









L'interface de ligne de commande de NSX peut servir à récupérer les journaux de suivi détaillés, à utiliser les captures de paquets et à examiner les mesures dans le cadre du dépannage de l'équilibrage de charge.
Problème
L'équilibrage de charge ne fonctionne pas comme prévu.
Solution
- Activez la connexion SSH ou vérifiez que vous pouvez vous connecter via SSH au dispositif virtuel. Edge Services Gateway est un dispositif virtuel qui a la possibilité d'activer SSH pendant le déploiement. Si vous devez activer SSH, sélectionnez le dispositif requis, puis dans le menu Actions, cliquez sur Modifier les informations d'identification CLI (Change CLI Credentials).

- Edge Services Gateway présente plusieurs commandes d'affichage qui étudient l'état de l'exécution et l'état de la configuration. Utilisez les commandes pour afficher les informations relatives à la configuration et aux statistiques.
nsxedge> show configuration loadbalancer nsxedge> show configuration loadbalancer virtual [virtual-server-name] nsxedge> show configuration loadbalancer pool [pool-name] nsxedge> show configuration loadbalancer monitor [monitor-name] nsxedge> show configuration loadbalancer profile [profile-name] nsxedge> show configuration loadbalancer rule [rule-name]
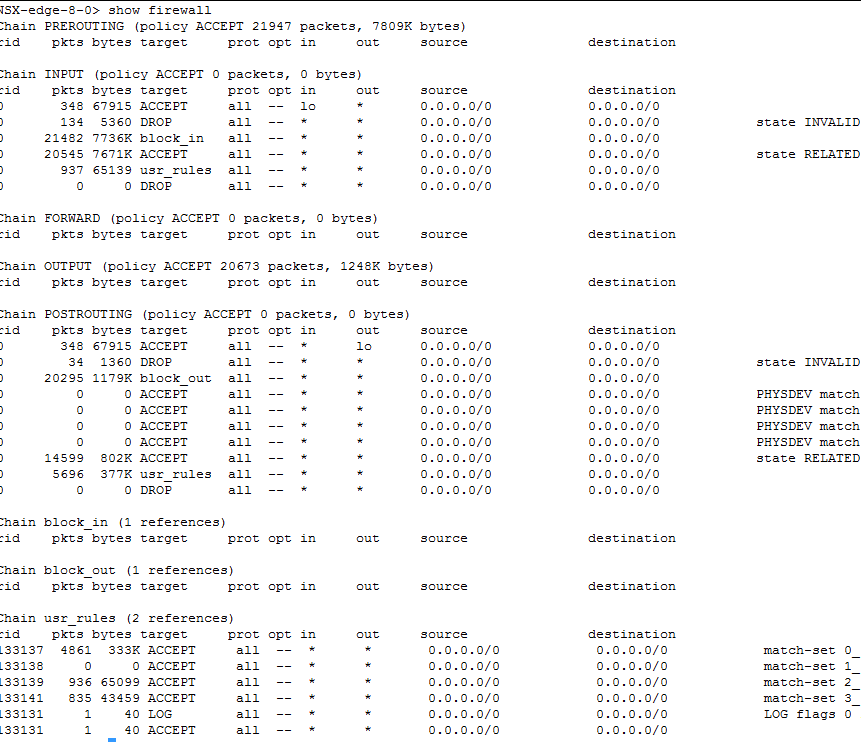
- Pour que l'équilibrage de charge et NAT fonctionnent correctement, le pare-feu doit être activé. Utilisez la commande #show firewall. Si vous ne voyez pas de sortie logique à l'aide de la commande, consultez la section Dépannage et vérification de la configuration de l'équilibrage de charge à l'aide de l'interface utilisateur.
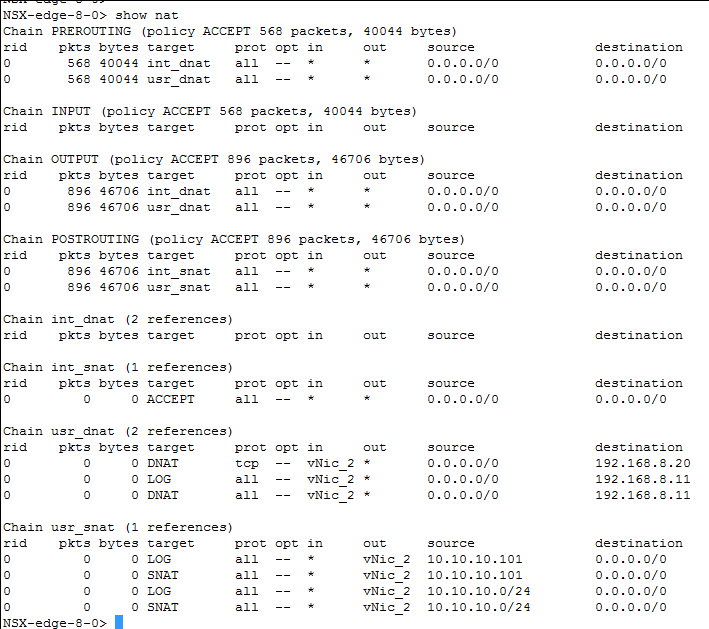
- L'équilibrage de charge requiert le bon fonctionnement du NAT. Utilisez la commande show nat. Si vous ne voyez pas de sortie logique à l'aide de la commande, consultez la section Dépannage et vérification de la configuration de l'équilibrage de charge à l'aide de l'interface utilisateur.
