









Le Runbook de contrôle de santé de l'interface CLI VMware Integrated OpenStack couvre les cas viocli check health et les procédures de résolution des problèmes signalés.
Vous pouvez exécuter l'une des solutions suivantes pour les problèmes signalés dans viocli check health :
Nœud non prêt
- Pour obtenir l'état du nœud, exécutez la commande
osctl get node.osctl get node NAME STATUS ROLES AGE VERSION controller-dqpzc8r69w Ready openstack-control-plane 17d v1.17.2+vmware.1 controller-lqb7xjgm9r Ready openstack-control-plane 17d v1.17.2+vmware.1 controller-mvn5nmdrsp Ready openstack-control-plane 17d v1.17.2+vmware.1 vxlan-vm-111-161.vio-mgmt.eng.vmware.com Ready master 17d v1.17.2+vmware.1
- Redémarrez le service kubelet sur le site
not ready nodeavec la commande suivante :viosshcmd ${not_ready_node} 'sudo systemctl restart kubelet' - Pour revérifier l'état de ce problème, exécutez
viocli check health -n kubernetes.
Nœud avec une adresse IP dupliquée
Pour plus d'informations sur le nœud avec une adresse IP dupliquée, voir KB 82608.
Pour revérifier l'état de ce problème, exécutez viocli check health -n kubernetes.
Nœud malsain
- Exécutez
osctl describe node <node>pour obtenir l'état de santé du nœud.Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- NetworkUnavailable False Sat, 05 Jun 2021 10:47:53 +0000 Sat, 05 Jun 2021 10:47:53 +0000 CalicoIsUp Calico is running on this node MemoryPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasNoDiskPressure kubelet has no disk pressure PIDPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasSufficientPID kubelet has sufficient PID available Ready True Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:32 +0000 KubeletReady kubelet is posting ready status
- Si l'état de
NetworkUnavailable,MemoryPressure,DiskPressure, ouPIDPressureest vrai, le nœud Kubernetes est dans un état malsain. Vous devez donc vérifier l'état du système et l'utilisation des ressources du nœud malsain. - Pour revérifier l'état de ce problème, exécutez
viocli check health -n kubernetes.
Nœud avec une utilisation élevée du disque
- Connectez-vous au nœud qui signale une utilisation élevée du disque.
#viossh ${node} - Vérifiez l'utilisation du disque avec
df -h. - Supprimer les fichiers inutilisés sur le nœud.
- Pour revérifier l'état de ce problème, exécutez
viocli check health -n kubernetes.
Evicted, contactez le support VMware pour obtenir de l'aide.
- Connectez-vous au nœud avec l'utilisation élevée de l’inode.
#viossh ${node} - Vérifiez l'utilisation des inodes avec
df -i /. - Supprimer les fichiers inutilisés sur le nœud.
- Pour revérifier l'état de ce problème, exécutez
viocli check health -n kubernetes.
Node avec Snapshot
- Connectez-vous au vCenter et supprimez les instantanés pris pour les nœuds de contrôleur VMware Integrated OpenStack.
- S'il signale une erreur fail to connect to vCenter, vous devez vérifier les informations de connexion de vCenter dans VMware Integrated OpenStack.
- Pour revérifier l'état de ce problème, exécutez
viocli check health -n kubernetes.
Impossible de résoudre le FQDN
- Depuis le nœud de gestion VMware Integrated OpenStack, vérifiez la résolution DNS à l'aide des commandes suivantes :
#viosshcmd ${node_name} -c "nslookup ${reported_host}" #toolbox -c "dig $host +noedns +tcp" - En cas d'échec, vérifiez le serveur DNS configuré dans le nœud VMware Integrated OpenStack /etc/resolve.conf.
- Pour revérifier l'état de ce problème, exécutez
viocli check health -n connectivity.
