Con variables y expresiones, es posible usar parámetros de entrada y de salida con las tareas de la canalización. Los parámetros que introduce enlazan la tarea de canalización a una o más variables, expresiones o condiciones, y determinan el comportamiento de la canalización cuando se ejecuta.
Las canalizaciones pueden ejecutar soluciones de distribución de software simples o complejas
Al enlazar tareas de canalización, puede incluir expresiones complejas y predeterminadas. Como resultado, la canalización puede ejecutar soluciones de distribución de software simples o complejas.
Para crear los parámetros en la canalización, haga clic en la pestaña Entrada o Salida y agregue una variable mediante la introducción del signo $ y una expresión. Por ejemplo, este parámetro se utiliza como una entrada de tarea que llama a una URL: ${Stage0.Task3.input.URL}.
El formato de enlaces de variables utiliza componentes de sintaxis denominados ámbitos y claves. El SCOPE define el contexto como entrada o salida, y la KEY define los detalles. En la ${Stage0.Task3.input.URL} de ejemplo del parámetro, input es el componente SCOPE y la URL es el componente KEY.
Las propiedades de salida de una tarea se pueden resolver en cualquier cantidad de niveles anidados de enlaces de variables.
Para obtener más información sobre el uso de enlaces de variables en canalizaciones, consulte Cómo utilizar las variables de enlace en canalizaciones de Code Stream.
Usar expresiones de dólar con ámbitos y claves para enlazar tareas de canalización
Puede enlazar las tareas de canalización mediante expresiones en variables de signo de dólar. Las expresiones se introducen como ${SCOPE.KEY.<PATH>}.
Para determinar el comportamiento de una tarea de canalización, en cada expresión, SCOPE es el contexto que utiliza Code Stream. El ámbito busca una KEY, que define el detalle de la acción que lleva a cabo la tarea. Cuando el valor de KEY es un objeto anidado, se puede proporcionar una PATH opcional.
En estos ejemplos, se describen SCOPE y KEY, y se muestra cómo puede utilizarlos en la canalización.
Tabla 1.
Utilizar SCOPE y KEY
| SCOPE |
Propósito de expresión y ejemplo |
KEY |
Cómo utilizar SCOPE y KEY en la canalización |
| input |
Propiedades de entrada de una canalización: ${input.input1}
|
Nombre de la propiedad de entrada |
Para hacer referencia a la propiedad de entrada de una canalización en una tarea, utilice este formato:
tasks:
mytask:
type: REST
input:
url: ${input.url}
action: get
input:
url: https://www.vmware.com
|
| output |
Propiedades de salida de una canalización: ${output.output1}
|
Nombre de la propiedad de salida |
Para hacer referencia a una propiedad de salida para enviar una notificación, utilice este formato:
notifications:
email:
- endpoint: MyEmailEndpoint
subject: "Deployment Successful"
event: COMPLETED
to:
- [email protected]
body: |
Pipeline deployed the service successfully. Refer ${output.serviceURL}
|
| task input |
Entrada de una tarea: ${MY_STAGE.MY_TASK.input.SOMETHING}
|
Indica la entrada de una tarea en una notificación. |
Cuando se inicia un trabajo de Jenkins, puede hacer referencia al nombre del trabajo que se activa desde la entrada de la tarea. En este caso, envíe una notificación con este formato:
notifications:
email:
- endpoint: MyEmailEndpoint
stage: MY_STAGE
task: MY_TASK
subject: "Build Started"
event: STARTED
to:
- [email protected]
body: |
Jenkins job ${MY_STAGE.MY_TASK.input.job} started for commit id ${input.COMMITID}.
