









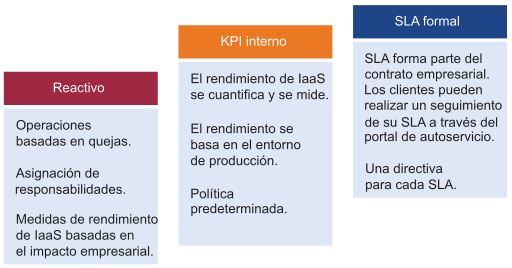
El rendimiento se encarga de garantizar que las cargas de trabajo obtienen los recursos necesarios. Los indicadores clave de rendimiento (KPI) pueden utilizarse para identificar problemas de rendimiento relacionados con las cargas de trabajo. Utilice estos KPI para definir los SLA asociados a los niveles de servicio. Estos paneles de control usan un KPI para mostrar el rendimiento de las cargas de trabajo en la capa de consumidor y el rendimiento total de las cargas de trabajo en la capa de proveedor.
El SLA es el contrato empresarial formal que se establece con los clientes. Por lo general, el SLA se establece entre el proveedor de la IaaS (el equipo de infraestructura) y el cliente de IaaS (el equipo de aplicación o la unidad de negocio). El SLA formal necesita una transformación operativa, por ejemplo, requiere más que cambios técnicos y es posible que necesite consultar el contrato, el precio (no el coste), el proceso y los empleados. El KPI cubre las métricas de SLA y las métricas adicionales que proporcionan una advertencia temprana. Si no tiene un SLA, empiece por un KPI interno. Debe comprender y perfilar el rendimiento real de su IaaS. Utilice la configuración predeterminada de vRealize Operations si no tiene su propio umbral, ya que esos umbrales se seleccionaron para admitir operaciones proactivas.
Los tres procesos de la administración del rendimiento
- Planificación. Establezca sus objetivos de rendimiento. Cuando se diseña un vSAN, se debe saber cuántos milisegundos de latencia de disco se desea obtener. 10 milisegundos medidos a nivel de máquina virtual (no al nivel de vSAN) es un buen comienzo.
- Supervisión. Compare el plan con la realidad. ¿La realidad coincide con el rendimiento que se supone a la arquitectura? Si no es así, esto se debe solucionar.
- Solución de problemas. Cuando la realidad no se adapta a la planificación, se debe implementar una solución de forma proactiva y no esperar problemas ni quejas.
- Contención: este es el indicador principal.
- Configuración: Compruebe las incompatibilidades de versiones.
- Disponibilidad: compruebe si hay errores de software. Tiempo de paralización, bloqueo de vMotion. Esto requiere Log Insight.
- Uso: compruebe esto al final. Si los primeros tres parámetros son correctos, puede omitir este paso.
Las tres capas de la administración del rendimiento
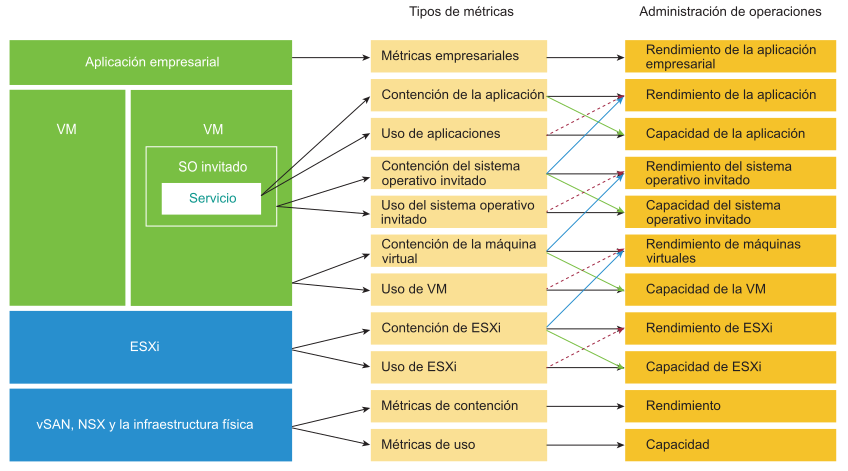
Existen tres dominios principales para aplicaciones empresariales. Cada uno de estos dominios tiene su propio conjunto de equipos. Cada equipo tiene un conjunto de responsabilidades exclusivas y requiere el conjunto de aptitudes asociadas. Los tres dominios comprenden la empresa, la aplicación y la IaaS. Consulte el gráfico que aparece a continuación para conocer las tres capas y las preguntas típicas en cada capa. 
La administración del rendimiento es en gran medida un ejercicio de eliminación. La metodología consiste en desglosar cada capa y determinar si está causando el problema de rendimiento. Por lo tanto, es fundamental tener una sola métrica para indicar si una capa en particular tiene un buen rendimiento o no. Esta métrica principal se denomina justamente Indicador clave de rendimiento (KPI).
La capa superior depende de la capa que se encuentra debajo de ella y, por lo tanto, la capa de infraestructura suele ser la fuente de contención. Como resultado, debe centrarse primero en la capa inferior, ya que esta sirve como base para la capa que está arriba. Lo bueno es que esta capa suele ser una capa horizontal, que proporciona un conjunto de servicios de infraestructura genéricos, independientemente de las aplicaciones empresariales que se estén ejecutando en ella.
Las dos métricas de la administración del rendimiento
El contador principal para el rendimiento es la contención. La mayoría de los usuarios se fijan en el uso, ya que creen que puede haber un problema si el uso es elevado. Ese problema es la contención. La contención se manifiesta en diferentes formas tales como colas, latencia, descartes, cancelaciones y cambios de contexto.
