









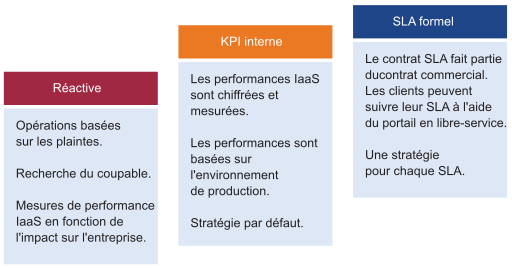
Les performances consistent à garantir que les charges de travail obtiennent les ressources nécessaires. Les indicateurs de performance clés (KPI) peuvent être utilisés pour identifier les problèmes de performances liés aux charges de travail. Utilisez ces KPI pour définir les SLA associés aux niveaux de service. Ces tableaux de bord utilisent des KPI pour afficher les performances des charges de travail au niveau de la couche consommateur et les performances agrégées des charges de travail au niveau de la couche fournisseur.
Le SLA est le contrat commercial formel que vous passez avec vos clients. En général, le SLA est compris entre le fournisseur IaaS (l'équipe de l'infrastructure) et le client IaaS (l'équipe d'application ou l'unité commerciale). Le SLA formel nécessite une transformation opérationnelle, par exemple, il demande plus que des modifications techniques et vous devrez peut-être examiner le contrat, le prix (pas le coût), le processus et les personnes. Les KPI couvrent les mesures SLA et les mesures supplémentaires qui fournissent un avertissement précoce. Si vous ne disposez pas d'un SLA, commencez par un KPI interne. Vous devez comprendre et profiler les performances réelles de votre IaaS. Utilisez les paramètres par défaut dans VMware Aria Operations si vous ne disposez pas de votre propre seuil, car ces seuils ont été sélectionnés pour prendre en charge les opérations proactives.
Les trois processus de gestion des performances
- Planification. Définissez vos objectifs de performances. Lorsque vous architecturez un vSAN, vous devez connaître le nombre de millisecondes de latence de disque que vous souhaitez définir. 10 millisecondes mesurées au niveau de la machine virtuelle (pas au niveau de la vSAN) est un bon début.
- Surveillance. Comparez le plan avec la situation réelle. La réalité correspond-elle à votre architecture qui était censée être livrée ? Si ce n'est pas le cas, vous devez la corriger.
- Dépannage. Lorsque la réalité n'est pas conforme au plan, vous devez la corriger de manière proactive et ne pas attendre les problèmes et les plaintes.
- Contention : il s'agit de l'indicateur principal.
- Configuration : Vérifiez les incompatibilités de version.
- Disponibilité : vérifiez les erreurs logicielles. Temps de latence de vMotion, fermé. Log Insight est requis.
- Utilisation : vérifiez cet indicateur à la fin. Si les trois premiers paramètres sont corrects, vous pouvez ignorer cette étape.
Les trois couches de gestion des performances
Il existe trois domaines principaux d'applications d'entreprise. Chacun de ces domaines a son propre ensemble d'équipes. Chaque équipe a un ensemble de responsabilités uniques et nécessite l'ensemble des compétences associées. Les trois domaines comprennent l'Activité, l'Application et l'IaaS. Reportez-vous au graphique ci-dessous pour comprendre les trois couches et les questions fréquemment posées sur chaque couche. 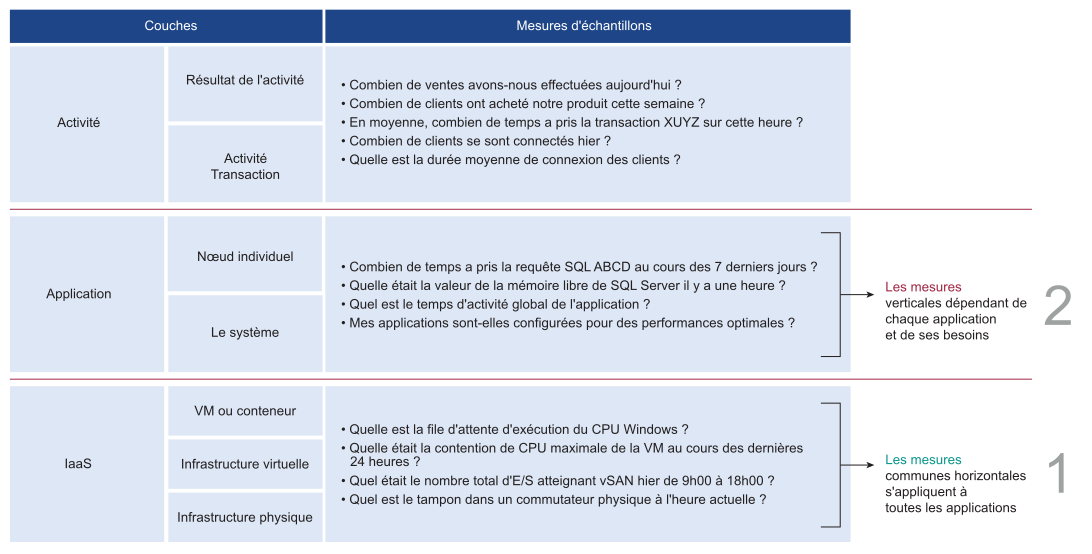
La gestion des performances est principalement un exercice de suppression. La méthodologie découpe chaque couche et détermine si cette couche provoque le problème de performances. Il est donc impératif de disposer d'une mesure unique pour indiquer si une couche particulière est performante ou non. Cette mesure principale est justement appelée un indicateur de performance clé (KPI, Key Performance Indicator).
