
✔ | ✔ | Solo vSphere. Esto permite al usuario especificar una lista de servidores DNS delimitada por comas que se configurarán en los nodos del plano de control, por ejemplo, CONTROL_PLANE_NODE_NAMESERVERS: 10.132.7.1, 10.142.7.1. Compatible con Ubuntu y Photon; no se admite en Windows. Para ver un ejemplo de caso práctico, consulte Node IPAM a continuación. |
CONTROL_PLANE_NODE_SEARCH_DOMAINS |
✔ | ✔ | Solo clústeres basados en clases. Configura los dominios de búsqueda .local para los nodos del clúster, por ejemplo, CONTROL_PLANE_NODE_SEARCH_DOMAINS: corp.local. Para configurar esta opción en un clúster heredado basado en planes en vSphere, utilice una superposición ytt como se describe en Resolver dominio local. |
CONTROLPLANE_SIZE |
✔ | ✔ | Opcional. Tamaño de las máquinas virtuales del nodo de plano de control. Reemplaza los parámetros SIZE y VSPHERE_CONTROL_PLANE_. Consulte SIZE para conocer los posibles valores. |
OS_ARCH |
✔ | ✔ | Opcional. Arquitectura del sistema operativo de la máquina virtual del nodo. La opción predeterminada y solo actual es amd64. |
OS_NAME |
✔ | ✔ | Opcional. Sistema operativo de máquina virtual de nodo. El valor predeterminado es ubuntu para Ubuntu LTS. También se puede photon para Photon OS en vSphere o amazon para Amazon Linux en AWS. |
OS_VERSION |
✔ | ✔ | Opcional. Versión del sistema operativo de OS_NAME anterior. El valor predeterminado es 20.04 para Ubuntu. Puede ser 3 para Photon en vSphere y 2 para Amazon Linux en AWS. |
SIZE |
✔ | ✔ | Opcional. Tamaño de las máquinas virtuales del nodo de trabajo y del plano de control. Reemplaza los parámetros VSPHERE_CONTROL_PLANE_* y VSPHERE_WORKER_*. Para vSphere, establezca small, medium, large o extra-large, como se describe en Tamaños de nodo predefinidos. Para AWS, establezca un tipo de instancia, por ejemplo, t3.small. Para Azure, establezca un tipo de instancia, por ejemplo, Standard_D2s_v3. |
WORKER_MACHINE_COUNT |
✔ | ✔ | Opcional. Implemente un clúster de carga de trabajo con más nodos de trabajo que los planos dev y prod definidos de forma predeterminada. |
WORKER_NODE_NAMESERVERS |
✔ | ✔ | Solo vSphere. Esto permite al usuario especificar una lista de servidores DNS delimitada por comas que se configurarán en los nodos del trabajo, por ejemplo, WORKER_NODE_NAMESERVERS: 10.132.7.1, 10.142.7.1. Compatible con Ubuntu y Photon; no se admite en Windows. Para ver un ejemplo de caso práctico, consulte Node IPAM a continuación. |
WORKER_NODE_SEARCH_DOMAINS |
✔ | ✔ | Solo clústeres basados en clases. Configura los dominios de búsqueda .local para los nodos del clúster, por ejemplo, CONTROL_PLANE_NODE_SEARCH_DOMAINS: corp.local. Para configurar esta opción en un clúster heredado basado en planes en vSphere, utilice una superposición ytt como se describe en Resolver dominio local. |
WORKER_SIZE |
✔ | ✔ | Opcional. Tamaño de las máquinas virtuales del nodo de trabajo. Reemplaza los parámetros VSPHERE_WORKER_SIZE y . Consulte SIZE para conocer los posibles valores. |
CUSTOM_TDNF_REPOSITORY_CERTIFICATE |
✔ | ✔ | (Vista previa técnica) Opcional. Establezca esta opción si utiliza un servidor de repositorio tdnf personalizado con un certificado autofirmado, en lugar del servidor de repositorio tdnf predeterminado photon. Introduzca el contenido del certificado codificado en base64 del servidor de repositorio de tdnf. Elimina todos los repositorios en |
Estándares de seguridad de pods para el controlador de admisión de seguridad de pods
Configure los estándares de seguridad de pods para un controlador de admisión de seguridad de pods (Pod Security Admission, PSA) de todo el clúster, el plano de control y los nodos de trabajo, así como el sistema operativo que ejecutan las instancias de nodo. Para obtener más información, consulte Controlador de admisión de seguridad de pods.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
POD_SECURITY_STANDARD_AUDIT |
✖ | ✔ | Opcional, por defecto es restricted. Establece la directiva de seguridad para el modo audit del controlador PSA en todo el clúster. Valores posibles: restricted, baseline y privileged. |
POD_SECURITY_STANDARD_DEACTIVATED |
✖ | ✔ | Opcional, el valor predeterminado es false. Establézcalo en true para desactivar PSA en todo el clúster. |
POD_SECURITY_STANDARD_ENFORCE |
✖ | ✔ | Opcional, de forma predeterminada no tiene ningún valor. Establece la directiva de seguridad para el modo enforce del controlador PSA en todo el clúster. Valores posibles: restricted, baseline y privileged. |
POD_SECURITY_STANDARD_WARN |
✖ | ✔ | Opcional, por defecto es restricted. Establece la directiva de seguridad para el modo warn del controlador PSA en todo el clúster. Valores posibles: restricted, baseline y privileged. |
Ajuste de Kubernetes (solo clústeres basados en clases)
Los servidores de la API de Kubernetes, Kubelets y otros componentes exponen varias marcas de configuración para el ajuste; por ejemplo, la marca --tls-cipher-suites para configurar conjuntos de claves de cifrado para la protección de la seguridad, la marca --election-timeout para aumentar el tiempo de espera de etcd en un clúster grande, etc.
ImportanteEstas variables de configuración de Kubernetes son para usuarios avanzados. VMware no garantiza la funcionalidad de los clústeres configurados con combinaciones arbitrarias de estas opciones.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
APISERVER_EXTRA_ARGS |
✔ | ✔ | Solo clústeres basados en clases. Especifique kube-apiserver marcas con el formato "key1=value1;key2=value2". Por ejemplo, establezca paquetes de cifrado con APISERVER_EXTRA_ARGS: “tls-min-version=VersionTLS12;tls-cipher-suites=TLS_RSA_WITH_AES_256_GCM_SHA384” |
CONTROLPLANE_KUBELET_EXTRA_ARGS |
✔ | ✔ | Solo clústeres basados en clases. Especifique las marcas kubelet del plano de control con el formato "key1=value1;key2=value2". Por ejemplo, limite el número de pods del plano de control con CONTROLPLANE_KUBELET_EXTRA_ARGS: “max-pods=50” |
ETCD_EXTRA_ARGS |
✔ | ✔ | Solo clústeres basados en clases. Especifique las marcas etcd con el formato "key1=value1;key2=value2". Por ejemplo, si el clúster tiene más de 500 nodos o el almacenamiento presenta un rendimiento deficiente, puede aumentar heartbeat-interval y election-timeout con ETCD_EXTRA_ARGS: “heartbeat-interval=300;election-timeout=2000” |
KUBE_CONTROLLER_MANAGER_EXTRA_ARGS |
✔ | ✔ | Solo clústeres basados en clases. Especifique las marcas kube-controller-manager con el formato "key1=value1;key2=value2". Por ejemplo, desactive la generación de perfiles de rendimiento con KUBE_CONTROLLER_MANAGER_EXTRA_ARGS: “profiling=false” |
KUBE_SCHEDULER_EXTRA_ARGS |
✔ | ✔ | Solo clústeres basados en clases. Especifique las marcas kube-scheduler con el formato "key1=value1;key2=value2". Por ejemplo, habilite el modo de acceso de pod único con KUBE_SCHEDULER_EXTRA_ARGS: “feature-gates=ReadWriteOncePod=true” |
WORKER_KUBELET_EXTRA_ARGS |
✔ | ✔ | Solo clústeres basados en clases. Especifique las marcas de kubelet de trabajo con el formato "key1=value1;key2=value2". Por ejemplo, limite el número de pods de trabajo con WORKER_KUBELET_EXTRA_ARGS: “max-pods=50” |
Escalador automático de clústeres
Las siguientes variables adicionales están disponibles para configurar si ENABLE_AUTOSCALER está establecido en true. Para obtener información sobre el escalador automático de clústeres, consulte Escalar clústeres de carga de trabajo.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
AUTOSCALER_MAX_NODES_TOTAL |
✖ | ✔ | Opcional; el valor predeterminado es 0. Cantidad total máxima de nodos en el clúster, trabajo más plano de control. Establece el valor del parámetro Escalador automático de clústeres max-nodes-total. El escalador automático de clústeres no intenta escalar el clúster más allá de este límite. Si se establece en 0, el escalador automático de clústeres toma decisiones de escala en función de los ajustes mínimos y máximos de SIZE que configure. |
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_ADD |
✖ | ✔ | Opcional; el valor predeterminado es 10m. Establece el valor del parámetro Escalador automático de clústeres scale-down-delay-after-add. Cantidad de tiempo que el escalador automático de clústeres espera después de una operación de escalado vertical para después reanudar los análisis de reducción horizontal. |
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_DELETE |
✖ | ✔ | Opcional; el valor predeterminado es 10s. Establece el valor del parámetro Escalador automático de clústeres scale-down-delay-after-delete. Cantidad de tiempo que el escalador automático de clústeres espera después de eliminar un nodo y, a continuación, reanuda los análisis de escalado vertical. |
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_FAILURE |
✖ | ✔ | Opcional; el valor predeterminado es 3m. Establece el valor del parámetro Escalador automático de clústeres scale-down-delay-after-failure. Cantidad de tiempo que el escalador automático de clústeres espera después de un error de reducción horizontal para después reanudar los análisis de reducción horizontal. |
AUTOSCALER_SCALE_DOWN_UNNEEDED_TIME |
✖ | ✔ | Opcional; el valor predeterminado es 10m. Establece el valor del parámetro Escalador automático de clústeres scale-down-unneeded-time. Cantidad de tiempo que el escalador automático de clústeres debe esperar antes de reducir horizontalmente un nodo apto. |
AUTOSCALER_MAX_NODE_PROVISION_TIME |
✖ | ✔ | Opcional; el valor predeterminado es 15m. Establece el valor del parámetro Escalador automático de clústeres max-node-provision-time. Cantidad máxima de tiempo que el escalador automático de clústeres espera a que se aprovisione un nodo. |
AUTOSCALER_MIN_SIZE_0 |
✖ | ✔ | Obligatorio, todas las IaaS. Cantidad mínima de nodos de trabajo. El escalador automático de clústeres no intenta reducir horizontalmente los nodos por debajo de este límite. Para los clústeres de prod en AWS, AUTOSCALER_MIN_SIZE_0 establece el número mínimo de nodos de trabajo en la primera zona de disponibilidad. Si no se establece, el valor predeterminado es WORKER_MACHINE_COUNT para clústeres con un solo nodo de trabajo o WORKER_MACHINE_COUNT_0 para clústeres con varios nodos de trabajo. |
AUTOSCALER_MAX_SIZE_0 |
✖ | ✔ | Obligatorio, todas las IaaS. Cantidad máxima de nodos de trabajo. El escalador automático de clústeres no intenta escalar verticalmente los nodos de más allá de este límite. Para los clústeres de prod en AWS, AUTOSCALER_MAX_SIZE_0 establece el número máximo de nodos de trabajo en la primera zona de disponibilidad. Si no se establece, el valor predeterminado es WORKER_MACHINE_COUNT para clústeres con un solo nodo de trabajo o WORKER_MACHINE_COUNT_0 para clústeres con varios nodos de trabajo. |
AUTOSCALER_MIN_SIZE_1 |
✖ | ✔ | Obligatorio, utilícelo solo para clústeres de prod en AWS. Cantidad mínima de nodos de trabajo del segundo AZ. El escalador automático de clústeres no intenta reducir horizontalmente los nodos por debajo de este límite. Si no se establece, el valor predeterminado es WORKER_MACHINE_COUNT_1. |
AUTOSCALER_MAX_SIZE_1 |
✖ | ✔ | Obligatorio, utilícelo solo para clústeres de prod en AWS. Cantidad máxima de nodos de trabajo en la segunda zona de disponibilidad. El escalador automático de clústeres no intenta escalar verticalmente los nodos de más allá de este límite. Si no se establece, el valor predeterminado es WORKER_MACHINE_COUNT_1. |
AUTOSCALER_MIN_SIZE_2 |
✖ | ✔ | Obligatorio, utilícelo solo para clústeres de prod en AWS. Cantidad mínima de nodos de trabajo del tercero AZ. El escalador automático de clústeres no intenta reducir horizontalmente los nodos por debajo de este límite. Si no se establece, el valor predeterminado es WORKER_MACHINE_COUNT_2. |
AUTOSCALER_MAX_SIZE_2 |
✖ | ✔ | Obligatorio, utilícelo solo para clústeres de prod en AWS. Cantidad máxima de nodos de trabajo del tercero AZ. El escalador automático de clústeres no intenta escalar verticalmente los nodos de más allá de este límite. Si no se establece, el valor predeterminado es WORKER_MACHINE_COUNT_2. |
Configuración de proxy
Si el entorno tiene acceso a Internet restringido o incluye servidores proxy, tiene la opción de configurar Tanzu Kubernetes Grid para enviar tráfico HTTP y HTTPS saliente desde kubelet, containerd y el plano de control a los servidores proxy.