NTP non synchronisé dans le nœud
Pour de plus amples informations sur les dossiers, reportez-vous à la section KB 78565. Pour revérifier l'état de ce problème, exécutez viocli check health -n connectivity.
LDAP inaccessible
Vérifiez la connexion des nœuds de VMware Integrated OpenStack au serveur LDAP spécifié et assurez-vous que le paramètre LDAP (utilisateur, informations d'identification) dans VMware Integrated OpenStack est correct. Pour revérifier l'état de ce problème, exécutez viocli check health -n connectivity.
vCenter inaccessible
En cas de vCenter inaccessible, vérifiez la connexion des nœuds de VMware Integrated OpenStack au vCenter spécifié et assurez-vous que le paramètre vCenter (utilisateur, informations d'identification) dans VMware Integrated OpenStack est correct. Pour revérifier l'état de ce problème, exécutez viocli check health -n connectivity.
NSX inaccessible
En cas de NSX inaccessible, vérifiez la connexion des nœuds VMware Integrated OpenStack au serveur NSX spécifié et assurez-vous que le paramètre NSX (utilisateur, informations d'identification) est correct. Pour revérifier l'état de ce problème, exécutez viocli check health -n connectivity.
- Vous devez disposer de toutes les conditions préalables énumérées dans le document Integrate VMware Integrated OpenStack with vRealize Log Insight prêt.
- Pour revérifier l'état de ce problème, exécutez
viocli check health -n connectivity.
- Assurez-vous que le serveur DNS peut communiquer avec le réseau d'accès aux API VMware Integrated OpenStack.
- Vous devez disposer de toutes les conditions préalables énumérées dans le document Enable the Designate Component.
- Pour revérifier l'état de ce problème, exécutez
viocli check health -n connectivity.
Partition du réseau inaccessible dans le nœud rabbitmq
- Pour forcer la recréation du nœud de gestion
rabbitmq, exécutez VMware Integrated OpenStack sur le nœud de gestion.#osctl delete pod ${reported_rabbitmq_node} - Pour revérifier l'état de ce problème, exécutez
viocli heath check -n rabbitmq.
Problème au niveau du cluster WSREP
viocli get deployment est En cours d'exécution. Contactez le support VIO. Sinon, suivez les instructions ci-dessous.
- Exécutez la commande suivante à partir du nœud de gestion VMware Integrated OpenStack :
#kubectl -n openstack exec -ti mariadb-server-0 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;" #kubectl -n openstack exec -ti mariadb-server-1 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;" #kubectl -n openstack exec -ti mariadb-server-2 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;"
- Si la sortie
wsrep_cluster_sizedemariadb-server-xn'est pas 3, alors recréez le nœudmariadbavec :#kubectl -n openstack delete pod mariadb-server-x
- Si un grand écart de
wsrep_last_commitedest constaté entre les trois nœuds, recommencez le nœudmariadbou les nœuds avec un plus petit nombre avecwsrep_last_committed.#kubectl -n openstack delete pod mariadb-server-x
- Pour revérifier l'état de ce problème, exécutez
viocli check health -n mariadb.
Les grandes tables dans la base de données OpenStack
nova.instancesreportez-vous à l'article KB 83768.
glance.imagesDes tâches cron sont activées par défaut pour purger automatiquement les enregistrements supprimés de manière logicielle dans la base de données Glance.
Vérifiez si la tâche cron de purge de base de données est activée et si elle s'exécute correctement.
viocli update glance jobs: db_purge: age_in_days: 60 max_rows: 1000 db_purge_images: age_in_days: 60 max_rows: 1000 manifests: cron_job_db_purge: true cron_job_db_purge_images: truecron_job_db_purgeest utilisé pour activer la purge de base de données pour la table Glance, à l'exception de la table « image ».cron_job_db_purge_imagesest utilisé pour activer la purge de base de données pour la table « image » Glance.--age_in_days NUMpurge uniquement les lignes supprimées pendant plus de NUM jours. La valeur par défaut est de 30 jours.--max_rows NUMpurge un maximum de NUM lignes de chaque tableau. La valeur par défaut est de 100.cinder.volumesetcinder.volume_attachmentÉtapes manuelles de purge de la base de données Cinder
- Sauvegardez la base de données Cinder.
