Aprenda a transmitir métricas de Supervisor recopiladas por Telegraf a una plataforma de observación personalizada. Telegraf se habilita de forma predeterminada en el Supervisor y recopila métricas en formato Prometheus de los componentes de Supervisor, como el servidor de API de Kubernetes, el servicio de máquina virtual y Tanzu Kubernetes Grid, entre otros. Como administrador de vSphere, puede configurar una plataforma de observación, como VMware Aria Operations for Applications, Grafana y otras, con la finalidad de ver y analizar las métricas de Supervisor recopiladas.
Telegraf es un agente basado en servidores que se utiliza para recopilar y enviar métricas procedentes de diferentes sistemas, bases de datos e IoT. Cada componente de Supervisor expone un endpoint al que se conecta Telegraf. Después, Telegraf envía las métricas recopiladas a la plataforma de observación que elija. Puede configurar alguno de los complementos de salida que Telegraf admite como plataforma de observación para agregar y analizar métricas de Supervisor. Consulte la documentación de Telegraf para obtener información sobre los complementos de salida compatibles.
Los siguientes componentes exponen endpoints a los que se conecta Telegraf y recopila métricas: servidor de API de Kubernetes, etcd, kubelet, administrador de controladores de Kubernetes, programador de Kubernetes, Tanzu Kubernetes Grid, servicio de máquina virtual, servicio de imagen de máquina virtual, NSX Container Plug-in (NCP), interfaz de almacenamiento de contenedor (Container Storage Interface, CSI), administrador de certificados, NSX y varias métricas de host, como CPU, memoria y almacenamiento.
Ver los pods y la configuración de Telegraf
Telegraf se ejecuta en el espacio de nombres del sistema vmware-system-monitoring en el Supervisor. Para ver los pods y ConfigMap de Telegraf:
- Inicie sesión en el plano de control de Supervisor con una cuenta de administrador de vCenter Single Sign-On.
kubectl vsphere login --server <control planе IP> --vsphere-username [email protected]
- Con el siguiente comando, vea los pods de Telegraf:
kubectl -n vmware-system-monitoring get pods
Los pods resultantes son los siguientes:telegraf-csqsl telegraf-dkwtk telegraf-l4nxk
- Con el siguiente comando, vea los ConfigMap de Telegraf:
kubectl -n vmware-system-monitoring get cm
Los ConfigMap resultantes son los siguientes:default-telegraf-config kube-rbac-proxy-config kube-root-ca.crt telegraf-config
El ConfigMap
default-telegraf-configcontiene la configuración predeterminada de Telegraf y es de solo lectura. Puede utilizarlo como opción de reserva para restaurar la configuración entelegraf-configen caso de que el archivo esté dañado o simplemente desee restaurar los valores predeterminados. El único ConfigMap que puede editar estelegraf-config, el cual define qué componentes envían métricas a los agentes de Telegraf y a qué plataformas. - Vea el ConfigMap de
telegraf-config:kubectl -n vmware-system-monitoring get cm telegraf-config -o yaml
inputs del ConfigMap
telegraf-config define todos los endpoints de los componentes de
Supervisor en los que Telegraf recopila métricas, así como los tipos de métricas en sí. Por ejemplo, la siguiente entrada define el servidor de API de Kubernetes como un endpoint:
[[inputs.prometheus]]
# APIserver
## An array of urls to scrape metrics from.
alias = "kube_apiserver_metrics"
urls = ["https://127.0.0.1:6443/metrics"]
bearer_token = "/run/secrets/kubernetes.io/serviceaccount/token"
# Dropping metrics as a part of short term solution to vStats integration 1MB metrics payload limit
# Dropped Metrics:
# apiserver_request_duration_seconds
namepass = ["apiserver_request_total", "apiserver_current_inflight_requests", "apiserver_current_inqueue_requests", "etcd_object_counts", "apiserver_admission_webhook_admission_duration_seconds", "etcd_request_duration_seconds"]
# "apiserver_request_duration_seconds" has _massive_ cardinality, temporarily turned off. If histogram, maybe filter the highest ones?
