









Le service Autoscaler de VMware Cloud on AWS surveille la santé de votre infrastructure SDDC, détecte les pannes naissantes et réelles, et corrige automatiquement l'infrastructure en remplaçant les hôtes avant ou après une panne.
L'infrastructure AWS est fiable, mais les pannes sont inévitables, même dans l'infrastructure la plus fiable. L'article Fiabilité du cadre de l'architecture AWS traite de ses principes de conception pour la fiabilité dans le cloud. VMware Cloud on AWS étend ces principes en faisant abstraction de l'infrastructure sous-jacente et en exploitant les capacités d'analyse prédictive des pannes de vCenter Server et d'ESXi pour fournir une correction réactive en cas de panne et une correction prédictive qui peut empêcher les pannes d'affecter les charges de travail.
Architecture de correction automatique de haut niveau
- AWS envoie des informations au niveau de l'hôte à VMware, notamment des événements de maintenance planifiée d'AWS. Le service Autoscaler reçoit ces notifications et corrige automatiquement tous les problèmes au sein du SDDC.
- Un service de surveillance au niveau du SDDC reçoit des notifications des composants VMware Cloud on AWS sous-jacents.
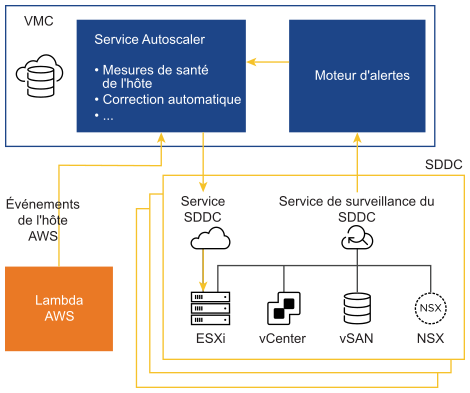
Correction réactive
La correction automatique réactive surveille les pannes matérielles et logicielles, et tente de corriger les problèmes de plusieurs manières. La correction automatique est un processus interne et en constante évolution. Les utilisateurs de VMware Cloud on AWS n'ont pas accès au workflow ou à sa configuration, mais pour vous aider à mieux le comprendre, voici une présentation générale des étapes actuellement mises en œuvre.
- 1 : Surveiller
- VMware Cloud on AWS surveille en permanence la santé de chaque hôte de votre SDDC. Lorsqu'une panne est détectée, un événement est envoyé à la correction automatique.
- 2 : Attendre les événements transitoires
- Certaines pannes détectées peuvent être temporaires. Par exemple, lorsque le système de surveillance ne peut pas atteindre un hôte en raison d'un problème de connectivité temporaire. La correction automatique attend cinq minutes pour déterminer si le problème est temporaire. Si c'est le cas, la correction automatique revient sans aucune action.
- 3 : Ajouter un hôte
- Si l'erreur ne se résout pas après cinq minutes, la correction automatique commence à ajouter un hôte au SDDC. L'ajout préventif d'un hôte de la même manière garantit que l'hôte est disponible si cela s'avère nécessaire. Veuillez noter que cet hôte ne vous sera pas facturé tant qu'il n'aura pas remplacé un hôte défectueux dans votre SDDC.
- 4 : Déterminer le type de panne et prendre des mesures
- Les hôtes peuvent tomber en panne pour différentes raisons et cela nécessite une action différente. Par exemple, une panne de disque vSAN sur un hôte qui est toujours connecté à un système vCenter Server peut être corrigée par un redémarrage logiciel, tandis qu'un hôte PSOD nécessite un redémarrage matériel.
- 5 : Vérifier la santé de l'hôte
- L'étape suivante consiste à vérifier si l'action de correction a corrigé l'hôte. Si l'hôte en panne est maintenant en bonne santé après un redémarrage logiciel ou matériel, la correction automatique évite une interruption supplémentaire du SDDC. Elle collecte et prend toutes les autres mesures nécessaires et supprime le nouvel hôte qui avait été ajouté de manière préventive à l'étape 3.
- 6 : Remplacer l'hôte
- Si l'hôte en panne ne peut pas être relancé, Autoscaler le supprime et le remplace par l'hôte ajouté à l'étape 3. vSphere HA et vSAN sont déclenchés, et des balises de stratégie de calcul sont attachées au nouvel hôte.
Correction préventive
- Un nouvel hôte est ajouté au cluster. Les balises sont copiées vers ce nouvel hôte à partir de l'hôte à remplacer.
- L'hôte ayant échoué est placé en mode de maintenance avec une évacuation complète des données. Cela déplace sans interruption les machines virtuelles ou les données vSAN vers d'autres hôtes dans le cluster.
- L'hôte ayant échoué est supprimé du cluster.
Événements Autoscaler
Lorsque le service Autoscaler reçoit un événement de panne, il détermine le type de panne et prend les mesures appropriées. Le journal d'activité du SDDC inclut toutes les activités d'Autoscaler, mais n'affiche pas l'événement d'échec qui a déclenché l'activité.
- Événements de vCenter Server
-
- Un événement est déclenché pour vérifier l'état de connexion de l'hôte
- Un événement se déclenche lorsque l'hôte ESXi est déconnecté ou ne répond pas.
- Événements de DAS
-
- Événements de vSphere HA : un événement est créé lorsqu'il n'existe aucune communication avec le nœud master ou lorsque HA est en panne. (FDM)
- Lorsqu'un hôte est en panne, le système HA signale une panne d'hôte.
- vSAN événements
-
- En cas de panne de disque sur les hôtes.
- Lorsque l'hôte vSAN est déconnecté.
- Événements d'EDRS (sans échec)
- Mise à niveau : désactiver l'EDRS. Les activités de maintenance nécessitent fréquemment un hôte supplémentaire et un ou plusieurs hôtes sont ajoutés dans le cadre de l'événement de maintenance. L'EDRS est désactivé pour la durée de toute maintenance planifiée afin d'empêcher que ces activités ne déclenchent des événements de réduction de charge/montée en charge.
- Événements AWS
-
- Événements de maintenance planifiés. Notification d'AWS indiquant qu'un problème de santé de l'instance a été détecté et que l'instance doit être évacuée.
- Tableau de bord de santé personnel (PHD, Personal Health Dashboard). Flux d'événements qui fournit des informations sur divers composants matériels et permet à VMware de détecter les pannes matérielles de manière préventive.
- Vérification de l'état du système. Surveille la santé des systèmes AWS sur lesquels repose l'instance. Cette vérification signale les problèmes que seul AWS peut corriger. Dans de nombreux cas, ces problèmes sont temporaires et aucune action n'est requise.
- Vérification de l'état de l'instance. Surveille la configuration logicielle et réseau de chaque instance. Cette vérification surveille la disponibilité de l'instance en émettant des demandes ARP périodiques vers la carte réseau. Ajout de la génération de rapports sur la disponibilité de l'instance au niveau de la couche EC2. Les contrôles de l'état de l'instance surveillent l'utilisation du matériel sous-jacent et signalent les problèmes de mise en réseau, l'épuisement de la mémoire, le système de fichiers endommagé, les erreurs de noyau, etc. Contrairement aux vérifications de l'état du système, la résolution des vérifications de l'état de l'instance nécessite une intervention de VMware.
- Événements SDDC
- Intégrité de l'hôte vCenter Server.
