









Cuando se habilita vSphere IaaS control plane en clústeres de vSphere y se convierten en Supervisores, el plano de control de Kubernetes se crea dentro de la capa del hipervisor. Esta capa contiene objetos específicos que habilitan la capacidad para ejecutar cargas de trabajo de Kubernetes en ESXi.
El diagrama muestra la arquitectura de alto nivel de vSphere IaaS control plane, con Tanzu Kubernetes Grid en la parte superior, el Supervisor en el centro y, a continuación, ESXi, las redes y el almacenamiento en la parte inferior, donde vCenter Server se encarga de administrarlos.
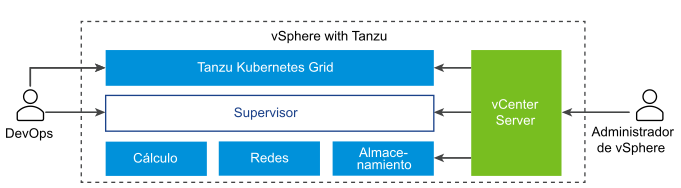
Un Supervisor se ejecuta sobre una capa de SDDC compuesta por ESXi para recursos informáticos, NSX o redes VDS y vSAN u otra solución de almacenamiento compartido. El almacenamiento compartido se utiliza para volúmenes persistentes de los pods de vSphere y máquinas virtuales que se ejecutan dentro del Supervisor, y pods de un clúster de Tanzu Kubernetes Grid. Después de crear un Supervisor, como administrador de vSphere puede crear espacios de nombres de vSphere dentro del Supervisor. Como ingeniero de desarrollo y operaciones, puede ejecutar cargas de trabajo que contengan contenedores que se ejecutan dentro de los pods de vSphere, implementar máquinas virtuales a través del servicio de máquina virtual y crear clústeres de Tanzu Kubernetes Grid.
Puede implementar un Supervisor en tres zonas de vSphere para proporcionar alta disponibilidad de nivel de clúster que proteja las cargas de trabajo de Kubernetes contra errores en el nivel de clúster. Una zona de vSphere se asigna a un clúster de vSphere que se puede configurar como un dominio de errores independiente. En una implementación de tres zonas, los tres clústeres de vSphere se convierten en un Supervisor. También puede implementar un Supervisor en un clúster de vSphere, que creará automáticamente una zona de vSphere y la asignará al clúster, a menos que se use un clúster de vSphere que ya esté asignado a una zona. En una implementación de clúster único, el Supervisor solo tiene alta disponibilidad en el nivel de host que proporciona vSphere HA.
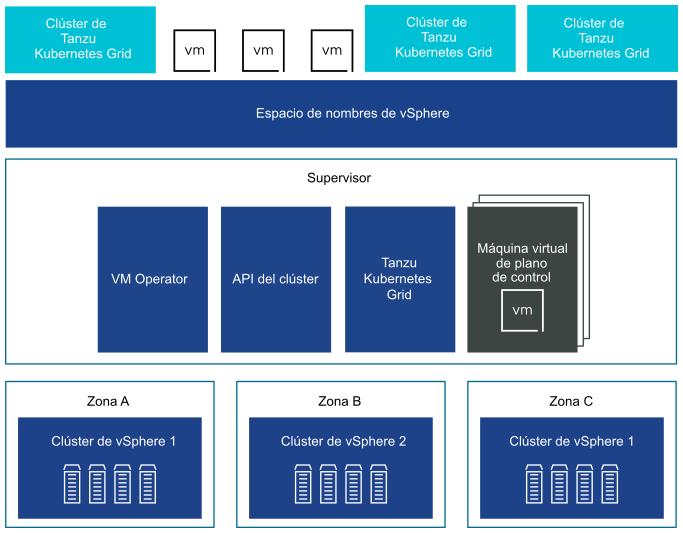
En un Supervisor de tres zonas, puede ejecutar cargas de trabajo de Kubernetes en clústeres de Tanzu Kubernetes Grid y en máquinas virtuales creadas mediante el servicio de máquina virtual. Un Supervisor de tres zonas tiene los siguientes componentes:
- Máquina virtual del plano de control del Supervisor. En total, en el Supervisor se crean tres máquinas virtuales del plano de control del Supervisor. En una implementación de tres zonas, una máquina virtual del plano de control reside en cada zona. Las tres máquinas virtuales del plano de control del Supervisor cuentan con equilibrio de carga, ya que cada una de ellas tiene su propia dirección IP. Además, se asigna una dirección IP flotante a una de las máquinas virtuales y se reserva una 5.ª dirección IP para fines de aplicación de revisiones. vSphere DRS determina la colocación exacta de las máquinas virtuales del plano de control en los hosts ESXi que forman parte del Supervisor y las migra cuando es necesario.