- En plus du pare-feu qui est activé et de l'équilibrage de charge qui possède des règles NAT, vous devez aussi vous assurer que le processus d'équilibrage de charge est activé. Utilisez la commande show service loadbalancer pour vérifier l'état du moteur de l'équilibrage de charge (L4/L7).
nsxedge> show service loadbalancer haIndex: 0 ----------------------------------------------------------------------- Loadbalancer Services Status: L7 Loadbalancer : running ----------------------------------------------------------------------- L7 Loadbalancer Statistics: STATUS PID MAX_MEM_MB MAX_SOCK MAX_CONN MAX_PIPE CUR_CONN CONN_RATE CONN_RATE_LIMIT MAX_CONN_RATE running 1580 0 2081 1024 0 0 0 0 0 ----------------------------------------------------------------------- L4 Loadbalancer Statistics: MAX_CONN ACT_CONN INACT_CONN TOTAL_CONN 0 0 0 0 Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn- Utilisez la commande show service loadbalancer session pour afficher la table de session de l'équilibrage de charge. Vous verrez des sessions s'il y a du trafic sur le système.
nsxedge> show service loadbalancer session ----------------------------------------------------------------------- L7 Loadbalancer Statistics: STATUS PID MAX_MEM_MB MAX_SOCK MAX_CONN MAX_PIPE CUR_CONN CONN_RATE CONN_RATE_LIMIT MAX_CONN_RATE running 1580 0 2081 1024 0 0 0 0 0 -----------------L7 Loadbalancer Current Sessions: 0x2192df1f300: proto=unix_stream src=unix:1 fe=GLOBAL be=<NONE> srv=<none> ts=09 age=0s calls=2 rq[f=c08200h, i=0,an=00h,rx=20s,wx=,ax=] rp[f=008000h,i=0,an=00h,rx=,wx=,ax=] s0=[7,8h,fd=1,ex=] s1=[7,0h,fd=-1,ex=] exp=19s ----------------------------------------------------------------------- L4 Loadbalancer Statistics: MAX_CONN ACT_CONN INACT_CONN TOTAL_CONN 0 0 0 0 L4 Loadbalancer Current Sessions: pro expire state source virtual destination
- Vérifiez la commande show service loadbalancer pour afficher l'état de table rémanente de couche 7 de l'équilibrage de charge. Remarquez que ce tableau n'affiche pas d'informations sur les serveurs virtuels accélérés.
nsxedge> show service loadbalancer table ----------------------------------------------------------------------- L7 Loadbalancer Sticky Table Status: TABLE TYPE SIZE(BYTE) USED(BYTE)
- Utilisez la commande show service loadbalancer session pour afficher la table de session de l'équilibrage de charge. Vous verrez des sessions s'il y a du trafic sur le système.
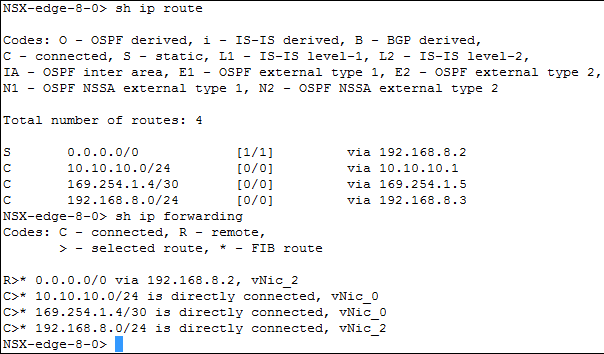
- Si tous les services requis s'exécutent correctement, étudiez la table de routage : vous devez avoir un itinéraire vers le client et vers les serveurs. Utilisez les commandes show ip route et show ip forwarding qui mappent des itinéraires avec les interfaces.