# Similarly, maybe filters to _only_ allow error code related metrics through?
## Optional TLS Config
tls_ca = "/run/secrets/kubernetes.io/serviceaccount/ca.crt"
La propiedad alias indica el componente desde el que se recopilan las métricas. La propiedad namepass especifica qué métricas de componentes exponen y recopilan respectivamente los agentes de Telegraf.
Aunque el ConfigMap telegraf-config ya contiene un amplio rango de métricas, puede definir otras adicionales. Consulte Métricas para componentes del sistema de Kubernetes y Referencia de métricas de Kubernetes.
Configurar la plataforma de observación en Telegraf
En la sección outps de telegraf-config puede configurar dónde transmite Telegraf las métricas que recopila. Existen varias opciones, como outputs.file, outputs.wavefront, outputs.prometheus_client y outps-https. La sección outps-https es donde puede configurar las plataformas de observación que desea utilizar para la adición y la supervisión de las métricas de Supervisor. Telegraf se puede configurar para enviar las métricas a más de una plataforma. Para editar el ConfigMap telegraf-config y configurar una plataforma de observación donde ver las métricas de Supervisor, siga los pasos que se indican a continuación:
- Inicie sesión en el plano de control de Supervisor con una cuenta de administrador de vCenter Single Sign-On.
kubectl vsphere login --server <control planе IP> --vsphere-username [email protected]
- Guarde el ConfigMap
telegraf-configen la carpeta kubectl local:kubectl get cm telegraf-config -n vmware-system-monitoring -o jsonpath="{.data['telegraf\.conf']}">telegraf.confAsegúrese de almacenar el ConfigMap
telegraf-configen un sistema de control de versiones antes de realizar cambios en él en caso de que desee restaurar una versión anterior del archivo. En caso de que desee restaurar la configuración predeterminada, puede utilizar los valores del ConfigMapdefault-telegraf-config. - Agregue secciones
outputs.httpcon la configuración de conexión de las plataformas de observación que elija mediante un editor de texto, como VIM:vim telegraf.config
Puede eliminar directamente la marca de comentario de la siguiente sección y editar los valores según corresponda, o bien puede agregar una secciónoutputs.httpnueva según sea necesario.#[[outputs.http]] # alias = "prometheus_http_output" # url = "<PROMETHEUS_ENDPOINT>" # insecure_skip_verify = <PROMETHEUS_SKIP_INSECURE_VERIFY> # data_format = "prometheusremotewrite" # username = "<PROMETHEUS_USERNAME>" # password = "<PROMETHEUS_PASSWORD>" # <DEFAULT_HEADERS>Por ejemplo, así sería una configuración deoutputs.httppara Grafana:[[outputs.http]] url = "http://<grafana-host>:<grafana-metrics-port>/<prom-metrics-push-path>" data_format = "influx" [outputs.http.headers] Authorization = "Bearer <grafana-bearer-token>"
Consulte Transferir métricas desde Telegraf a Grafana para obtener más información sobre cómo configurar paneles de control y consumir métricas de Telegraf.
A continuación se muestra un ejemplo con VMware Aria Operations for Applications (anteriormente conocido como Wavefront):[[outputs.wavefront]] url = "http://<wavefront-proxy-host>:<wavefront-proxy-port>"El método que se recomienda para introducir métricas en Aria Operations for Applications es a través de un proxy. Consulte Proxies de Wavefront para obtener más información.
