Avec des variables et des expressions, vous pouvez utiliser des paramètres d'entrée et des paramètres de sortie avec vos tâches de pipeline. Les paramètres que vous entrez lient votre tâche de pipeline à une ou plusieurs variables, expressions ou conditions, et déterminent le comportement du pipeline lors de son exécution.
Les pipelines peuvent exécuter des solutions de livraison de logiciels simples ou complexes
Lorsque vous liez des tâches de pipeline ensemble, vous pouvez inclure des expressions par défaut et complexes. Par conséquent, votre pipeline peut exécuter des solutions de livraison de logiciel simples ou complexes.
Pour créer les paramètres dans votre pipeline, cliquez sur l'onglet Entrée ou Sortie et ajoutez une variable en entrant le symbole dollar $ et une expression. Par exemple, ce paramètre est utilisé comme une entrée de tâche qui appelle une URL : ${Stage0.Task3.input.URL}.
Le format des liaisons de variables utilise des composants de syntaxe appelés portées et clés. SCOPE définit le contexte comme entrée ou sortie, et KEY définit les détails. Dans l'exemple de paramètre ${Stage0.Task3.input.URL}, input est SCOPE et l'URL est KEY.
Les propriétés de sortie d'une tâche peuvent résoudre n'importe quel nombre de niveaux imbriqués de liaison de variable.
Pour en savoir plus sur l'utilisation de liaisons de variables dans des pipelines, consultez Utilisation des liaisons de variables dans les pipelines Code Stream.
Utilisation d'expressions en dollars avec des étendues et des clés pour lier des tâches de pipeline
Vous pouvez lier des tâches de pipeline en utilisant des expressions dans des variables à symbole de dollar. Vous entrez des expressions en tant que ${SCOPE.KEY.<PATH>}.
Pour déterminer le comportement d'une tâche de pipeline, dans chaque expression, SCOPE est le contexte que Code Stream utilise. La portée recherche une KEY qui définit les détails de l'action effectuée par la tâche. Lorsque la valeur de KEY est un objet imbriqué, vous pouvez fournir un PATH facultatif.
Ces exemples décrivent SCOPE et KEY, et vous montrent comment les utiliser dans votre pipeline.
Tableau 1.
Utilisation de SCOPE et de KEY
| SCOPE |
Objet de l'expression et exemple |
KEY |
Utilisation de SCOPE et KEY dans votre pipeline |
| input |
Propriétés d'entrée d'un pipeline : ${input.input1}
|
Nom de la propriété d'entrée |
Pour faire référence à la propriété d'entrée d'un pipeline dans une tâche, utilisez ce format :
tasks:
mytask:
type: REST
input:
url: ${input.url}
action: get
input:
url: https://www.vmware.com
|
| output |
Propriétés de sortie d'un pipeline : ${output.output1}
|
Nom de la propriété de sortie |
Pour faire référence à une propriété de sortie pour l'envoi d'une notification, utilisez ce format :
notifications:
email:
- endpoint: MyEmailEndpoint
subject: "Deployment Successful"
event: COMPLETED
to:
- [email protected]
body: |
Pipeline deployed the service successfully. Refer ${output.serviceURL}
|
| task input |
Entrée d'une tâche : ${MY_STAGE.MY_TASK.input.SOMETHING}
|
Indique l'entrée d'une tâche dans une notification |
Lorsqu'un travail Jenkins démarre, il peut faire référence au nom de la tâche déclenchée à partir de l'entrée de la tâche. Dans ce cas, envoyez une notification à l'aide de ce format :
notifications:
email:
- endpoint: MyEmailEndpoint
stage: MY_STAGE
task: MY_TASK
subject: "Build Started"
event: STARTED
to:
- [email protected]
body: |
Jenkins job ${MY_STAGE.MY_TASK.input.job} started for commit id ${input.COMMITID}.
|
| task output |
Sortie d'une tâche : ${MY_STAGE.MY_TASK.output.SOMETHING}
|
Indique la sortie d'une tâche dans une tâche suivante |
Pour faire référence à la sortie de la tâche de pipeline 1 dans la tâche 2, utilisez ce format :
taskOrder:
- task1
- task2
tasks:
task1:
type: REST
input:
action: get
url: https://www.example.org/api/status
task2:
type: REST
input:
action: post
url: https://status.internal.example.org/api/activity
payload: ${MY_STAGE.task1.output.responseBody}
|
| var |
Variable : ${var.myVariable}
|
Faire référence à une variable dans un point de terminaison |
Pour faire référence à une variable secrète dans un point de terminaison pour mot de passe, utilisez ce format :
---
project: MyProject
kind: ENDPOINT
name: MyJenkinsServer
type: jenkins
properties:
url: https://jenkins.example.com
username: jenkinsUser
password: ${var.jenkinsPassword}
|
| var |
Variable : ${var.myVariable}
|
Faire référence à une variable dans un pipeline |
Pour faire référence à une variable dans une URL de pipeline, utilisez ce format :
tasks:
task1:
type: REST
input:
action: get
url: ${var.MY_SERVER_URL}
|
| task status |
État d'une tâche : ${MY_STAGE.MY_TASK.status}
${MY_STAGE.MY_TASK.statusMessage}
|
|
|
| stage status |
État d'une étape : ${MY_STAGE.status}
${MY_STAGE.statusMessage}
|
|
|
Expressions par défaut
Vous pouvez utiliser des variables avec des expressions dans votre pipeline. Ce résumé inclut les expressions par défaut que vous pouvez utiliser.