- Tanzu Kubernetes Grid y la API de clúster. Módulos que se ejecutan en el Supervisor y habilitan el aprovisionamiento y la administración de clústeres de Tanzu Kubernetes Grid.
- servicio de máquina virtual. Un módulo que es responsable de implementar y ejecutar las máquinas virtuales independientes y las máquinas virtuales que conforman clústeres de Tanzu Kubernetes Grid.
En un Supervisor de tres zonas se crea un grupo de recursos de espacio de nombres un en cada clúster de vSphere que se asigna a una zona. El espacio de nombres se distribuye entre los tres clústeres de vSphere en cada zona. Los recursos utilizados para el espacio de nombres en un Supervisor de tres zonas se toman de los tres clústeres de vSphere subyacentes a partes iguales. Por ejemplo, si dedica 300 MHz de CPU, se toman 100 MHz de cada clúster de vSphere.
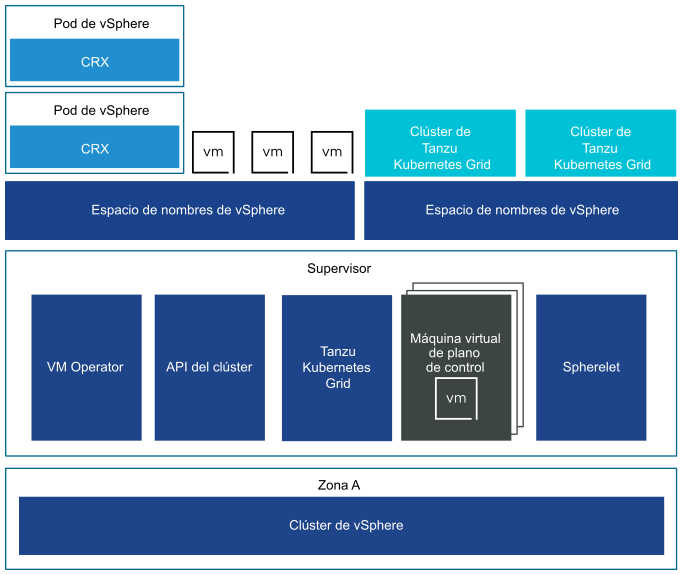
Un Supervisor implementado en un solo clúster de vSphere también tiene tres máquinas virtuales del plano de control que residen en los hosts ESXi que forman parte del clúster. En un Supervisor de clúster único se pueden ejecutar pods de vSphere además de máquinas virtuales y clústeres de Tanzu Kubernetes Grid. vSphere DRS se integra con el programador de Kubernetes en las máquinas virtuales del plano de control del Supervisor, por lo que DRS determina la colocación de los pods de vSphere. Cuando programa una pod de vSphere como ingeniero de operaciones y desarrollo, la solicitud pasa por el flujo de trabajo de Kubernetes común y después a DRS, el cual toma la decisión de colocación final.
Debido a la compatibilidad con pod de vSphere, un Supervisor de clúster único tiene los siguientes componentes adicionales:
- Spherelet. Se crea un proceso adicional llamado "Spherelet" en cada host. Se trata de un kubelet que se transporta de forma nativa a ESXi y permite que el host ESXi se convierta en parte del clúster de Kubernetes.
- Componente Container Runtime Executive (CRX). CRX es similar a una máquina virtual desde la perspectiva de Hostd y vCenter Server. CRX incluye un kernel de Linux paravirtualizado que funciona junto con el hipervisor. CRX utiliza las mismas técnicas de virtualización de hardware que las máquinas virtuales y tiene un límite de máquina virtual alrededor. Se utiliza una técnica de arranque directo, que permite que el invitado de CRX de Linux inicie el proceso de inicialización principal sin pasar por la inicialización del kernel. Esto permite que los pods de vSphere arranquen casi tan rápido como los contenedores.