osctl exec -ti mariadb-server-0 -- mysqldump --defaults-file=/etc/mysql/admin_user.cnf -R cinder > /tmp/cinder_backup.sql
- Connectez-vous à cinder-api-xxxxx pod.
osctl exec -ti deploy/cinder-api bash
- Nettoyez la base de données Cinder.
cinder-manage db purge 60
Note :utilisation de la commande : cinder-manage db purge
age_in_days.arguments de position :
age_in_daysPurgez les lignes supprimées antérieures à la durée de vie en jours.Vous devrez peut-être ajuster
age_in_dayspour nettoyer davantage d'éléments supprimés de manière logicielle dans la base de données Cinder.
Trop de ressources réseau anciennes dans le plan de contrôle
Pour la solution, voir Échec d’activer le ceilomètre quand il y a 10k réseaux de locataires neutrons dans les notes de mise à jour.VMware Integrated OpenStack 7.1
OpenStack Keystone ne fonctionne pas correctement
- Vous devez essayer de vous connecter à OpenStack à partir de la boîte à outils en tant qu'utilisateur admin et essayer d'exécuter les commandes telles que
openstack user listetopenstack user show. Si la connexion échoue, collectez et vérifiez les journaux de Keystone pour les messages d'erreur. - Obtenez la liste des pods keystone-api :
#osctl get pod | grep keystone-api
- Collectez les journaux :
#osctl logs keystone-api-xxxx -c keystone-api >keystone-api-xxxx.log
- Pour vérifier l'état de ce problème, exécutez
viocli check health -n keystone.
ID de réseau vide dans la base de données Neutron
Pour la solution, voir KB 76455. Pour vérifier l'état de ce problème, exécutez viocli check health -n neutron.
Référence vCenter erronée dans Neutron
- Obtenez le nom de
viocluster.Siosctl get viocluster
viocluster1est renvoyé, passez à l'étape suivante. Sinon, il s’agit d’une fausse alarme. Contactez le support VMware pour obtenir une solution définitive. - Obtenez la configuration de
vioclustervCenter.# osctl get viocluster viocluster1 -oyaml
- Sauvegarde de la configuration de Neutron.
osctl get neutron -oyaml > neutron-<time-now>.yml
- Modifiez la CR Neutron
cmd:osctl edit neutron neutron-xxxet ensuite changez la spécification de la CR en remplaçant la référence vCenter trouvée à l'étape 1.spec: conf: plugins: nsx: dvs: dvs_name: vio-dvs host_ip: .VCenter:vcenter812:spec.hostname <---- change the vcenter instance to viocluster refered host_password: .VCenter:vcenter812:spec.password <---- same above host_username: .VCenter:vcenter812:spec.username <---- insecure: .VCenter:vcenter812:spec.insecure <---- - Pour vérifier l'état de ce problème, exécutez
viocli check health -n neutron.
- Obtenez le pod Nova.
osctl get pod | grep nova
Vérifiez si le pod Nova n'est pas dans le statut En cours d’exécution.
- Supprimez le pod avec :
osctl delete pod xxx.Attendez le nouveau pod jusqu'à ce que son statut soit En cours d’exécution.
- Pour vérifier l'état de ce problème, exécutez
viocli check health -n nova.
Service Nova périmé
Pour le service Nova périmé, voir KB 78736. Pour vérifier l'état de ce problème, exécutez viocli check health -n nova.
- Connectez-vous à la boîte à outils et essayez de trouver et de supprimer le service Nova redondant et certains services Nova sans points de terminaison.