| Expression |
Description |
${comments} |
Commentaires fournis lors de la demande d'exécution du pipeline. |
${duration} |
Durée de l'exécution du pipeline. |
${endTime} |
Heure de fin de l'exécution du pipeline en UTC, si conclue. |
${executedOn} |
Identique à l'heure de début, l'heure de début de l'exécution du pipeline en UTC. |
${executionId} |
ID de l'exécution du pipeline. |
${executionUrl} |
URL qui permet d'accéder à l'exécution du pipeline dans l'interface utilisateur. |
${name} |
Nom du pipeline. |
${requestBy} |
Nom de l'utilisateur qui a demandé l'exécution. |
${stageName} |
Nom de l'étape actuelle, lorsqu'elle est utilisée dans l'étendue d'une étape. |
${startTime} |
Heure de début de l'exécution du pipeline en UTC. |
${status} |
État de l'exécution. |
${statusMessage} |
Message d'état de l'exécution du pipeline. |
${taskName} |
Nom de la tâche actuelle, lorsqu'elle est utilisée au niveau d'une entrée de tâche ou d'une notification. |
Utilisation de SCOPE et KEY dans les tâches de pipeline
Vous pouvez utiliser des expressions avec n'importe quelle tâche de pipeline prise en charge. Ces exemples vous montrent comment définir SCOPE et KEY, et confirmer la syntaxe. Ces exemples de code utilisent MY_STAGE et MY_TASK comme étape de pipeline et noms de tâches.
Pour en savoir plus sur les tâches disponibles, consultez Types de tâches disponibles dans Code Stream.
Tableau 2.
Assemblage de tâches
| Tâche |
Scope |
Key |
Utilisation de SCOPE et KEY dans la tâche |
| Opération de l'utilisateur |
|
Input |
summary : résumé de la demande d'opération d'utilisateur
description : description de la demande d'opération d'utilisateur
approvers : liste des adresses e-mail de l'approbateur, dans lesquelles chaque entrée peut être une variable avec une virgule ou utiliser un point-virgule pour les e-mails séparés
approverGroups : liste des adresses des groupes d'approbateurs pour la plate-forme et l'identité
sendemail : envoie éventuellement une notification par e-mail lors de la demande ou de la réponse lorsqu'elle est définie sur true
expirationInDays : nombre de jours qui représente le délai d'expiration de la demande
|
${MY_STAGE.MY_TASK.input.summary}
${MY_STAGE.MY_TASK.input.description}
${MY_STAGE.MY_TASK.input.approvers}
${MY_STAGE.MY_TASK.input.approverGroups}
${MY_STAGE.MY_TASK.input.sendemail}
${MY_STAGE.MY_TASK.input.expirationInDays}
|
|
Output |
index : chaîne hexadécimale à 6 chiffres qui représente la demande
respondedBy : nom du compte de la personne qui a approuvé/refusé l'opération d'utilisateur
respondedByEmail : adresse e-mail de la personne qui a répondu
comments : commentaires fournis lors de la réponse
|
${MY_STAGE.MY_TASK.output.index}
${MY_STAGE.MY_TASK.output.respondedBy}
${MY_STAGE.MY_TASK.output.respondedByEmail}
${MY_STAGE.MY_TASK.output.comments}
|
| Condition |
|
|
Input |
condition : condition à évaluer. Lorsque la condition est évaluée sur true, elle indique que la tâche est terminée, tandis que d'autres réponses font échouer la tâche
|
${MY_STAGE.MY_TASK.input.condition}
|
|
Output |
result : résultat lors de l'évaluation
|
${MY_STAGE.MY_TASK.output.response}
|
Tableau 3.
