









Si votre administrateur de cloud a configuré Private AI Automation Services dans VMware Aria Automation, vous pouvez demander des charges de travail d'IA à l'aide du catalogue Automation Service Broker.
Private AI Automation Services prend en charge deux éléments de catalogue dans Automation Service Broker auxquels les utilisateurs disposant des autorisations respectives peuvent accéder et qu'ils peuvent demander.
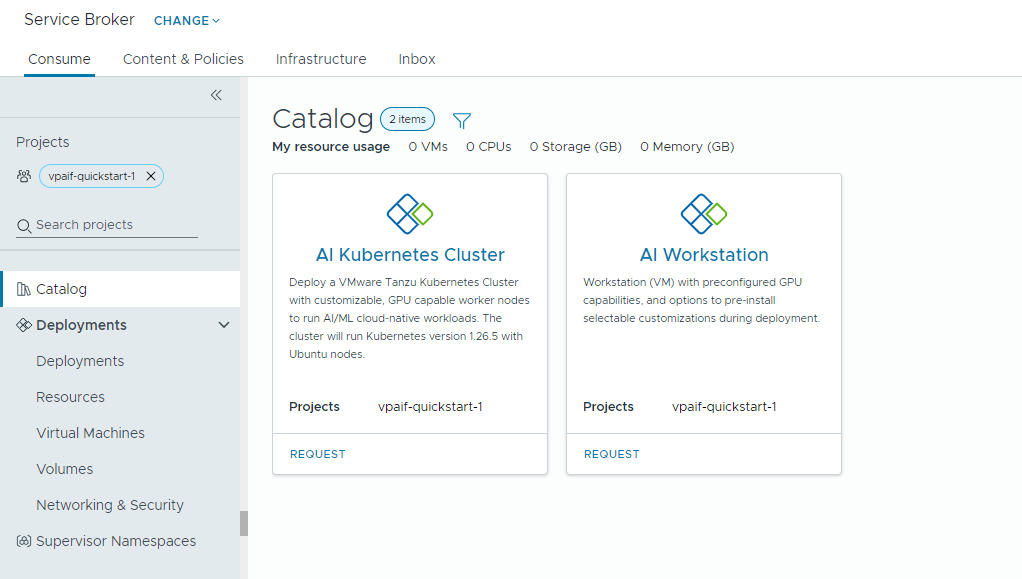
- Station de travail d'IA : machine virtuelle prenant en charge les GPU qui peut être configurée avec le vCPU, le vGPU, la mémoire et le logiciel IA/ML NVIDIA souhaités.
- Cluster Kubernetes d'IA : cluster Tanzu Kubernetes prenant en charge les GPU qui peut être configuré avec NVIDIA GPU Operator.
Avant de commencer
- Vérifiez que Private AI Automation Services est configuré pour votre projet et que vous disposez des autorisations pour demander des éléments de catalogue d'IA.
N'oubliez pas que toutes les valeurs correspondent ici à des exemples de cas d'utilisation. Les valeurs de votre compte dépendent de votre environnement.
Déployer une machine virtuelle Deep Learning sur un domaine de charge de travail VI
En tant qu'expert en science des données, vous pouvez déployer un environnement de développement défini par logiciel de GPU unique à partir du catalogue Automation Service Broker en libre-service. Vous pouvez personnaliser la machine virtuelle prenant en charge les GPU grâce aux paramètres de machine afin de modéliser les exigences de développement, spécifier les configurations logicielles IA/ML pour répondre aux exigences de formation et d'inférence, et spécifier les modules IA/ML à partir du registre NVIDIA NGC via une clé d'accès au portail.
Procédure
Déployer un cluster Tanzu Kubernetes prenant en charge l'IA
En tant qu'ingénieur DevOps, vous pouvez demander un cluster Tanzu Kubernetes prenant en charge les GPU, dans lequel les nœuds worker peuvent exécuter des charges de travail IA/ML.
Le cluster TKG contient un opérateur NVIDIA GPU Operator, qui est un opérateur Kubernetes responsable de la configuration du pilote NVIDIA approprié pour le matériel NVIDIA GPU sur les nœuds de cluster TKG. Le cluster déployé est prêt à l'utilisation pour les charges de travail IA/ML sans configuration supplémentaire liée au GPU.
Procédure
- Localisez la carte Cluster Kubernetes d'IA, puis cliquez sur Demander.
- Sélectionnez un projet.
- Entrez un nom et une description pour votre déploiement.
- Sélectionnez le nombre de nœuds du panneau de contrôle.
Paramètre Exemple de valeur Nombre de nœuds 1 Classe de VM cpu-only-medium - 8 CPUs and 16 GB Memory La sélection de classe définit les ressources disponibles dans la machine virtuelle.
- Sélectionnez le nombre de nœuds de travail.
Paramètre Description Nombre de nœuds 3 Classe de VM a100-medium - 4 vGPU (64 GB), 16 CPUs and 32 GB Memory - Cliquez sur Envoyer.
Résultats
Le déploiement contient un espace de noms de superviseur, un cluster TKG avec trois nœuds de travail, plusieurs ressources dans le cluster TKG et une application carvel qui déploie l'application d'opérateur GPU.
Surveiller les déploiements Private AI
Vous utilisez la page Déploiements pour gérer vos déploiements et les ressources associées, apporter des modifications aux déploiements, assurer le dépannage des échecs de déploiement, effectuer des modifications sur les ressources et détruire les déploiements inutilisés.
Pour gérer vos déploiements, sélectionnez .
Pour plus d'informations, reportez-vous à la section Gestion de mes déploiements Automation Service Broker.
