









Pour créer un pipeline d'intégration continue et de livraison continue (CICD) dans Automation Pipelines, vous pouvez utiliser le modèle de pipeline intelligent CICD. Pour planifier votre build native CICD, collectez les informations du modèle de pipeline intelligent avant de créer le pipeline dans cet exemple de plan.
Pour créer un pipeline CICD, vous devez planifier les étapes d'intégration continue (Continuous Integration, CI) et de livraison continue (Continuous Delivery, CD) de votre pipeline.
Une fois que vous avez saisi les informations requises dans le modèle de pipeline intelligent et que vous les avez enregistrées, le modèle crée un pipeline comprenant des étapes et des tâches. Il indique également la destination du déploiement de votre image en fonction des types d'environnement que vous sélectionnez, par exemple Dev (Développement) et Prod (Production). Le pipeline publiera votre image de conteneur et effectuera les actions requises pour l'exécuter. Après l'exécution de votre pipeline, vous pouvez surveiller les tendances en matière d'exécution de pipeline.
Lorsqu'un pipeline inclut une image de Docker Hub, vous devez vous assurer que l'image intègre cURL ou wget avant d'exécuter le pipeline. Lorsque le pipeline s'exécute, Automation Pipelines télécharge un fichier binaire qui utilise cURL ou wget pour exécuter des commandes.
Pour plus d'informations sur la configuration de l'espace de travail, consultez Configuration de l'espace de travail de pipeline.
Planification de l'étape d'intégration continue (CI)
Pour planifier l'étape d'intégration continue de votre pipeline, configurez les conditions externes et internes requises, et déterminez les informations requises dans la partie d'intégration continue du modèle de pipeline intelligent. En voici un résumé.
Cet exemple utilise un espace de travail Docker.
Points de terminaison et référentiels dont vous aurez besoin :
- Référentiel de code source dans lequel vos développeurs archivent leur code. Automation Pipelines intègre la toute dernière version du code dans le pipeline lorsque les développeurs valident les modifications.
- Point de terminaison de type de service GitHub-Enterprise, GitLab-Enterprise ou Bitbucket-Enterprise pour le référentiel dans lequel réside le code source du développeur.
- D'un point de terminaison Docker pour l'hôte de la build Docker qui exécutera les commandes de la build dans un conteneur.
- D'un point de terminaison Kubernetes afin que Automation Pipelines puisse déployer votre image sur un cluster Kubernetes.
- D'une image de générateur qui crée le conteneur sur lequel les tests d'intégration continue s'exécutent.
- D'un point de terminaison de registre d'images afin que l'hôte de la build Docker puisse en extraire l'image du générateur.
Vous aurez besoin d'accéder à un projet. Projet qui regroupe tous vos travaux, y compris votre pipeline, vos points de terminaison et vos tableaux de bord. Assurez-vous d'être membre d'un projet dans Automation Pipelines. Si ce n'est pas le cas, demandez à un administrateur de Automation Pipelines de vous ajouter en tant que membre d'un projet. Reportez-vous à la section Ajout d'un projet dans Automation Pipelines.
Vous aurez besoin d'un Webhook Git, ce qui permet à Automation Pipelines d'utiliser le déclencheur Git pour déclencher votre pipeline lorsque les développeurs valident les modifications apportées au code. Reportez-vous à la section Utilisation du déclencheur Git dans Automation Pipelines pour exécuter un pipeline.
Vos boîtes à outils dédiées aux builds :
- Votre type de build, par exemple Maven.
- Tous les outils de génération post-processus que vous utilisez, tels que JUnit, JaCoCo, Checkstyle et FindBugs.
Votre outil de publication :
- Un outil comme docker qui déploiera votre conteneur de builds.
- Une balise d'image, soit l'ID de validation, soit le numéro de build.
Votre espace de travail dédié aux builds :
- Un hôte de build Docker, point de terminaison Docker.
- Un registre d'images. La partie relative à la CI du pipeline extrait l'image du point de terminaison de registre sélectionné. Le conteneur exécute les tâches de CI et déploie votre image. Si le registre requiert des informations d'identification, vous devez créer un point de terminaison de registre d'image, puis le sélectionner ici pour que l'hôte puisse extraire l'image du registre.
- URL de l'image de générateur qui crée le conteneur sur lequel les tâches d'intégration continue s'exécutent.
Planification de l'étape de livraison continue (CD)
Pour planifier l'étape de livraison continue de votre pipeline, configurez les conditions externes et internes requises, et déterminez les informations à saisir dans la partie de livraison continue du modèle de pipeline intelligent.
Points de terminaison dont vous aurez besoin :
- D'un point de terminaison Kubernetes afin que Automation Pipelines puisse déployer votre image sur un cluster Kubernetes.
