









NSX prend en charge les déploiements multisites dans lesquels vous pouvez gérer tous les sites d'un cluster NSX Manager.
- Récupération d'urgence
- Actif-Actif
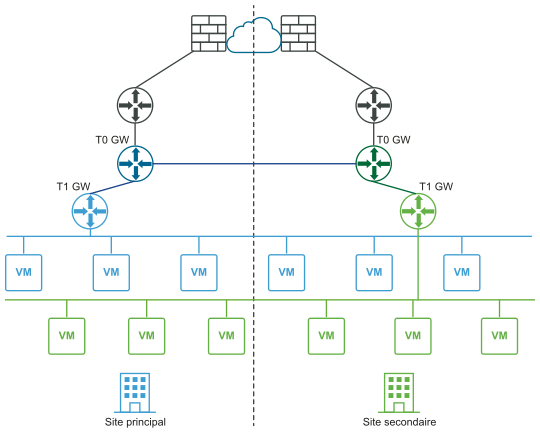
Le schéma suivant illustre un déploiement de récupération d'urgence.
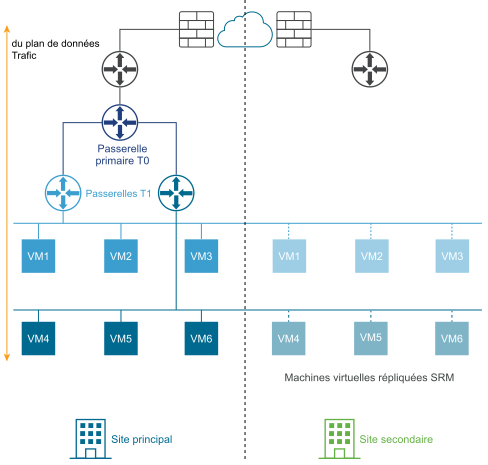
Dans un déploiement de récupération d'urgence, NSX sur le site principal gère la mise en réseau de l'entreprise. Le site secondaire est prêt à prendre le relais en cas de défaillance irrémédiable sur le site principal.
Le schéma suivant illustre un déploiement actif-actif.
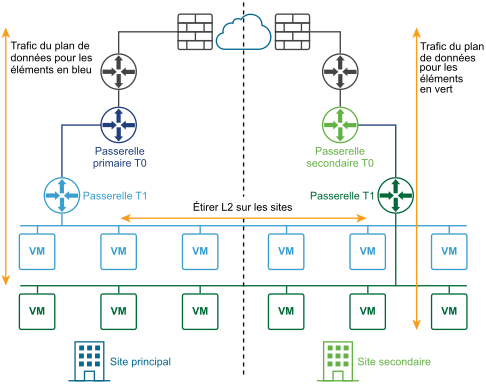
Vous pouvez déployer deux sites pour une récupération automatique ou manuelle/basée sur un script du plan de gestion et du plan de données.
Récupération automatique du plan de gestion
- Un cluster vCenter étendu avec haute disponibilité (HA) sur les sites configurés.
- Un VLAN de gestion étendu.
Le cluster NSX Manager est déployé sur le VLAN de gestion et se trouve physiquement dans le site principal. En cas de panne d'un site principal, vSphere HA redémarre les instances de NSX Manager sur le site secondaire. Tous les nœuds de transport se reconnectent automatiquement aux instances de NSX Manager redémarrées. Ce processus dure environ 10 minutes. Pendant ce temps, le plan de gestion n'est pas disponible, mais il n'y a aucun impact sur le plan de données.
