









Puede utilizar dos VLAN no enrutables que están separadas de forma lógica y de forma física para generar una topología de aislamiento.
En este ejemplo se indican los pasos de configuración para un vSphere Distributed Switch, pero también se pueden utilizar conmutadores estándar de vSphere. Utiliza dos NIC físicas de 10 GB y las separa de forma lógica en la capa de redes de vSphere.
Cree dos grupos de puertos distribuidos para cada vmknic de VMkernel de vSAN. Cada grupo de puertos tiene una etiqueta de VLAN independiente. Para la configuración de VMkernel de vSAN, se requieren dos direcciones IP en ambas VLAN para el tráfico de vSAN.
Las implementaciones prácticas suelen utilizar cuatro vínculos superiores físicos para obtener una redundancia completa.
Para cada grupo de puertos, la directiva de formación de equipos y conmutación por error utiliza la configuración predeterminada.
-
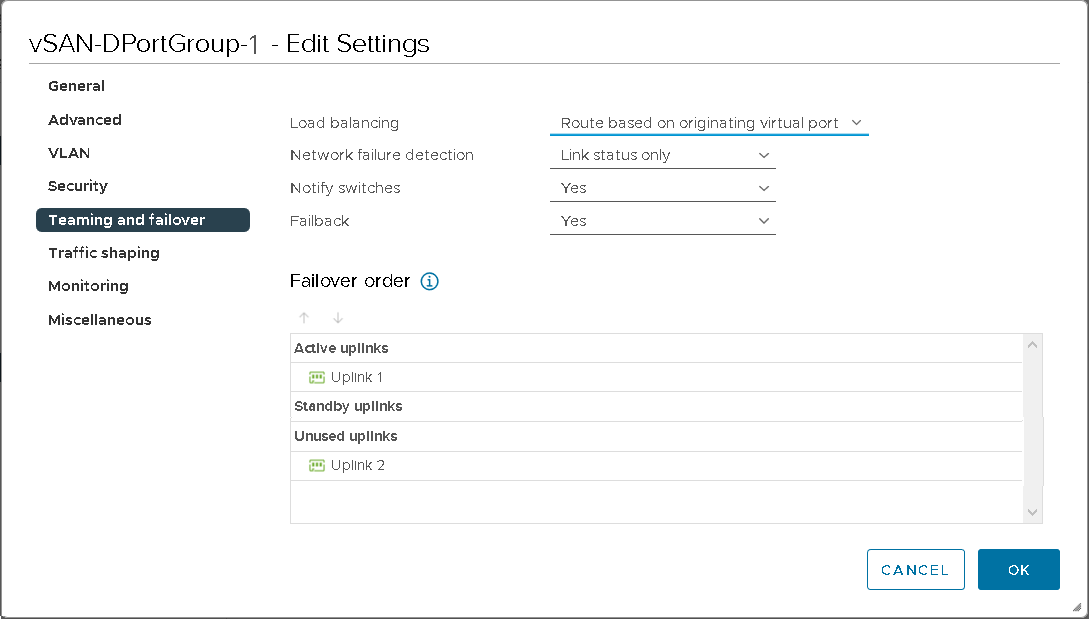
Equilibrio de carga: Enrutar según el identificador de puerto de origen
-
Detección de errores de red: Solo estado de vínculo
-
Notificar a conmutadores: Sí (valor predeterminado)
-
Conmutación por recuperación: Sí (valor predeterminado)
-
La configuración del vínculo superior tiene un vínculo superior en la posición Activo y otro en la posición Sin utilizar.
Una red está totalmente aislada de la otra red.
Grupo de puertos 1 de vSAN
En este ejemplo, se utiliza un grupo de puertos distribuidos llamado vSAN-DPortGroup-1. VLAN 3266 está etiquetado para este grupo de puertos con la siguiente directiva de formación de equipos y conmutación por error:
-
Tráfico en el grupo de puertos etiquetado con VLAN 3266
-
Equilibrio de carga: Enrutar según el identificador de puerto de origen
-
Detección de errores de red: Solo estado de vínculo
-
Notificar a conmutadores: Sí (valor predeterminado)
-
Conmutación por recuperación: Sí (valor predeterminado)
-
La configuración del vínculo superior tiene el vínculo superior 1 en la posición Activo y el vínculo superior 2 en la posición Sin utilizar.