Tanzu Kubernetes Grid permite habilitar proxies para cualquiera de las siguientes opciones:
- Para el clúster de administración y uno o varios clústeres de carga de trabajo
- Solo para el clúster de administración
- Para uno o varios clústeres de carga de trabajo
Para obtener más información, consulte Configurar proxies en Crear un archivo de configuración del clúster de administración.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
TKG_HTTP_PROXY_ENABLED |
✔ | ✔ | Opcional, para enviar tráfico HTTP(S) saliente desde el clúster de administración a un proxy (por ejemplo, en un entorno con acceso a Internet restringido), establezca esta opción en |
TKG_HTTP_PROXY |
✔ | ✔ | Opcional, establezca si desea configurar un proxy; para desactivar la configuración del proxy para un clúster individual, establézcalo en
Por ejemplo, |
TKG_HTTPS_PROXY |
✔ | ✔ | Opcional, establezca si desea configurar un proxy. Solo se aplica cuando TKG_HTTP_PROXY_ENABLED = true. La URL del proxy HTTPS. Puede establecer esta variable en el mismo valor que TKG_HTTP_PROXY o proporcionar un valor diferente. La URL debe empezar con http:// Si establece TKG_HTTPS_PROXY, también debe establecer TKG_HTTP_PROXY. |
TKG_NO_PROXY |
✔ | ✔ | Opcional. Solo se aplica cuando Uno o varios CIDR de red o nombres de host que deben omitir el proxy HTTP(S), separados por comas y enumerados sin espacios ni caracteres comodín ( Por ejemplo, Internamente, Tanzu Kubernetes Grid anexa Si establece TKG_NO_PROXY permite que las máquinas virtuales del clúster se comuniquen directamente con la infraestructura que ejecuta la misma red, detrás del mismo proxy. Esto puede incluir, entre otros, la infraestructura, el servidor de OIDC o LDAP, Harbor, VMware NSX y NSX Advanced Load Balancer (vSphere). Establezca TKG_NO_PROXY para incluir todos los endpoints a los que deben acceder los clústeres, pero a los que los servidores proxy no pueden acceder. |
TKG_PROXY_CA_CERT |
✔ | ✔ | Opcional. Establezca si el servidor proxy utiliza un certificado autofirmado. Proporcione el certificado de CA en formato codificado en base64, por ejemplo …TKG_PROXY_CA_CERT: “LS0t[]tLS0tLQ==””. |
TKG_NODE_SYSTEM_WIDE_PROXY |
✔ | ✔ | (Vista previa técnica) Opcional. Coloca los siguientes ajustes en export HTTP_PROXY=$TKG_HTTP_PROXY Cuando los usuarios utilizan SSH en el nodo de TKG y ejecutan comandos, de forma predeterminada, los comandos utilizan las variables definidas. Los procesos systemd no se ven afectados. |
Configuración de CNI de Antrea
Variables opcionales adicionales que se establecerán si CNI está establecido en antrea. Para obtener más información, consulte Configurar CNI de Antrea en Crear un archivo de configuración del clúster de administración.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
ANTREA_DISABLE_UDP_TUNNEL_OFFLOAD |
✔ | ✔ | Opcional; el valor predeterminado es false. Se establece en true para desactivar la descarga de suma de comprobación UDP de Antrea. Al establecer esta variable en true, se evitan problemas conocidos con la red subyacente y los controladores de red de NIC físicas. |
ANTREA_EGRESS |
✔ | ✔ | Opcional; el valor predeterminado es true. Habilite esta variable para definir la IP de SNAT que se utiliza para el tráfico del pod que sale del clúster. Para obtener más información, consulte Egress en la documentación de Antrea. |
ANTREA_EGRESS_EXCEPT_CIDRS |
✔ | ✔ | Opcional. Los rangos de CIDR que salen no tendrán SNAT para el tráfico de pod saliente. Incluya las comillas (““). Por ejemplo, “10.0.0.0/6”. |
ANTREA_ENABLE_USAGE_REPORTING |
✔ | ✔ | Opcional; el valor predeterminado es false. Activa o desactiva los informes de uso (telemetría). |
ANTREA_FLOWEXPORTER |
✔ | ✔ | Opcional; el valor predeterminado es false. Se establece en true para la visibilidad del flujo de red. El exportador de flujos sondea los flujos de conntrack periódicamente y exporta los flujos como registros de flujo de IPFIX. Para obtener más información, consulte Visibilidad del flujo de red en Antrea en la documentación de Antrea. |
ANTREA_FLOWEXPORTER_ACTIVE_TIMEOUT |
✔ | ✔ | Opcional; el valor predeterminado es Nota: Las unidades de tiempo válidas son |
ANTREA_FLOWEXPORTER_COLLECTOR_ADDRESS |
✔ | ✔ | Opcional. Esta variable proporciona la dirección del recopilador IPFIX. Incluya las comillas (““). El valor predeterminado es “flow-aggregator.flow-aggregator.svc:4739:tls”. Para obtener más información, consulte Visibilidad del flujo de red en Antrea en la documentación de Antrea. |
ANTREA_FLOWEXPORTER_IDLE_TIMEOUT |
✔ | ✔ | Opcional; el valor predeterminado es Nota: Las unidades de tiempo válidas son |
ANTREA_FLOWEXPORTER_POLL_INTERVAL |
✔ | ✔ | Opcional; el valor predeterminado es Nota: Las unidades de tiempo válidas son |
ANTREA_IPAM |
✔ | ✔ | Opcional; el valor predeterminado es false. Establézcalo en true para asignar direcciones IP de IPPools. El conjunto deseado de rangos de IP, de forma opcional con VLAN, se define con CRD IPPool. Para obtener más información, consulte Capacidades de IPAM de Antrea en la documentación de Antrea. |
ANTREA_KUBE_APISERVER_OVERRIDE |
✔ | ✔ | Opcional. Especifique la dirección del servidor de API de Kubernetes. Para obtener más información, consulte Eliminar kube-proxy en la documentación de Antrea. |
ANTREA_MULTICAST |
✔ | ✔ | Opcional; el valor predeterminado es false. Se establece en true para el tráfico de multidifusión dentro de la red del clúster (entre pods) y entre la red externa y la red del clúster. |
ANTREA_MULTICAST_INTERFACES |
✔ | ✔ | Opcional. Los nombres de la interfaz en los nodos de que se utilizan para reenviar tráfico de multidifusión. Incluya las comillas (””). Por ejemplo, “eth0”. |
ANTREA_NETWORKPOLICY_STATS |
✔ | ✔ | Opcional; el valor predeterminado es true. Habilite esta variable para recopilar estadísticas de NetworkPolicy. Los datos estadísticos incluyen el número total de sesiones, paquetes y bytes permitidos o denegados por una instancia de NetworkPolicy. |
ANTREA_NO_SNAT |
✔ | ✔ | Opcional; el valor predeterminado es false. Establézcalo en true para desactivar la traducción de direcciones de red de origen (SNAT). |
ANTREA_NODEPORTLOCAL |
✔ | ✔ | Opcional; el valor predeterminado es true. Establézcalo en false para desactivar el modo NodePortLocal. Para obtener más información, consulte NodePortLocal (NPL) en la documentación de Antrea. |
ANTREA_NODEPORTLOCAL_ENABLED |
✔ | ✔ | Opcional. Establézcalo en true para habilitar el modo NodePortLocal, como se describe en NodePortLocal (NPL) en la documentación de Antrea. |
ANTREA_NODEPORTLOCAL_PORTRANGE |
✔ | ✔ | Opcional; el valor predeterminado es 61000-62000. Para obtener más información, consulte NodePortLocal (NPL) en la documentación de Antrea. |
ANTREA_POLICY |
✔ | ✔ | Opcional; el valor predeterminado es true. Activa o desactiva la API de directiva nativa de Antrea, que son CRD de directivas específicas de Antrea. Además, la implementación de directivas de red de Kubernetes permanece activa cuando esta variable está habilitada. Para obtener información sobre el uso de directivas de red, consulte CDR de directiva de red de Antrea en la documentación de Antrea. |
ANTREA_PROXY |
✔ | ✔ | Opcional; el valor predeterminado es false. Activa o desactiva AntreaProxy, para reemplazar kube-proxy para el tráfico de servicio de pod a ClusterIP, a fin de mejorar el rendimiento y reducir la latencia. Tenga en cuenta que kube-proxy se sigue utilizando para otros tipos de tráfico de servicios. Para obtener más información sobre el uso de proxies, consulte AntreaProxy en la documentación de Antrea. |
ANTREA_PROXY_ALL |
✔ | ✔ | Opcional; el valor predeterminado es false. Activa o desactiva AntreaProxy para controlar todo el tráfico de servicio, incluido el tráfico de NodePort, LoadBalancer y ClusterIP. Para reemplazar kube-proxy por AntreaProxy, se debe habilitar ANTREA_PROXY_ALL. Para obtener más información sobre el uso de proxies, consulte AntreaProxy en la documentación de Antrea. |
ANTREA_PROXY_LOAD_BALANCER_IPS |
✔ | ✔ | Opcional; el valor predeterminado es true. Establézcalo en false para dirigir el tráfico de equilibrio de carga al equilibrador de carga externo. |
ANTREA_PROXY_NODEPORT_ADDRS |
✔ | ✔ | Opcional. La dirección IPv4 o IPv6 para NodePort. Incluya las comillas (““). |
ANTREA_PROXY_SKIP_SERVICES |