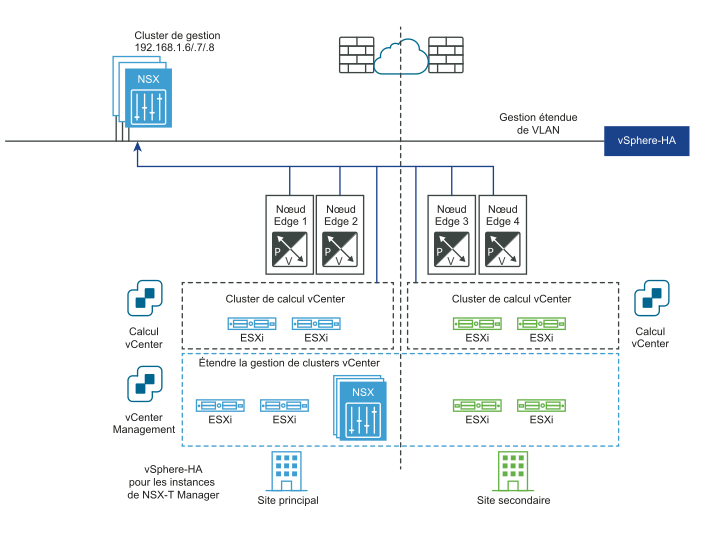
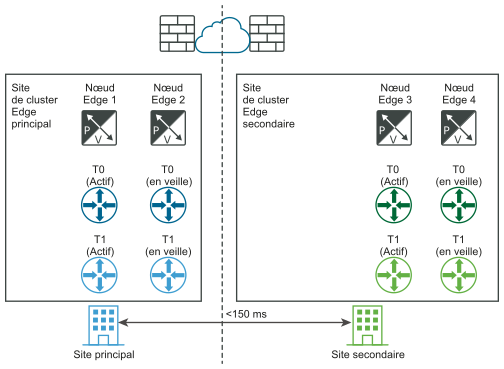
Les diagrammes suivants illustrent la récupération automatique du plan de gestion.
Avant le sinistre :
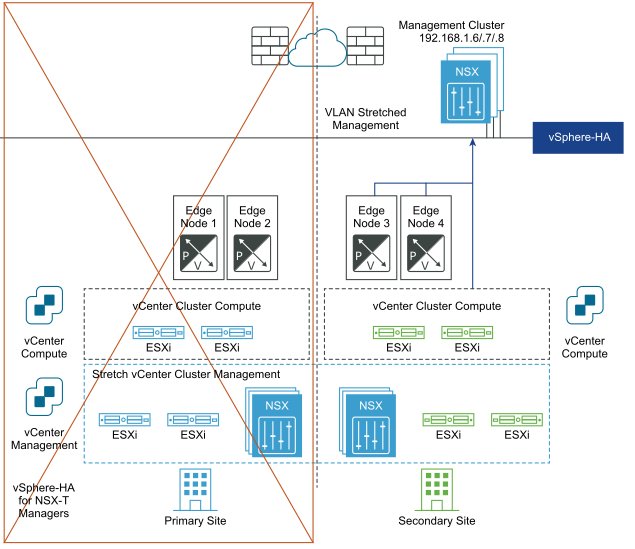
Après la récupération d'urgence :
Récupération automatique du plan de données
Pour réaliser la récupération automatique du plan de données, vous pouvez configurer des domaines de pannes pour les nœuds Edge. Vous pouvez regrouper des nœuds Edge dans un cluster Edge dans différents domaines de pannes. NSX Manager place automatiquement toutes les nouvelles passerelles de niveau 1 actives dans le domaine de pannes préféré et la passerelle de niveau 1 en veille dans l'autre domaine. Les passerelles de niveau 1 déployées avant les créations de domaines de pannes conservent leur placement de nœud Edge d'origine et peuvent ne pas s'exécuter où vous le souhaitez. Si vous souhaitez corriger leur positionnement, modifiez le T1 et sélectionnez manuellement les nœuds Edge pour les passerelles de niveau 1 actives et en veille.
- La latence maximale entre les nœuds Edge est de 10 ms.
- Si le routage nord-sud asymétrique n'est pas réalisable, par exemple un pare-feu physique est utilisé en direction du nord vers le nœud NSX Edge, le mode VMware HA de la passerelle de niveau 0 doit être actif-en veille et le mode de basculement doit être préemptif.
- Si le routage nord-sud asymétrique est possible, par exemple, les deux emplacements sont deux bâtiments sans pare-feu physique entre eux, le mode VMware HA de la passerelle de niveau 0 peut être actif-actif.
Les nœuds Edge peuvent être des machines virtuelles ou Bare Metal. Le mode de basculement de la passerelle de niveau 1 peut être préemptif ou non. Toutefois, le mode préemptif est recommandé pour garantir le même emplacement pour les passerelles de niveau 0 et de niveau 1.
