









Vous pouvez surveiller l'état du cluster à l'aide de l'interface utilisateur de gestion des dispositifs VMware Cloud Director.
Procédure
- Connectez-vous en tant qu'utilisateur racine à l'interface utilisateur de gestion de dispositif à l'adresse https://primary_eth1_ip_address:5480.
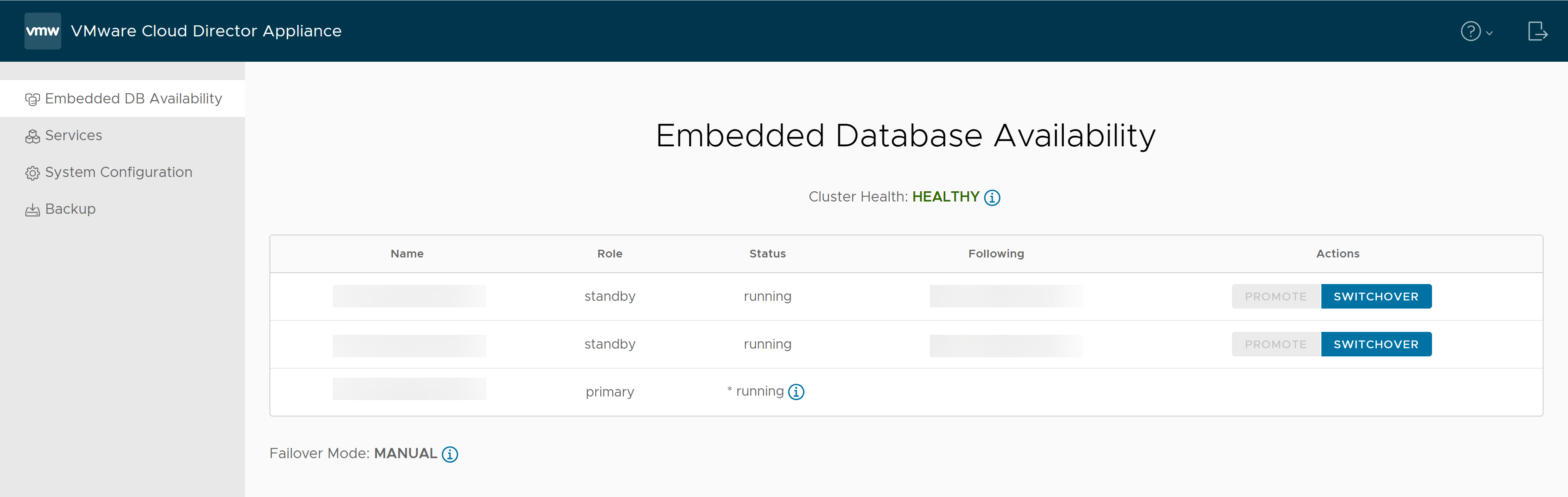
- Dans le panneau de gauche, sélectionnez Disponibilité de la base de données intégrée.
Vous pouvez afficher les noms DNS courts des nœuds, leurs rôles, leur état, le nom de leur nœud en amont, c'est-à-dire l'instance principale actuelle et les actions disponibles sur les nœuds.
Dans la colonne Suivant, un point d'interrogation (?) devant le nom d'hôte indique que l'instance principale actuelle est inaccessible. Un point d'exclamation (!) devant le nom d'hôte indique que les métadonnées de l'instance principale actuelle ne sont pas actualisées et peuvent être incorrectes, ou que le nœud n'est pas attaché à l'instance principale actuelle. Le problème peut se produire si vous redémarrez le nœud après une interruption de service prolongée. Si le nœud ne peut pas être attaché à l'instance principale, vous devez annuler son enregistrement et le remplacer par une nouvelle instance en veille.
- Affichez la santé du cluster.
État de santé du cluster Description Sain Le cluster est dans un état sain. La cellule principale et les deux cellules en veille sont en ligne et opérationnelles.
L'interface utilisateur et l'API de VMware Cloud Director sont opérationnelles.
Dégradé Le cluster est dans un état dégradé. La cellule principale et l'une des cellules en veille sont en ligne et opérationnelles, mais l'autre cellule en veille ne fonctionne pas. La base de données principale est opérationnelle dans cet état, mais s'il existe une autre panne de base de données de l'une des deux cellules opérationnelles, la cellule principale devient non fonctionnelle. La cellule en veille non fonctionnelle doit être remplacée par une nouvelle cellule en veille opérationnelle dès que possible pour restaurer le cluster à un état
Healthy.L'interface utilisateur et l'API de VMware Cloud Director sont opérationnelles.
No_Active_Primary Il n'y a pas de base de données principale opérationnelle. S'il y a deux cellules en veille opérationnelles, l'une d'entre elles doit être promue pour devenir la nouvelle cellule principale. Si l'environnement ne dispose pas de deux cellules en veille opérationnelles, vous devez diagnostiquer le problème et résoudre la situation manuellement.
L'interface utilisateur et l'API de VMware Cloud Director ne sont pas disponibles.
Read_Only_Primary Il y a une base de données principale en ligne, mais elle est
Read_Only, car l'environnement ne dispose pas d'une cellule en veille opérationnelle. Deux nouvelles cellules en veille doivent être déployées.L'interface utilisateur et l'API de VMware Cloud Director ne sont pas disponibles.
Critical_Problem Le cluster est dans un état incohérent. Par exemple, plusieurs cellules principales sont en ligne ou une cellule en veille ne suit pas la bonne cellule principale. Vous devez diagnostiquer le problème et y remédier manuellement.
Cet état peut affecter la disponibilité de l'interface utilisateur et de l'API de VMware Cloud Director.
SSH_Problem Le problème SSH indique que l'utilisateur postgres ne peut pas se connecter à ses nœuds de base de données homologues sur SSH. Vous devez résoudre ce problème critique le plus tôt possible. Reportez-vous à la section La santé de votre cluster VMware Cloud Director indique un problème SSH.
L'interface utilisateur et l'API de VMware Cloud Director ne peuvent pas être entièrement fonctionnelles.
- Affichez le mode de basculement du dispositif.
Mode de basculement Description Automatique Si une panne de la base de données principale se produit, VMware Cloud Director déclenche automatiquement un basculement de base de données. Manuelle Si une panne de la base de données principale se produit, vous devez initier un basculement de base de données à l'aide de l'interface utilisateur de gestion des dispositifs VMware Cloud Director ou de l'API de basculement. Indéterminé Le mode de basculement n'est pas cohérent sur tous les nœuds du cluster. Vous devez diagnostiquer le problème et y remédier. À l'aide de l'API du dispositif VMware Cloud Director, réinitialisez le FailoverModesurManualou surAutomatic. Reportez-vous aux informations sur le mode de basculement dans la rubrique Référence de schéma de VMware Cloud Director Appliance API.
