Pour garantir des performances optimales, il est nécessaire que les charges de travail obtiennent les ressources nécessaires. Ainsi, la gestion des performances est principalement un exercice de suppression. La méthodologie consiste à séparer chaque couche et à déterminer si une couche particulière génère des problèmes de performances. Il est impératif de disposer d'une mesure unique pour indiquer si une couche particulière est performante ou non. Cette mesure principale est justement appelée un indicateur de performance clé (KPI, Key Performance Indicator).
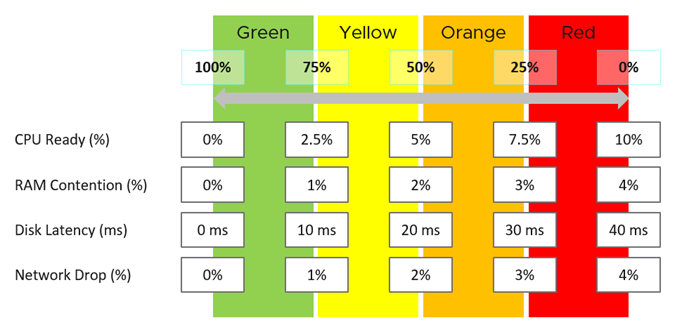
Chaque mesure, telle que la latence de disque, possède quatre plages : vert, jaune, orange et rouge.
Pour en faciliter la surveillance, chaque plage est mappée de 0 à 100 %. Le vert est mappé aux valeurs comprises entre 75 et 100 %, et le rouge aux valeurs comprises entre 0 et 25 %. La division de 100 % en quatre plages égales permet à chaque plage d'avoir une étendue correcte.
La technique ci-dessus permet de combiner des mesures ayant différentes unités. Chacune d'entre elles est mappée à la même étendue, qui correspond à un pourcentage.
La logique pour mapper correctement une mesure à quatre plages nécessite cinq mesures et non quatre. Par exemple, pour la latence de disque :
-
Si celle-ci est de 41 ms, elle correspond à 0 % (rouge), car la limite supérieure du rouge est de 40 ms.
-
Si celle-ci est de 35 ms, elle correspond à 12,5 %, car elle se situe entre 30 ms et 40 ms, et donc dans le rouge.
-
Si celle-ci est de 30 ms, elle correspond à 25 % et se situe ainsi à la limite entre rouge et orange.
Une fois chaque mesure convertie en une plage comprise entre 0 et 100 %, la valeur moyenne, pas la valeur maximale, est utilisée pour déterminer la mesure du KPI. La moyenne est utilisée pour éviter qu'une mesure puisse dominer la valeur du KPI. Si une mesure est essentielle pour vos opérations, vous pouvez utiliser des alertes pour cette mesure. L'utilisation d'une moyenne reflète la réalité, car chaque mesure est comptabilisée de la même manière.
Ces tableaux de bord utilisent des KPI pour afficher les performances des sessions Horizon au niveau de la couche consommateur et les performances agrégées des charges de travail au niveau de la couche d'infrastructure Horizon. Ils sont conçus pour l'architecte ou l'administrateur principal Horizon et fournissent un aperçu des performances globales de la partie centre de données du poste de travail en tant que service.
Gestion des performances dans Horizon
Pour la surveillance et le dépannage des performances, Horizon est semblable à une architecture client/serveur, dans laquelle le client se trouve sur le réseau WAN. Les composants de réseau et de centre de données sont indépendants les uns des autres. Ils utilisent différents ensembles de mesures et doivent être surveillés en tant qu'entité propre. Ils disposent de leur propre ensemble d'actions de correction. Dans les grandes entreprises, le réseau est géré par une équipe distincte.
Management Pack for Horizon surveille, puis fournit des KPI de manière séparée.

Le composant client est le dernier objet de la surveillance des performances, car il fonctionne principalement comme une télévision. Il affiche les pixels transmis et accepte une entrée simple. En outre, un problème avec un client a tendance à être isolé. Cependant, une panne de réseau et de centre de données peut affecter de nombreux utilisateurs.
Trois processus de dépannage des performances
Les trois processus distincts de la gestion des performances sont les suivants :
-
Planification. C'est à cette étape que vous définissez les objectifs de performance. Lorsque vous créez ce vSAN, combien de millisecondes de latence de disque envisagez-vous ? 10 ms mesurées au niveau de la machine virtuelle (pas au niveau du vSAN) est un bon début.