✔ | ✔ | Opcional. Una matriz de valores de cadena que se puede utilizar para indicar una lista de servicios que AntreaProxy debe ignorar. El tráfico a estos servicios no será con equilibrio de carga. Incluya las comillas (””). Por ejemplo, una ClusterIP válida, como 10.11.1.2, o un nombre de servicio con un espacio de nombres, como kube-system/kube-dns, son valores válidos. Para obtener más información, consulte Casos prácticos especiales en la documentación de Antrea. |
ANTREA_SERVICE_EXTERNALIP |
✔ | ✔ | Opcional; el valor predeterminado es false. Establézcalo en true para permitir que un controlador asigne direcciones IP externas desde un recurso ExternalIPPool para servicios con el tipo LoadBalancer. Para obtener más información sobre cómo implementar servicios de tipo LoadBalancer, consulte Servicio de tipo LoadBalancer en la documentación de Antrea. |
ANTREA_TRACEFLOW |
✔ | ✔ | Opcional; el valor predeterminado es true. Para obtener información sobre el uso de Traceflow, consulte la Guía de usuario de Traceflow en la documentación de Antrea. |
ANTREA_TRAFFIC_ENCAP_MODE |
✔ | ✔ | Opcional; el valor predeterminado es Nota: los modos El modo |
ANTREA_TRANSPORT_INTERFACE |
✔ | ✔ | Opcional. El nombre de la interfaz en el nodo de que se utiliza para tunelización o enrutamiento del tráfico. Incluya las comillas (““). Por ejemplo, “eth0”. |
ANTREA_TRANSPORT_INTERFACE_CIDRS |
✔ | ✔ | Opcional. Los CIDR de red de la interfaz en el nodo de que se utiliza para tunelización o enrutamiento del tráfico. Incluya las comillas (””). Por ejemplo, “10.0.0.2/24”. |
Comprobaciones de estado de máquinas
Si desea configurar las comprobaciones de estado de las máquinas para los clústeres de administración y carga de trabajo, establezca las siguientes variables. Para obtener más información, consulte Configurar comprobaciones de estado de máquinas en Crear un archivo de configuración del clúster de administración. Para obtener información sobre cómo realizar operaciones de comprobación de estado de máquinas después de la implementación del clúster, consulte Configurar comprobaciones de estado de máquinas para clústeres de carga de trabajo.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
ENABLE_MHC |
✔ | basado en clases: ✖ basado en planes: ✔ |
Opcional, establézcalo en true o false para activar o desactivar el controlador MachineHealthCheck tanto en el plano de control como en los nodos de trabajo del clúster de carga de trabajo o de administración de destino. O déjelo en blanco y establezca ENABLE_MHC_CONTROL_PLANE y ENABLE_MHC_WORKER_NODE por separado para los nodos de trabajo y el plano de control. El valor predeterminado está vacío.El controlador proporciona supervisión del estado de la máquina y reparación automática. Para los clústeres de carga de trabajo creados por vSphere with Tanzu, establézcalos en false. |
ENABLE_MHC_CONTROL_PLANE |
✔ | Opcional; el valor predeterminado es true. Para obtener más información, consulte la tabla siguiente. |
|
ENABLE_MHC_WORKER_NODE |
✔ | Opcional; el valor predeterminado es true. Para obtener más información, consulte la tabla siguiente. |
|
MHC_MAX_UNHEALTHY_CONTROL_PLANE |
✔ | ✖ | Opcional; solo clústeres basados en clases. El valor predeterminado es 100%. Si el número de máquinas en mal estado supera el valor establecido, el controlador MachineHealthCheck no realiza la corrección. |
MHC_MAX_UNHEALTHY_WORKER_NODE |
✔ | ✖ | Opcional; solo clústeres basados en clases. El valor predeterminado es 100%. Si el número de máquinas en mal estado supera el valor establecido, el controlador MachineHealthCheck no realiza la corrección. |
MHC_FALSE_STATUS_TIMEOUT |
✔ | basado en clases: ✖ basado en planes: ✔ |
Opcional; el valor predeterminado es 12m. Tiempo que el controlador MachineHealthCheck permite que la condición Ready de un nodo permanezca en False antes de considerar que la máquina está en mal estado y volver a crearla. |
MHC_UNKNOWN_STATUS_TIMEOUT |
✔ | Opcional; el valor predeterminado es 5m. Tiempo que el controlador MachineHealthCheck permite que la condición Ready de un nodo permanezca en Unknown antes de considerar que la máquina está en mal estado y volver a crearla. |
|
NODE_STARTUP_TIMEOUT |
✔ | Opcional; el valor predeterminado es 20m. Tiempo que el controlador MachineHealthCheck espera a que un nodo se una a un clúster antes de considerar que la máquina está en mal estado y volver a crearla. |
|
Utilice la siguiente tabla para determinar cómo configurar las variables ENABLE_MHC, ENABLE_MHC_CONTROL_PLANE y ENABLE_MHC_WORKER_NODE.
Valor de ENABLE_MHC |
Valor de ENABLE_MHC_CONTROL_PLANE |
Valor de ENABLE_MHC_WORKER_NODE |
¿Se habilitó la corrección del plano de control? | ¿Se habilitó la corrección del nodo de trabajo? |
|---|---|---|---|---|
true / Emptytrue/vacío |
true / false / vacío |
true / false / vacío |
Sí | Sí |
false |
true/vacío |
true/vacío |
Sí | Sí |
false |
true/vacío |
false |
Sí | No |
false |
false |
true/vacío |
No | Sí |
Configuración del registro de imágenes privadas
Si implementa los clústeres de administración de Tanzu Kubernetes Grid y los clústeres de Kubernetes en entornos que no están conectados a Internet, debe configurar un repositorio de imágenes privado dentro del firewall y rellenarlo con las imágenes de Tanzu Kubernetes Grid. Para obtener información sobre la configuración de un repositorio de imágenes privado, consulte Preparar un entorno restringido por Internet.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
ADDITIONAL_IMAGE_REGISTRY_1, ADDITIONAL_IMAGE_REGISTRY_2, ADDITIONAL_IMAGE_REGISTRY_3 |
✔ | ✔ | Solo clústeres de administración independientes y cargas de trabajo basados en clases. Las direcciones IP o los FQDN de hasta tres registros privados de confianza, además del registro de imágenes principal establecido por TKG_CUSTOM_IMAGE_REPOSITORY, para que los nodos del clúster de carga de trabajo accedan. Consulte Registros de confianza para un clúster basado en clases. |
ADDITIONAL_IMAGE_REGISTRY_1_CA_CERTIFICATE, ADDITIONAL_IMAGE_REGISTRY_2_CA_CERTIFICATE, ADDITIONAL_IMAGE_REGISTRY_3_CA_CERTIFICATE |
✔ | ✔ | Solo clústeres de administración independientes y cargas de trabajo basados en clases. Los certificados de CA en formato codificado en base64 de registros de imágenes privadas configurados con ADDITIONAL_IMAGE_REGISTRY- anterior. Por ejemplo, …ADDITIONAL_IMAGE_REGISTRY_1_CA_CERTIFICATE: “LS0t[]tLS0tLQ==”. |
ADDITIONAL_IMAGE_REGISTRY_1_SKIP_TLS_VERIFY, ADDITIONAL_IMAGE_REGISTRY_2_SKIP_TLS_VERIFY, ADDITIONAL_IMAGE_REGISTRY_3_SKIP_TLS_VERIFY |
✔ | ✔ | Solo clústeres de administración independientes y cargas de trabajo basados en clases. Establézcalo en ADDITIONAL_IMAGE_REGISTRY- para los registros de imágenes privadas configurados con anterior que utilicen un certificado autofirmado pero no utilicen ADDITIONAL_IMAGE_REGISTRY_CA_CERTIFICATE. ADDITIONAL_IMAGE_REGISTRYDebido a que el webhook de conectividad de Tanzu inserta el certificado de CA de Harbor en los nodos del clúster, _SKIP_TLS_VERIFY should always be set to false cuando se utiliza Harbor. |
TKG_CUSTOM_IMAGE_REPOSITORY |
✔ | ✔ | Obligatorio si implementa Tanzu Kubernetes Grid en un entorno restringido por Internet. Proporcione la dirección IP o el FQDN del registro privado que contiene imágenes del sistema de TKG desde las que arrancan los clústeres, lo que se denomina registro de imagen principal a continuación. Por ejemplo, custom-image-repository.io/yourproject. |
TKG_CUSTOM_IMAGE_REPOSITORY_SKIP_TLS_VERIFY |
✔ | ✔ | Opcional. Establézcalo en true si el registro principal de imágenes privado utiliza un certificado autofirmado y usted no utiliza TKG_CUSTOM_IMAGE_REPOSITORY_CA_CERTIFICATE. Debido a que el webhook de conectividad de Tanzu inserta el certificado de CA de Harbor en los nodos del clúster, TKG_CUSTOM_IMAGE_REPOSITORY_SKIP_TLS_VERIFY siempre debe establecerse en false cuando se utiliza Harbor. |
TKG_CUSTOM_IMAGE_REPOSITORY_CA_CERTIFICATE |
✔ | ✔ | Opcional. Establezca si el registro principal de imágenes privado utiliza un certificado autofirmado. Proporcione el certificado de CA en formato codificado en base64, por ejemplo, …TKG_CUSTOM_IMAGE_REPOSITORY_CA_CERTIFICATE: “LS0t[]tLS0tLQ==”. |
vSphere
Las opciones de la siguiente tabla son las opciones mínimas que se especifican en el archivo de configuración del clúster al implementar clústeres de carga de trabajo en vSphere. La mayoría de estas opciones son las mismas para el clúster de carga de trabajo y el clúster de administración que se utiliza para implementarlo.
