Vous configurez la restauration sous la forme d'un pipeline avec des tâches qui rétablissent votre déploiement à un état stable antérieur suite à un échec dans un pipeline de déploiement. Pour restaurer en cas d'échec, vous associez le pipeline de restauration à des tâches ou des étapes.
Les raisons d'effectuer une restauration varient en fonction de votre rôle.
- En tant qu'ingénieur en publication, je souhaite que Automation Pipelines s'assure de la réussite d'un pipeline lors de la publication, afin que je puisse décider, en connaissance de cause, de la poursuite de la publication ou de son annulation. Les échecs possibles incluent l'échec d'une tâche, un rejet dans UserOps et le dépassement du seuil des mesures.
- En tant que propriétaire d'environnements, je souhaite redéployer une version précédente afin de pouvoir rapidement rétablir l'état de fonctionnement optimal d'un environnement.
- En tant que propriétaire d'environnements, je souhaite être en mesure d'annuler un déploiement Bleu-vert afin de pouvoir réduire les interruptions de service causées par les versions ayant échoué.
Lorsque vous utilisez un modèle de pipeline intelligent pour créer un pipeline CD tandis que l'option de restauration est activée, la restauration est automatiquement ajoutée aux tâches du pipeline. Dans ce cas d'utilisation, vous utiliserez le modèle de pipeline intelligent pour définir la restauration d'un déploiement d'application vers un cluster Kubernetes à l'aide du modèle de déploiement de mise à niveau propagée. Le modèle de pipeline intelligent crée un pipeline de déploiement, et un ou plusieurs pipelines de restauration.
- Dans le pipeline de déploiement, la restauration est requise en cas d'échec des tâches Mettre à jour le déploiement ou Vérifier le déploiement.
- Dans le pipeline de restauration, le déploiement est mis à jour avec une ancienne image.
Vous pouvez également créer manuellement un pipeline de restauration à l'aide d'un modèle vide. Avant de créer un pipeline de restauration, vous devez planifier votre flux de restauration. Pour plus d'informations de base sur la restauration, reportez-vous à la section Planification de la restauration dans Automation Pipelines.
Conditions préalables
- Assurez-vous d'être membre d'un projet dans Automation Pipelines. Si ce n'est pas le cas, demandez à un administrateur de Automation Pipelines de vous ajouter en tant que membre d'un projet. Reportez-vous à la section Ajout d'un projet dans Automation Pipelines.
- Configurez les clusters Kubernetes sur lesquels votre pipeline déploiera votre application. Configurez un cluster de développement et un cluster de production.
- Vérifiez que vous disposez d'une configuration de registre Docker.
- Identifier un projet qui regroupera tous vos travaux, y compris votre pipeline, vos points de terminaison et vos tableaux de bord.
- Familiarisez-vous avec le modèle intelligent CD comme décrit dans la partie CD de la section Planification d'une build native CICD dans Automation Pipelines avant d'utiliser le modèle de pipeline intelligent. Par exemple :
- Créez le développement Kubernetes et les points de terminaison de production qui déploient votre image d'application sur les clusters Kubernetes.
- Préparez le fichier YAML Kubernetes qui crée l'espace de noms, le service et le déploiement. Si vous devez télécharger une image à partir d'un référentiel privé, le fichier YAML doit inclure une section avec le secret de configuration Docker.
Procédure
- Entrez les informations dans le modèle de pipeline intelligent.
- Sélectionnez un projet.
- Entrez un nom de pipeline comme MiseÀniveauPropagée-Exemple.
- Sélectionnez les environnements de votre application. Pour ajouter une restauration à votre déploiement, vous devez sélectionner Prod.
- Cliquez sur Sélectionner, choisissez un fichier YAML Kubernetes et cliquez sur Processus.
Le modèle de pipeline intelligent affiche les services et les environnements de déploiement disponibles.
- Sélectionnez le service que le pipeline utilisera pour le déploiement.
- Sélectionnez les points de terminaison de cluster pour l'environnement Dev et l'environnement Prod.
- Pour la source Image, sélectionnez Entrée d'exécution du pipeline.
- Pour le modèle de déploiement, sélectionnez Mise à niveau propagée.
- Cliquez sur Restaurer.
- Fournissez l'URL de contrôle de santé.
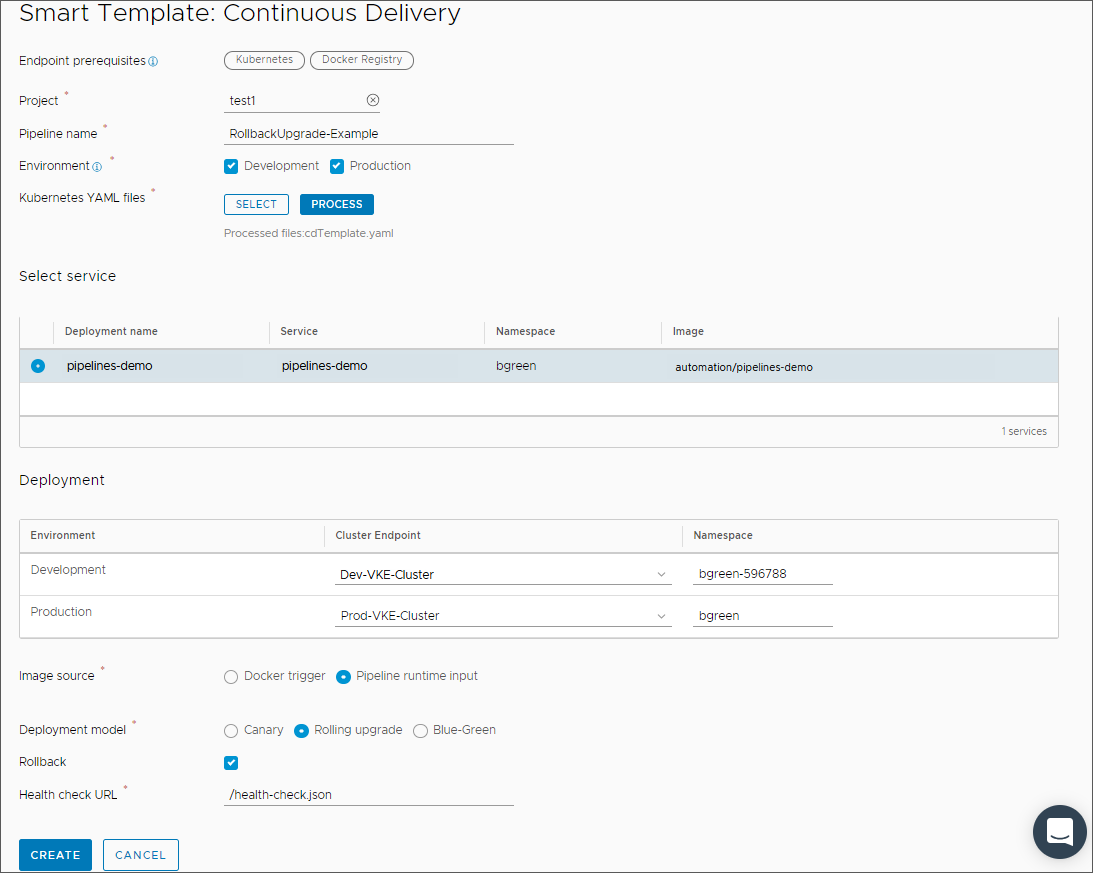
- Pour créer le pipeline nommé MiseÀniveauRestauration-Exemple, cliquez sur Créer.
Le pipeline nommé RollbackUpgrade-Example s'affiche et l'icône de restauration s'affiche sur les tâches qui peuvent être restaurées à l'étape de développement et à l'étape de production.
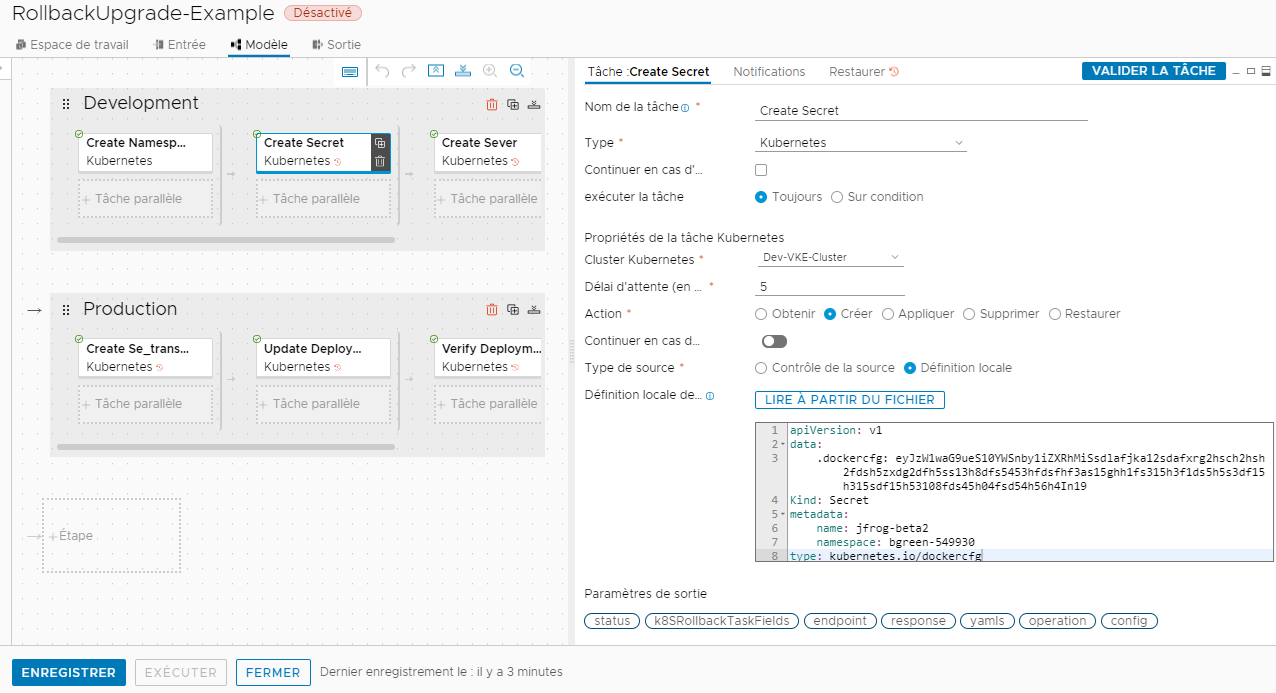
- Fermez le pipeline.
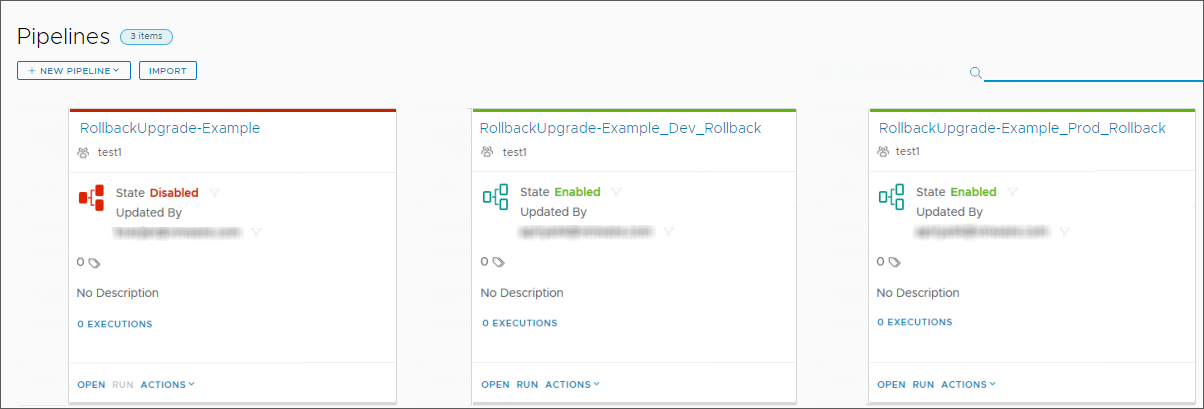
Sur la page Pipelines, le pipeline que vous avez créé s'affiche, et un nouveau pipeline pour chaque étape de votre pipeline s'affiche.
- MiseÀniveauPropagée-Exemple. Automation Pipelines désactive le pipeline que vous avez créé par défaut, ce qui garantit que vous l'examinez avant de l'exécuter.
- MiseÀniveauPropagée-Exemple_Dév_Restauration. L'échec de tâches à l'étape de développement, telles que le service Créer un service, Créer un secret, Créer un déploiement et Vérifier le déploiement appelle ce pipeline de développement par restauration. Pour garantir la restauration des tâches de développement, Automation Pipelines active le pipeline de développement par restauration par défaut.
- MiseÀniveauPropagée-Exemple_Prod_Restauration. L'échec de tâches à l'étape de production, telles que Déployer la phase 1, Vérifier la phase 1, Déployer la phase de lancement Terminer la phase de lancement et Vérifier la phase de lancement appelle ce pipeline de production par restauration. Pour garantir la restauration des tâches de production, Automation Pipelines active le pipeline de production par restauration par défaut.
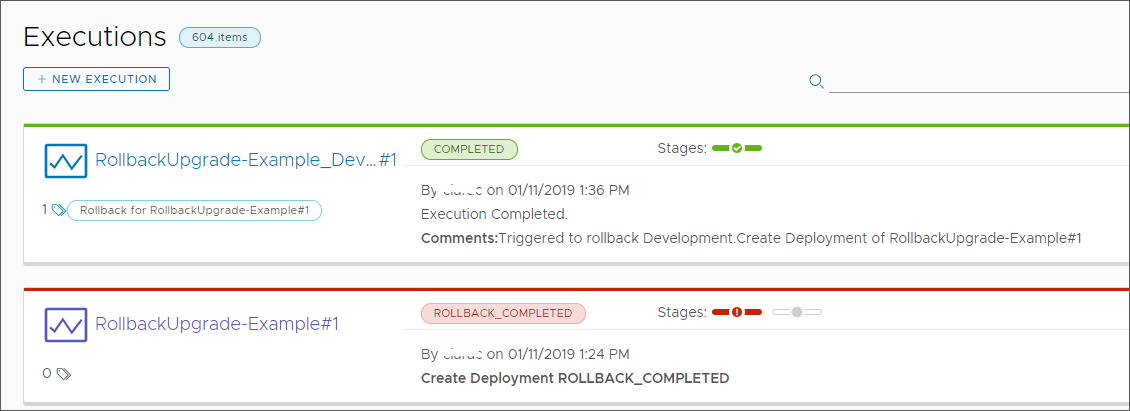
- Sur la page Exécutions, sélectionnez pour surveiller l'exécution du pipeline.
L'opération RUNNING du pipeline commence et les différentes tâches de l'étape de développement sont effectuées une à une. Si le pipeline ne parvient pas à exécuter une tâche pendant l'étape de développement, le pipeline nommé RollingUpgrade-Example_Dev_Rollback est déclenché et restaure le déploiement, puis l'état du pipeline devient ROLLING_BACK.
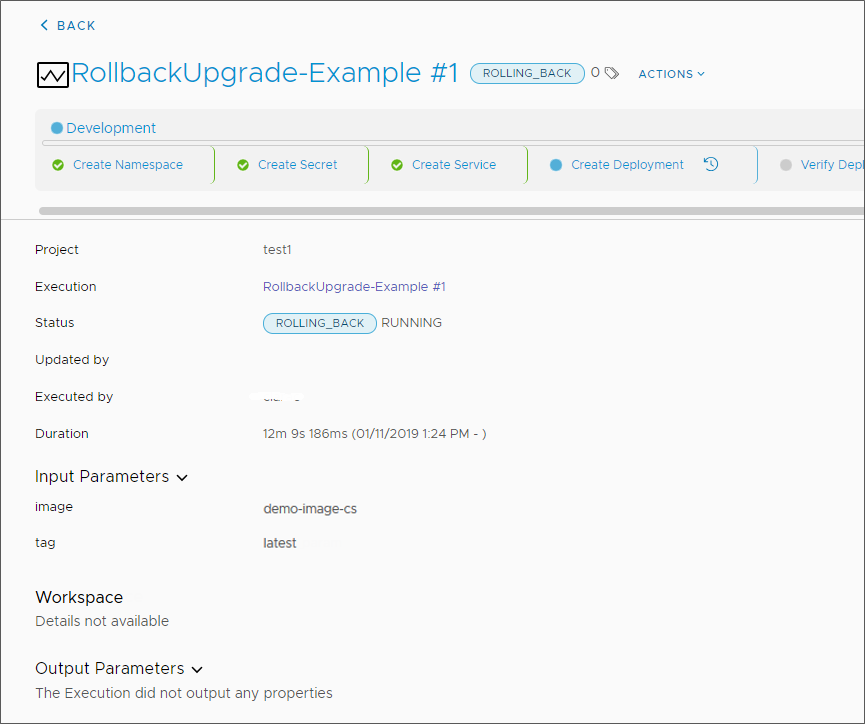
Après restauration, la page Exécutions répertorie deux exécutions de pipeline MiseÀniveauPropagée-Exemple.
- Le pipeline que vous avez créé a été restauré et affiche ROLLBACK_COMPLETED.
- Le pipeline de développement par restauration qui a été déclenché et qui a effectué la restauration indique COMPLETED.