Tâches de pipeline
| Tâche |
Scope |
Key |
Utilisation de SCOPE et KEY dans la tâche |
| Pipeline |
|
Input |
name : nom du pipeline à exécuter
inputProperties : propriétés d'entrée à transmettre à l'exécution de pipeline imbriquée
|
${MY_STAGE.MY_TASK.input.name}
${MY_STAGE.MY_TASK.input.inputProperties} # Faire référence à toutes les propriétés
${MY_STAGE.MY_TASK.input.inputProperties.input1} # Faire référence à la valeur de input1
|
|
Output |
executionStatus : état de l'exécution du pipeline
executionIndex : index de l'exécution du pipeline
outputProperties : propriétés de sortie de l'exécution du pipeline
|
${MY_STAGE.MY_TASK.output.executionStatus}
${MY_STAGE.MY_TASK.output.executionIndex}
${MY_STAGE.MY_TASK.output.outputProperties} # Faire référence à toutes les propriétés
${MY_STAGE.MY_TASK.output.outputProperties.output1} # Faire référence à la valeur d'output1
|
Tableau 4.
Automatiser les tâches d'intégration continue
| Tâche |
Scope |
Key |
Utilisation de SCOPE et KEY dans la tâche |
| CI |
|
Input |
steps : ensemble de chaînes, qui représentent les commandes à exécuter
export : variables d'environnement à conserver après l'exécution des étapes
artifacts : chemins d'artefacts à conserver dans le chemin partagé
process : ensemble d'éléments de configuration pour le traitement de JUnit, JaCoCo, Checkstyle, FindBugs
|
${MY_STAGE.MY_TASK.input.steps}
${MY_STAGE.MY_TASK.input.export}
${MY_STAGE.MY_TASK.input.artifacts}
${MY_STAGE.MY_TASK.input.process}
${MY_STAGE.MY_TASK.input.process[0].path} # Faire référence au chemin d'accès de la première configuration
|
|
Output |
exports : paire clé-valeur, qui représente les variables d'environnement exportées depuis l'entrée export
artifacts : chemin d'artefacts correctement conservés
processResponse : ensemble de résultats traités pour le process d'entrée
|
${MY_STAGE.MY_TASK.output.exports} # Faire référence à toutes les exportations
${MY_STAGE.MY_TASK.output.exports.myvar} # Faire référence à la valeur de myvar
${MY_STAGE.MY_TASK.output.artifacts}
${MY_STAGE.MY_TASK.output.processResponse}
${MY_STAGE.MY_TASK.output.processResponse[0].result} # Résultat de la configuration du premier processus
|
| Personnalisé |
|
Input |
name : nom de l'intégration personnalisée
version : version de l'intégration personnalisée, publiée ou déconseillée
properties : propriétés à envoyer à l'intégration personnalisée
|
${MY_STAGE.MY_TASK.input.name}
${MY_STAGE.MY_TASK.input.version}
${MY_STAGE.MY_TASK.input.properties} # Faire référence à toutes les propriétés
${MY_STAGE.MY_TASK.input.properties.property1} # Faire référence à la valeur de property1
|
|
Output |
properties : propriétés de sortie de la réponse d'intégration personnalisée
|
${MY_STAGE.MY_TASK.output.properties} # Faire référence à toutes les propriétés
${MY_STAGE.MY_TASK.output.properties.property1} # Faire référence à la valeur de property1
|
Tableau 5.
Automatiser les tâches de déploiement continue : modèle de cloud
| Tâche |
Scope |
Key |
Utilisation de SCOPE et KEY dans la tâche |
| Modèle de cloud |
|
|
Input |
action : un des éléments createDeployment, updateDeployment, deleteDeployment, rollbackDeployment
blueprintInputParams : utilisé pour les actions Créer un déploiement et Mettre à jour le déploiement
allowDestroy : des machines peuvent être détruites lors du processus de déploiement de la mise à jour.
CREATE_DEPLOYMENT
blueprintName : nom du modèle de cloudblueprintVersion : version du modèle de cloud OU
fileUrl : URL du modèle de cloud distant YAML, après la sélection d'un serveur GIT. UPDATE_DEPLOYMENT Une de ces combinaisons :
blueprintName : nom du modèle de cloudblueprintVersion : version du modèle de cloud OU
fileUrl : URL du modèle de cloud distant YAML, après la sélection d'un serveur GIT. ------
deploymentId : ID du déploiement OU
deploymentName: nom du déploiement ------
DELETE_DEPLOYMENT
deploymentId : ID du déploiement OU
deploymentName: nom du déploiement ROLLBACK_DEPLOYMENT Une de ces combinaisons :
deploymentId : ID du déploiement OU
deploymentName: nom du déploiement ------
blueprintName : nom du modèle de cloudrollbackVersion : version à restaurer |
|
|
Output |
|
Paramètres pouvant être liés à d'autres tâches ou à la sortie d'un pipeline :
- Le nom du déploiement est accessible en tant que ${Stage0.Task0.output.deploymentName}
- L'ID de déploiement est accessible en tant que ${Stage0.Task0.output.deploymentId}
- Les détails du déploiement constituent un objet complexe et les détails internes sont accessibles à l'aide des résultats JSON.