-
Surveillance. C'est à cette étape que vous comparez la planification à la situation réelle. La réalité correspond-elle à ce que votre architecture est censée fournir ? Si ce n'est pas le cas, vous devez la modifier.
-
Dépannage. Effectuez cette étape lorsque la réalité est pire que la planification, pas en cas de réclamation. Vous ne voulez pas consacrer du temps au dépannage, c'est pourquoi il est recommandé de l'effectuer de manière proactive.

Deux mesures de gestion des performances
Le compteur principal pour mesurer les performances est la contention. La plupart des clients examinent l'utilisation, car ils craignent qu'un problème survienne si celle-ci est élevée. Ce problème est une contention. La contention se manifeste sous différentes formes. Il peut s'agir d'une file d'attente, d'une latence, d'un abandon, d'une interruption ou d'un changement de contexte.
Ne pensez pas que des indicateurs d'utilisation très élevés signifient un problème de performances. Si un hôte ESXi subit un gonflage, une compression et un échange, cela ne signifie pas que votre machine virtuelle présente un problème de performances de mémoire. Mesurez les performances de l'hôte en fonction de son efficacité par rapport à ses machines virtuelles. Bien qu'elle soit liée à l'utilisation d'ESXi, la mesure des performances n'est pas basée sur l'utilisation. Elle est basée sur les mesures de contention.
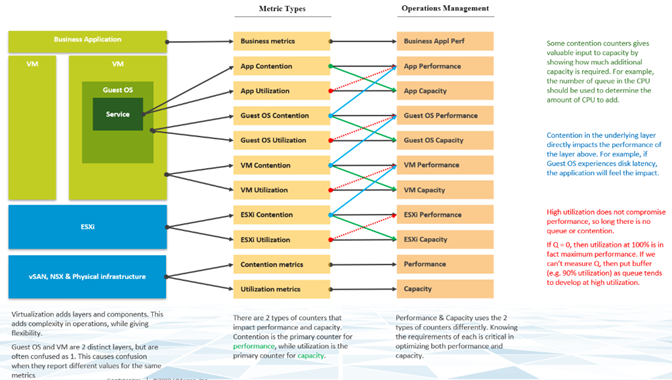
Il est possible que les machines virtuelles du cluster souffrent de faibles performances, alors que l'utilisation du cluster est faible. Une des raisons principales de cette situation est que l'utilisation du cluster examine la couche de fournisseur (ESXi), tandis que les performances s'intéressent à un consommateur individuel (machine virtuelle).

Du point de vue de la gestion des performances, le cluster vSphere est le plus petit bloc de construction logique des ressources. Bien que le pool de ressources et l'affinité de l'hôte de machine virtuelle puissent fournir un plus petit bloc, ils sont complexes d'un point de vue opérationnel et ne peuvent pas fournir la qualité prévue de service IaaS. Le pool de ressources ne peut pas fournir une classe de service différenciée. Par exemple, votre SLA stipule que le poste de travail premium est deux fois plus rapide que le poste de travail normal, puisqu'il est facturé à 200 %. Le pool de ressources peut donner deux fois plus de partages au poste de travail premium. Il est impossible de déterminer d'avance les parts supplémentaires correspondant à la moitié de la disponibilité du CPU.
Profondeur et ampleur
La surveillance proactive requiert des analyses à angles multiples. Si le problème rencontré par un utilisateur est causé par un souci de performances, vos prochaines questions sont les suivantes :
-
Est-ce grave ? Vous souhaitez évaluer la profondeur du problème.
-
Combien d'utilisateurs sont affectés ? Vous souhaitez évaluer l'ampleur du problème.
La réponse à la deuxième question affecte le dépannage. L'incident est-il isolé ou très répandu ? S'il est isolé, vous examinez l'objet concerné plus attentivement. S'il s'agit d'un problème généralisé, vous examinez les zones communes (telles que les clusters, les banques de données, les pools de ressources et les hôtes) qui sont partagées avec l'objet concerné.