Para obtener más información sobre los archivos de configuración de vSphere, consulte Configuración del clúster de administración para vSphere e Implementar clústeres de carga de trabajo en vSphere.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
DEPLOY_TKG_ON_VSPHERE7 |
✔ | ✔ | Opcional. Si se implementa en vSphere 7 u 8, establézcalo en true para omitir la solicitud sobre la implementación en vSphere 7 u 8, o false. Consulte Clústeres de administración en vSphere with Tanzu. |
ENABLE_TKGS_ON_VSPHERE7 |
✔ | ✔ | Opcional si se implementa en vSphere 7 u 8, establézcalo en true para que se redireccione a la página de la interfaz de usuario de habilitación de vSphere with Tanzu o false. Consulte Clústeres de administración en vSphere with Tanzu. |
NTP_SERVERS |
✔ | ✔ | Solo clústeres basados en clases. Configura el servidor NTP del clúster si va a implementar clústeres en un entorno de vSphere que no tenga la opción 42 de DHCP, por ejemplo, NTP_SERVERS: time.google.com. Para configurar esta opción en un clúster heredado basado en planes, utilice una superposición de ytt como se describe en Configurar NTP sin la opción 42 de DHCP (vSphere). |
TKG_IP_FAMILY |
✔ | ✔ | Opcional. Para implementar un clúster en vSphere 7 u 8 con IPv6 puro, establézcalo en ipv6. Para las redes de pila dual (experimental), consulte Clústeres de pila dual. |
VIP_NETWORK_INTERFACE |
✔ | ✔ | Opcional. Debe establecerse en eth0, eth1, etc. Nombre de la interfaz de red, por ejemplo, una interfaz Ethernet. El valor predeterminado es eth0. |
VSPHERE_AZ_CONTROL_PLANE_MATCHING_LABELS |
✔ | ✔ | Para los clústeres implementados en varias zonas de disponibilidad, establece etiquetas de selector de clave/valor para especificar las AZ en las que pueden implementarse los nodos del plano de control del clúster. Esto permite configurar los nodos, por ejemplo, para que se ejecuten en todas las zonas de disponibilidad en una región y un entorno específicos sin enumerar las zonas de disponibilidad de forma individual, por ejemplo: “region=us-west-1,environment=staging”. Consulte Ejecución de clústeres en varias zonas de disponibilidad |
VSPHERE_CONTROL_PLANE_DISK_GIB |
✔ | ✔ | Opcional. El tamaño en gigabytes del disco de las máquinas virtuales del nodo de plano de control. Incluya las comillas (““). Por ejemplo, "30". |
VSPHERE_AZ_0, VSPHERE_AZ_1, VSPHERE_AZ_2 |
✔ | ✔ | Opcional Las zonas de implementación en las que se implementan las implementaciones de máquinas en un clúster. Consulte Ejecución de clústeres en varias zonas de disponibilidad |
VSPHERE_CONTROL_PLANE_ENDPOINT |
✔ | ✔ | Obligatorio para Kube-Vip. Dirección IP virtual estática o nombre de dominio completo (FQDN) asignado a una dirección estática, para las solicitudes de API al clúster. Esta opción es necesaria si utiliza Kube-VIP para el endpoint del servidor de API, como se configuró al establecer AVI_CONTROL_PLANE_HA_PROVIDER en false. Si utiliza NSX Advanced Load Balancer, AVI_CONTROL_PLANE_HA_PROVIDER: true, puede:
|
VSPHERE_CONTROL_PLANE_ENDPOINT_PORT |
✔ | ✔ | Opcional, se establece si se desea anular el puerto del servidor de la API de Kubernetes para las implementaciones en vSphere con NSX Advanced Load Balancer. El puerto predeterminado es 6443. Para anular el puerto del servidor de la API de Kubernetes para las implementaciones en vSphere sin NSX Advanced Load Balancer, establezca CLUSTER_API_SERVER_PORT. |
VSPHERE_CONTROL_PLANE_MEM_MIB |
✔ | ✔ | Opcional. La cantidad de memoria en megabytes para las máquinas virtuales del nodo de plano de control. Incluya las comillas (””). Por ejemplo, "2048". |
VSPHERE_CONTROL_PLANE_NUM_CPUS |
✔ | ✔ | Opcional. La cantidad de CPU para las máquinas virtuales del nodo de plano de control. Incluya las comillas (““). Deben ser al menos 2. Por ejemplo, "2". |
VSPHERE_DATACENTER |
✔ | ✔ | Obligatorio. El nombre del centro de datos en el que se implementará el clúster, tal como aparece en el inventario de vSphere. Por ejemplo, /MY-DATACENTER. |
VSPHERE_DATASTORE |
✔ | ✔ | Obligatorio. El nombre del almacén de datos vSphere que utilizará el clúster, como aparece en el inventario de vSphere. Por ejemplo, /MY-DATACENTER/datastore/MyDatastore. |
VSPHERE_FOLDER |
✔ | ✔ | Obligatorio. El nombre de una carpeta de máquina virtual existente en la que se colocan máquinas virtuales de Tanzu Kubernetes Grid, tal como aparece en el inventario de vSphere. Por ejemplo, si creó una carpeta denominada TKG, la ruta será /MY-DATACENTER/vm/TKG. |
VSPHERE_INSECURE |
✔ | ✔ | Opcional. Establezca true para omitir la verificación de la huella digital. Si es false, establezca VSPHERE_TLS_THUMBPRINT. |
VSPHERE_MTU |
✔ | ✔ | Opcional. Establezca el tamaño de la unidad de transmisión máxima (Maximum Transmission Unit, MTU) para los nodos del clúster de carga de trabajo y administración en un conmutador estándar de vSphere. El valor predeterminado es 1500 si no está establecido. El valor máximo es 9000. Consulte Configurar MTU de nodo de clúster. |
VSPHERE_NETWORK |
✔ | ✔ | Obligatorio. El nombre de una red de vSphere existente que se utilizará como red de servicio de Kubernetes, como aparece en el inventario de vSphere. Por ejemplo, VM Network. |
VSPHERE_PASSWORD |
✔ | ✔ | Obligatorio. La contraseña para la cuenta de usuario del administrador de vSphere. Este valor está codificado en base64 cuando se ejecuta tanzu cluster create. |
VSPHERE_REGION |
✖ | ✔ | Opcional. Etiqueta para la región en vCenter, que se utiliza para asignar almacenamiento CSI en un entorno con varios centros de datos o clústeres de hosts. Consulte Implementar un clúster con etiquetas de región y zona para CSI |
VSPHERE_RESOURCE_POOL |
✔ | ✔ | Obligatorio. El nombre de un grupo de recursos existente en el que se colocará esta instancia de Tanzu Kubernetes Grid, como aparece en el inventario de vSphere. Para utilizar el grupo de recursos raíz para un clúster, introduzca la ruta de acceso completa; por ejemplo, para un clúster denominado cluster0 en el centro de datos MY-DATACENTER, la ruta de acceso completa es /MY-DATACENTER/host/cluster0/Resources. |
VSPHERE_SERVER |
✔ | ✔ | Obligatorio. La dirección IP o el FQDN de la instancia de vCenter Server donde se desea implementar el clúster de carga de trabajo. |
VSPHERE_SSH_AUTHORIZED_KEY |
✔ | ✔ | Obligatorio. Pegue el contenido de la clave pública SSH que creó en Implementar un clúster de administración para vSphere. Por ejemplo, …"ssh-rsa NzaC1yc2EA [] hnng2OYYSl+8ZyNz3fmRGX8uPYqw== [email protected]". |
VSPHERE_STORAGE_POLICY_ID |
✔ | ✔ | Opcional. El nombre de una directiva de almacenamiento de máquina virtual para el clúster de administración, como aparece en Directivas y perfiles > Directivas de almacenamiento de máquinas virtuales. Si se establece VSPHERE_DATASTORE, la directiva de almacenamiento debe incluirla. De lo contrario, el proceso de creación del clúster elige un almacén de datos compatible con la directiva. |
VSPHERE_TEMPLATE |
✖ | ✔ | Opcional. Especifique la ruta de acceso a un archivo OVA si utiliza varias imágenes OVA personalizadas para la misma versión de Kubernetes, en el formato /MY-DC/vm/MY-FOLDER-PATH/MY-IMAGE. Para obtener más información, consulte Implementar un clúster con una imagen OVA personalizada. |
VSPHERE_TLS_THUMBPRINT |
✔ | ✔ | Obligatorio si VSPHERE_INSECURE es false. La huella digital del certificado de vCenter Server. Para obtener información sobre cómo obtener la huella digital del certificado de vCenter Server, consulte Obtener huellas digitales de certificado vSphere. Este valor se puede omitir si el usuario desea utilizar una conexión no segura estableciendo VSPHERE_INSECURE en true. |
VSPHERE_USERNAME |
✔ | ✔ | Obligatorio. Una cuenta de usuario vSphere, incluido el nombre de dominio, con los privilegios necesarios para la operación de Tanzu Kubernetes Grid. Por ejemplo, [email protected]. |
VSPHERE_WORKER_DISK_GIB |
✔ | ✔ | Opcional. El tamaño en gigabytes del disco para las máquinas virtuales del nodo de trabajo. Incluya las comillas (””). Por ejemplo, "50". |
VSPHERE_WORKER_MEM_MIB |
✔ | ✔ | Opcional. La cantidad de memoria en megabytes para las máquinas virtuales del nodo de trabajo. Incluya las comillas (““). Por ejemplo, "4096". |
VSPHERE_WORKER_NUM_CPUS |
✔ | ✔ | Opcional. Número de CPU para las máquinas virtuales del nodo de trabajo. Incluya las comillas (””). Deben ser al menos 2. Por ejemplo, "2". |
VSPHERE_ZONE |
✖ | ✔ | Opcional. Etiqueta para la zona en vCenter, que se utiliza para asignar almacenamiento CSI en un entorno con varios centros de datos o clústeres de hosts. Consulte Implementar un clúster con etiquetas de región y zona para CSI |
Equilibrador de carga kube-VIP (vista previa técnica)
Para obtener información sobre cómo configurar Kube-VIP como un servicio de equilibrador de carga de Capa 4, consulte Equilibrador de carga de Kube-VIP.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
KUBEVIP_LOADBALANCER_ENABLE |
✖ | ✔ | Opcional; el valor predeterminado es false. Establézcalo en true o false. Habilita Kube-VIP como equilibrador de carga para cargas de trabajo. Si está establecido en true, debe establecer una de las siguientes variables. |
KUBEVIP_LOADBALANCER_IP_RANGES |
✖ | ✔ | Una lista de rangos de IP que no se superponen para asignar a la IP de servicio tipoLoadBalancer. Por ejemplo: 10.0.0.1-10.0.0.23,10.0.2.1-10.0.2.24. |