- À l'aide de l'API, créez des domaines de panne pour les deux sites, par exemple FD1A-Preferred_Site1 et FD2A-Preferred_Site1. Définissez le paramètre preferred_active_edge_services sur
truepour le site principal et définissez-le surfalsepour le site secondaire.POST /api/v1/failure-domains { "display_name": "FD1A-Preferred_Site1", "preferred_active_edge_services": "true" } POST /api/v1/failure-domains { "display_name": "FD2A-Preferred_Site1", "preferred_active_edge_services": "false" } - À l'aide de l'API, configurez un cluster Edge que vous avez étendu sur les deux sites. Par exemple, le cluster dispose de nœuds Edge EdgeNode1A et EdgeNode1B dans le site principal, et des nœuds Edge EdgeNode2A et EdgeNode2B dans le site secondaire. Les passerelles de niveau 0 et de niveau 1 actives s'exécutent sur EdgeNode1A et EdgeNode1B. Les passerelles de niveau 0 et de niveau 1 en veille s'exécutent sur EdgeNode2A et EdgeNode2B.
- À l'aide de l'API, associez chaque nœud Edge au domaine de pannes du site. Pour obtenir les données sur le nœud Edge, exécutez l'API
GET /api/v1/transport-nodes/<transport-node-id>. Utilisez le résultat de l'API GET comme entrée pour l'APIPUT /api/v1/transport-nodes/<transport-node-id>, avec la propriété, failure_domain_id, définie de manière appropriée. Par exemple,GET /api/v1/transport-nodes/<transport-node-id> Response: "resource_type": "TransportNode", "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... } PUT /api/v1/transport-nodes/<transport-node-id> { "resource_type": "TransportNode", "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... "failure_domain_id": "<UUID>", } - À l'aide de l'API, configurez le cluster Edge pour allouer des nœuds en fonction du domaine de pannes. Pour obtenir les données sur le cluster Edge, exécutez l'API
GET /api/v1/edge-clusters/<edge-cluster-id>. Utilisez le résultat de l'API GET comme entrée pour l'APIPUT /api/v1/edge-clusters/<edge-cluster-id>, avec la propriété supplémentaire, allocation_rules, définie de manière appropriée. Par exemple,GET /api/v1/edge-clusters/<edge-cluster-id> Response: { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... } PUT /api/v1/edge-clusters/<edge-cluster-id> { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... "allocation_rules": [ { "action": { "enabled": true, "action_type": "AllocationBasedOnFailureDomain" } } ], } - Créez des passerelles de niveau 0 et de niveau 1 à l'aide de l'API ou de l'interface utilisateur de NSX Manager.
En cas de panne complète d'un site principal, les passerelles de niveau 0 et de niveau 1 en veille dans le site secondaire prennent automatiquement le relais et deviennent les nouvelles passerelles actives.
Les diagrammes suivants illustrent la récupération automatique du plan de données.
Avant le sinistre :
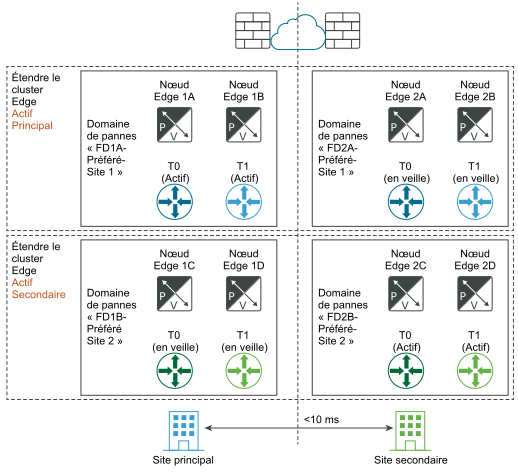
Après la récupération d'urgence :
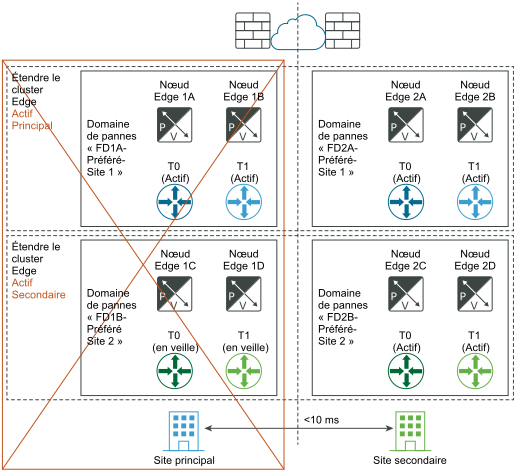
En cas de panne de l'un des nœuds Edge du site principal et pas d'une panne totale du site, il est important que le même principe s'applique. Par exemple, dans le diagramme « Avant le sinistre », supposons que le nœud Edge 1B héberge le niveau 1 bleu actif et que le nœud Edge 2B héberge le niveau 1 bleu en veille. Si le nœud Edge 1B échoue, la passerelle bleue de niveau 1 en veille sur le nœud Edge 2B prend le relais et devient la nouvelle passerelle active de niveau 1 bleue.
