









Con la introducción de la disponibilidad continua en vRealize Operations 8, hemos recibido un gran número de preguntas frecuentes. Esta sección pretende ayudarle a mejorar sus conocimientos y percepción sobre la disponibilidad continua.
- ¿Cómo se almacenan los datos en los nodos de análisis?
-
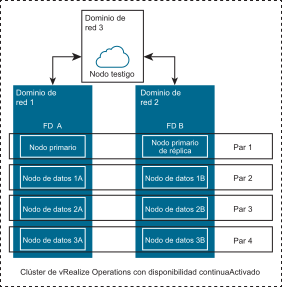
Al detectar un objeto, vRealize Operations determina en qué nodo se deben conservar los datos y, a continuación, copia (duplica) los datos en el par de nodos del otro dominio de errores. Cada objeto se almacena en dos nodos de análisis (pares de nodos) en los dominios de errores y siempre están sincronizados.
Por ejemplo, vRealize Operations cuenta con ocho nodos de análisis, la disponibilidad continua (CA) se encuentra activada y, como resultado, cada dominio de errores tiene cuatro nodos de análisis (consulte el diagrama anterior).
Cuando se detecta un nuevo objeto, vRealize Operations decide almacenar los datos en el "Nodo de datos 2B" (principales), guardando automáticamente una copia de los datos en el "Nodo de datos 2A" (secundarios).
En el caso de que "FD A" deje de estar disponible, se utilizarán los datos "principales" del "Nodo de datos 2B".
En el caso de que "FD B" deje de estar disponible, se utilizarán los datos "secundarios" del "Nodo de datos 2A".
- ¿Qué situaciones interrumpen un clúster de disponibilidad continua? No se admite la pérdida simultánea del nodo primario o del nodo de réplica primario y los nodos de datos, o dos o más nodos de datos en ambos dominios de errores.
-
Cada nodo de análisis procedente del dominio de errores 1 tiene su par de nodos en el dominio de errores 2 o viceversa.
Según el ejemplo mencionado anteriormente, contamos con cuatro pares de nodos:
Nodo primario + réplica
Nodo de datos 1A (FD A) + Nodo de datos 1B (FD B)
Nodo de datos 2A (FD A) + Nodo de datos 2B (FD B)
Nodo de datos 3A (FD A) + Nodo de datos 3B (FD B)
Los dos nodos de cada par de nodos siempre están sincronizados y almacenan además los mismos datos. Por lo tanto, el clúster continuará funcionando sin pérdida de datos mientras esté disponible un nodo procedente de todos los pares de nodos.
- ¿Qué sucede si un nodo de datos de uno de los dominios de errores deja de estar disponible?
- El clúster estará en estado degradado, pero seguirá funcionando cuando un nodo deje de estar disponible en cualquiera de los dominios de errores. No se perderán los datos. El nodo de datos debe repararse o reemplazarse de modo que el clúster no permanezca en un estado degradado.
- ¿Se interrumpirá el clúster si se pierden dos nodos de datos en el dominio de errores 1 y el nodo de réplica primario en el dominio de errores 2?
- En este ejemplo, el clúster seguirá funcionando sin ningún tipo de pérdida de datos. Si sigue estando disponible un nodo de análisis de cada par de nodos, no habrá pérdida de datos.
- ¿Qué sucede si un dominio de errores completo deja de estar disponible?
-
El clúster continuará en estado degradado, pero seguirá funcionando cuando un dominio de errores completo deje de estar disponible. No se perderán los datos. El dominio de errores debe repararse o bien conectarse de modo que el clúster no permanezca en un estado degradado.
No se puede recuperar el dominio de errores, ya que es posible reemplazar el dominio de errores completo por los nodos recién implementados. Desde la IU del administrador, solo se puede reemplazar el nodo de réplica primario. Si se pierde el dominio de errores completo del nodo primario, deberá esperar hasta que se produzca la conmutación por error del nodo primario y el nodo de réplica primario se haya promocionado como el nuevo nodo primario.
- ¿Cuál es el proceso adecuado para volver a agregar un nodo con errores en un dominio de errores? ¿Cuánto tiempo se tardará en sincronizar?
- El procedimiento recomendado para volver a agregar un nodo con errores consiste en utilizar la función "Reemplazar nodos de clúster" en la IU del administrador. Una vez que se haya agregado el nodo de sustitución, se sincronizarán los datos. El tiempo de sincronización depende en gran medida del recuento de objetos, del periodo histórico de los objetos, del ancho de banda de red y de la carga en el clúster.
- ¿Qué sucede cuando la latencia de red entre dominios de errores supera los 20 ms? ¿Cuánto tiempo puede vRealize Operations tolerar la latencia extendida?
- Es necesario cumplir los requisitos de latencia para lograr un rendimiento óptimo. La latencia entre dominios de errores debe ser < 10 ms, con picos de hasta los 20 ms durante intervalos de 20 segundos. Para obtener más información acerca de las instrucciones de latencia de red, consulte el artículo de la base de conocimientos Instrucciones de tamaño de vRealize Operations Manager (KB 2093783).
- Cuando la latencia de red entre dominios de errores supera los "20 ms durante intervalos de 20 segundos" durante un intervalo de tiempo, pero, a continuación, vuelve a establecerse en menos de 10 ms, ¿cuánto tiempo tarda en volver a sincronizarse?
- Una latencia alta no significa que la sincronización se haya detenido. Cuando se detecta un objeto, vRealize Operations decide qué nodo debe conservar los datos (principales) y, a continuación, una segunda copia de los datos irá a su par de nodos (secundarios). Cada objeto se almacena en dos nodos de análisis (pares) entre ambos dominios de error. La sincronización es un proceso en curso en el que el nodo secundario se sincroniza periódicamente con el nodo principal. La sincronización se realiza en función de las marcas de tiempo de la última sincronización de los nodos principal y secundario. Por lo tanto, no hay ninguna cola de datos de sincronización en vRealize Operations.