La couche supérieure dépend de la couche inférieure et la couche d'infrastructure est donc généralement la source de contention. Par conséquent, privilégiez d'abord la couche inférieure, car elle sert de base pour la couche supérieure. Cette couche est généralement une couche horizontale, fournissant un ensemble de services d'infrastructure génériques, quelles que soient les applications métiers qui y sont exécutées.
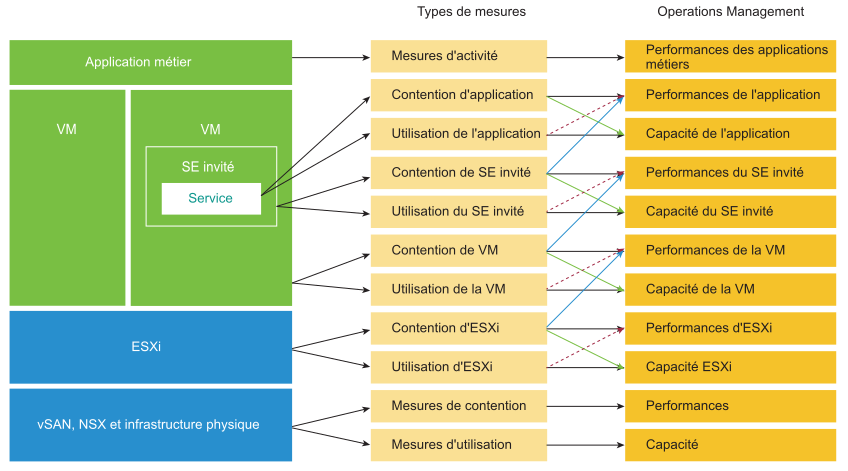
Les deux mesures de gestion des performances
Le compteur principal pour mesurer les performances est la contention. La plupart des clients examinent l'utilisation, car ils craignent qu'un problème survienne si celle-ci est élevée. Ce problème est une contention. Les contentions se manifestent sous différentes formes, comme la file d'attente, la latence, les abandons, les annulations et le changement de contexte.
Cependant, ne prenez pas les indicateurs d'utilisation extrêmement élevée pour un problème de performances. Si votre hôte ESXi subit un gonflage, une compression et un échange, cela ne signifie pas que votre machine virtuelle présente un problème de performances. Vous mesurez les performances de l'hôte en fonction de son efficacité quant à ses VM. Alors que les performances sont liées à l'utilisation de l'hôte ESXi, les mesures des performances ne sont pas basées sur l'utilisation, mais sur des mesures de contention.
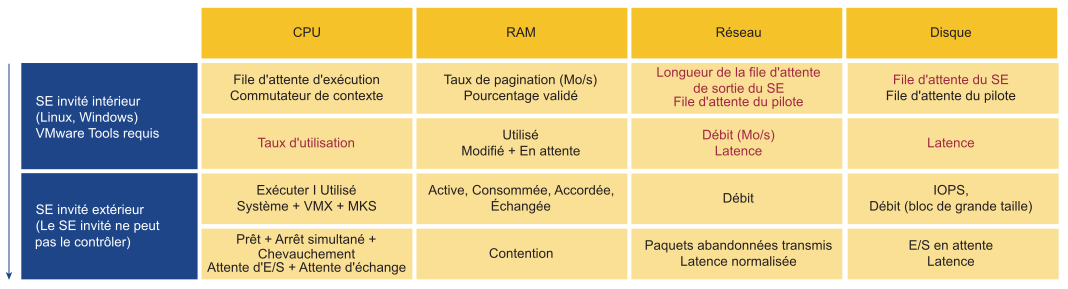
| Configuration de l'infrastructure | Configuration de la machine virtuelle et du SE invité |
|---|---|
Paramètres ESXi
|
VM : limite, partage et réservation
|
Réseau
|
Taille : effet NUMA. VM qui s'étend sur les nœuds NUMA. |
Paramètres de cluster
|
Snapshot. Les E/S sont traitées en deux fois. Pilotes de VM. |
vSAN
|
Ping pong de processus, échappement de processus et file d'attente au niveau du système d'exploitation Windows ou Linux. |
Du point de vue de la gestion des performances, le cluster vSphere est le plus petit bloc de construction logique des ressources. Bien que le pool de ressources et l'affinité de l'hôte de VM puissent fournir une plus petite tranche, ils sont complexes d'un point de vue opérationnel et ne peuvent pas fournir la qualité prévue de service IaaS. Le pool de ressources ne peut pas fournir une classe de service différenciée. Par exemple, votre SLA stipule que la classe de service Or est deux fois plus rapide que la classe Argent, étant facturée à 200 % de plus. Le pool de ressources peut donner à la classe Or deux fois plus de parts. Mais il est impossible de déterminer en amont si ces parts supplémentaires correspondent à la moitié de la disponibilité du CPU.