KUBEVIP_LOADBALANCER_CIDRS |
✖ | ✔ | Una lista de CIDR que no se superponen para asignar a la IP de servicio tipo LoadBalancer IP. Por ejemplo: 10.0.0.0/24,10.0.2/24. Reemplaza el ajuste KUBEVIP_LOADBALANCER_IP_RANGES. |
NSX Advanced Load Balancer
Para obtener información sobre cómo implementar NSX Advanced Load Balancer, consulte Instalar NSX Advanced Load Balancer.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
AVI_ENABLE |
✔ | ✖ | Opcional; el valor predeterminado es false. Establézcalo en true o false. Habilita NSX Advanced Load Balancer como equilibrador de carga para cargas de trabajo. Si se establece true, debe establecer las variables requeridas que aparecen en NSX Advanced Load Balancer a continuación. |
AVI_ADMIN_CREDENTIAL_NAME |
✔ | ✖ | Opcional; el valor predeterminado es avi-controller-credentials. El nombre del secreto de Kubernetes que contiene el nombre de usuario y la contraseña del administrador del controlador de NSX Advanced Load Balancer. |
AVI_AKO_IMAGE_PULL_POLICY |
✔ | ✖ | Opcional; el valor predeterminado es IfNotPresent. |
AVI_CA_DATA_B64 |
✔ | ✖ | Obligatorio. El contenido de la entidad de certificación del controlador que se utiliza para firmar el certificado del controlador. Debe estar codificado en base64. Recupere el contenido del certificado personalizado sin codificar como se describe en Configuración del controlador Avi: Certificado personalizado. |
AVI_CA_NAME |
✔ | ✖ | Opcional; el valor predeterminado es avi-controller-ca. El nombre del secreto de Kubernetes que contiene la entidad de certificación del controlador de NSX Advanced Load Balancer. |
AVI_CLOUD_NAME |
✔ | ✖ | Obligatorio. La nube que creó en la implementación de NSX Advanced Load Balancer. Por ejemplo, Default-Cloud. |
AVI_CONTROLLER |
✔ | ✖ | Obligatorio. Dirección IP o nombre de host del controlador de NSX Advanced Load Balancer. |
AVI_CONTROL_PLANE_HA_PROVIDER |
✔ | ✔ | Obligatorio. Establézcalo en true para habilitar NSX Advanced Load Balancer como endpoint del servidor de API del plano de control, o false para usar Kube-Vip como endpoint del plano de control. |
AVI_CONTROL_PLANE_NETWORK |
✔ | ✖ | Opcional. Define la red VIP del plano de control del clúster de carga de trabajo. Utilícelo cuando desee configurar una red VIP independiente para los clústeres de carga de trabajo. Este campo es opcional y, si se deja en blanco, utilizará la misma red que AVI_DATA_NETWORK. |
AVI_CONTROL_PLANE_NETWORK_CIDR |
✔ | ✖ | Opcional; el valor predeterminado es la misma red que AVI_DATA_NETWORK_CIDR. El CIDR de la subred que se utilizará para el plano de control del clúster de carga de trabajo. Utilícelo cuando desee configurar una red VIP independiente para los clústeres de carga de trabajo. Puede ver el CIDR de subred de una red en particular en la vista Infraestructura - Redes de la interfaz de NSX Advanced Load Balancer. |
AVI_DATA_NETWORK |
✔ | ✖ | Obligatorio. El nombre de la red al que se asigna la subred de IP flotante o el grupo de IP a un equilibrador de carga para el tráfico a las aplicaciones alojadas en clústeres de carga de trabajo. Esta red debe estar presente en la misma instancia de vCenter Server que la red de Kubernetes que utiliza Tanzu Kubernetes Grid, que se especifica en la variable SERVICE_CIDR. Esto permite a NSX Advanced Load Balancer detectar la red de Kubernetes en vCenter Server, así como implementar y configurar motores de servicio. |
AVI_DATA_NETWORK_CIDR |
✔ | ✖ | Obligatorio. El CIDR de la subred que se utilizará para la VIP del equilibrador de carga. Esto proviene de una de las subredes configuradas de la red VIP. Puede ver el CIDR de subred de una red en particular en la vista Infraestructura - Redes de la interfaz de NSX Advanced Load Balancer. |
AVI_DISABLE_INGRESS_CLASS |
✔ | ✖ | Opcional; el valor predeterminado es false. Desactive la clase de entrada. |
AVI_DISABLE_STATIC_ROUTE_SYNC |
✔ | ✖ | Opcional; el valor predeterminado es false. Establezca el valor en true si se puede acceder a las redes del pod desde el motor de servicio NSX ALB. |
AVI_INGRESS_DEFAULT_INGRESS_CONTROLLER |
✔ | ✖ | Opcional; el valor predeterminado es false. Utilice AKO como controlador de entrada predeterminado.Nota: Esta variable no funciona en TKG v2.3. Para obtener una solución alternativa, consulte el problema conocido Algunas variables de configuración de NSX ALB no funcionan en las notas de la versión. |
AVI_INGRESS_NODE_NETWORK_LIST |
✔ | ✖ | Especifica el nombre de la red del grupo de puertos (PG) de la que forman parte los nodos y el CIDR asociado que la CNI asigna a cada nodo para que ese nodo asigne a sus pods. Es mejor actualizarlo en el archivo AKODeploymentConfig, consulte Entrada L7 Ingress en el modo ClusterIP, pero si usa el archivo de configuración del clúster, el formato es similar a: ‘[{“networkName”: “vsphere-portgroup”,“cidrs”: [“100.64.42.0/24”]}]’ |
AVI_INGRESS_SERVICE_TYPE |
✔ | ✖ | Opcional. Especifica si la AKO funciona en el modo ClusterIP, NodePort o NodePortLocal. El valor predeterminado es NodePort. |
AVI_INGRESS_SHARD_VS_SIZE |
✔ | ✖ | Opcional. AKO utiliza una lógica de particionamiento para los objetos de entrada de Capa 7. Un VS particionado implica alojar varias entradas no seguras o seguras alojadas por una IP o VIP virtual. Establézcalo en LARGE, MEDIUM o SMALL. Valor predeterminado SMALL. Utilice esta opción para controlar los números de VS de Capa 7. Esto se aplica a los dos VS seguros o no seguros, pero no se aplica al acceso directo. |
AVI_LABELS |
✔ | ✔ | Opcional. Cuando se establece, NSX Advanced Load Balancer solo se habilita en los clústeres de carga de trabajo que tengan esta etiqueta. Incluya las comillas (""). Por ejemplo, AVI_LABELS: “{foo: ‘bar’}”. |
AVI_MANAGEMENT_CLUSTER_CONTROL_PLANE_VIP_NETWORK_CIDR |
✔ | ✖ | Opcional. El CIDR de la subred que se utilizará para el plano de control del clúster de administración. Se utiliza cuando se desea configurar una red VIP independiente para el plano de control del clúster de administración. Puede ver el CIDR de subred de una red en particular en la vista Infraestructura - Redes de la interfaz de NSX Advanced Load Balancer. Este campo es opcional y, si se deja en blanco, utilizará la misma red que AVI_DATA_NETWORK_CIDR. |
AVI_MANAGEMENT_CLUSTER_CONTROL_PLANE_VIP_NETWORK_NAME |
✔ | ✖ | Opcional. Define la red VIP del plano de control del clúster de administración. Se utiliza cuando se desea configurar una red VIP independiente para el plano de control del clúster de administración. Este campo es opcional y, si se deja en blanco, utilizará la misma red que AVI_DATA_NETWORK. |
AVI_MANAGEMENT_CLUSTER_SERVICE_ENGINE_GROUP |
✔ | ✖ | Opcional. Especifica el nombre del grupo de motores de servicio que utilizará AKO en el clúster de administración. Este campo es opcional y, si se deja en blanco, utilizará la misma red que AVI_SERVICE_ENGINE_GROUP. |
AVI_MANAGEMENT_CLUSTER_VIP_NETWORK_NAME |
✔ | ✖ | Opcional; el valor predeterminado es la misma red que AVI_DATA_NETWORK. El nombre de la red en el que se asigna una la subred de IP flotante o un grupo de IP a un equilibrador de carga de trabajo para el clúster de administración y el plano de control del clúster de carga de trabajo (si se utiliza NSX ALB para proporcionar HA del plano de control). Esta red debe estar presente en la misma instancia de vCenter Server que la red de Kubernetes que utiliza Tanzu Kubernetes Grid, que se especifica en la variable SERVICE_CIDR para el clúster de administración. Esto permite a NSX Advanced Load Balancer detectar la red de Kubernetes en vCenter Server, así como implementar y configurar motores de servicio. |
AVI_MANAGEMENT_CLUSTER_VIP_NETWORK_CIDR |
✔ | ✖ | Opcional; el valor predeterminado es la misma red que AVI_DATA_NETWORK_CIDR. El CIDR de la subred que se utilizará para el clúster de administración y el plano de control del clúster de carga de trabajo (si se utiliza NSX ALB para proporcionar HA del plano de control). Esto proviene de una de las subredes configuradas de la red VIP. Puede ver el CIDR de subred de una red en particular en la vista Infraestructura - Redes de la interfaz de NSX Advanced Load Balancer. |
AVI_NAMESPACE |
✔ | ✖ | Opcional; el valor predeterminado es “tkg-system-networking”. El espacio de nombres del operador de AKO. |
AVI_NSXT_T1LR |
✔ | ✖ | Opcional. La ruta del enrutador NSX T1 que configuró para el clúster de administración en la interfaz de usuario del controlador AVI, en NSX Cloud. Esto es necesario cuando se utiliza NSX Cloud en el controlador de ALB de NSX.Para utilizar un T1 diferente para los clústeres de carga de trabajo, modifique el objeto AKODeploymentConfig install-ako-for-all después de crear el clúster de administración. |
AVI_PASSWORD |
✔ | ✖ | Obligatorio. La contraseña que estableció para el administrador del controlador cuando lo implementó. |
AVI_SERVICE_ENGINE_GROUP |
✔ | ✖ | Obligatorio. Nombre del grupo de motores de servicio. Por ejemplo, Default-Group. |
AVI_USERNAME |
✔ | ✖ | Obligatorio. El nombre de usuario admin que estableció para el host del controlador cuando lo implementó. |
Enrutamiento de pods de NSX
Estas variables configuran pods de carga de trabajo de dirección IP enrutables, como se describe en Implementar un clúster con pods de IP enrutables. Todos los ajustes de tipo de cadena deben estar entre comillas, por ejemplo, "true".