Récupération manuelle/basée sur un script du plan de gestion
- DNS pour NSX Manager avec une durée de vie courte (par exemple, 5 minutes).
- Sauvegarde NSX Manager continue.
Ni vSphere HA ni un VLAN de gestion étiré n'est requis. Les gestionnaires NSX doivent être associés à un nom DNS avec une durée de vie courte. Tous les nœuds de transport (nœuds Edge et hyperviseurs) doivent se connecter au NSX Manager à l'aide de leur nom DNS. Pour gagner du temps, vous pouvez éventuellement pré-installer un cluster NSX Manager sur le site secondaire.
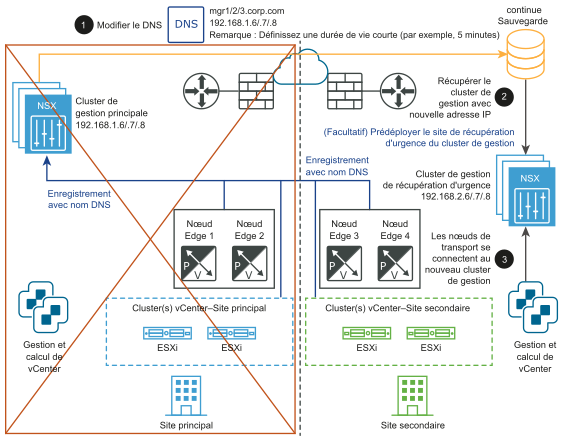
- Modifiez l'enregistrement DNS pour que le cluster NSX Manager possède différentes adresses IP.
- Restaurez le cluster NSX Manager depuis une sauvegarde.
- Connectez les nœuds de transport vers le nouveau cluster NSX Manager.
Les schémas suivants illustrent la récupération manuelle/basée sur un script du plan de gestion.
Avant le sinistre :
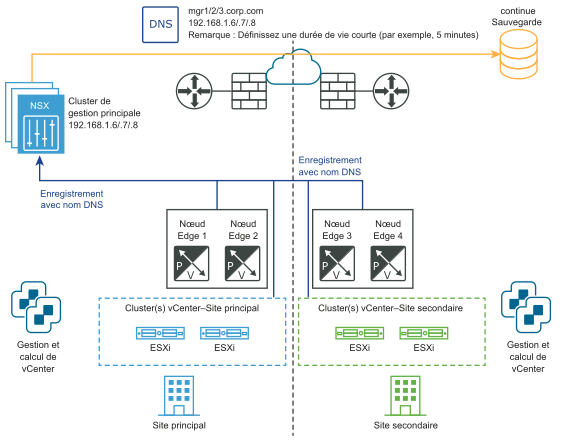
Après le sinistre :
Récupération manuelle/basée sur un script du plan de données
Configuration requise : la latence maximale entre les nœuds Edge est de 150 ms.
Les nœuds Edge peuvent être des machines virtuelles ou Bare Metal. Les passerelles de niveau 0 à chaque emplacement peuvent être actives-en veille ou actives-actives. Vous pouvez installer des machines virtuelles de nœud Edge dans différents serveurs vCenter. Aucun vSphere HA n'est requis.
- Pour tous les niveaux 1 du site principal (bleu), mettez à jour leur configuration de cluster Edge pour qu'elle soit le site de cluster Edge secondaire.
- Pour tous les niveaux 1 du site principal (bleu), reconnectez-les au site secondaire de niveau 0 (vert).