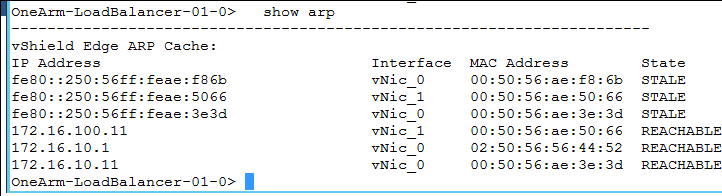
- Assurez-vous d'avoir une entrée ARP pour les systèmes, comme la passerelle ou le tronçon suivant, et les serveurs principaux à l'aide de la commande show arp.
- Les journaux donnent des informations pour aider à trouver le trafic qui pourrait aider au diagnostic des problèmes. Utilisez les commandes show log ou show log follow pour suivre le journal qui aidera à détecter le trafic. Remarquez que vous devez exécuter l'équilibrage de charge avec Journalisation (Logging) activé, et défini sur Info ou Débogage (Debug).
nsxedge> show log 2016-04-20T20:15:36+00:00 vShieldEdge kernel: Initializing cgroup subsys cpuset 2016-04-20T20:15:36+00:00 vShieldEdge kernel: Initializing cgroup subsys cpu 2016-04-20T20:15:36+00:00 vShieldEdge kernel: Initializing cgroup subsys cpuacct ... - Après avoir vérifié que les services de base s'exécutent avec les bons chemins vers les clients, regardons ce qui se passe dans la couche d'application. Utilisez la commande show service loadbalancer pool pour afficher l'état du pool de l'équilibrage de charge (L4/L7). Un membre du pool doit être en mesure du servir du contenu ; en général, plusieurs membres sont nécessaires car le volume des requêtes dépasse la capacité d'une seule charge de travail. Si la surveillance de santé est fournie par un contrôle de santé intégré, la sortie affiche heure de modification du dernier état et raison de l'échec lorsque le contrôle de santé échoue. Si la surveillance de santé est fournie par un service de surveillance, outre les deux sorties citées précédemment, l'heure du dernier contrôle s'affiche aussi.
nsxedge> show service loadbalancer pool ----------------------------------------------------------------------- Loadbalancer Pool Statistics: POOL Web-Tier-Pool-01 | LB METHOD round-robin | LB PROTOCOL L7 | Transparent disabled | SESSION (cur, max, total) = (0, 0, 0) | BYTES in = (0), out = (0) +->POOL MEMBER: Web-Tier-Pool-01/web-01a, STATUS: UP | | HEALTH MONITOR = BUILT-IN, default_https_monitor:L7OK | | | LAST STATE CHANGE: 2016-05-16 07:02:00 | | SESSION (cur, max, total) = (0, 0, 0) | | BYTES in = (0), out = (0) +->POOL MEMBER: Web-Tier-Pool-01/web-02a, STATUS: UP | | HEALTH MONITOR = BUILT-IN, default_https_monitor:L7OK | | | LAST STATE CHANGE: 2016-05-16 07:02:01 | | SESSION (cur, max, total) = (0, 0, 0) | | BYTES in = (0), out = (0) - Vérifiez l'état de la surveillance des services (OK, WARNING, CRITICAL) pour voir la santé de tous les serveurs principaux configurés.
nsxedge> show service loadbalancer monitor ----------------------------------------------------------------------- Loadbalancer Health Check Statistics: MONITOR PROVIDER POOL MEMBER HEALTH STATUS built-in Web-Tier-Pool-01 web-01a default_https_monitor:L7OK built-in Web-Tier-Pool-01 web-02a default_https_monitor:L7OKPour la commande show service load balancer monitor, trois types de valeurs de surveillance de santé sont affichés dans la sortie de l'interface de ligne de commande :- Intégré : la surveillance de santé est activée et est réalisée par le moteur L7 (proxy HA).
- Service de surveillance : la surveillance de santé est activée et est réalisée par le moteur du service de surveillance (NAGIOS). L'état d'exécution du service de surveillance peut être vérifié avec les commandes de l'interface de ligne de commande
show service monitoretshow service monitor service. Le champ État (Status) doit être OK, AVERTISSEMENT ou CRITIQUE. - Non défini : la surveillance de santé est désactivée.