Sin embargo, no se deben confundir los indicadores de utilización ultra alta como un problema de rendimiento. Si el host ESXi experimenta un aumento, una compresión y un intercambio, no significa que la máquina virtual tenga un problema de rendimiento. El rendimiento del host se mide según la eficacia del servicio que ofrece a sus máquinas virtuales. A pesar de que el rendimiento se relaciona con el uso de hosts ESXi, la métrica de rendimiento no se basa en el uso, sino que se basa en las métricas de contención.
| Falta de configuración | Configuración del sistema operativo invitado y la máquina virtual |
|---|---|
Ajustes de ESXi
|
Máquina virtual: limitar, compartir y reserva
|
Red
|
Tamaño: efecto NUMA. Máquina virtual que abarca nodos NUMA. |
Ajustes del clúster
|
Instantánea. E/S tiene dos veces más procesos. Controladores de máquinas virtuales. |
vSAN
|
Ping pong de procesos, procesos "runaway" y cola del nivel del sistema operativo de Windows o Linux. |
Desde el punto de vista de administración del rendimiento, el clúster de vSphere es el bloque de creación lógico más pequeño de los recursos. A pesar de que el grupo de recursos y la afinidad de host de máquina virtual pueden proporcionar una unidad de menor tamaño, son operaciones complejas y no pueden ofrecer la calidad prometida de servicio de la IaaS. El grupo de recursos no puede proporcionar una clase de servicio diferenciada. Por ejemplo, su SLA establece que Gold es dos veces más rápido que Silver, ya que se carga a un ritmo 200 % superior. El grupo de recursos puede conceder a Gold dos veces más recursos compartidos. No se puede determinar de primeras si esos recursos compartidos adicionales se traducen en la mitad de la preparación de la CPU.
Rendimiento de máquinas virtuales

Los contadores de KPI pueden contener aspectos demasiado técnicos para algunos usuarios, por lo que vRealize Operations incluye una línea de inicio a modo de introducción. Puede ajustar el umbral después de generar un perfil para su entorno. Esta creación de perfiles es un buen ejercicio, ya que la mayoría de los clientes no tienen una línea base. La creación de perfiles requiere una edición avanzada.
Métricas de rendimiento
| IaaS | Contador de máquinas virtuales | Umbral |
|---|---|---|
| CPU | Preparado | 2,5 % |
| RAM | Contención | 1% |
| Disco | Latencia | 10 ms |
| Red | Paquete descartado de TX | 0 |
La tabla es un ejemplo de un umbral riguroso. Se utiliza un estándar alto para el rendimiento, ya que es un KPI interno para el consumo del equipo de infraestructura. No es un SLA formal externo que se confirma con los clientes. Debe haber un búfer entre el KPI interno y el SLA externo, de modo que el equipo de operaciones reciba advertencias tempranas y tenga tiempo para reaccionar antes de que se infrinja el SLA externo. Un estándar alto también es crucial para el entorno de desarrollo. Si el estándar se establece en el entorno con menor rendimiento, no se puede aplicar al desarrollo más crítico.
Se utiliza un umbral único para que las operaciones sean simples. Esto significa que se espera que el rendimiento de producción tenga una puntuación más alta que el entorno de desarrollo. Se espera que el rendimiento del entorno de desarrollo sea peor que el del entorno de producción, mientras que todo lo demás debe ser igual. Un umbral único ayuda a explicar la diferencia de calidad de servicio (Quality of Service, QoS) proporcionada por una clase de servicio diferente. Por ejemplo, si paga menos, obtiene un bajo rendimiento y, si paga la mitad del precio, podrá obtener la mitad del rendimiento.
Los cuatro elementos de IaaS (CPU, RAM, disco y red) que se mencionan en la tabla se evalúan en cada ciclo de recopilación. El tiempo de recopilación se establece en cinco minutos, ya que es un equilibrio adecuado para la supervisión. Si el SLA se basa en un minuto, es demasiado ajustado y se produce un aumento del coste o una reducción del umbral.
Consideraciones de diseño
Todos los paneles de control de rendimiento comparten los mismos principios de diseño. Se diseñan a propósito para que sean similares, ya que resulta confuso si cada panel de control tiene un aspecto diferente a otros teniendo en cuenta que tienen el mismo objetivo.
Los paneles de control están diseñados con dos secciones distintas: resumen y detalle.
- Por lo general, la sección de resumen se encuentra en la parte superior del panel de control para proporcionar una perspectiva general.
- La sección de detalles se encuentra debajo de la sección de resumen. Le permite profundizar en un objeto específico. Por ejemplo, puede obtener el informe de rendimiento detallado de cualquier máquina virtual específica.
En la sección detalles, utilice el cambio de contexto rápido para comprobar el rendimiento de varios objetos durante la solución de problemas de rendimiento. Por ejemplo, si está analizando el rendimiento de la máquina virtual, puede ver la información específica de la máquina virtual y los KPI sin cambiar de pantalla. Puede mover de una máquina virtual a otra y ver los detalles sin abrir varias ventanas.
El panel de control utiliza una visualización progresiva para minimizar la sobrecarga de información y garantizar que la página web se cargue rápidamente. Además, si la sesión del explorador permanece abierta, la interfaz recuerda las últimas selecciones.
Muchos de los paneles de control de rendimiento y capacidad comparten un diseño similar, ya que existen unas características comunes entre estos pilares de operaciones.