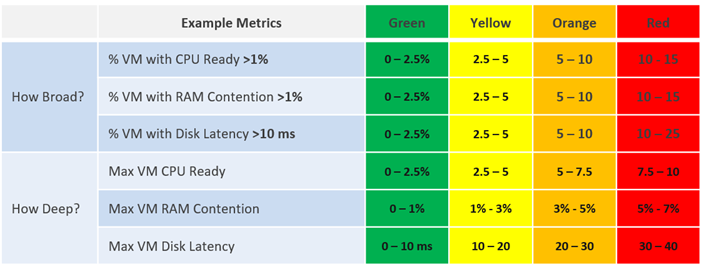
Notez que vous n'avez pas demandé à quoi correspondent les performances moyennes ? En effet, la moyenne ne sert plus à rien dans ce cas. Lorsque les performances moyennes sont incorrectes, la moitié de la population est déjà vraisemblablement affectée.
Count() fonctionne mieux que Percentage() lorsque le nombre de membres est important. Par exemple, dans un environnement VDI à 100 000 utilisateurs, cinq utilisateurs affectés correspondent à 0,005 %. Il est plus facile d'effectuer la surveillance en se basant sur un nombre, car il se traduit dans la réalité.
Flux globaux
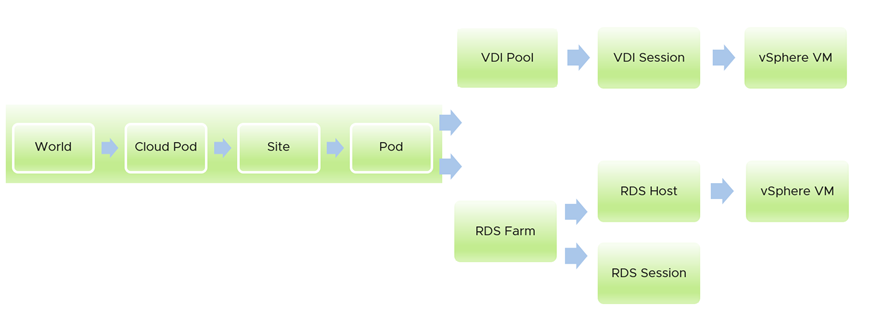
Les tableaux de bord Management Pack for Horizon ne sont pas conçus pour fonctionner de manière isolée. Ils forment un flux, en transmettant un contexte lorsque vous descendez dans la hiérarchie. L'exemple suivant montre comment vous pouvez descendre dans la hiérarchie depuis une vue de haut niveau vers la machine virtuelle sous-jacente prenant en charge une session. Le premier tableau de bord couvre tous les espaces dans le monde d'Horizon. À partir de celui-ci, vous pouvez descendre dans la hiérarchie vers une batterie de serveurs RDS ou un pool VDI. Dans chaque branche, vous pouvez descendre dans la hiérarchie vers la session individuelle.
Considérations relatives à la conception
Tous les tableaux de bord de performances partagent les mêmes principes de conception. Ils sont conçus intentionnellement pour avoir une apparence semblable, car cela pourrait être source de confusion si tous les tableaux de bord avaient une apparence différente. Les tableaux de bord poursuivent le même objectif.
Un tableau de bord est conçu de haut en bas avec les sections Résumé et Détail.
-
La section Résumé est généralement située en haut du tableau de bord. Elle offre une vision globale.
-
La section Détail est placée sous la section Résumé. Elle vous permet d'explorer un objet spécifique. Par exemple, s'il s'agit des performances de machine virtuelle, vous pouvez obtenir les performances détaillées d'une machine virtuelle spécifique.
Cette section Détail est également conçue avec un commutateur de contexte rapide, car vous pouvez vérifier les performances de plusieurs objets lors du dépannage des performances. Par exemple, le tableau de bord Performance des hôtes RDS vous fournit toutes les informations spécifiques de l'hôte RDS et vous permet de consulter les KPI sans changer d'écran. Vous pouvez également passer d'un hôte RDS à un autre et afficher les détails sans ouvrir plusieurs fenêtres.
Depuis l'interface utilisateur, le tableau de bord utilise la diffusion progressive pour réduire la surcharge d'information et garantir un chargement rapide de la page Web. Tant que votre session de navigateur reste active, votre dernière sélection reste en mémoire.