|
| task output |
Salida de una tarea: ${MY_STAGE.MY_TASK.output.SOMETHING}
|
Indica la salida de una tarea en una tarea posterior. |
Para hacer referencia a la salida de la tarea de canalización 1 en la tarea 2, utilice este formato:
taskOrder:
- task1
- task2
tasks:
task1:
type: REST
input:
action: get
url: https://www.example.org/api/status
task2:
type: REST
input:
action: post
url: https://status.internal.example.org/api/activity
payload: ${MY_STAGE.task1.output.responseBody}
|
| var |
Variable: ${var.myVariable}
|
Referencia a la variable de un endpoint |
Para hacer referencia a una variable secreta en un endpoint de una contraseña, utilice este formato:
---
project: MyProject
kind: ENDPOINT
name: MyJenkinsServer
type: jenkins
properties:
url: https://jenkins.example.com
username: jenkinsUser
password: ${var.jenkinsPassword}
|
| var |
Variable: ${var.myVariable}
|
Referencia a la variable en una canalización |
Para hacer referencia a la variable en una URL de canalización, utilice este formato:
tasks:
task1:
type: REST
input:
action: get
url: ${var.MY_SERVER_URL}
|
| task status |
Estado de una tarea: ${MY_STAGE.MY_TASK.status}
${MY_STAGE.MY_TASK.statusMessage}
|
|
|
| stage status |
Estado de una etapa: ${MY_STAGE.status}
${MY_STAGE.statusMessage}
|
|
|
Expresiones predeterminadas
Puede utilizar variables con expresiones en la canalización. Este resumen incluye las expresiones predeterminadas que puede utilizar.
| Expresión |
Descripción |
${comments} |
Comentarios proporcionados al solicitar la ejecución de la canalización. |
${duration} |
Duración de la ejecución de la canalización |
${endTime} |
Hora de finalización de la ejecución de la canalización en UTC (si finalizó) |
${executedOn} |
Igual que la hora de inicio, la hora en que comienza la ejecución de la canalización en UTC |
${executionId} |
Identificador de la ejecución de la canalización |
${executionUrl} |
URL que permite acceder a la ejecución de la canalización en la interfaz de usuario |
${name} |
Nombre de la canalización |
${requestBy} |
Nombre del usuario que solicitó la ejecución |
${stageName} |
Nombre de la etapa actual (cuando se utiliza en el ámbito de una etapa) |
${startTime} |
Hora de inicio de la ejecución de la canalización en UTC |
${status} |
Estado de la ejecución |
${statusMessage} |
Mensaje de estado de la ejecución de la canalización |
${taskName} |
Nombre de la tarea actual (cuando se utiliza en una notificación o una entrada de tarea) |
Cómo usar SCOPE y KEY en tareas de canalización
Puede utilizar expresiones con cualquiera de las tareas de canalización compatibles. En estos ejemplos se muestra cómo definir SCOPE y KEY, y cómo confirmar la sintaxis. Los ejemplos de código utilizan MY_STAGE y MY_TASK como los nombres de la etapa y la tarea de canalización.
Para obtener más información sobre las tareas disponibles, consulte Qué tipos de tareas están disponibles en Code Stream.
Tabla 2.
Tareas de activación periódica
| Tarea |
Scope |
Key |
Cómo utilizar SCOPE y KEY en la tarea |
| Operación de usuario |
|
Input |
summary: Resumen de la solicitud de operación de usuario
description: Descripción de la solicitud de operación de usuario
approvers: Lista de direcciones de correo electrónico del aprobador, en las que cada entrada puede ser una variable con una coma, o un punto y coma para correos electrónicos distintos
approverGroups: Lista de direcciones de grupos de aprobadores para la plataforma y la identidad
sendemail: De manera opcional, se envía una notificación por correo electrónico según solicitud o respuesta cuando se establece en true
expirationInDays: Número de días que representa el tiempo de caducidad de la solicitud
|
${MY_STAGE.MY_TASK.input.summary}
${MY_STAGE.MY_TASK.input.description}
${MY_STAGE.MY_TASK.input.approvers}
${MY_STAGE.MY_TASK.input.approverGroups}
${MY_STAGE.MY_TASK.input.sendemail}
${MY_STAGE.MY_TASK.input.expirationInDays}
|
|
Output |
index: Cadena hexadecimal de 6 dígitos que representa la solicitud
respondedBy: Nombre de la cuenta de la persona que aprobó o rechazó la operación de usuario
respondedByEmail: Dirección de correo electrónico de la persona que respondió
comments: Comentarios proporcionados durante la respuesta
|
${MY_STAGE.MY_TASK.output.index}
${MY_STAGE.MY_TASK.output.respondedBy}
${MY_STAGE.MY_TASK.output.respondedByEmail}
${MY_STAGE.MY_TASK.output.comments}
|
| Condición |
|
|
Input |
condition: Condición que se va a evaluar. Cuando la condición se evalúa como true, la tarea se marca como completada, mientras que otras respuestas presentan errores
|
${MY_STAGE.MY_TASK.input.condition}
|
|
Output |
result: Resultado tras la evaluación
|
${MY_STAGE.MY_TASK.output.response}
|
Tabla 3.
Tareas de canalización
| Tarea |
Scope |
Key |
Cómo utilizar SCOPE y KEY en la tarea |
| Canalización |
|
Input |
name: Nombre de la canalización que se va a ejecutar
inputProperties: Propiedades de entrada para transferir a la ejecución de la canalización anidada
|
${MY_STAGE.MY_TASK.input.name}
${MY_STAGE.MY_TASK.input.inputProperties} # Haga referencia a todas las propiedades
${MY_STAGE.MY_TASK.input.inputProperties.input1} # Haga referencia al valor de input1
|
|
Output |
executionStatus: Estado de la ejecución de la canalización
executionIndex: Índice de ejecución de la canalización
outputProperties: Propiedades de salida de una ejecución de la canalización
|
${MY_STAGE.MY_TASK.output.executionStatus}
${MY_STAGE.MY_TASK.output.executionIndex}
${MY_STAGE.MY_TASK.output.outputProperties} # Haga referencia a todas las propiedades
${MY_STAGE.MY_TASK.output.outputProperties.output1} # Haga referencia al valor de output1
|
Tabla 4.
Automatizar tareas de integración continua
| Tarea |
Scope |
Key |
Cómo utilizar SCOPE y KEY en la tarea |
| CI |
|
Input |
steps: Un conjunto de cadenas, que representan los comandos que se ejecutarán
export: Variables de entorno que se conservarán después de ejecutar los pasos
artifacts: Rutas de acceso de artefactos que se conservarán en la ruta de acceso compartida
process: Conjunto de elementos de configuración para procesamiento de JUnit, JaCoCo, Checkstyle, FindBugs
|
${MY_STAGE.MY_TASK.input.steps}
${MY_STAGE.MY_TASK.input.export}
${MY_STAGE.MY_TASK.input.artifacts}
${MY_STAGE.MY_TASK.input.process}
${MY_STAGE.MY_TASK.input.process[0].path} # Haga referencia a la ruta de acceso de la primera configuración
|
|
Output |
exports: Par clave-valor, que representa las variables de entorno exportadas de la entrada export
artifacts: Ruta de acceso de los artefactos conservados correctamente
processResponse:Conjunto de resultados procesados para la entrada process
|
${MY_STAGE.MY_TASK.output.exports} # Haga referencia a todas las exportaciones
${MY_STAGE.MY_TASK.output.exports.myvar} # Haga referencia al valor de myvar
${MY_STAGE.MY_TASK.output.artifacts}
${MY_STAGE.MY_TASK.output.processResponse}
${MY_STAGE.MY_TASK.output.processResponse[0].result} # Resultado de la primera configuración del proceso
|
| Personalizada |
|
Input |
name: Nombre de la integración personalizada
version: Una versión de la integración personalizada, publicada u obsoleta
properties: Propiedades que se enviarán a la integración personalizada
|
${MY_STAGE.MY_TASK.input.name}
${MY_STAGE.MY_TASK.input.version}
${MY_STAGE.MY_TASK.input.properties} # Haga referencia a todas las propiedades
${MY_STAGE.MY_TASK.input.properties.property1} # Haga referencia al valor de property1
|
|
Output |
properties: Propiedades de salida de la respuesta de integración personalizada
|
${MY_STAGE.MY_TASK.output.properties} # Haga referencia a todas las propiedades
${MY_STAGE.MY_TASK.output.properties.property1} # Haga referencia al valor de property1
|
Tabla 5.
Automatizar tareas de implementación continua: plantilla de nube
| Tarea |
Scope |
Key |
Cómo utilizar SCOPE y KEY en la tarea |
| Plantilla de nube |
|
|
Input |
action: una instancia de createDeployment, updateDeployment, deleteDeployment, rollbackDeployment
blueprintInputParams: se utiliza para las acciones de creación de implementación y actualización de implementación.
allowDestroy: permite destruir las máquinas en el proceso de implementación de actualizaciones.
CREATE_DEPLOYMENT
blueprintName: nombre de la plantilla de nube.blueprintVersion: versión de la plantilla de nube O
fileUrl: dirección URL del YAML de plantilla de nube remoto después de seleccionar un servidor de GIT UPDATE_DEPLOYMENT Cualquiera de estas combinaciones:
blueprintName: nombre de la plantilla de nube.blueprintVersion: versión de la plantilla de nube O
fileUrl: dirección URL del YAML de plantilla de nube remoto después de seleccionar un servidor de GIT ------
deploymentId: identificador de la implementación. O
deploymentName: nombre de la implementación. ------
DELETE_DEPLOYMENT
deploymentId: identificador de la implementación. O
deploymentName: nombre de la implementación. ROLLBACK_DEPLOYMENT Cualquiera de estas combinaciones:
deploymentId: identificador de la implementación. O
deploymentName: nombre de la implementación. ------
blueprintName: nombre de la plantilla de nube.rollbackVersion: versión a la que se revertirá |
|
|
Output |
|
Parámetros que se pueden enlazar a otras tareas o a la salida de una canalización:
- Se puede acceder al nombre de la implementación como ${Stage0.Task0.output.deploymentName}.
- Se puede acceder al identificador de implementación como ${Stage0.Task0.output.deploymentId}.
- Los detalles de la implementación son un objeto complejo, y se puede acceder a los detalles internos mediante los resultados de JSON.
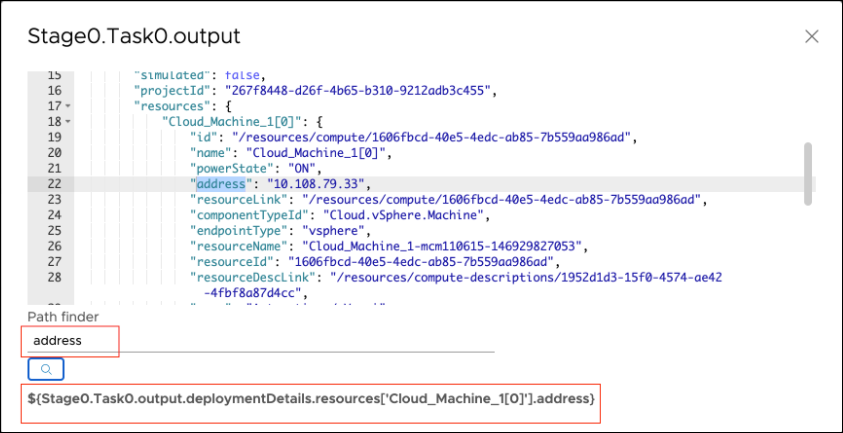
Para acceder a cualquier propiedad, utilice el operador de punto para seguir la jerarquía de JSON. Por ejemplo, para acceder a la dirección del recurso Cloud_Machine_1[0], el enlace $ es: ${Stage0.Task0.output.deploymentDetails.resources['Cloud_Machine_1[0]'].address}. De forma similar, para el tipo, el enlace $ es: ${Stage0.Task0.output.deploymentDetails.resources['Cloud_Machine_1[0]'].flavor}. En la interfaz de usuario de Code Stream, puede obtener los enlaces $ para cualquier propiedad.
- En el área de propiedades de salida de la tarea, haga clic en Ver salida de JSON.
- Para encontrar el enlace $, introduzca cualquier propiedad.
- Haga clic en el icono de búsqueda, que muestra el enlace $ correspondiente.
|
Salida JSON de ejemplo:
Objeto de detalles de implementación de ejemplo:
{
"id": "6a031f92-d0fa-42c8-bc9e-3b260ee2f65b",
"name": "deployment_6a031f92-d0fa-42c8-bc9e-3b260ee2f65b",
"description": "Pipeline Service triggered operation",
"orgId": "434f6917-4e34-4537-b6c0-3bf3638a71bc",
"blueprintId": "8d1dd801-3a32-4f3b-adde-27f8163dfe6f",
"blueprintVersion": "1",
"createdAt": "2020-08-27T13:50:24.546215Z",
"createdBy": "[email protected]",
"lastUpdatedAt": "2020-08-27T13:52:50.674957Z",
"lastUpdatedBy": "[email protected]",
"inputs": {},
"simulated": false,
"projectId": "267f8448-d26f-4b65-b310-9212adb3c455",
"resources": {
"Cloud_Machine_1[0]": {
"id": "/resources/compute/1606fbcd-40e5-4edc-ab85-7b559aa986ad",
"name": "Cloud_Machine_1[0]",
"powerState": "ON",
"address": "10.108.79.33",
"resourceLink": "/resources/compute/1606fbcd-40e5-4edc-ab85-7b559aa986ad",
"componentTypeId": "Cloud.vSphere.Machine",
"endpointType": "vsphere",
"resourceName": "Cloud_Machine_1-mcm110615-146929827053",
"resourceId": "1606fbcd-40e5-4edc-ab85-7b559aa986ad",
"resourceDescLink": "/resources/compute-descriptions/1952d1d3-15f0-4574-ae42-4fbf8a87d4cc",
"zone": "Automation / Vms",
"countIndex": "0",
"image": "ubuntu",
"count": "1",
"flavor": "small",
"region": "MYBU",
"_clusterAllocationSize": "1",
"osType": "LINUX",
"componentType": "Cloud.vSphere.Machine",
"account": "bha"
}
},
"status": "CREATE_SUCCESSFUL",
"deploymentURI": "https://api.yourenv.com/automation-ui/#/deployment-ui;ash=/deployment/6a031f92-d0fa-42c8-bc9e-3b260ee2f65b"
}
Tabla 6.
Automatizar tareas de implementación continua: Kubernetes
| Tarea |
Scope |
Key |
Cómo utilizar SCOPE y KEY en la tarea |
| Kubernetes |
|
Input |
action: una instancia de GET, CREATE, APPLY, DELETE, ROLLBACK
timeout: tiempo de espera general para cualquier acción.filterByLabel: etiqueta adicional para filtrar por acción GET mediante K8S labelSelector. GET, CREATE, DELETE, APPLY
yaml: YAML en línea para procesar y enviar a Kubernetes.parameters: par KEY, VALUE; reemplace $$KEY por VALUE en el área de entrada de YAML en línea.filePath: ruta de acceso relativa desde el endpoint de Git de SCM, si se proporciona, desde el que se recupera el YAML.scmConstants: par KEY, VALUE; reemplace $${KEY} por VALUE en el YAML recuperado a través de SCM.continueOnConflict: cuando se establece como true, si ya hay un recurso, la tarea continúa. ROLLBACK
resourceType: tipo de recurso que se revertiráresourceName: nombre del recurso que se revertirá.namespace: espacio de nombres en el que se debe realizar la reversión.revision: revisión a la que se revertirá. |
${MY_STAGE.MY_TASK.input.action} #Determina la acción que se va a realizar.
${MY_STAGE.MY_TASK.input.timeout}
${MY_STAGE.MY_TASK.input.filterByLabel}
${MY_STAGE.MY_TASK.input.yaml}
${MY_STAGE.MY_TASK.input.parameters}
${MY_STAGE.MY_TASK.input.filePath}
${MY_STAGE.MY_TASK.input.scmConstants}
${MY_STAGE.MY_TASK.input.continueOnConflict}
${MY_STAGE.MY_TASK.input.resourceType}
${MY_STAGE.MY_TASK.input.resourceName}
${MY_STAGE.MY_TASK.input.namespace}
${MY_STAGE.MY_TASK.input.revision}
|
|
Output |
response: captura la respuesta completa.
response.<RESOURCE>: el recurso corresponde a configMaps, implementaciones, endpoints, ingresos, trabajos, espacios de nombres, pods, replicaSets, replicationControllers, secretos, servicios, statefulSets, nodos, loadBalancers.
response.<RESOURCE>.<KEY>: la clave corresponde a una instancia de apiVersion, clase, metadatos o especificaciones.
|
${MY_STAGE.MY_TASK.output.response}
${MY_STAGE.MY_TASK.output.response.}
|
Tabla 7.