- Reemplace el archivo
telegraf-configexistente en el Supervisor por el que editó en su carpeta local:kubectl create cm --from-file telegraf.conf -n vmware-system-monitoring telegraf-config --dry-run=client -o yaml | kubectl replace -f -
- Compruebe si la nueva configuración se ha guardado correctamente:
- Vea el nuevo ConfigMap telegraf-config:
kubectl -n vmware-system-monitoring get cm telegraf-config -o yaml
- Compruebe si todos los pods de Telegraf están en funcionamiento:
kubectl -n vmware-system-monitoring get pods
- En caso de que algunos de los pods de Telegraf no se estén ejecutando, compruebe los registros de Telegraf para ese pod para solucionar los problemas:
kubectl -n vmware-system-monitoring logs <telegraf-pod>
- Vea el nuevo ConfigMap telegraf-config:
Paneles de control de ejemplo de Operations for Applications
A continuación se muestra un panel de control con un resumen de las métricas recibidas desde el servidor de API y etcd en un Supervisor a través de Telegraf:
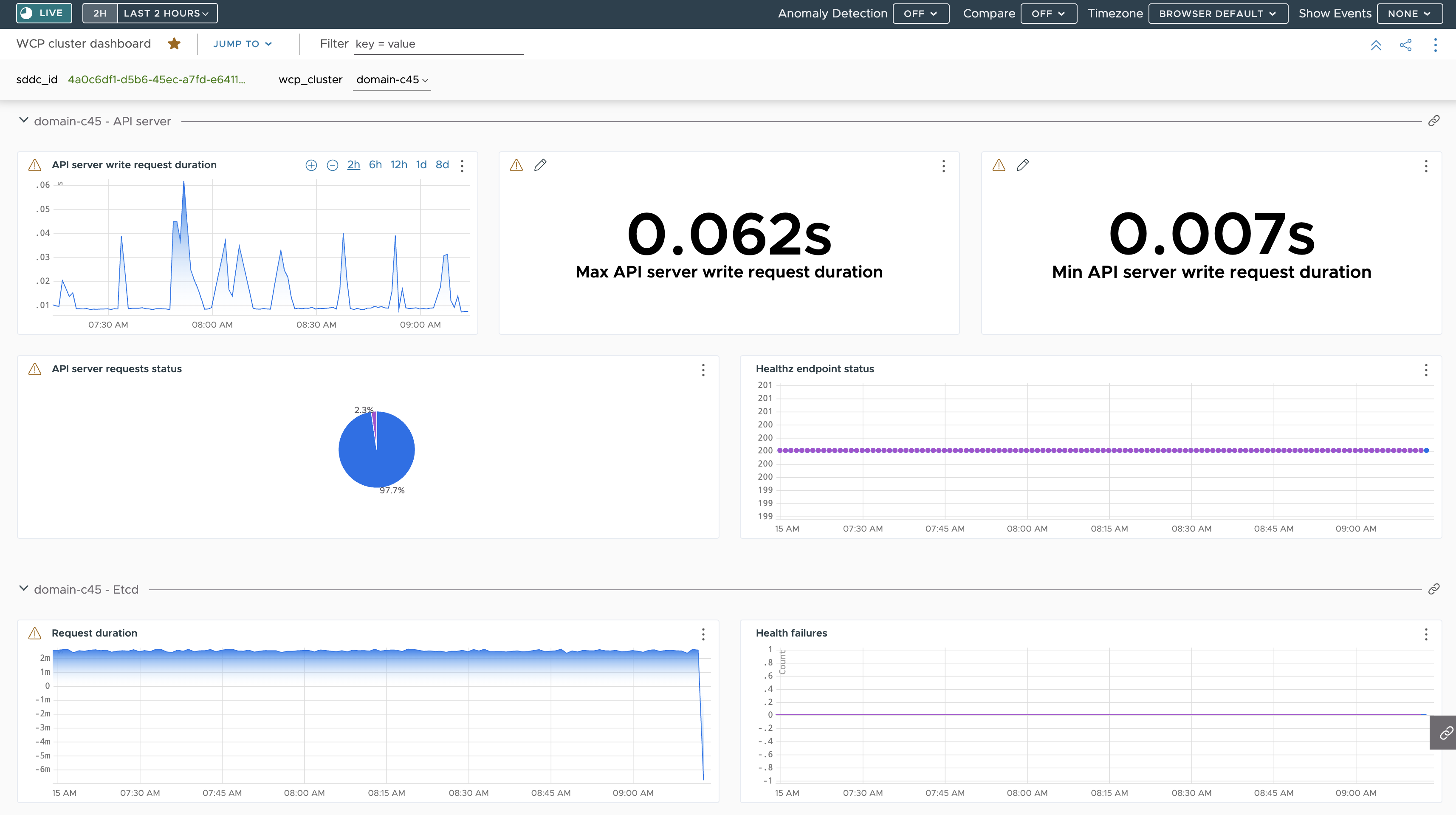
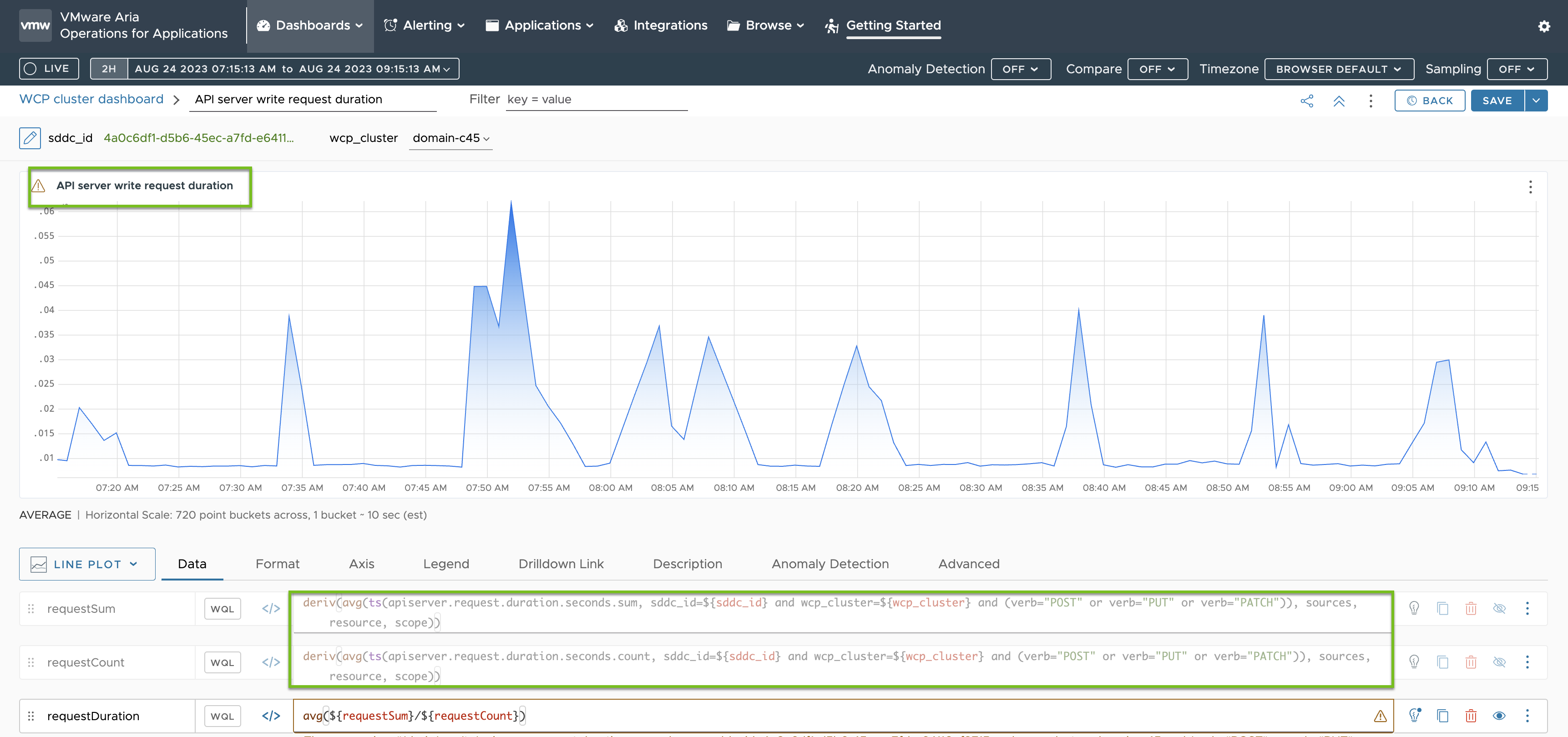
Las métricas para la duración de la solicitud de escritura del servidor de API se basan en las métricas que se especifican en el ConfigMap telegraf-config como se puede ver resaltado en verde: