









Le tableau de bord Contention des clusters est le tableau de bord principal pour les performances de cluster vSphere. Il est conçu pour les administrateurs ou les architectes VMware. Il peut être utilisé à des fins de surveillance et de dépannage. Une fois que vous avez déterminé qu'il existe un problème de performances, utilisez le tableau de bord Utilisation des clusters pour voir si la contention est causée par une utilisation élevée.
Considérations relatives à la conception
Ce tableau de bord est utilisé dans le cadre de votre procédure d'exploitation standard (SOP). Il est conçu pour une utilisation quotidienne. Par conséquent, les vues sont définies pour afficher les données des dernières 24 heures. Le tableau de bord fournit des mesures de performances pour les machines virtuelles dans le centre de données sélectionné.
L'utilisation du cluster n'est pas affichée dans le tableau de bord Contention des clusters. Vous devez séparer les deux concepts : utilisation et contention. Les performances et la capacité sont des concepts différents, gérés par deux équipes distinctes. Le CPU et la mémoire sont également affichés séparément. Vous pouvez rencontrer un problème avec l'un, sans que l'autre soit affecté. Le CPU est plus courant, car la mémoire a tendance à avoir un ratio de surcharge inférieur.
Pour afficher les considérations relatives à la conception communes à tous les tableaux de bord de gestion des performances, consultez Tableaux de bord Performances.
Utilisation du tableau de bord
- Performances moyennes du cluster (%).
- Il s'agit du KPI principal pour l'intégralité de votre IaaS. Il trace les performances de votre IaaS toutes les 5 minutes, ce qui vous donne une visibilité sur les tendances des performances globales.
- La mesure elle-même est simplement la moyenne des mesures du KPI/des performances du cluster (%). Cette mesure de performances calcule la moyenne des performances de la VM/du nombre de mesures de KPI enfreintes pour toutes les machines virtuelles en cours d'exécution dans le cluster. Par conséquent, une valeur de 100 % indique que chaque machine virtuelle en cours d'exécution dans le cluster est bien desservie.
- Étant donné que ce KPI prend en compte toutes les machines virtuelles en cours d'exécution dans votre environnement, le nombre doit être stable. Une analogie concrète de ce système serait l'indice boursier. Alors que les actions individuelles peuvent être volatiles, l'ensemble de l'indice doit être relativement stable sur des intervalles de 5 minutes.
- Le mouvement relatif de la mesure est aussi important que la valeur absolue de la mesure. Le nombre absolu peut ne pas être aussi élevé que vous le souhaitez, mais s'il n'y a pas de réclamation pendant un long moment, il n'y a aucune raison urgente de l'améliorer.
- Performances des clusters.
- Elles répertorient tous les clusters, triés du cluster en cours d'exécution le moins performant au plus performant, sur la dernière semaine. Vous pouvez modifier cette période.
- Les pires performances affichent le nombre le plus bas dans la période. Comme VMware Aria Operations collecte des données toutes les 5 minutes, 12 x 24 x 7 = 2 016 points de données sont créés par semaine. Cette colonne indique le pire point parmi ces 2 016 points de données.
- Un nombre unique parmi ces 2 016 points de données peut être une aberration qui doit parfois être complétée par un autre nombre. Un choix logique est la moyenne de ces nombres. Pour que les performances moyennes soient faibles, un grand nombre de critères doivent être faibles. L'attente de la moyenne entraîne un retard dans vos opérations et une augmentation des plaintes. Pour la surveillance des performances, le 95e centile est un meilleur résumé que la moyenne.
- Votre cluster doit fonctionner à 100 % et réaliser ses fonctions comme prévu.
- Sélectionnez un cluster dans le tableau.
- Tous les graphiques de santé indiquent le KPI du cluster sélectionné.
- Il est important d'afficher la profondeur et la portée des problèmes de performances. Un problème qui affecte une ou deux machines virtuelles nécessite un dépannage différent d'un problème qui affecte toutes les machines virtuelles du cluster.
- La profondeur est constatée en générant un rapport sur le pire compteur de machine virtuelle. Ce rapport indique la valeur la plus élevée de disponibilité de CPU de VM, de contention de mémoire de VM et de latence de disque de VM parmi toutes les VM en cours d'exécution. Si le nombre le plus mauvais est correct, vous n'avez pas besoin d'examiner le reste des machines virtuelles.
- Un cluster de grande taille comportant des milliers de machines virtuelles peut avoir une seule machine virtuelle subissant de mauvaises performances alors que 99,9 % des machines virtuelles fonctionnent correctement. Le compteur de profondeur peut ne pas signaler que la plupart des machines virtuelles fonctionnent correctement. Il signale uniquement les dysfonctionnements. C'est là qu'intervient la portée.
- Les compteurs de portée indiquent le pourcentage de la population de machine virtuelle qui rencontre des problèmes de performances. Le seuil défini est strict, car l'objectif consiste à fournir un avertissement précoce et à activer les opérations proactives.
Points à noter
Il est possible que les machines virtuelles du cluster souffrent de performances médiocres, alors que l'utilisation du cluster est faible. Une des raisons principales de cette situation est que l'utilisation du cluster examine la couche de fournisseur (ESXi), tandis que les performances s'intéressent au consommateur individuel (VM). Le tableau suivant montre différentes raisons possibles.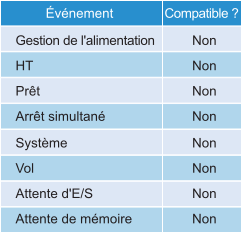
Du point de vue de la gestion des performances, le cluster vSphere est le plus petit bloc de construction logique des ressources. Bien que le pool de ressources et l'affinité de l'hôte de VM puissent fournir une plus petite tranche, ils sont complexes d'un point de vue opérationnel et ne peuvent pas fournir la qualité prévue de service IaaS. Le pool de ressources ne peut pas fournir une classe de service différenciée. Par exemple, votre SLA stipule que la classe de service Or est deux fois plus rapide que la classe Argent, étant facturée à 200 % de plus. Le pool de ressources peut donner à la classe Or deux fois plus de parts. Mais il est impossible de déterminer en amont si ces parts supplémentaires correspondent à la moitié de la disponibilité du CPU.
Certains paramètres tels que le niveau d'automatisation DRS et la présence de nombreux pools de ressources peuvent avoir un impact sur les performances. Envisagez d'ajouter un widget de propriétés pour afficher la propriété appropriée d'un cluster sélectionné et un widget de relation pour afficher les pools de ressources.
Pour un environnement volumineux avec de nombreux clusters, ajoutez un regroupement pour rendre la liste plus gérable. Regroupez-les par classe de service, afin de pouvoir vous concentrer sur les clusters critiques.