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
NSXT_POD_ROUTING_ENABLED |
✖ | ✔ | Opcional; el valor predeterminado es “false”. Establézcalo en “true” para habilitar los pods enrutables de NSX con las siguientes variables. Consulte Implementar un clúster con pods de IP enrutables. |
NSXT_MANAGER_HOST |
✖ | ✔ | Obligatorio si NSXT_POD_ROUTING_ENABLED= “true”.Dirección IP de NSX Manager. |
NSXT_ROUTER_PATH |
✖ | ✔ | Obligatorio si NSXT_POD_ROUTING_ENABLED= “true”. La ruta del enrutador T1 se muestra en NSX Manager. |
| Para la autenticación de nombre de usuario/contraseña en NSX: | |||
NSXT_USERNAME |
✖ | ✔ | Nombre de usuario para iniciar sesión en NSX Manager. |
NSXT_PASSWORD |
✖ | ✔ | Contraseña para iniciar sesión en NSX Manager. |
Para autenticarse en NSX con credenciales y almacenarlas en un secreto de Kubernetes (también establecer NSXT_USERNAME y NSXT_PASSWORD anteriores): |
|||
NSXT_SECRET_NAMESPACE |
✖ | ✔ | Opcional; el valor predeterminado es “kube-system”. El espacio de nombres con el secreto que contiene el nombre de usuario y contraseña de NSX. |
NSXT_SECRET_NAME |
✖ | ✔ | Opcional; el valor predeterminado es “cloud-provider-vsphere-nsxt-credentials”. El nombre del secreto que contiene el nombre de usuario y contraseña de NSX. |
| Para la autenticación de certificados en NSX: | |||
NSXT_ALLOW_UNVERIFIED_SSL |
✖ | ✔ | Opcional; el valor predeterminado es false. Establezca esta opción en “true” si NSX utiliza un certificado autofirmado. |
NSXT_ROOT_CA_DATA_B64 |
✖ | ✔ | Obligatorio si NSXT_ALLOW_UNVERIFIED_SSL= “false”.Cadena de certificado raíz de la entidad de certificación con codificación Base64 que NSX usa para la autenticación LDAP. |
NSXT_CLIENT_CERT_KEY_DATA |
✖ | ✔ | Cadena de archivo de clave de certificado con codificación en base64 para el certificado de cliente local. |
NSXT_CLIENT_CERT_DATA |
✖ | ✔ | Cadena de archivo de certificado con codificación Base64 para el certificado de cliente local. |
| Para la autenticación remota en NSX con VMware Identity Manager, en VMware Cloud (VMC): | |||
NSXT_REMOTE_AUTH |
✖ | ✔ | Opcional; el valor predeterminado es false. Establezca esta opción en “true” de autenticación remota para NSX con VMware Identity Manager, en VMware Cloud (VMC). |
NSXT_VMC_AUTH_HOST |
✖ | ✔ | Opcional; el valor predeterminado está vacío. Host de autenticación de VMC. |
NSXT_VMC_ACCESS_TOKEN |
✖ | ✔ | Opcional; el valor predeterminado está vacío. Token de acceso de autenticación de VMC. |
Node IPAM
Estas variables configuran la administración de direcciones IP (IP Address Management, IPAM) en el clúster como se describe en Node IPAM. Todos los ajustes de tipo de cadena deben estar entre comillas, por ejemplo, "true".
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
CONTROL_PLANE_NODE_NAMESERVERS |
✔ | ✔ | Lista delimitada por comas de servidores de nombres, por ejemplo, “10.10.10.10”, para las direcciones de nodo de plano de control administradas por Node IPAM. Compatible con Ubuntu y Photon; no se admite en Windows. |
NODE_IPAM_IP_POOL_APIVERSION |
✖ | ✔ | Versión de API para el objeto InClusterIPPool utilizado por el clúster de carga de trabajo. El valor predeterminado es “ipam.cluster.x-k8s.io/v1alpha2”; versiones anteriores de TKG que utilizaban v1alpha1. |
NODE_IPAM_IP_POOL_KIND |
✖ | ✔ | Tipo de objeto de grupo de direcciones IP utilizado por el clúster de carga de trabajo. El valor predeterminado es “InClusterIPPool” o puede ser “GlobalInClusterIPPool” para compartir el mismo grupo con otros clústeres. |
NODE_IPAM_IP_POOL_NAME |
✖ | ✔ | Nombre del objeto de grupo de direcciones IP que configura el grupo de direcciones IP utilizado por un clúster de carga de trabajo. |
WORKER_NODE_NAMESERVERS |
✔ | ✔ | Lista delimitada por comas de servidores de nombres, por ejemplo, “10.10.10.10”, para las direcciones de nodo de trabajo administradas por Node IPAM. Compatible con Ubuntu y Photon; no se admite en Windows. |
MANAGEMENT_NODE_IPAM_IP_POOL_GATEWAY |
✔ | ✖ | La puerta de enlace predeterminada para las direcciones del grupo de IPAM en un clúster de administración, por ejemplo, "10.10.10.1". |
MANAGEMENT_NODE_IPAM_IP_POOL_ADDRESSES |
✔ | ✖ | Las direcciones disponibles para que IPAM asigne en un clúster de administración, en una lista delimitada por comas que puede incluir direcciones IP únicas, rangos (por ejemplo, 10.0.0.2-10.0.0.100) o CIDR (por ejemplo, 10.0.0.32/27).Incluya direcciones adicionales para que permanezcan sin utilizar, según sea necesario para las actualizaciones del clúster. El valor predeterminado del número de direcciones adicionales requerido es uno y se establece mediante el topology.cluster.x-k8s.io/upgrade-concurrency de anotación en las definiciones topology.controlPlane y topology.workers de la especificación del objeto de clúster. |
MANAGEMENT_NODE_IPAM_IP_POOL_SUBNET_PREFIX |
✔ | ✖ | El prefijo de red de la subred para las direcciones del grupo de IPAM en un clúster de administración independiente, por ejemplo, “24” |
Clústeres habilitados para GPU
Estas variables configuran clústeres de carga de trabajo habilitados para GPU en modo de acceso directo PCI, como se describe en Implementar un clúster de carga de trabajo habilitado para GPU. Todos los ajustes de tipo de cadena deben estar entre comillas, por ejemplo, "true".
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
VSPHERE_CONTROL_PLANE_CUSTOM_VMX_KEYS |
✔ | ✔ | Establece claves VMX personalizadas en todas las máquinas del plano de control. Use el formato Key1=Value1,Key2=Value2. Consulte Implementar un clúster de carga de trabajo habilitado para GPU. |
VSPHERE_CONTROL_PLANE_HARDWARE_VERSION |
✔ | ✔ | La versión de hardware de la máquina virtual del plano de control con el dispositivo GPU en modo de acceso directo PCI. La versión mínima requerida es 17. El formato del valor es vmx-17, donde los dígitos finales son la versión de hardware de la máquina virtual. Para obtener compatibilidad con funciones en diferentes versiones de hardware, consulte Funciones de hardware disponibles con el ajuste de compatibilidad de máquina virtual en la documentación de vSphere. |
VSPHERE_CONTROL_PLANE_PCI_DEVICES |
✔ | ✔ | Configura el acceso directo PCI en todas las máquinas del plano de control. Utilice el formato <vendor_id>:<device_id>. Por ejemplo, VSPHERE_WORKER_PCI_DEVICES: “0x10DE:0x1EB8”. Para encontrar los identificadores de proveedor y dispositivo, consulte Implementar un clúster de carga de trabajo habilitado para GPU. |
VSPHERE_IGNORE_PCI_DEVICES_ALLOW_LIST |
✔ | ✔ | Establécelo en false si utiliza la GPU NVIDIA Tesla T4 y true si utiliza la GPU NVIDIA V100. |
VSPHERE_WORKER_CUSTOM_VMX_KEYS |
✔ | ✔ | Establece claves VMX personalizadas en todas las máquinas de trabajo. Use el formato Key1=Value1,Key2=Value2. Para obtener un ejemplo, consulte Implementar un clúster de carga de trabajo habilitado para GPU. |
VSPHERE_WORKER_HARDWARE_VERSION |
✔ | ✔ | La versión de hardware de la máquina virtual de trabajo con el dispositivo GPU en modo de acceso directo PCI. La versión mínima requerida es 17. El formato del valor es vmx-17, donde los dígitos finales son la versión de hardware de la máquina virtual. Para obtener compatibilidad con funciones en diferentes versiones de hardware, consulte Funciones de hardware disponibles con el ajuste de compatibilidad de máquina virtual en la documentación de vSphere. |
VSPHERE_WORKER_PCI_DEVICES |
✔ | ✔ | Configura el acceso directo PCI en todas las máquinas de trabajo. Utilice el formato <vendor_id>:<device_id>. Por ejemplo, VSPHERE_WORKER_PCI_DEVICES: “0x10DE:0x1EB8”. Para encontrar los identificadores de proveedor y dispositivo, consulte Implementar un clúster de carga de trabajo habilitado para GPU. |
WORKER_ROLLOUT_STRATEGY |
✔ | ✔ | Opcional. Configura la estrategia de lanzamiento MachineDeployment. El valor predeterminado es RollingUpdate. Si está establecido en OnDelete, en las actualizaciones, las máquinas de trabajo existentes se eliminarán primero antes de crear las máquinas de trabajo de reemplazo. Es imprescindible establecer esta opción en OnDelete si los nodos de trabajo están utilizando todos los dispositivos PCI disponibles. |
AWS
Las variables de la siguiente tabla son las opciones que se especifican en el archivo de configuración del clúster al implementar clústeres de carga de trabajo en AWS. Muchas de estas opciones son las mismas para el clúster de carga de trabajo y el clúster de administración que se utiliza para implementarlo.