Signification des couleurs
Le tableau de bord utilise la couleur pour indiquer que différents seuils sont utilisés.
| Compteur | Seuil utilisé |
|---|---|
| KPI | Vert : de 75 % à 100 % Jaune : de 50 % à 75 % Orange : de 25 % à 50 % Rouge : de 0 % à 25 % En conséquence, les ensembles de seuils sont 25 %, 50 % et 75 %. |
| Nombre d'éléments dans le rouge. Par exemple, le nombre de sessions VDI avec un KPI rouge. |
Celui-ci doit être en permanence égal à 0, car il ne doit pas y avoir de sessions VDI avec une valeur de KPI située dans la plage rouge. Par conséquent, les ensembles de seuils sont 1, 2 et 3. Si vous souhaitez que le rouge s'affiche lorsque le nombre est égal à 1, vous pouvez le définir les ensembles de seuils sur 0,1, 0,2 ou 1. |
Les nombres affichés doivent se trouver dans la zone verte (de 75 % à 100 %). La valeur moyenne ne peut pas être de 100 %, mais elle doit se situer dans la plage verte.
Analyse avec un tableau
Un tableau est simplement une liste, où chaque ligne représente un objet et chaque colonne affiche une valeur unique. Cette option permet de répertorier des centaines de lignes, avec la possibilité de filtrer et de trier. Chaque valeur de cellule peut également avoir un code couleur.
Le tableau est adapté si vous recherchez plus de détails. Cependant, en résumé, son principal problème est de pouvoir donner une analyse dans la durée, car chaque cellule ne peut contenir qu'une seule valeur. Comment donner une analyse de ce qui est arrivé dans le passé ? Par exemple, comment afficher les performances au cours de la dernière semaine ? Il existe des milliers de points de données au cours des sept derniers jours, lesquels choisir ?
Il existe quelques options possibles dans vRealize Operations Cloud 8.2 :
-
Le nombre actuel. Il est utile pour indiquer la situation actuelle. Toutefois, cette valeur ne reflète pas ce qui s'est produit il y a cinq minutes.
-
La moyenne de la période. La moyenne est un indicateur tardif. Au moment où la moyenne devient mauvaise, 50 % de la population est déjà en mauvaise situation.
-
La plus mauvaise valeur de la période. Cet indicateur peut être trop extrême, car il ne s'agit que d'un pic. Dans certains cas, un simple nombre parmi des centaines de points de données peut être considéré comme hors-norme. Il est utile pour la détection de pics, mais il doit être complété.
-
Le 95e centile. Il s'agit d'un point médian entre la moyenne et la plus mauvaise valeur. Pour la surveillance des performances, le 95e centile est un meilleur résumé que la moyenne.
Utilisez conjointement la plus mauvaise valeur et le 95e centile, en commençant par le 95e centile. Si les nombres sont éloignés, cela signifie que la plus mauvaise valeur est vraisemblablement hors-norme.
Pour une meilleure visibilité, envisagez d'ajouter le 98e centile en complément du 95e centile et de la pire valeur.
Analyse avec un graphique à barres
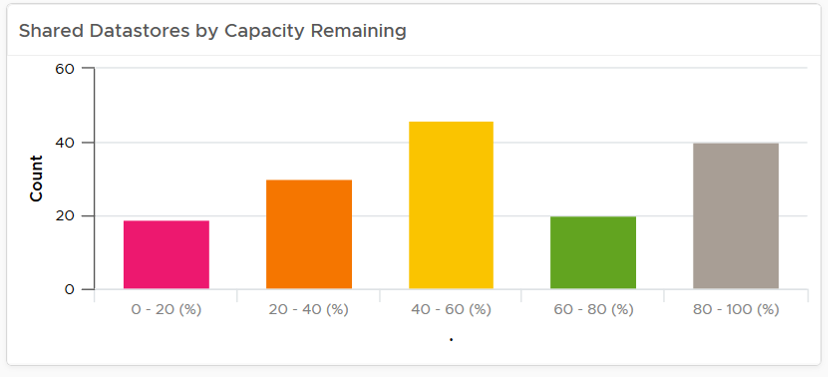
Il existe de nombreuses formes de graphiques de distribution, mais le graphique à barres est la forme la plus répandue. Il peut être utilisé pour fournir des informations sur un grand ensemble de données. Par exemple, les banques de données partagées vSphere sont affichées selon leur capacité restante. Elles sont classées en cinq compartiments, de la capacité restante la plus faible à la plus élevée. Chaque compartiment obtient une couleur pour indiquer une signification. Une capacité supérieure à 80 % obtient une couleur grise, car une grande quantité de capacité inutilisée indique un gaspillage de ressources.