# openstack catalog list

# openstack service list

- Découvrez le service Nova utilisé.
# openstack endpoint list |grep nova
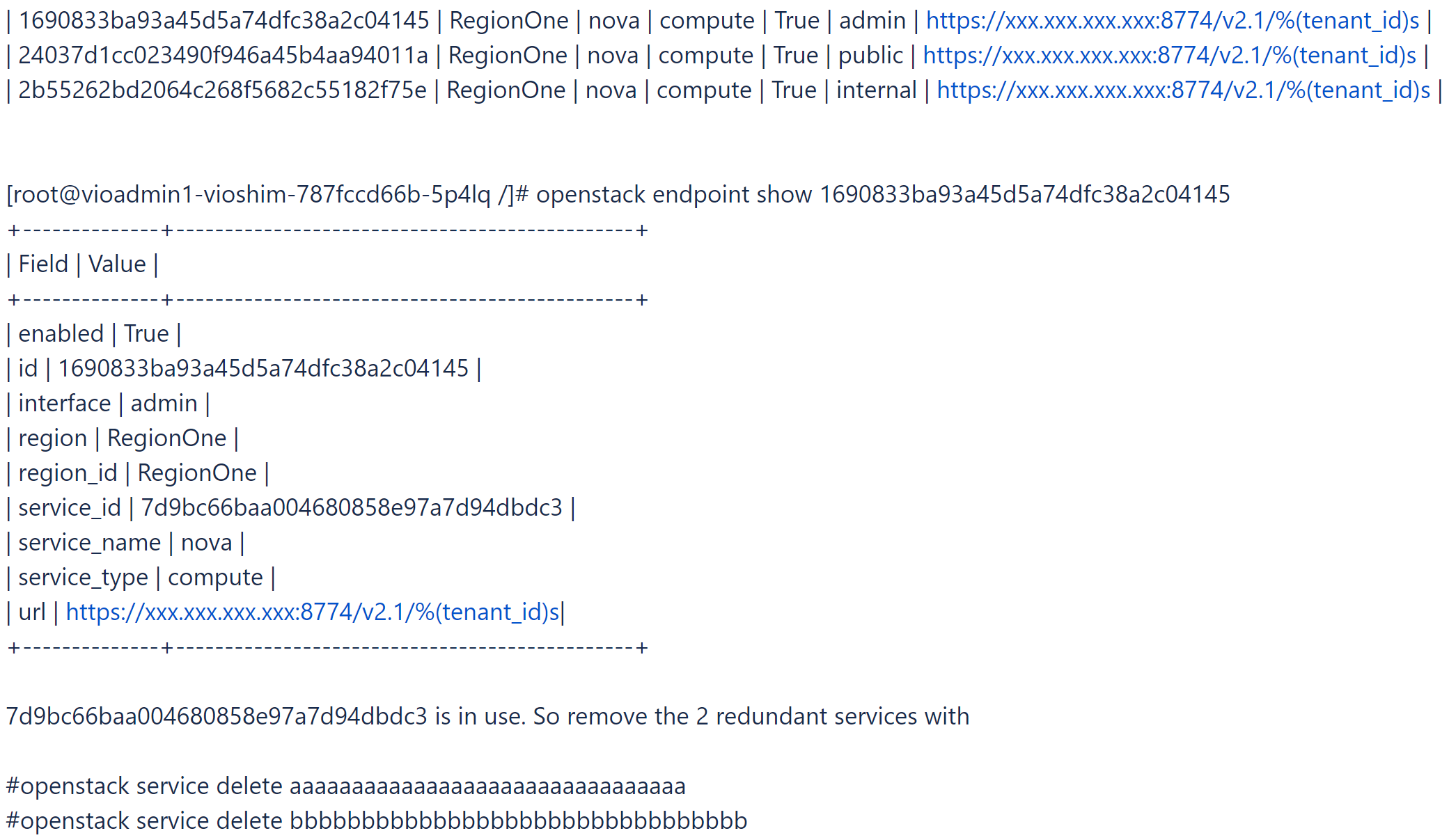
- Pour vérifier l'état de ce problème, exécutez
viocli check health -n nova.