Performances de la VM
Les compteurs KPI peuvent sembler techniques pour certains utilisateurs. C'est pourquoi VMware Aria Operations inclut une ligne de départ pour qu'ils puissent se lancer. Vous pouvez ajuster le seuil une fois que vous avez profilé votre environnement. Ce profilage est un excellent exercice, car la plupart des clients ne disposent pas d'une ligne de base. Le profilage nécessite une édition avancée.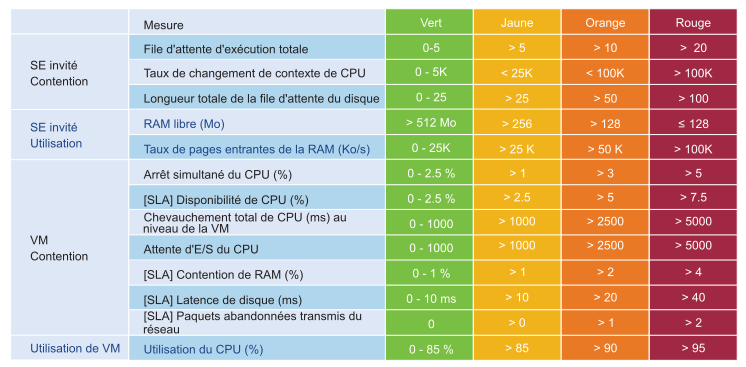
Mesures de performance
| IaaS | Compteur de VM | Seuil |
|---|---|---|
| CPU | Prêt | 2,5 % |
| RAM | Contention | 1% |
| Disque | Latence | 10 ms |
| Réseau | Paquets abandonnés transmis | 0 |
Le tableau est un exemple de seuil strict. Une norme élevée est utilisée pour les performances, car il s'agit d'un KPI interne pour la consommation de l'équipe d'infrastructure. Il ne s'agit pas d'un SLA formel externe qui est confirmé avec les clients. Il doit y avoir un tampon entre le KPI interne et le contrat SLA externe afin que l'équipe responsable des opérations reçoive des avertissements précoces et ait le temps de réagir avant que le SLA externe ne soit enfreint. Une norme élevée fonctionne également depuis le point stratégique pour l'affichage de l'environnement de développement. Si la norme est définie sur l'environnement le moins performant, elle ne peut pas être appliquée au développement le plus critique.
Un seuil unique est utilisé pour simplifier les opérations. Cela signifie que les performances en production doivent avoir un score supérieur à celui de l’environnement de développement. Les performances de l'environnement de développement doivent être pires que celles de l'environnement de production, alors que tout le reste est équivalent. Un seuil unique permet d'expliquer la différence de qualité de service (QoS) offerte par une classe de service différente. Par exemple, si vous payez moins, vous obtenez de mauvaises performances et si vous payez la moitié du prix, attendez-vous à obtenir la moitié des performances.
Les quatre éléments IaaS (CPU, RAM, disque et réseau) indiqués dans le tableau sont évalués à chaque cycle de collecte. La durée de collecte est définie sur cinq minutes, car il s’agit d’un équilibre approprié pour la surveillance. Si le SLA est basé sur une minute, il est trop proche et entraîne une augmentation des coûts ou une réduction du seuil.
Considérations relatives à la conception
Tous les tableaux de bord de performances partagent les mêmes principes de conception. Puisqu'ils ont le même objectif, les tableaux de bord sont intentionnellement conçus pour être similaires. En effet, des tableaux différents les uns des autres entraîneraient une certaine confusion.
Les tableaux de bord sont conçus avec deux sections distinctes : Résumé et Détail.
- La section Résumé est généralement placée en haut du tableau de bord pour fournir l'image globale.
- La section Détail est placée sous la section Résumé. Elle vous permet d'explorer un objet spécifique. Par exemple, vous pouvez obtenir le rapport détaillé sur les performances d'une machine virtuelle spécifique.
Dans la section Détail, utilisez le commutateur de contexte rapide pour vérifier les performances de plusieurs objets lors du dépannage des performances. Par exemple, si vous examinez les performances de la machine virtuelle, vous pouvez afficher les informations spécifiques à la machine virtuelle et les KPI sans changer d'écran. Vous pouvez également passer d'une VM à une autre et afficher les détails sans ouvrir plusieurs fenêtres.
Le tableau de bord utilise la diffusion progressive pour réduire la surcharge d'information et garantir un chargement rapide de la page Web. De plus, si votre session de navigateur continue de fonctionner, l'interface mémorise vos dernières sélections.
La plupart des tableaux de bord de performances et de capacité partagent une disposition similaire, car il existe une similitude entre ces piliers d'opérations.