Tableau 1. État de santé avec une description État de santé Description Intégré - UNK : inconnu
- INI : initialisation
- SOCKERR : erreur de socket
- L4OK : vérification effectuée sur la couche 4, aucun test de couche supérieure activé
- L4TOUT : expiration de la couche 1 à 4
- L4CON : problème de connexion de la couche 1 à 4. Par exemple, « Connexion refusée » (tcp rst) ou « Aucun itinéraire vers l'hôte » (icmp)
- L6OK : vérification effectuée sur la couche 6
- L6TOUT : expiration de la couche 6 (SSL)
- L6RSP : réponse incorrecte de la couche 6 - erreur de protocole. Peut survenir parce que :
- le serveur principal prend uniquement en charge « SSLv3 » ou « TLSv1.0 », ou
- le certificat du serveur principal n'est pas valide, ou
- la négociation du chiffrement a échoué, etc
- L7OK : vérification effectuée sur la couche 7
- L7OKC : vérification effectuée sous condition sur la couche 7. Par exemple, 404 avec disable-on-404
- L7TOUT : expiration de la couche 7 (HTTP/SMTP)
- L7RSP : réponse incorrecte de la couche 7 - erreur de protocole
- L7STS : erreur de réponse de la couche 7. Par exemple, HTTP 5xx
CRITIQUE - La version 2 du protocole SSL n'est pas prise en charge par votre bibliothèque SSL
- Version du protocole SSL non prise en charge
- Impossible de créer le contexte SSL
- Impossible d'établir une connexion SSL
- Impossible d'initier la négociation SSL
- Impossible de récupérer le certificat de serveur
- Impossible de récupérer le sujet du certificat
- Format d'heure incorrect dans le certificat
- Le certificat « <cn> » a expiré le <expire time of certificate>
- Le certificat « <cn> » a expiré aujourd'hui <expire time of certificate>
AVERTISSEMENT/CRITIQUE Le certificat « <cn> » expire dans <days_left/expire time of certificate> jour(s)
ICMP - Réseau inaccessible
- Hôte inaccessible
- Protocole inaccessible
- Port inaccessible
- Échec de l'itinéraire source
- Hôte source isolé
- Réseau inconnu
- Hôte inconnu
- Réseau refusé
- Hôte refusé
- Type de service (ToS) incorrect pour le réseau
- Type de service (ToS) incorrect pour l'hôte
- Interdit par le filtre
- Violation de la priorité d'hôte
- Limite de priorité. Niveau minimal de priorité requis pour l'opération
- Code non valide
UDP/TCP - Échec de la création du socket
- Connexion à l'adresse xxxx et au port xxx : [consultez Code d'erreur Linux]
- Aucune donnée reçue de l'hôte
- Réponse inattendue de la part de l'hôte/socket
HTTP/HTTPS - HTTP INCONNU : erreur d'allocation de mémoire
- HTTP CRITIQUE : impossible d'ouvrir le socket TCP (échec de la création du socket ou de la connexion au serveur)
- HTTP CRITIQUE : erreur lors de la réception des données
- HTTP CRITIQUE : aucune donnée reçue de l'hôte
- HTTP CRITIQUE : réponse HTTP non valide reçue de la part de l'hôte : <status line> (format de ligne de format attendu incorrect)
- HTTP CRITIQUE : ligne d'état non valide <status line> (le code d'état ne contient pas 3 chiffres : XXX)
- HTTP CRITIQUE : état non valide <status line> (code d'état >= 600 ou < 100)
- HTTP CRITIQUE : chaîne introuvable
- HTTP CRITIQUE : modèle introuvable
- HTTP AVERTISSEMENT : taille de page <page_length> trop grande
- HTTP AVERTISSEMENT : taille de page <page_length> trop petite
- Lorsque le code d'erreur est L4TOUT/L4CON, c'est qu'il y a généralement des problèmes de connectivité sur la mise en réseau sous-jacente. Duplicate IP se produit souvent comme cause première avec ce type de raison. Lorsque cette erreur se produit, le dépannage se présente comme suit :
- Vérifiez l'état de Haute disponibilité (HA) des Edge, lorsque la haute disponibilité est activée à l'aide de la commande show service highavailability sur les deux Edge. Vérifiez si le lien Haute disponibilité est DÉSACTIVÉ et si tous les Edges sont Active, pour qu'il n'y ait plus d'IP Edge en doublon sur le réseau.
- Vérifiez la table ARP Edge par la commande show arp et vérifiez si l'entrée ARP du serveur principal est modifiée entre les deux adresses MAC.
- Vérifiez la table ARP du serveur principal ou utilisez la commande arp-ping, puis vérifiez si une autre machine à la même IP que l'IP Edge.