Para obtener más información sobre los archivos de configuración de AWS, consulte Configuración del clúster de administración para AWS y Archivos de configuración del clúster de AWS.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
AWS_ACCESS_KEY_ID |
✔ | ✔ | Opcional. El identificador de clave de acceso de la cuenta de AWS. Esta es una opción para autenticarse en AWS. Consulte Configurar credenciales de cuenta de AWS. Utilice solo AWS_PROFILE o una combinación de AWS_ACCESS_KEY_ID y AWS_SECRET_ACCESS_KEY, pero no ambas. |
AWS_CONTROL_PLANE_OS_DISK_SIZE_GIB |
✔ | ✔ | Opcional. Tamaño de disco para los nodos del plano de control. Reemplaza el tamaño de disco predeterminado para el tipo de máquina virtual establecido por CONTROL_PLANE_MACHINE_TYPE, SIZE o CONTROLPLANE_SIZE. |
AWS_LOAD_BALANCER_SCHEME_INTERNAL |
✔ | ✔ | Opcional. Para los clústeres de administración, establece el esquema del equilibrador de carga para que sea interno, lo que impide el acceso a través de Internet. Para los clústeres de carga de trabajo, garantiza que el clúster de administración acceda al equilibrador de carga del clúster de carga de trabajo de forma interna cuando compartan una VPC o estén emparejados. Consulte Usar equilibrador de carga interno para el servidor de API de Kubernetes. |
AWS_NODE_AZ |
✔ | ✔ | Obligatorio. El nombre de la zona de disponibilidad de AWS en la región elegida que desea utilizar como zona de disponibilidad para este clúster de administración. Los nombres de las zonas de disponibilidad son iguales que el nombre de la región de AWS, con un solo sufijo de letra en minúscula, como a, b, c. Por ejemplo, us-west-2a. Para implementar un clúster de administración prod con tres nodos de plano de control, también debe establecer AWS_NODE_AZ_1 y AWS_NODE_AZ_2. El sufijo de letra en cada una de estas zonas de disponibilidad debe ser único. Por ejemplo, us-west-2a, us-west-2b y us-west-2c. |
AWS_NODE_OS_DISK_SIZE_GIB |
✔ | ✔ | Opcional. Tamaño de disco para los nodos de trabajo. Reemplaza el tamaño de disco predeterminado para el tipo de máquina virtual establecido por NODE_MACHINE_TYPE, SIZE o WORKER_SIZE. |
AWS_NODE_AZ_1 y AWS_NODE_AZ_2 |
✔ | ✔ | Opcional. Establezca estas variables si desea implementar un clúster de administración prod con tres nodos de plano de control. Ambas zonas de disponibilidad deben estar en la misma región que AWS_NODE_AZ. Consulte AWS_NODE_AZ para obtener más información. Por ejemplo, us-west-2a, ap-northeast-2b, etc. |
AWS_PRIVATE_NODE_CIDR_1 |
✔ | ✔ | Opcional. Si el rango recomendado de 10.0.2.0/24 no está disponible, introduzca un rango de IP diferente en formato CIDR. Cuando Tanzu Kubernetes Grid implementa el clúster de administración, crea esta subred en AWS_NODE_AZ_1. Consulte AWS_PRIVATE_NODE_CIDR para obtener más información. |
AWS_PRIVATE_NODE_CIDR_2 |
✔ | ✔ | Opcional. Si el rango recomendado de 10.0.4.0/24 no está disponible, introduzca un rango de IP diferente en formato CIDR. Cuando Tanzu Kubernetes Grid implementa el clúster de administración, crea esta subred en AWS_NODE_AZ_2. Consulte AWS_PRIVATE_NODE_CIDR para obtener más información. |
AWS_PROFILE |
✔ | ✔ | Opcional. El perfil de credenciales de AWS, administrado por aws configure, que Tanzu Kubernetes Grid utiliza para acceder a su cuenta de AWS. Esta es la opción preferida para autenticarse en AWS. Consulte Configurar credenciales de cuenta de AWS.Utilice solo AWS_PROFILE o una combinación de AWS_ACCESS_KEY_ID y AWS_SECRET_ACCESS_KEY, pero no ambas. |
AWS_PUBLIC_NODE_CIDR_1 |
✔ | ✔ | Opcional. Si el rango recomendado de 10.0.3.0/24 no está disponible, introduzca un rango de IP diferente en formato CIDR. Cuando Tanzu Kubernetes Grid implementa el clúster de administración, crea esta subred en AWS_NODE_AZ_1. Consulte AWS_PUBLIC_NODE_CIDR para obtener más información. |
AWS_PUBLIC_NODE_CIDR_2 |
✔ | ✔ | Opcional. Si el rango recomendado de 10.0.5.0/24 no está disponible, introduzca un rango de IP diferente en formato CIDR. Cuando Tanzu Kubernetes Grid implementa el clúster de administración, crea esta subred en AWS_NODE_AZ_2. Consulte AWS_PUBLIC_NODE_CIDR para obtener más información. |
AWS_PRIVATE_SUBNET_ID |
✔ | ✔ | Opcional. Si configura AWS_VPC_ID para utilizar una VPC existente, introduzca el identificador de una subred privada que ya exista en AWS_NODE_AZ. Este ajuste es opcional. Si no lo establece, tanzu management-cluster create identifica automáticamente la subred privada. Para implementar un clúster de administración prod con tres nodos de plano de control, también debe establecer AWS_PRIVATE_SUBNET_ID_1 y AWS_PRIVATE_SUBNET_ID_2. |
AWS_PRIVATE_SUBNET_ID_1 |
✔ | ✔ | Opcional. El identificador de una subred privada que existe en AWS_NODE_AZ_1. Si no establece esta variable, tanzu management-cluster create identifica automáticamente la subred privada. Consulte AWS_PRIVATE_SUBNET_ID para obtener más información. |
AWS_PRIVATE_SUBNET_ID_2 |
✔ | ✔ | Opcional. El identificador de una subred privada que existe en AWS_NODE_AZ_2. Si no establece esta variable, tanzu management-cluster create identifica automáticamente la subred privada. Consulte AWS_PRIVATE_SUBNET_ID para obtener más información. |
AWS_PUBLIC_SUBNET_ID |
✔ | ✔ | Opcional. Si configura AWS_VPC_ID para utilizar una VPC existente, introduzca el identificador de una subred pública que ya exista en AWS_NODE_AZ. Este ajuste es opcional. Si no lo establece, tanzu management-cluster create identifica automáticamente la subred pública. Para implementar un clúster de administración prod con tres nodos de plano de control, también debe establecer AWS_PUBLIC_SUBNET_ID_1 y AWS_PUBLIC_SUBNET_ID_2. |
AWS_PUBLIC_SUBNET_ID_1 |
✔ | ✔ | Opcional. El identificador de una subred pública que existe en AWS_NODE_AZ_1. Si no establece esta variable, tanzu management-cluster create identifica la subred pública automáticamente. Consulte AWS_PUBLIC_SUBNET_ID para obtener más información. |
AWS_PUBLIC_SUBNET_ID_2 |
✔ | ✔ | Opcional. El identificador de una subred pública que existe en AWS_NODE_AZ_2. Si no establece esta variable, tanzu management-cluster create identifica la subred pública automáticamente. Consulte AWS_PUBLIC_SUBNET_ID para obtener más información. |
AWS_REGION |
✔ | ✔ | Obligatorio. El nombre de la región de AWS en la que se implementará el clúster. Por ejemplo, us-west-2. También puede especificar las regiones us-gov-east y us-gov-west en AWS GovCloud. Si ya estableció una región diferente como variable de entorno, por ejemplo, en Implementar clústeres de administración en AWS, debe desactivar esa variable de entorno. Por ejemplo, us-west-2, ap-northeast-2, etc. |
AWS_SECRET_ACCESS_KEY |
✔ | ✔ | Opcional. La clave de acceso secreta de la cuenta de AWS. Esta es una opción para autenticarse en AWS. Consulte Configurar credenciales de cuenta de AWS. Utilice solo AWS_PROFILE o una combinación de AWS_ACCESS_KEY_ID y AWS_SECRET_ACCESS_KEY, pero no ambas. |
AWS_SECURITY_GROUP_APISERVER_LB |
✔ | ✔ | Opcional. Grupos de seguridad personalizados con reglas personalizadas que se aplicarán al clúster. Consulte Configurar grupos de seguridad personalizados. |
AWS_SECURITY_GROUP_BASTION |
|||
AWS_SECURITY_GROUP_CONTROLPLANE |
|||
AWS_SECURITY_GROUP_APISERVER_LB |
|||
AWS_SECURITY_GROUP_NODE |
|||
AWS_SESSION_TOKEN |
✔ | ✔ | Opcional. Proporcione el token de sesión de AWS concedido a su cuenta si se le solicita que utilice una clave de acceso temporal. Para obtener más información sobre el uso de claves de acceso temporales, consulte Comprender y obtener las credenciales de AWS. proporcione el token de sesión para su cuenta de AWS. Si lo prefiere, puede especificar las credenciales de la cuenta como variables de entorno local o en la cadena de proveedores de credenciales predeterminadas de AWS. |
AWS_SSH_KEY_NAME |
✔ | ✔ | Obligatorio. El nombre de la clave privada SSH que registró con su cuenta de AWS. |
AWS_VPC_ID |
✔ | ✔ | Opcional. Para utilizar una VPC que ya exista en la región de AWS seleccionada, introduzca el identificador de la VPC y, a continuación, establezca AWS_PUBLIC_SUBNET_ID y AWS_PRIVATE_SUBNET_ID. |
BASTION_HOST_ENABLED |
✔ | ✔ | Opcional. De forma predeterminada, esta opción está establecida en "true" en la configuración de Tanzu Kubernetes Grid global. Especifique "true" para implementar un host bastión de AWS o "false" para reutilizar un host bastión existente. Si no existe ningún host bastión en las zonas de disponibilidad y configura AWS_VPC_ID para que use una VPC existente, establezca BASTION_HOST_ENABLED en "true". |
CONTROL_PLANE_MACHINE_TYPE |
✔ | ✔ | Obligatorio si no se establecen SIZE o CONTROLPLANE_SIZE independientes de la nube. El tipo de instancia de Amazon EC2 que se utilizará para los nodos del plano de control del clúster, por ejemplo, t3.small o m5.large. |
NODE_MACHINE_TYPE |
✔ | ✔ | Obligatorio si no se establecen SIZE o WORKER_SIZE independientes de la nube. El tipo de instancia de Amazon EC2 que se utilizará para los nodos de trabajo del clúster, por ejemplo, t3.small o m5.large. |
Microsoft Azure
Las variables de la siguiente tabla son las opciones que se especifican en el archivo de configuración del clúster al implementar clústeres de carga de trabajo en Azure. Muchas de estas opciones son las mismas para el clúster de carga de trabajo y el clúster de administración que se utiliza para implementarlo.
