Conozca cuáles son las topologías y directrices generales para implementar un Supervisor en un clúster de vSAN ampliado. El clúster de vSAN ampliado ofrece la capacidad de ejecutar máquinas virtuales con alta disponibilidad en un entorno de centro de datos ampliado. A partir de la versión vSphere 8 Update 3, también puede ejecutar cargas de trabajo de TKG en un único clúster ampliado de vSAN que tenga un mismo número de hosts separados geográficamente. De esta forma, se proporciona alta disponibilidad distribuida para las cargas de trabajo de TKG en un entorno de centro de datos ampliado.
Un clúster ampliado de vSAN es un clúster de vSAN que abarca dos sitios de datos para una disponibilidad y un equilibrio de carga entre los sitios más rápidos. Ambos sitios tienen el mismo número de hosts ESXi y forman parte del mismo clúster de vSphere. Por lo general, los sitios que forman parte de un clúster ampliado de vSAN se encuentran en ubicaciones separadas geográficamente y se denominan dominios de errores de vSAN. En la mayoría de los casos, los clústeres ampliados de vSAN se implementan en entornos donde la distancia entre los centros de datos es limitada, por ejemplo, entornos metropolitanos o de campus. En la configuración de un clúster ampliado de vSAN, los dos sitios de datos son sitios activos. En caso de que se produzca un error en un sitio, las cargas de trabajo se reinician en el sitio que siga activo. Cada clúster ampliado de vSAN también tiene un nodo testigo que sirve como factor determinante cuando se debe tomar una decisión en relación con la disponibilidad de los componentes del almacén de datos cuando se pierde la conexión de red entre los dos sitios.
Para obtener más información sobre los clústeres ampliados de vSAN, consulte la Documentación de VMware vSAN y la Guía de clústeres ampliados de vSAN.
Puede implementar un Supervisor en un clúster ampliado de vSAN existente en modo activo/activo. Cuando se implementa un Supervisor en un clúster ampliado de vSAN y se aplica la configuración para proporcionar HA a las cargas de trabajo de Supervisor, esta configuración se conoce como modo de implementación.
La implementación de Supervisor admitida en un clúster ampliado de vSAN es un Supervisor de zona única, donde el clúster de vSphere subyacente es un clúster ampliado de vSAN.
Para implementar un clúster ampliado de vSAN, siga las recomendaciones e instrucciones proporcionadas en la Guía de clústeres ampliados de vSAN y la Documentación de VMware vSAN. Para activar y configurar un Supervisor que se ejecute en un clúster ampliado de vSAN, siga las instrucciones de la guía actual. De esta forma, puede asegurarse de que:
- Un error en un único host no desactiva todas las máquinas virtuales del plano de control del Supervisor y los nodos del plano de control y de trabajo de Tanzu Kubernetes Grid.
- El aislamiento o el error en un solo sitio permiten que todas las cargas de trabajo del Supervisor se recuperen por completo y vuelvan al estado de ejecución en el sitio que sigue funcionando. Si se produce un error en uno de los sitios del clúster ampliado de vSAN o queda aislado del otro sitio y del testigo, las cargas de trabajo del Supervisor aún se pueden recuperar y devolver al estado de ejecución en el otro sitio que aún está en funcionamiento y conectado al nodo testigo. Esto incluye todas las máquinas virtuales del plano de control del Supervisor, los nodos de trabajo y del plano de control del clúster de Tanzu Kubernetes Grid, y todos los pods dentro de clústeres de Tanzu Kubernetes Grid.
- Al desactivar el vínculo entre sitios de los dos sitios a través de la red de vSAN, se permite que todas las cargas de trabajo, las máquinas virtuales del plano de control del Supervisor y los nodos de trabajo y de plano de control de Tanzu Kubernetes Grid se recuperen y vuelvan al estado de ejecución.
- Todas las cargas de trabajo del Supervisor pueden acceder a las notificaciones de volumen persistente (Persistent Volume Claims, PVC) a las que accedían antes del evento de error, incluidos un error de host único, un error o aislamiento de todo el sitio, o un error de vínculo entre sitios.
- Todos los servicios de equilibrador de carga de Tanzu Kubernetes Grid y del Supervisor siguen siendo accesibles desde fuera del Supervisor después de un evento de error.
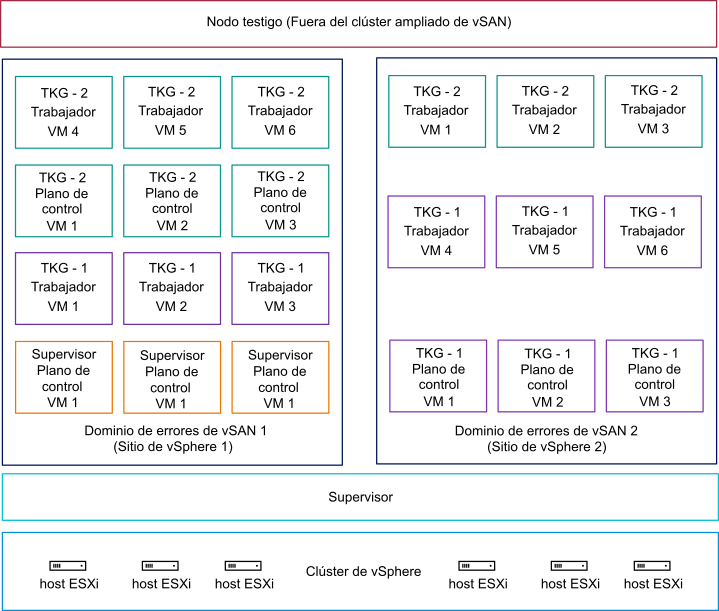
En el siguiente ejemplo de implementación, el clúster ampliado de vSAN se ejecuta en una topología activa/activa. El Supervisor se configura respectivamente en un modo de implementación activa/activa. Los nodos del plano de control del clúster de Tanzu Kubernetes Grid y del Supervisor se colocan. Los nodos de trabajo de los clústeres de Tanzu Kubernetes Grid se distribuyen entre los dos sitios. La ubicación de las máquinas virtuales del clúster de Tanzu Kubernetes Grid y del Supervisor se determina mediante reglas de afinidad de sitio. Se implementa un host testigo fuera del clúster ampliado de vSAN.