Certains espaces de traitement Nova continuent de redémarrer en raison du délai d'expiration du démarrage
Cette alarme indique que certains espaces de traitement Nova peuvent avoir un état défectueux. Contactez le support VMware pour obtenir une solution. Pour vérifier l'état du problème, exécutez viocli check health -n nova.
Banque de données Glance inaccessible
- Obtenez la liste des services de Glance.
osctl get glance
- Obtenez des informations sur la banque de données de Glance.
osctl get glance $glance-xxx -o yaml
- Trouvez les informations de connexion au datastore.
spec: conf: backends: vmware_backend: vmware_datastores: xxxx vmware_server_host: xxxx vmware_server_password: xxxx vmware_server_username: .xxxx - Si les informations sont incorrectes, vérifiez la connexion du vCenter et de la banque de données et mettez-la à jour avec
osctl update glance $glance-xxxen conséquence. - Pour vérifier l'état de ce problème, exécutez
viocli check health -n glance.
Image(s) Glance avec un format d'emplacement incorrect
Le message indique que certaines images Glance ont un format d'emplacement incorrect. Contactez le support VMware pour obtenir une solution. Pour vérifier l'état du problème, exécutez viocli check health -n glance.
Nova Cinder en panne
- Obtenez le module Cinder.
osctl get pod | grep cinder | grep -v Completed
Vérifiez si le pod Cinder n'est pas dans le statut En cours d’exécution.
- Supprimez le pod avec :
osctl delete pod xxx.Attendez le nouveau pod jusqu'à ce que son statut soit le suivant : En cours d’exécution.
- Pour vérifier l'état de ce problème, exécutez
viocli check health -n cinder.
- Connectez-vous au
cinder-volumepod.#osctl exec -ti cinder-volume-0 bash
- Vérifiez et listez les services de Cinder périmés.
#cinder-manage service list
Par exemple :#cinder-manage service list

- Débarrassez-vous des services Cinder périmés en utilisant la commande
cinder-managedans le podcinder-volume.# cinder-manage service remove cinder-scheduler cinder-scheduler-7868dc59dc-km9mj # cinder-manage service remove cinder-volume controller01@e-muc-cb-1b-az3:172.23.48.18
- Pour vérifier l'état de ce problème, exécutez
viocli check health -n cinder.
- Pour installer la commande requise dans le nœud de gestion VMware Integrated OpenStack, exécutez
tdnf install xxx. - Pour vérifier l'état de ce problème, exécutez
viocli check health -n basic.
Liste vide de nœuds Kubernetes ou nœud inaccessible
Exécutez osctl get nodes depuis le nœud de gestion VMware Integrated OpenStack et vérifiez s'il peut capturer la sortie correcte. Pour vérifier l'état de ce problème, exécutez viocli check health -n basic.
Aucun pod en cours d'exécution
Exécutez osctl get pod |grep xxxdepuisVMware Integrated OpenStack le nœud de gestion et vérifiez s'il peut capturer un pod en cours d'exécution à partir de la sortie. Pour vérifier l'état de cette question, viocli check health -n basic.
Pod inaccessible
Exécutez osctl exec -it $pod_name bash depuis le nœud de gestion VMware Integrated OpenStack et vérifiez si vous pouvez vous connecter au pod. Pour vérifier l'état de ce problème, exécutez viocli check health -n basic.
Exécutez une commande dans un pod
Vérifiez le fichier journal /var/log/viocli_health_check.log pour obtenir des informations détaillées et essayez de réexécuter la commande depuis le nœud de gestion VMware Integrated OpenStack. Pour vérifier l'état de ce problème, exécutez viocli check health -n basic.