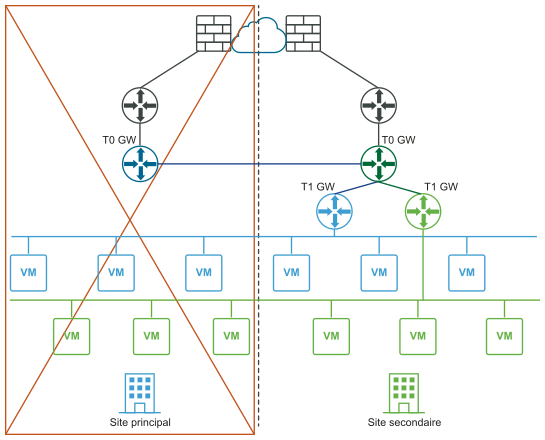
Les schémas suivants illustrent la récupération manuelle/basée sur un script du plan de données avec les vues de réseau logique et physique.
Avant le sinistre (vues logique et physique) :
Après le sinistre (vues logique et physique) :
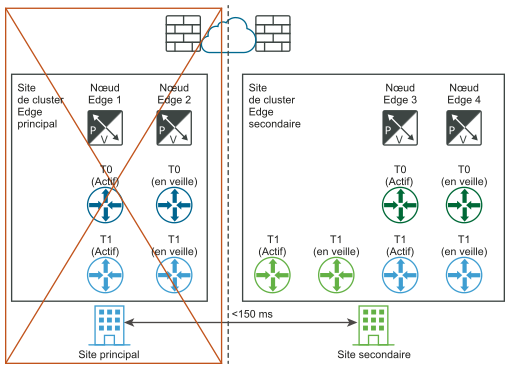
Configuration requise pour les déploiements multisites
- La bande passante doit être supérieure ou égale à 1 Gbit/s et la latence (RTT) doit être inférieure à 150 ms.
- Définissez le MTU sur 9000. Il doit être d'au moins 1600.
- Avec la récupération automatique du plan de gestion avec la gestion VLAN étendue entre les sites. vSphere HA sur les sites pour les VM NSX Manager.
- Avec la récupération manuelle/basée sur un script du plan de gestion avec la gestion VLAN étendue entre les sites. VMware SRM pour les VM NSX Manager.
- Avec récupération manuelle/scriptée du plan de gestion sans gestion VLAN étendue entre les sites.
- Sauvegarde NSX Manager continue.
- NSX Manager doit être configuré pour utiliser le nom de domaine complet.
- Le même fournisseur internet doit être utilisé si les adresses IP publiques sont exposées via des services tels que NAT ou l'équilibreur de charge.
- Avec récupération automatique du plan de gestion
- La latence maximale entre les emplacements est de 10 ms.
- Le mode HA pour la passerelle de niveau 0 doit être actif-en veille et le mode de basculement doit être préemptif pour garantir l'absence de routage asymétrique.
- Le mode HA de la passerelle de niveau 0 peut être actif-actif si le routage asymétrique est acceptable (par exemple, différents bâtiments dans une région métropolitaine).
- Avec récupération manuelle/scriptée du plan de gestion
- La latence maximale entre les emplacements est de 150 ms.
- Le CMS doit prendre en charge un plug-in NSX. Dans cette version, VMware Integrated OpenStack (VIO) et vRealize Automation (vRA) répondent à cette exigence.
Limitations
- Aucune capacité de sortie locale. Tout le trafic nord-sud doit se produire au sein d'un site.
- Le logiciel de récupération d'urgence de calcul doit prendre en charge NSX, par exemple, VMware Site Recovery Manager 8.1.2 ou version ultérieure.
- Lors de la restauration de NSX Manager dans un environnement multisite, procédez comme suit sur le site secondaire/principal :
- Une fois que le processus de restauration s'est arrêté à l'étape Ajouter un nœud à un cluster, avant d'ajouter des nœuds de gestion, vous devez d'abord supprimer l'adresse IP virtuelle existante et définir la nouvelle adresse IP virtuelle à partir de la page de l'interface utilisateur.
- Ajoutez de nouveaux nœuds à un cluster à un nœud restauré après les mises à jour de l'adresse IP virtuelle.