Integración de aplicaciones de desarrollo, prueba e implementación
| Tarea |
Scope |
Key |
Cómo utilizar SCOPE y KEY en la tarea |
| Bamboo |
|
Input |
plan: Nombre del plan
planKey: Clave del plan
variables: Variables que se transferirán al plan
parameters: Parámetros que se transferirán al plan
|
${MY_STAGE.MY_TASK.input.plan}
${MY_STAGE.MY_TASK.input.planKey}
${MY_STAGE.MY_TASK.input.variables}
${MY_STAGE.MY_TASK.input.parameters} # Haga referencia a todos los parámetros
${MY_STAGE.MY_TASK.input.parameters.param1} # Haga referencia al valor de param1
|
|
Output |
resultUrl: URL de la compilación resultante
buildResultKey: Clave de la compilación resultante
buildNumber: Número de compilación
buildTestSummary: Resumen de las pruebas ejecutadas
successfulTestCount: Resultado de la prueba aprobado
failedTestCount: Resultado de la prueba erróneo
skippedTestCount: Resultado de la prueba omitido
artifacts: artefactos desde la compilación
|
${MY_STAGE.MY_TASK.output.resultUrl}
${MY_STAGE.MY_TASK.output.buildResultKey}
${MY_STAGE.MY_TASK.output.buildNumber}
${MY_STAGE.MY_TASK.output.buildTestSummary} # Haga referencia a todos los resultados
${MY_STAGE.MY_TASK.output.successfulTestCount} # Haga referencia al recuento de pruebas específico
${MY_STAGE.MY_TASK.output.buildNumber}
|
| Jenkins |
|
Input |
job: Nombre del trabajo de Jenkins
parameters: Parámetros que se transferirán al trabajo
|
${MY_STAGE.MY_TASK.input.job}
${MY_STAGE.MY_TASK.input.parameters} # Haga referencia a todos los parámetros
${MY_STAGE.MY_TASK.input.parameters.param1} # Haga referencia al valor de un parámetro
|
|
Output |
job: Nombre del trabajo de Jenkins
jobId: Identificador del trabajo resultante, por ejemplo, 1234
jobStatus: Estado en Jenkins
jobResults: Recopilación de resultados de cobertura de prueba/código
jobUrl: URL de la ejecución del trabajo resultante
|
${MY_STAGE.MY_TASK.output.job}
${MY_STAGE.MY_TASK.output.jobId}
${MY_STAGE.MY_TASK.output.jobStatus}
${MY_STAGE.MY_TASK.output.jobResults} # Haga referencia a todos los resultados
${MY_STAGE.MY_TASK.output.jobResults.junitResponse} # Haga referencia a los resultados de JUnit
${MY_STAGE.MY_TASK.output.jobResults.jacocoRespose} # Haga referencia a los resultados de JaCoCo
${MY_STAGE.MY_TASK.output.jobUrl}
|
| TFS |
|
Input |
projectCollection: Recopilación de proyectos desde TFS
teamProject: Proyecto seleccionado de la recopilación disponible
buildDefinitionId: Identificador de definición de compilación que se va a ejecutar
|
${MY_STAGE.MY_TASK.input.projectCollection}
${MY_STAGE.MY_TASK.input.teamProject}
${MY_STAGE.MY_TASK.input.buildDefinitionId}
|
|
Output |
buildId: Identificador de compilación resultante
buildUrl: URL para visitar el resumen de la compilación
logUrl: URL para visitar los logs
dropLocation: Ubicación de destino de los artefactos si los hubiera
|
${MY_STAGE.MY_TASK.output.buildId}
${MY_STAGE.MY_TASK.output.buildUrl}
${MY_STAGE.MY_TASK.output.logUrl}
${MY_STAGE.MY_TASK.output.dropLocation}
|
| vRO |
|
Input |
workflowId: Identificador del flujo de trabajo que se va a ejecutar
parameters: Parámetros que se transferirán al flujo de trabajo
|
${MY_STAGE.MY_TASK.input.workflowId}
${MY_STAGE.MY_TASK.input.parameters}
|
|
Output |
workflowExecutionId: Identificador de la ejecución del flujo de trabajo
properties: Propiedades de salida de la ejecución del flujo de trabajo
|
${MY_STAGE.MY_TASK.output.workflowExecutionId}
${MY_STAGE.MY_TASK.output.properties}
|
Tabla 8.