Grupo de puertos 2 de vSAN
Para complementar el grupo de puertos 1 de vSAN, configure un segundo grupo de puertos distribuidos llamado vSAN-portgroup-2 con las siguientes diferencias:
-
Tráfico en el grupo de puertos etiquetado con VLAN 3265
-
La configuración del vínculo superior tiene el vínculo superior 2 en la posición Activo y el vínculo superior 1 en la posición Sin utilizar.
Configuración de puerto de VMkernel de vSAN
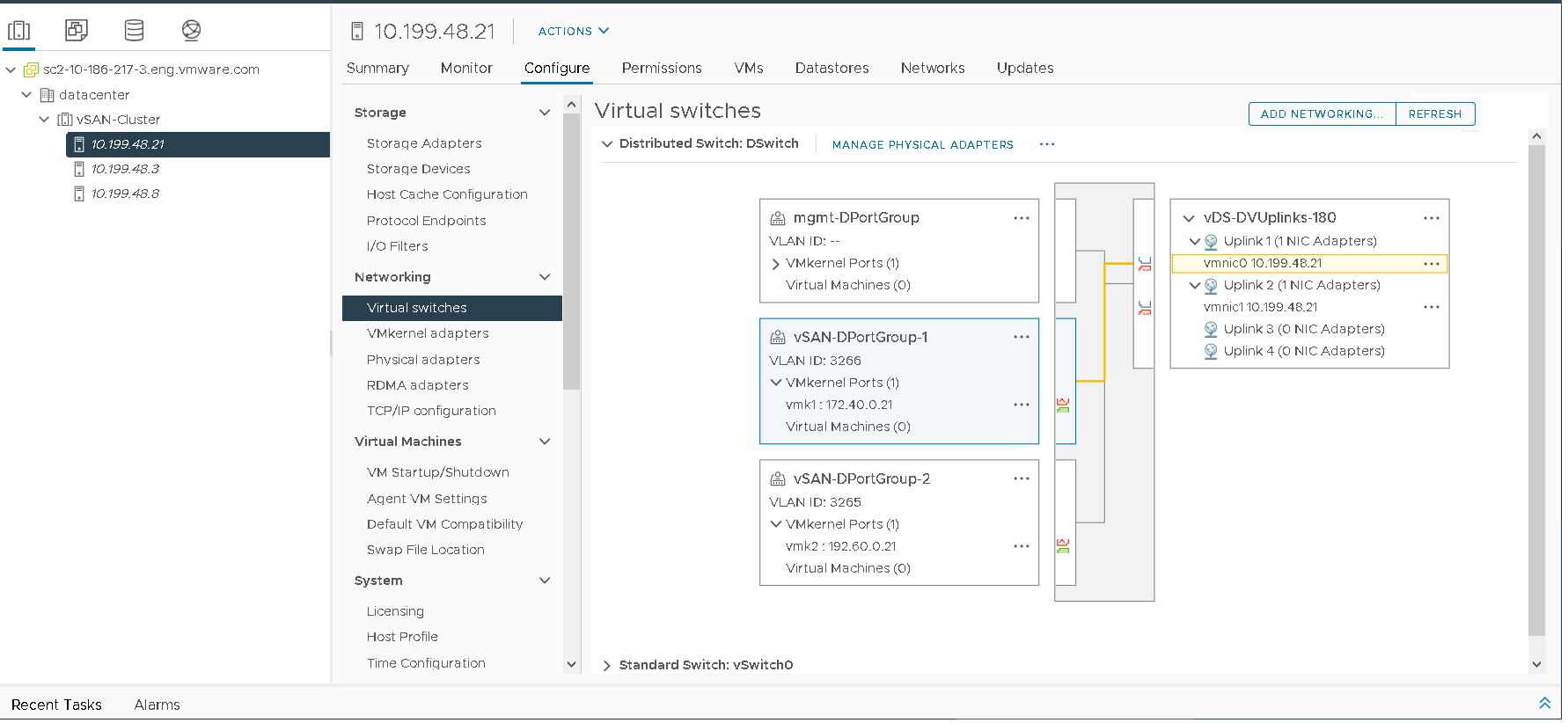
Cree dos interfaces de vSAN VMkernel en ambos grupos de puertos. En este ejemplo, los grupos de puertos se llaman vmk1 y vmk2.
-
vmk1 está asociado a VLAN 3266 (172.40.0.xx) y, como resultado, al grupo de puertos vSAN-DPortGroup-1.
-
vmk2 está asociado a VLAN 3265 (192.60.0.xx) y, como resultado, al grupo de puertos vSAN-DPortGroup-2.
Equilibrio de carga
vSAN no tiene ningún mecanismo de equilibrio de carga para diferenciar entre varios vmknics, por lo que la ruta de E/S de vSAN seleccionada no es determinista en las NIC físicas. Los gráficos de rendimiento de vSphere muestran que una NIC física suele utilizarse más que la otra. Una sencilla prueba de E/S realizada en nuestros laboratorios usando 120 máquinas virtuales con un índice de lectura/escritura de 70:30 y un tamaño de bloque de 64K en un clúster de vSAN de cuatro hosts basado íntegramente en tecnología flash reveló una carga desequilibrada en todas las NIC.
Los gráficos de rendimiento de vSphere muestran una carga desequilibrada en las NIC.
Pérdida de redundancia de vínculo superior de red
Considere un error de red introducido en esta configuración. vmnic1 está deshabilitado en un determinado host de vSAN. Como resultado, se ve afectado el puerto vmk2. Una NIC con errores activa tanto alarmas de conectividad de red como alarmas de redundancia.
Para vSAN, este proceso de conmutación por error se activa aproximadamente 10 segundos después de que CMMDS detecta un error . Durante la conmutación por error y la recuperación, vSAN detiene las conexiones activas en la red con errores e intenta restablecer las conexiones en la red funcional restante.
Debido a que dos puertos de VMkernel de vSAN independientes se comunican en VLAN aisladas, es posible que se activen errores de comprobación de estado de vSAN. Esto se espera, ya que vmk2 ya no puede comunicarse con sus pares en VLAN 3265.
Los gráficos de rendimiento muestran que la carga de trabajo afectada se reinició en vmnic0, ya que vmnic1 tiene un error (deshabilitado para los fines de esta prueba). Esta prueba ilustra una diferencia importante entre la formación de equipos de NIC de vSphere y esta topología. vSAN intenta restablecer o reiniciar las conexiones en la red restante.
Sin embargo, en algunos casos de error, la recuperación de las conexiones afectadas puede requerir hasta 90 segundos para completarse debido al tiempo de espera de la conexión TCP de ESXi. Es posible que se produzca un error en los intentos de conexión posteriores, pero el tiempo de espera de los intentos de conexión se agota en 5 segundos y los intentos se rotan en todas las direcciones IP posibles. Este comportamiento puede afectar a la E/S del invitado de la máquina virtual. Como resultado, es posible que sea necesario volver a intentar la E/S de las máquinas virtuales y las aplicaciones.
Por ejemplo, en las máquinas virtuales con Windows Server 2012, es posible que se registren los identificadores de eventos 153 (restablecimiento de dispositivos) y 129 (eventos de reintento) durante el proceso de conmutación por error y recuperación. En el ejemplo, el identificador de evento 129 se registró aproximadamente 90 segundos hasta que se recuperó la E/S.
Es posible que tenga que modificar la configuración del tiempo de espera del disco de algunos sistemas operativos invitados para garantizar que no se vean gravemente afectados. Los valores de tiempo de espera de disco pueden variar en función de la presencia de VMware Tools y del tipo de sistema operativo invitado y su versión. Para obtener más información sobre cómo cambiar los valores de tiempo de espera del disco de SO invitado, consulte el artículo 1009465 de la base de conocimientos de VMware.
Recuperación y conmutación por recuperación
Cuando se repara la red, las cargas de trabajo no se vuelven a equilibrar automáticamente, a menos que se produzca otro error al forzar la carga de trabajo debido a otro error. Tan pronto como la red afectada se recupera, queda disponible para las nuevas conexiones TCP.