- Connectez-vous à la boîte à outils et exécutez quelques commandes OpenStack, par exemple,
openstack catalog listet vérifiez si la commande peut capturer le retour correct. - Pour plus de messages, ajoutez l'option debug. Par exemple :
openstack catalog list --debug
- Pour vérifier l'état de ce problème, exécutez
viocli check health -n basic.
- Obtenez le mot de passe administrateur d'openstack et comparez-le avec
OS_PASSWORD.osctl get secret keystone-keystone-admin -o jsonpath='{.data.OS_PASSWORD} - S'il n'y a pas de valeur stockée dans
keystone-keystone-admin, mettez-la à jour avecosctl edit secret keystone-keystone-admin. - Pour vérifier l'état de ce problème, exécutez
viocli check health -n basic.
Le cluster vCenter est surchargé/les hôtes sont sous pression
Vérifiez les hôtes vCenter pour le plan de contrôle VIO et ajoutez davantage de ressources, ou nettoyez certaines instances inutilisées pour réduire la pression sur les ressources.
- Consultez le journal /var/log/viocli_health_check.log et recherchez le dernier message pour
check_vio_cert_expireafin de savoir depuis combien de temps le certificat a expiré ou dans combien de temps il va expirer. - Pour mettre à jour le certificat, suivez les instructions dans Mettre à jour le certificat pour VMware Integrated OpenStack.
- Pour vérifier à nouveau l'état du problème, exécutez
viocli check health -n connectivity.
Le certificat LDAP a expiré/est sur le point d'expirer
- Consultez le journal /var/log/viocli_health_check.log et recherchez le dernier message pour
check_ldap_cert_expireafin de savoir depuis combien de temps le certificat a expiré ou dans combien de temps il va expirer. - Pour mettre à jour le certificat, suivez les instructions dans Mettre à jour le certificat pour le serveur LDAP.
Note : Si aucun LDAP n'est configuré, la vérification sera ignorée et renverra le message de journal
No LDAP Certificate found. - Pour vérifier à nouveau l'état du problème, exécutez
viocli check health -n connectivity.
Le certificat vCenter a expiré/est sur le point d'expirer
- Consultez le journal /var/log/viocli_health_check.log et recherchez le dernier message pour
check_vcenter_cert_expireafin de savoir depuis combien de temps le certificat a expiré ou dans combien de temps il va expirer. - Pour mettre à jour le certificat, suivez les instructions dans Configuration de VMware integrated OpenStack avec un certificat vCenter ou NSX-T mis à jour.
Note : Si vCenter est configuré pour utiliser une connexion non sécurisée, la vérification sera ignorée et renverra le message de journal
Use insecure connection. - Pour vérifier à nouveau l'état du problème, exécutez
viocli check health -n connectivity.
Le certificat NSX a expiré/est sur le point d'expirer
- Consultez le journal /var/log/viocli_health_check.log et recherchez le dernier message pour
check_nsx_cert_expireafin de savoir depuis combien de temps le certificat a expiré ou dans combien de temps il va expirer. - Pour mettre à jour le certificat, suivez les instructions dans Configuration de VMware integrated OpenStack avec un certificat vCenter ou NSX-T mis à jour.
Note : Si NSX est configuré pour utiliser une connexion non sécurisée, la vérification sera ignorée et renverra le message de journal
Use insecure connection. - Pour vérifier à nouveau l'état du problème, exécutez
viocli check health -n connectivity.
Service xxx arrêté
Exécutez viocli start xxx pour démarrer le service. Pour vérifier l'état de ce problème, exécutez viocli check health -n lifecycle_manager.
- Consultez le journal /var/log/viocli_health_check.log et recherchez le dernier message pour
check_cluster_workloadqui précise en détail l'utilisation des ressources. - Corrigez les problèmes de ressources signalés et vérifiez à nouveau l'état en exécutant
viocli check health -n kubernetes.