Types d'environnement et fichiers :
- Tous les types d'environnement dans lesquels Automation Pipelines déploiera votre application, comme Dev (Développement) et Prod (Production). Le modèle de pipeline intelligent crée les étapes et les tâches de votre pipeline en fonction des types d'environnement que vous sélectionnez.
Tableau 1. Étapes de votre pipeline créées par le modèle de pipeline intelligent CICD Contenu du pipeline Fonctionnement Étape de publication de la build Génère et teste votre code, crée l'image de générateur et publie l'image sur votre hôte Docker. Étape de développement Utilise un cluster de développement Amazon Web Services (AWS) pour créer et déployer votre image. À cette étape, vous pouvez créer un espace de noms sur le cluster et créer une clé secrète. Étape de production Utilise une version de production de VMware Tanzu Kubernetes Grid Integrated Edition (anciennement VMware Enterprise PKS) pour déployer votre image sur un cluster Kubernetes de production. - Fichier YAML Kubernetes que vous sélectionnez dans la partie relative à la CD du modèle de pipeline intelligent CICD.
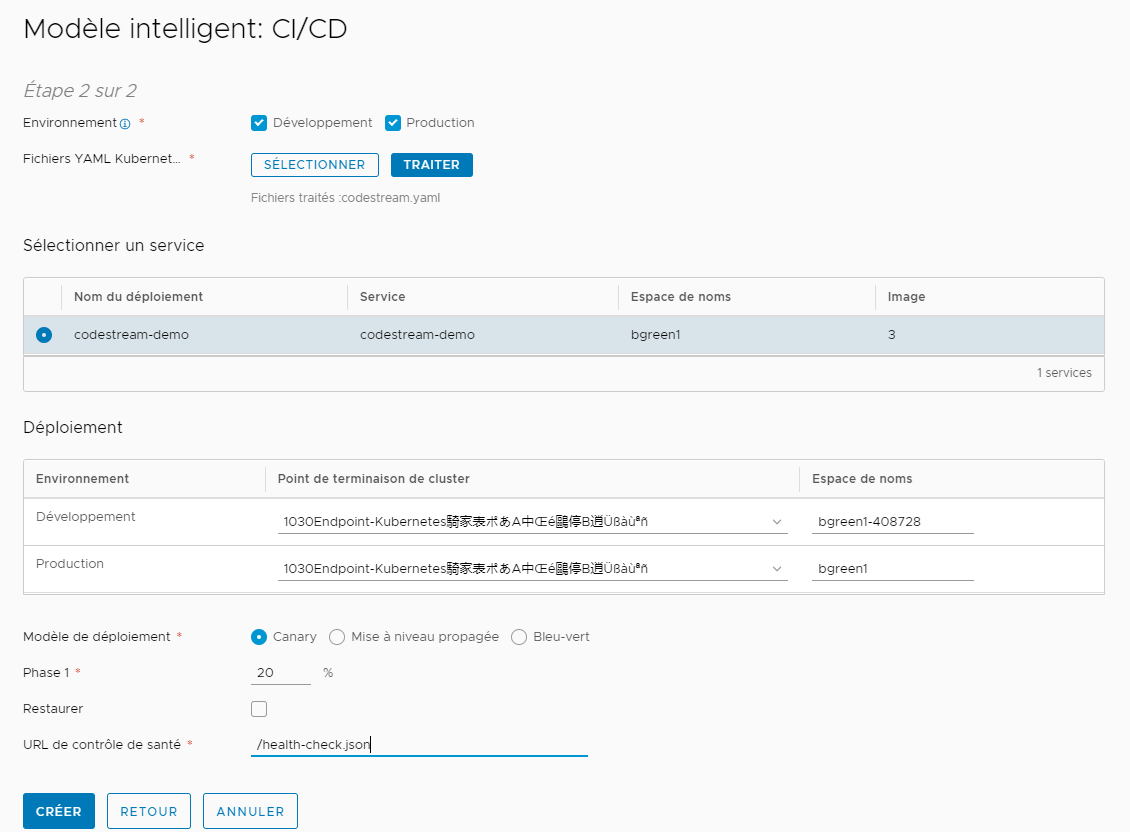
Le fichier YAML Kubernetes comporte trois sections obligatoires pour l'espace de noms, le service et le déploiement, et une section facultative pour le secret. Si vous prévoyez de créer un pipeline en téléchargeant une image à partir d'un référentiel privé, vous devez inclure une section avec le secret de configuration Docker. Si le pipeline que vous créez utilise uniquement des images accessibles publiquement, aucun secret n'est requis. L'exemple de fichier YAML suivant comporte quatre sections.
apiVersion: v1 kind: Namespace metadata: name: pipelines namespace: pipelines --- apiVersion: v1 data: .dockerconfigjson: eyJhdXRocyI6eyJodHRwczovL2luZ1234567890lci5pby92MS8iOnsidXNlcm5hbWUiOiJhdXRvbWF0aW9uYmV0YSIsInBhc3N3b3JkIjoiVk13YXJlQDEyMyIsImVtYWlsIjoiYXV0b21hdGlvbmJldGF1c2VyQGdtYWlsLmNvbSIsImF1dGgiOiJZWFYwYjIxaGRHbHZibUpsZEdFNlZrMTNZWEpsUURFeU13PT0ifX19 kind: Secret metadata: name: dockerhub-secret namespace: pipelines type: kubernetes.io/dockerconfigjson --- apiVersion: v1 kind: Service metadata: name: pipelines-demo namespace: pipelines labels: app: pipelines-demo spec: ports: - port: 80 selector: app: pipelines-demo tier: frontend type: LoadBalancer --- apiVersion: apps/v1 kind: Deployment metadata: name: pipelines-demo namespace: pipelines labels: app: pipelines-demo spec: replicas: 10 selector: matchLabels: app: pipelines-demo tier: frontend template: metadata: labels: app: pipelines-demo tier: frontend spec: containers: - name: pipelines-demo image: automationbeta/pipelines-demo:01 ports: - containerPort: 80 name: pipelines-demo imagePullSecrets: - name: dockerhub-secretNote : Le fichier YAML Kubernetes est également utilisé dans le modèle de pipeline intelligent CD, comme dans les exemples de cas d'utilisation suivants :Pour appliquer le fichier dans le modèle intelligent, cliquez sur Sélectionner et sélectionnez le fichier YAML Kubernetes. Cliquez ensuite sur Traiter. Le modèle de pipeline intelligent affiche les services et les environnements de déploiement disponibles. Vous sélectionnez un service, le point de terminaison du cluster et la stratégie de déploiement. Par exemple, pour utiliser le modèle de déploiement Canary, sélectionnez Canary et entrez le pourcentage de la phase de déploiement.
Pour découvrir un exemple d'utilisation du modèle de pipeline intelligent pour créer un pipeline en vue d'un déploiement Bleu-vert, reportez-vous à la section Déploiement d'une application dans Automation Pipelines vers un déploiement Bleu-vert.
Création du pipeline CICD à l'aide du modèle de pipeline intelligent
Une fois que vous aurez collecté toutes les informations et configuré ce dont vous avez besoin, voici comment vous créerez un pipeline à partir du modèle de pipeline intelligent CICD.
Sur la page Pipelines, sélectionnez .
Sélectionnez le modèle de pipeline intelligent CICD.
Vous allez remplir le modèle et enregistrer le pipeline avec les étapes qu'il crée. Si vous devez apporter des modifications finales, vous pouvez modifier le pipeline et l'enregistrer.
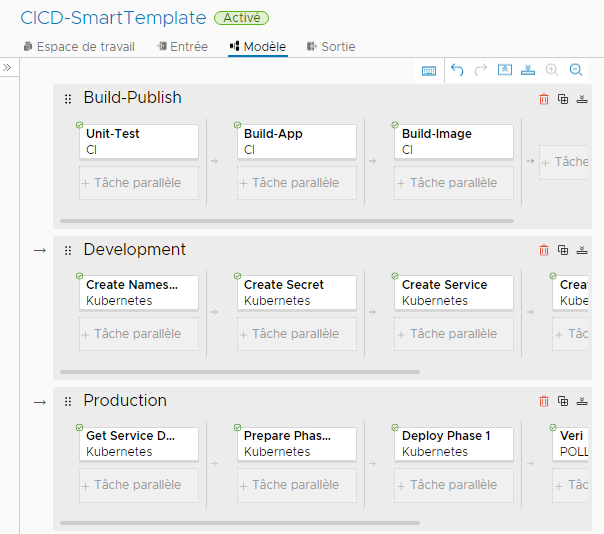
Ensuite, vous allez activer le pipeline et l'exécuter. Une fois le pipeline exécuté, voici quelques éléments que vous pouvez rechercher :
- Vérifiez que votre pipeline a abouti. Cliquez sur Exécutions et recherchez votre pipeline. S'il a échoué, corrigez les erreurs et exécutez-le à nouveau.
- Vérifiez que le Webhook Git fonctionne correctement. L'onglet Activité Git affiche les événements. Cliquez sur .
- Examinez le tableau de bord de pipeline et observez les tendances. Cliquez sur Tableaux de bord et recherchez votre tableau de bord de pipeline. Vous pouvez également créer un tableau de bord personnalisé pour générer des rapports sur des KPI supplémentaires.
Pour obtenir un exemple détaillé, reportez-vous à la section Intégration continue du code d'un référentiel GitHub ou GitLab à un pipeline dans Automation Pipelines.