Integración de otras aplicaciones a través de una API
| Tarea |
Scope |
Key |
Cómo utilizar SCOPE y KEY en la tarea |
| REST |
|
Input |
url: URL que se va a llamar
action: Método de HTTP por usar
headers: Encabezados de HTTP por transferir
payload: Carga útil de la solicitud
fingerprint: Huella digital que debe coincidir si la URL es HTTPS
allowAllCerts: Cuando se establece en true, puede ser cualquier certificado que tenga una URL HTTPS
|
${MY_STAGE.MY_TASK.input.url}
${MY_STAGE.MY_TASK.input.action}
${MY_STAGE.MY_TASK.input.headers}
${MY_STAGE.MY_TASK.input.payload}
${MY_STAGE.MY_TASK.input.fingerprint}
${MY_STAGE.MY_TASK.input.allowAllCerts}
|
|
Output |
responseCode: Códigos de respuesta HTTP
responseHeaders: Encabezado de respuesta HTTP
responseBody: Formato de cadena de respuesta recibida
responseJson: Respuesta interactiva si el tipo de contenido es application/json
|
${MY_STAGE.MY_TASK.output.responseCode}
${MY_STAGE.MY_TASK.output.responseHeaders}
${MY_STAGE.MY_TASK.output.responseHeaders.header1} # Haga referencia al encabezado de respuesta "header1"
${MY_STAGE.MY_TASK.output.responseBody}
${MY_STAGE.MY_TASK.output.responseJson} # Haga referencia a la respuesta como JSON
${MY_STAGE.MY_TASK.output.responseJson.a.b.c} # Haga referencia a un objeto anidado siguiendo la ruta de acceso de a.b.c JSON en la respuesta
|
| Sondeo |
|
Input |
url: URL que se va a llamar
headers: Encabezados de HTTP por transferir
exitCriteria: Criterios que se deben cumplir para que la tarea se realice correctamente o con errores. Un par clave-valor "correcto" → Expresión, "error" → Expresión
pollCount: Número de iteraciones que se realizarán. Un administrador de Code Stream puede establecer el recuento de sondeos en un máximo de 10.000.
pollIntervalSeconds: Número de segundos de espera entre cada iteración. El intervalo de sondeo debe ser mayor o igual que 60 segundos.
ignoreFailure: Cuando se establece en true, ignora los errores de respuesta intermedios
fingerprint: Huella digital que debe coincidir si la URL es HTTPS
allowAllCerts: Cuando se establece en true, puede ser cualquier certificado que tenga una URL HTTPS
|
${MY_STAGE.MY_TASK.input.url}
${MY_STAGE.MY_TASK.input.headers}
${MY_STAGE.MY_TASK.input.exitCriteria}
${MY_STAGE.MY_TASK.input.pollCount}
${MY_STAGE.MY_TASK.input.pollIntervalSeconds}
${MY_STAGE.MY_TASK.input.ignoreFailure}
${MY_STAGE.MY_TASK.input.fingerprint}
${MY_STAGE.MY_TASK.input.allowAllCerts}
|
|
Output |
responseCode: Códigos de respuesta HTTP
responseBody: Formato de cadena de respuesta recibida
responseJson: Respuesta interactiva si el tipo de contenido es application/json
|
${MY_STAGE.MY_TASK.output.responseCode}
${MY_STAGE.MY_TASK.output.responseBody}
${MY_STAGE.MY_TASK.output.responseJson} # Refer to response as JSON
|
Tabla 9.
Ejecución de scripts remotos y definidos por el usuario
| Tarea |
Scope |
Key |
Cómo utilizar SCOPE y KEY en la tarea |
| PowerShell Para ejecutar una tarea de PowerShell, debe:
|
|
Entrada |
host: Dirección IP o nombre de host de la máquina
username: Nombre de usuario que se usará para la conexión
password: Contraseña que se utilizará para conectarse
useTLS: Intentos de conexión HTTPS
trustCert: Cuando se establece en true, confía en certificados autofirmados
script: Script que se ejecutará
workingDirectory: Ruta de acceso del directorio al que se debe cambiar antes de ejecutar el script
environmentVariables: Un par clave-valor de la variable de entorno que se va a establecer
arguments: Argumentos para transferir al script
|
${MY_STAGE.MY_TASK.input.host}
${MY_STAGE.MY_TASK.input.username}
${MY_STAGE.MY_TASK.input.password}
${MY_STAGE.MY_TASK.input.useTLS}
${MY_STAGE.MY_TASK.input.trustCert}
${MY_STAGE.MY_TASK.input.script}
${MY_STAGE.MY_TASK.input.workingDirectory}
${MY_STAGE.MY_TASK.input.environmentVariables}
${MY_STAGE.MY_TASK.input.arguments}
|
|
Salida |
response: Contenido del archivo $SCRIPT _RESPONSE_FILE
responseFilePath: Valor de $SCRIPT _RESPONSE_FILE
exitCode: Procesar código de salida
logFilePath: Ruta de acceso al archivo que contiene stdout
errorFilePath: Ruta de acceso al archivo que contiene stderr
|
${MY_STAGE.MY_TASK.output.response}
${MY_STAGE.MY_TASK.output.responseFilePath}
${MY_STAGE.MY_TASK.output.exitCode}
${MY_STAGE.MY_TASK.output.logFilePath}
${MY_STAGE.MY_TASK.output.errorFilePath}
|
| SSH |
|
Input |
host: Dirección IP o nombre de host de la máquina
username: Nombre de usuario que se usará para la conexión
password: Contraseña que se utilizará para conectarse (de manera opcional, puede utilizar privateKey)
privateKey: instancia de privateKey que se utilizará para conectarse
passphrase: Frase de contraseña opcional para desbloquear la instancia de privateKey
script: Script que se ejecutará
workingDirectory: Ruta de acceso del directorio al que se debe cambiar antes de ejecutar el script
environmentVariables: Par clave-valor de la variable de entorno que se va a establecer
|
${MY_STAGE.MY_TASK.input.host}
${MY_STAGE.MY_TASK.input.username}
${MY_STAGE.MY_TASK.input.password}
${MY_STAGE.MY_TASK.input.privateKey}
${MY_STAGE.MY_TASK.input.passphrase}
${MY_STAGE.MY_TASK.input.script}
${MY_STAGE.MY_TASK.input.workingDirectory}
${MY_STAGE.MY_TASK.input.environmentVariables}
|
|
Output |
response: Contenido del archivo $SCRIPT _RESPONSE_FILE
responseFilePath: Valor de $SCRIPT _RESPONSE_FILE
exitCode: Procesar código de salida
logFilePath: Ruta de acceso al archivo que contiene stdout
errorFilePath: Ruta de acceso al archivo que contiene stderr
|
${MY_STAGE.MY_TASK.output.response}
${MY_STAGE.MY_TASK.output.responseFilePath}
${MY_STAGE.MY_TASK.output.exitCode}
${MY_STAGE.MY_TASK.output.logFilePath}
${MY_STAGE.MY_TASK.output.errorFilePath}
|
Cómo usar un enlace de variables entre tareas
Este ejemplo muestra cómo utilizar enlaces de variables en las tareas de la canalización.
Tabla 10.
Formatos de sintaxis de ejemplo
| Ejemplo |
Sintaxis |
| Para utilizar un valor de salida de la tarea para las notificaciones de canalización y las propiedades de salida de la canalización |
${<Stage Key>.<Task Key>.output.<Task output key>} |
| Para hacer referencia al valor de salida de la tarea anterior como entrada para la tarea actual |
${<Previous/Current Stage key>.<Previous task key not in current Task group>.output.<task output key>} |
Más información
Para obtener más información sobre el enlace de variables en las tareas, consulte:










