









En tant qu'administrateur ou développeur DevOps, vous pouvez créer des scripts personnalisés qui étendent la capacité de Code Stream.
Avec votre script, vous pouvez intégrer Code Stream à vos propres outils et API d'intégration continue (CI) et de prestation continue (CD) qui génèrent, testent et déploient vos applications. Les scripts personnalisés sont particulièrement utiles si vous n'exposez pas publiquement vos API d'application.
Votre script personnalisé peut effectuer presque toutes les opérations nécessaires à l'intégration de vos outils de génération, de test et de déploiement à Code Stream. Par exemple, votre script peut utiliser l'espace de travail de votre pipeline pour prendre en charge les tâches d'intégration continue qui génèrent et testent votre application, ainsi que les tâches de livraison continue qui la déploient. Il peut envoyer un message à Slack lorsqu'un pipeline se termine, et bien plus encore.
L'espace de travail de pipeline Code Stream prend en charge Docker et Kubernetes pour les tâches d'intégration continue et les tâches personnalisées.
Pour plus d'informations sur la configuration de l'espace de travail, consultez Configuration de l'espace de travail de pipeline.
Vous écrivez votre script personnalisé dans l'un des langages pris en charge. Dans le script, vous incluez votre logique métier, et définissez des entrées et des sorties. Les types de sorties peuvent inclure un nombre, une chaîne, un texte et un mot de passe. Vous pouvez créer plusieurs versions d'un script personnalisé avec une logique d'activité, une entrée et une sortie différentes.
Les scripts que vous créez résident dans votre instance de Code Stream. Vous pouvez importer du code YAML pour créer une intégration personnalisée ou exporter votre script sous la forme d'un fichier YAML à utiliser dans une autre instance de Code Stream.
Votre pipeline exécute une version publiée de votre script dans une tâche personnalisée. Si vous disposez de plusieurs versions publiées, vous pouvez définir l'une d'elles comme la plus récente afin qu'elle s'affiche avec l'étiquette dernière --> lorsque vous sélectionnez la tâche personnalisée.
Lorsqu'un pipeline utilise une intégration personnalisée et que vous tentez de supprimer cette intégration, un message d'erreur s'affiche indiquant que vous ne pouvez pas la supprimer.
La suppression d'une intégration personnalisée supprime toutes les versions de votre script personnalisé. Si vous disposez d'un pipeline existant incluant une tâche personnalisée qui utilise une version du script, ce pipeline va échouer. Pour vous assurer que les pipelines existants n'échouent pas, vous pouvez déconseiller et retirer la version de votre script que vous ne souhaitez plus utiliser. Si aucun pipeline n'utilise cette version, vous pouvez la supprimer.
| Actions… | Plus d'informations sur cette action… |
|---|---|
| Ajout d'une tâche personnalisée à votre pipeline. |
La tâche personnalisée :
|
| Sélection de votre script dans la tâche personnalisée. |
Vous déclarez les propriétés d'entrée et de sortie dans le script. |
| Enregistrement de votre pipeline, avant activation et exécution. |
Lorsque le pipeline s'exécute, la tâche personnalisée appelle la version du script spécifié et y exécute la logique métier, ce qui intègre votre outil de génération, de test et de déploiement à Code Stream. |
| Une fois votre pipeline exécuté, observation des exécutions. |
Vérifiez que le pipeline a fourni les résultats attendus. |
Lorsque vous utilisez une tâche personnalisée qui appelle une version d'intégration personnalisée, vous pouvez inclure des variables d'environnement personnalisées sous forme de paires nom-valeur dans l'onglet Espace de travail du pipeline. Lorsque l'image de générateur crée le conteneur d'espace de travail qui exécute la tâche CI et déploie votre image, Code Stream transmet les variables d'environnement à ce conteneur.
Par exemple, lorsque votre instance de Code Stream nécessite un proxy Web et que vous utilisez un hôte Docker pour créer un conteneur pour une intégration personnalisée, Code Stream exécute le pipeline et transmet les variables de configuration de proxy Web à ce conteneur.
| Nom | Valeur |
|---|---|
| HTTPS_PROXY | http://10.0.0.255:1234 |
| https_proxy | http://10.0.0.255:1234 |
| NO_PROXY | 10.0.0.32, *.dept.vsphere.local |
| no_proxy | 10.0.0.32, *.dept.vsphere.local |
| HTTP_PROXY | http://10.0.0.254:1234 |
| http_proxy | http://10.0.0.254:1234 |
| PATH | /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin |
Les paires nom-valeur s'affichent dans l'interface utilisateur de la manière suivante :
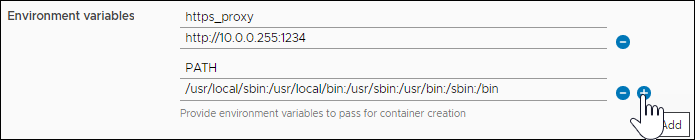
Cet exemple crée une intégration personnalisée qui connecte Code Stream à votre instance Slack et publie un message sur un canal Slack.
Conditions préalables
- Pour écrire votre script personnalisé, vérifiez que vous disposez de l'un des langages suivants : Python 2, Python 3, Node.js ; ou de l'un des langages Shell suivants : bash, sh ou zsh.
- Générez une image de conteneur à l'aide du composant d'exécution Node.js ou Python installé.
Procédure
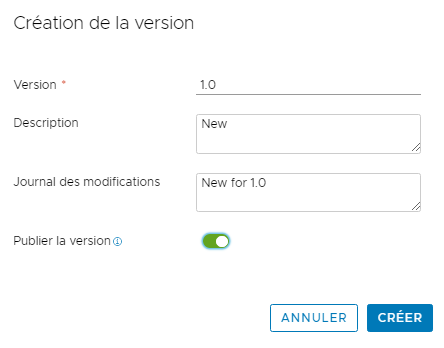
- Appliquez une version à votre script d'intégration personnalisé.
- Cliquez sur Version.
- Entrez les informations relatives à la version.
- Cliquez sur Version pour pouvoir sélectionner le script dans votre tâche personnalisée.
- Pour créer la version, cliquez sur Créer.
- (Facultatif) Vous pouvez définir n'importe quelle version publiée d'un script d'intégration personnalisée comme étant la plus récente afin que la version s'affiche avec l'étiquette dernière --> sur le canevas du pipeline.
- Placez le pointeur en haut du canevas, puis cliquez sur Historique des versions.
- Pour afficher les actions disponibles, cliquez sur les points de suspension horizontaux de la version souhaitée et sélectionnez Définir comme la plus récente.
Note : Seules les versions publiées s'affichent avec l'action Définir comme la plus récente.
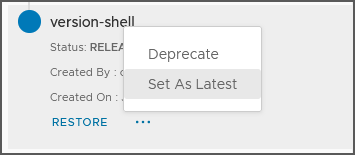
- Pour confirmer la sélection de la version, cliquez sur Définir comme la plus récente.
- Pour quitter l'Historique des versions et revenir au canevas de l'éditeur de script, cliquez sur la flèche Précédent.
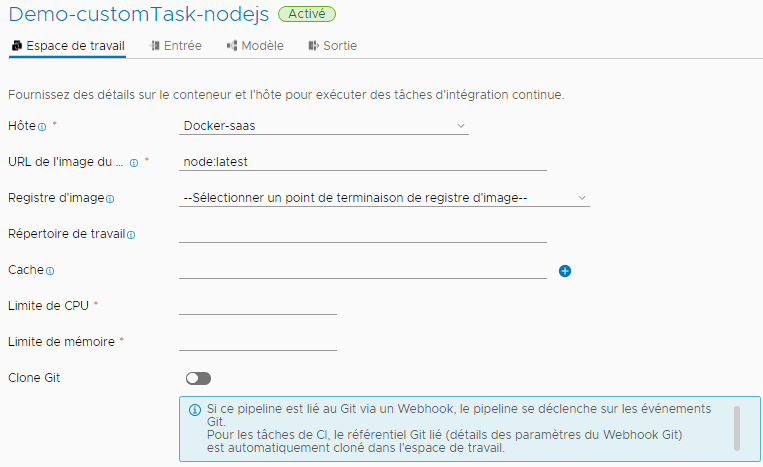
- Dans votre pipeline, configurez l'espace de travail.
Cet exemple utilise un espace de travail Docker.
- Cliquez sur l'onglet Espace de travail.
- Sélectionnez l'hôte Docker et l'URL de l'image du générateur.
- Ajoutez une tâche personnalisée à votre pipeline et configurez-la.
- Cliquez sur l'onglet Modèle.
- Ajoutez une tâche, sélectionnez le type personnalisé et entrez un nom pertinent.
- Sélectionnez votre script d'intégration personnalisé et sa version. Si une version du script a été définie comme la dernière version, cette version s'affiche avec l'étiquette dernière --> avant le nom de la version.
- Pour afficher un message personnalisé dans Slack, entrez le texte du message.
Tout texte que vous entrez remplace la
defaultValuedans votre script d'intégration personnalisé.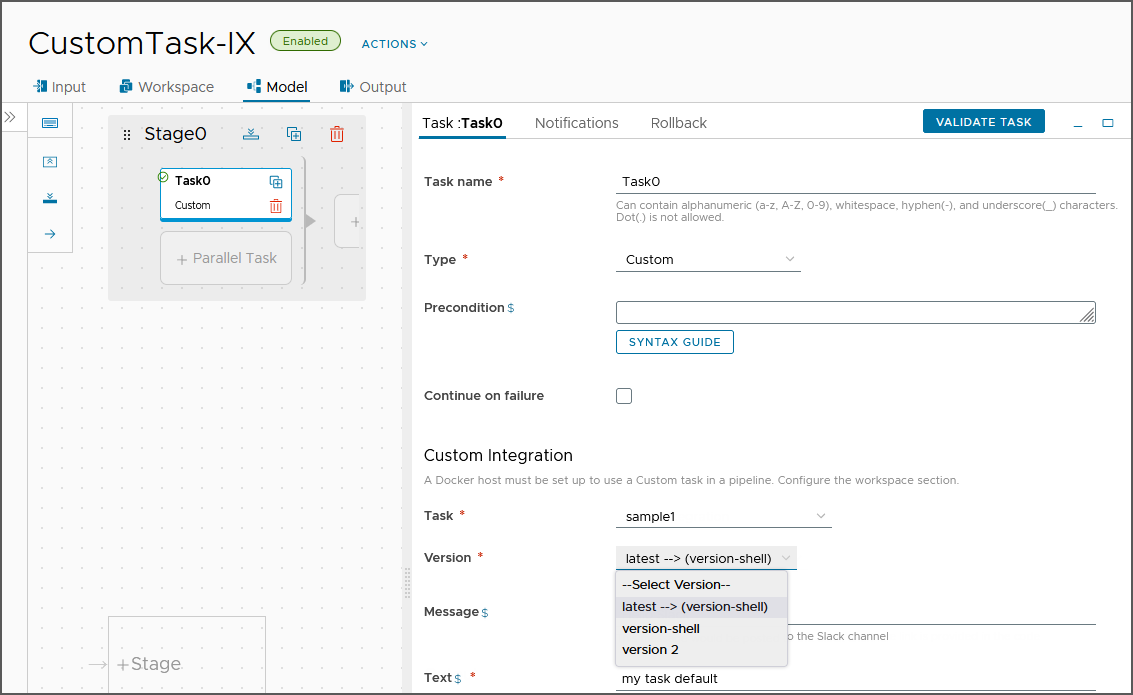
- Exécutez votre pipeline.
- Cliquez sur Exécuter.
- Observez l'exécution du pipeline.
- Vérifiez que la sortie inclut le code d'état, le code de réponse, l'état et le résultat déclaré attendus.
Vous avez défini statusCode comme propriété de sortie. Par exemple, un statusCode de 200 peut indiquer une publication Slack réussie et un responseCode de 0 peut indiquer la réussite sans erreur du script.
- Pour vérifier le résultat dans les journaux d'exécution, cliquez sur Exécutions, sur le lien vers votre pipeline, puis sur la tâche, et examinez les données consignées. Par exemple :
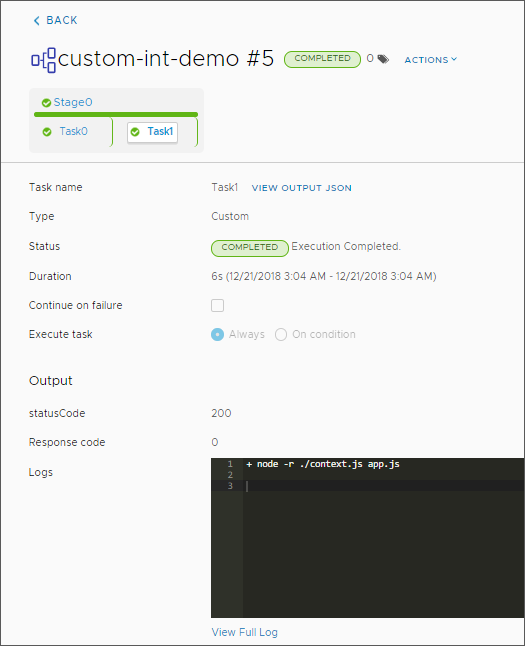
Résultats
Félicitations ! Vous avez créé un script d'intégration personnalisé qui connecte Code Stream à votre instance de Slack et publie un message sur un canal Slack.
Que faire ensuite
Continuez à créer des intégrations personnalisées pour prendre en charge l'utilisation de tâches personnalisées dans vos pipelines, afin de pouvoir étendre la capacité de Code Stream dans l'automatisation du cycle de vie de votre version logicielle.