Para obtener más información sobre los archivos de configuración de Azure, consulte Configuración del clúster de administración para Azure y Archivos de configuración del clúster de Azure.
| Variable | Se puede establecer en … | Descripción | |
|---|---|---|---|
| YAML del clúster de administración | YAML del clúster de carga de trabajo | ||
AZURE_CLIENT_ID |
✔ | ✔ | Obligatorio. El identificador de cliente de la aplicación para Tanzu Kubernetes Grid que registró con Azure. |
AZURE_CLIENT_SECRET |
✔ | ✔ | Obligatorio. El secreto de cliente de Azure de Registrar una aplicación Tanzu Kubernetes Grid en Azure. |
AZURE_CUSTOM_TAGS |
✔ | ✔ | Opcional. Lista separada por comas de etiquetas que se aplicarán a los recursos de Azure creados para el clúster. Una etiqueta es un par clave-valor, por ejemplo, “foo=bar, plan=prod”. Para obtener más información sobre el etiquetado de recursos de Azure, consulte Usar etiquetas para organizar la jerarquía de recursos y administración de Azure y La compatibilidad de etiquetas para los recursos de Azure en la documentación de Microsoft Azure. |
AZURE_ENVIRONMENT |
✔ | ✔ | Opcional; el valor predeterminado es AzurePublicCloud. Las nubes compatibles son AzurePublicCloud, AzureChinaCloud, AzureGermanCloud y AzureUSGovernmentCloud. |
AZURE_IDENTITY_NAME |
✔ | ✔ | Opcional, establezca si desea utilizar clústeres en diferentes cuentas de Azure. El nombre que se utilizará para la instancia de AzureClusterIdentity que se crea para utilizar clústeres en diferentes cuentas de Azure. Para obtener más información, consulte Clústeres en diferentes cuentas de Azure en Implementar clústeres de carga de trabajo en Azure. |
AZURE_IDENTITY_NAMESPACE |
✔ | ✔ | Opcional, establezca si desea utilizar clústeres en diferentes cuentas de Azure. El espacio de nombres de AzureClusterIdentity que crea para utilizar clústeres en diferentes cuentas de Azure. Para obtener más información, consulte Clústeres en diferentes cuentas de Azure en Implementar clústeres de carga de trabajo en Azure. |
AZURE_LOCATION |
✔ | ✔ | Obligatorio. El nombre de la región de Azure en la que se implementará el clúster. Por ejemplo, eastus. |
AZURE_RESOURCE_GROUP |
✔ | ✔ | Opcional; el valor predeterminado es CLUSTER_NAME. El nombre del grupo de recursos de Azure que desea usar para el clúster. Debe ser único para cada clúster. AZURE_RESOURCE_GROUP y AZURE_VNET_RESOURCE_GROUP son iguales de forma predeterminada. |
AZURE_SSH_PUBLIC_KEY_B64 |
✔ | ✔ | Obligatorio. Su clave pública SSH, creada en Implementar un clúster de administración en Microsoft Azure, convertida a base64 con las nuevas líneas eliminadas. Por ejemplo, …c3NoLXJzYSBB [] vdGFsLmlv. |
AZURE_SUBSCRIPTION_ID |
✔ | ✔ | Obligatorio. El identificador de suscripción de su suscripción de Azure. |
AZURE_TENANT_ID |
✔ | ✔ | Obligatorio. El identificador de tenant de su cuenta de Azure. |
| Redes | |||
AZURE_CONTROL_PLANE_OUTBOUND_LB_FRONTEND_IP_COUNT |
✔ | ✔ | Opcional; el valor predeterminado es 1. Establezca esta opción para agregar varias direcciones IP de front-end al equilibrador de carga del plano de control en entornos con un alto número de conexiones salientes esperadas. |
AZURE_ENABLE_ACCELERATED_NETWORKING |
✔ | ✔ | Opcional; el valor predeterminado es true. Establézcalo en false para desactivar las redes aceleradas de Azure en máquinas virtuales con más de 4 CPU. |
AZURE_ENABLE_CONTROL_PLANE_OUTBOUND_LB |
✔ | ✔ | Opcional. Establezca esta opción en true si AZURE_ENABLE_PRIVATE_CLUSTER está establecido en true y desea habilitar una dirección IP pública en el equilibrador de carga saliente para el plano de control. |
AZURE_ENABLE_NODE_OUTBOUND_LB |
✔ | ✔ | Opcional. Establezca esta opción en true si AZURE_ENABLE_PRIVATE_CLUSTER está en true y desea habilitar una dirección IP pública en el equilibrador de carga saliente para los nodos de trabajo. |
AZURE_ENABLE_PRIVATE_CLUSTER |
✔ | ✔ | Opcional. Establézcalo en true para configurar el clúster como privado y utilizar un equilibrador de carga interno de Azure (ILB) para su tráfico entrante. Para obtener más información, consulte Clústeres privados de Azure. |
AZURE_FRONTEND_PRIVATE_IP |
✔ | ✔ | Opcional. Establezca esta opción si AZURE_ENABLE_PRIVATE_CLUSTER está establecido en true y desea anular la dirección predeterminada del equilibrador de carga interno de 10.0.0.100. |
AZURE_NODE_OUTBOUND_LB_FRONTEND_IP_COUNT |
✔ | ✔ | Opcional; el valor predeterminado es 1. Establezca esta opción para agregar varias direcciones IP de front-end al equilibrador de carga del nodo de trabajo en entornos con un alto número de conexiones salientes esperadas. |
AZURE_NODE_OUTBOUND_LB_IDLE_TIMEOUT_IN_MINUTES |
✔ | ✔ | Opcional; el valor predeterminado es 4. Establezca esta opción para especificar el número de minutos que las conexiones TCP salientes se mantienen abiertas a través del equilibrador de carga saliente del nodo de trabajo. |
AZURE_VNET_CIDR |
✔ | ✔ | Opcional, establézcalo si desea implementar el clúster en una nueva VNet y subredes, y reemplazar los valores predeterminados. De forma predeterminada, AZURE_VNET_CIDR se establece en 10.0.0.0/16, en AZURE_CONTROL_PLANE_SUBNET_CIDR en 10.0.0.0/24 y en AZURE_NODE_SUBNET_CIDR en 10.0.1.0/24. |
AZURE_CONTROL_PLANE_SUBNET_CIDR |
|||
AZURE_NODE_SUBNET_CIDR |
|||
AZURE_VNET_NAME |
✔ | ✔ | Opcional, establézcalo si desea implementar el clúster en una VNet y subredes existentes, o asignar nombres a una nueva VNet y subredes. |
AZURE_CONTROL_PLANE_SUBNET_NAME |
|||
AZURE_NODE_SUBNET_NAME |
|||
AZURE_VNET_RESOURCE_GROUP |
✔ | ✔ | Opcional; el valor predeterminado es AZURE_RESOURCE_GROUP. |
| Máquinas virtuales del plano de control | |||
AZURE_CONTROL_PLANE_DATA_DISK_SIZE_GIB |
✔ | ✔ | Opcional. Tamaño del disco de datos y del disco del sistema operativo, tal como se describe en la documentación de Azure Funciones de disco, para máquinas virtuales del plano de control, en GB. Ejemplos: 128, 256. Los nodos del plano de control siempre se aprovisionan con un disco de datos. |
AZURE_CONTROL_PLANE_OS_DISK_SIZE_GIB |
|||
AZURE_CONTROL_PLANE_MACHINE_TYPE |
✔ | ✔ | Opcional; el valor predeterminado es Standard_D2s_v3. Tamaño de máquina virtual de Azure para las máquinas virtuales del nodo de plano de control, elegido para ajustarse a las cargas de trabajo esperadas. El requisito mínimo para los tipos de instancia de Azure es 2 CPU y 8 GB de memoria. Para ver los valores posibles, consulte la interfaz del instalador de Tanzu Kubernetes Grid. |
AZURE_CONTROL_PLANE_OS_DISK_STORAGE_ACCOUNT_TYPE |
✔ | ✔ | Opcional. Tipo de cuenta de almacenamiento de Azure para los discos de máquina virtual del plano de control. Ejemplo: Premium_LRS. |
| Máquinas virtuales del nodo de trabajo | |||
AZURE_ENABLE_NODE_DATA_DISK |
✔ | ✔ | Opcional; el valor predeterminado es false. Establézcalo en true para aprovisionar un disco de datos para cada máquina virtual del nodo de trabajo, como se describe en la documentación de Azure Funciones de disco. |
AZURE_NODE_DATA_DISK_SIZE_GIB |
✔ | ✔ | Opcional. Establezca esta variable si AZURE_ENABLE_NODE_DATA_DISK está establecida en true. Tamaño del disco de datos, tal como se describe en la documentación de Azure Funciones de disco, para máquinas virtuales del trabajo, en GB. Ejemplos: 128, 256. |
AZURE_NODE_OS_DISK_SIZE_GIB |
✔ | ✔ | Opcional. Tamaño del disco del sistema operativo, como se describe en la documentación de Azure Funciones de disco, para máquinas virtuales de trabajo, en GB. Ejemplos: 128, 256. |
AZURE_NODE_MACHINE_TYPE |
✔ | ✔ | Opcional. Tamaño de máquina virtual de Azure para las máquinas virtuales del nodo de trabajo, elegido para ajustarse a las cargas de trabajo esperadas. El valor predeterminado es Standard_D2s_v3. Para ver los valores posibles, consulte la interfaz del instalador de Tanzu Kubernetes Grid. |
AZURE_NODE_OS_DISK_STORAGE_ACCOUNT_TYPE |
✔ | ✔ | Opcional. Establezca esta variable si AZURE_ENABLE_NODE_DATA_DISK está establecida en true. Tipo de cuenta de almacenamiento de Azure para los discos de la máquina virtual de trabajo. Ejemplo: Premium_LRS. |
Prioridad del valor de configuración
Cuando la CLI de Tanzu crea un clúster, lee los valores de las variables enumeradas en este tema de varios orígenes. Si dichos orígenes entran en conflicto, se resuelven los conflictos en el siguiente orden de prioridad descendente:
| Procesando capas, ordenadas por prioridad descendente | Origen | Ejemplos |
|---|---|---|
| 1. Variables de configuración del clúster de administración establecidas en la interfaz del instalador | Se introduce en la interfaz del instalador iniciada por la opción –ui y se escribe en los archivos de configuración del clúster. La ubicación del archivo por defecto es~/.config/tanzu/tkg/clusterconfigs/. |
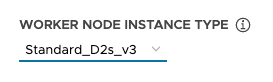 |
| 2. Variables de configuración del clúster establecidas en el entorno local | Se establece en shell. | export AZURE_NODE_MACHINE_TYPE=Standard_D2s_v3 |
3. Variables de configuración del clúster establecidas en la CLI de Tanzu, con tanzu config set env. |
Establecer en shell; se guardó en el archivo de configuración global de la CLI de Tanzu, ~/.config/tanzu/config.yaml. |
tanzu config set env.AZURE_NODE_MACHINE_TYPE Standard_D2s_v3 |
| 4. Variables de configuración del clúster establecidas en el archivo de configuración del clúster | Establecer en el archivo pasado a la opción –file de tanzu management-cluster create o tanzu cluster create. La archivo de forma predeterminada es ~/.config/tanzu/tkg/cluster-config.yaml. |
AZURE_NODE_MACHINE_TYPE: Standard_D2s_v3 |
| 5. Valores de configuración predeterminados de fábrica | Establecer en providers/config_default.yaml. No modifique este archivo. |
AZURE_NODE_MACHINE_TYPE: “Standard_D2s_v3” |