- ¿Cuál es la tolerancia del nodo testigo real en cuanto a los sondeos omitidos?
- Las operaciones del nodo testigo no se basan en un sondeo. El nodo testigo interactúa solo cuando uno de los nodos no puede comunicarse (después de varias comprobaciones) con los nodos del otro dominio de errores.
- ¿En qué momento específico se realizará la conmutación por error del nodo primario y del nodo de réplica primario?
- La conmutación por error se produce solo cuando ya no se puede acceder al nodo primario o si este no está activo.
- ¿Cuándo puede promocionar el nodo de réplica primario al nodo primario?
-
El nodo de réplica primario puede promocionarse al nodo primario en solo dos casos:
- Cuando el nodo primario existente está inactivo.
- El dominio de errores asociado está inactivo o sin conexión.
- Cuando el nodo primario original vuelve a estar conectado, ¿reanudará el control primario? ¿Cómo se sincronizan los datos?
- Cuando las operaciones regresan a la normalidad, con el nodo primario y el nodo de réplica primario conectados, el nodo primario recién promocionado (antes denominado nodo de réplica primario) sigue siendo el nuevo nodo primario y la nueva réplica maestra (antes, nodo primario) se sincroniza con el nuevo nodo primario.
- ¿Qué sucede si se interrumpe por completo la conectividad entre los dominios de errores, pero se recupera a continuación?
- Si las comunicaciones entre los dominios de errores se interrumpen por completo durante varios minutos, uno de los dominios de errores se quedará sin conexión automáticamente. Una vez recuperada la interrupción de la red, el usuario administrador debe conectar manualmente el dominio de errores, que comenzará a continuación la sincronización de los datos.
- ¿Qué sucede con los dominios de errores cuando el nodo testigo deja de estar disponible?
-
Siempre que ambos dominios de errores estén en buen estado y se comuniquen entre sí, la falta de disponibilidad del nodo testigo no tendrá efecto en el clúster. vRealize Operations continuará funcionando. Si hay un problema de comunicación entre los dominios de errores, podrán producirse tres situaciones:
- El nodo testigo es accesible desde ambos dominios de errores. El testigo desconectará uno de los dominios de errores en función del estado del sitio.
- Solo se podrá acceder al nodo testigo desde un solo dominio de errores. El otro dominio de errores se desconectará automáticamente.
- No se podrá acceder al nodo testigo desde ambos dominios de errores, ya que ambos dominios de errores se desconectarán.
- Cuando el dominio de errores sin conexión vuelve a estar disponible, ¿los dominios de errores sincronizarán todos los datos recopilados durante la interrupción de la comunicación?
- Los datos recopilados se sincronizan inmediatamente una vez que se restaura la conectividad con el dominio de errores y este se sincroniza para capturar todos los datos que faltan.
- ¿Qué sucede cuando un nodo de análisis no puede comunicarse con los nodos de análisis en el otro dominio de errores?
- Si un nodo de análisis no puede comunicarse con todos los nodos del otro dominio de errores, ni con el nodo testigo, se desconectará automáticamente. El usuario administrador deberá volver a conectar todos los nodos o el dominio de errores al completo que quedaron sin conexión automáticamente, una vez se haya comprobado que se han resuelto todos los problemas de comunicación.
- Si el número máximo de nodos de un clúster estándar es de 10 nodos extragrandes, con un máximo de 440 000 objetos, ¿por qué el número máximo de nodos en disponibilidad continua es mayor con 12 nodos extragrandes, que admiten un máximo de 2 640 000 objetos?
- Los 12 nodos extragrandes solo son compatibles en un clúster de disponibilidad continua y haciendo referencia a un máximo de seis nodos extragrandes en dos dominios de errores independientes. Esto permite un aumento del número de nodos a través de un clúster estándar y permite la recopilación de una mayor cantidad de objetos.
- ¿Es compatible un equilibrador de carga con la disponibilidad continua?
- Sí, para obtener más información sobre la configuración del equilibrador de carga, consulte la Guía de configuración del equilibrio de carga de vRealize Operations, disponible en Recursos en la página de documentación de vRealize Operations Manager.
- La documentación indica que "Cuando se activa la CA, el nodo de réplica puede asumir todas las funciones que proporciona el nodo primario, en caso de que se produzca un fallo en el nodo primario. La conmutación por error a la réplica es automática y solo requiere de dos a tres minutos de periodo de inactividad de vRealize Operations para reanudar las operaciones y reiniciar la recopilación de datos".
- Durante las pruebas, al desconectar la interfaz de red en el nodo primario, el cambio al nuevo nodo primario funcionaba durante 5 minutos, el usuario era expulsado de la IU del producto o bien se producían errores extraños.
- Los dos o tres minutos indicados son valores medios aproximados, por lo que es aceptable un valor de 5 minutos.
- Cuando el nodo primario se conecta a la red de nuevo después de una conmutación por error, ¿cuál es el procedimiento recomendado para devolver el nodo primario original a la función primaria?
- No es necesario revertir el nodo de réplica primario a la función del nodo primario ni viceversa. Si aún así desea restaurar el nodo primario anterior a la función primaria, use "Desconectar/conectar nodo" en el nuevo nodo primario o en su dominio de errores (donde se encuentre el nodo primario original)
- Cada vez que un nodo se desconecta o se reinicia, es necesario desconectar el dominio de errores correspondiente y volver a conectar para que el nodo vuelva a estar conectado.
- Todos los nodos, después de reiniciarse o desconectarse/conectarse, continuarán funcionando automáticamente. No es necesario realizar ningún paso adicional.