- Vérifiez les statistiques de l'objet d'équilibrage de charge (VIP, pools, membres). Regardez le pool spécifique et vérifiez que les membres sont prêts et exécutés. Vérifiez si le mode transparent est activé. Si oui, Edge Services Gateway doit être en ligne entre le client et le serveur. Vérifiez si les serveurs affichent les incréments de compteur de sessions.
nsxedge> show service loadbalancer pool Web-Tier-VIP-01 TIMESTAMP SESSIONS BYTESIN BYTESOUT SESSIONRATE HTTPREQS 2016-04-27 19:56:40 00 00 00 00 00 2016-04-27 19:55:00 00 32 100 00 00nsxedge> show service loadbalancer pool Web-Tier-VIP-01 | MEMBER +—> POOL MEMBER: TENANT-1-TCP-POOL-80/SERVER-1, STATUS: UP +—> POOL MEMBER: TENANT-1-TCP-POOL-80/SERVER-2, STATUS: UP
- Étudiez à présent le serveur virtuel et vérifiez s'il y a un pool par défaut et voyez si le pool y est lié aussi. Si vous utilisez des pools via des règles d'application, vous devez étudier de plus près des pools spécifiques comme illustré dans la commande #show service loadbalancer pool. Spécifiez le nom du serveur virtuel.
nsxedge> show service loadbalancer virtual Web-Tier-VIP-01 ----------------------------------------------------------------------- Loadbalancer VirtualServer Statistics: VIRTUAL Web-Tier-VIP-01 | ADDRESS [172.16.10.10]:443 | SESSION (cur, max, total) = (0, 0, 0) | RATE (cur, max, limit) = (0, 0, 0) | BYTES in = (0), out = (0) +->POOL Web-Tier-Pool-01 | LB METHOD round-robin | LB PROTOCOL L7 | Transparent disabled | SESSION (cur, max, total) = (0, 0, 0) | BYTES in = (0), out = (0) +->POOL MEMBER: Web-Tier-Pool-01/web-01a, STATUS: UP | | HEALTH MONITOR = BUILT-IN, default_https_monitor:L7OK | | | LAST STATE CHANGE: 2016-05-16 07:02:00 | | SESSION (cur, max, total) = (0, 0, 0) | | BYTES in = (0), out = (0) +->POOL MEMBER: Web-Tier-Pool-01/web-02a, STATUS: UP | | HEALTH MONITOR = BUILT-IN, default_https_monitor:L7OK | | | LAST STATE CHANGE: 2016-05-16 07:02:01 | | SESSION (cur, max, total) = (0, 0, 0) | | BYTES in = (0), out = (0) - Si tout a l'air d'être configuré correctement et que vous avez encore une erreur, vous devez capturer le trafic pour comprendre ce qu'il se passe. Il y a deux connexions : entre client et serveur virtuel, et entre Edge Services Gateway et le pool principal (avec ou sans la configuration transparente au niveau du pool). La commande #show ip forwarding a indiqué les interfaces vNIc et vous pouvez utiliser ces données.
Par exemple, supposez que l'ordinateur client est sur vNic_0 et que le serveur est sur vNic_1. Vous utilisez l'adresse IP cliente 192.168.1.2 et l'adresse IP VIP 192.168.2.2 exécutées sur le port 80. IP de l'interface de l'équilibrage de charge et un serveur principal IP de 192.168.3.3. Il existe deux commandes de capture de paquets différentes : une qui affiche les paquets alors que l'autre capture les paquets dans le fichier à télécharger. Capturez les paquets pour détecter l'échec anormal de l'équilibrage de charge. Vous pouvez capturer les paquets à partir de deux directions :
- Capturer les paquets du client.
- Capturer les paquets envoyés au serveur principal.
#debug packet capture interface interface-name [filter using _ for space]- creates a packet capture file that you can download #debug packet display interface interface-name [filter using _ for space]- outputs packet data to the console #debug show files - to see a list of packet capture #debug copy scp user@url:path file-name/all - to download the packet capture
Par exemple :- Capture sur vNIC_0 :
debug packet display interface vNic_0
- Capture sur toutes les interfaces :
debug packet display interface any
- Capture sur vNIC_0 avec un filtre :
debug packet display interface vNic_0 host_192.168.11.3_and_host_192.168.11.41 - Une capture de paquet du client vers le trafic du serveur virtuel :
#debug packet display|capture interface vNic_0 host_192.168.1.2_and_host_192.168.2.2_and_port_80 - Une capture de paquet entre Edge Services Gateway et le serveur où le pool est en mode transparent :
#debug packet display|capture interface vNic_1 host 192.168.1.2_and_host_192.168.3.3_and_port_80 - Une capture de paquet entre Edge Services Gateway et le serveur n'est pas en mode transparent :
#debug packet display|capture interface vNic_1 host 192.168.3.1_and_host_192.168.3.3_and_port_80