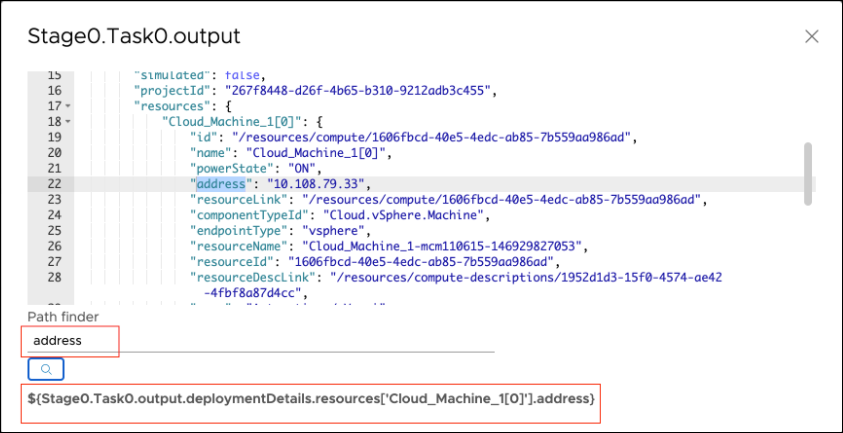
Pour accéder à n'importe quelle propriété, utilisez l'opérateur point pour suivre la hiérarchie JSON. Par exemple, pour accéder à l'adresse de la ressource Cloud_Machine_1[0], la liaison $ est : ${Stage0.Task0.output.deploymentDetails.resources['Cloud_Machine_1[0]'].address} De même, pour le type, la liaison $ est : ${Stage0.Task0.output.deploymentDetails.resources['Cloud_Machine_1[0]'].flavor} Dans l'interface utilisateur de Code Stream, vous pouvez obtenir les liaisons $ pour n'importe quelle propriété.
- Dans la zone de la propriété de sortie de la tâche, cliquez sur EXAMINER LE RÉSULTAT JSON.
- Pour trouver la liaison $, entrez n'importe quelle propriété.
- Cliquez sur l'icône de recherche, qui affiche la liaison $ correspondante.
|
Exemple de sortie JSON :
Exemple d'objet de détails de déploiement :
{
"id": "6a031f92-d0fa-42c8-bc9e-3b260ee2f65b",
"name": "deployment_6a031f92-d0fa-42c8-bc9e-3b260ee2f65b",
"description": "Pipeline Service triggered operation",
"orgId": "434f6917-4e34-4537-b6c0-3bf3638a71bc",
"blueprintId": "8d1dd801-3a32-4f3b-adde-27f8163dfe6f",
"blueprintVersion": "1",
"createdAt": "2020-08-27T13:50:24.546215Z",
"createdBy": "[email protected]",
"lastUpdatedAt": "2020-08-27T13:52:50.674957Z",
"lastUpdatedBy": "[email protected]",
"inputs": {},
"simulated": false,
"projectId": "267f8448-d26f-4b65-b310-9212adb3c455",
"resources": {
"Cloud_Machine_1[0]": {
"id": "/resources/compute/1606fbcd-40e5-4edc-ab85-7b559aa986ad",
"name": "Cloud_Machine_1[0]",
"powerState": "ON",
"address": "10.108.79.33",
"resourceLink": "/resources/compute/1606fbcd-40e5-4edc-ab85-7b559aa986ad",
"componentTypeId": "Cloud.vSphere.Machine",
"endpointType": "vsphere",
"resourceName": "Cloud_Machine_1-mcm110615-146929827053",
"resourceId": "1606fbcd-40e5-4edc-ab85-7b559aa986ad",
"resourceDescLink": "/resources/compute-descriptions/1952d1d3-15f0-4574-ae42-4fbf8a87d4cc",
"zone": "Automation / Vms",
"countIndex": "0",
"image": "ubuntu",
"count": "1",
"flavor": "small",
"region": "MYBU",
"_clusterAllocationSize": "1",
"osType": "LINUX",
"componentType": "Cloud.vSphere.Machine",
"account": "bha"
}
},
"status": "CREATE_SUCCESSFUL",
"deploymentURI": "https://api.yourenv.com/automation-ui/#/deployment-ui;ash=/deployment/6a031f92-d0fa-42c8-bc9e-3b260ee2f65b"
}
Tableau 6.
Automatiser les tâches de déploiement continues : Kubernetes
| Tâche |
Scope |
Key |
Utilisation de SCOPE et KEY dans la tâche |
| Kubernetes |
|
Input |
action : une des opérations GET, CREATE, APPLY, DELETE, ROLLBACK
timeout : délai d'expiration global d'une actionfilterByLabel : étiquette supplémentaire pour filtrer l'action GET avec K8S labelSelector GET, CREATE, DELETE, APPLY
yaml : YAML en ligne à traiter et à envoyer à Kubernetesparameters : paire KEY, VALUE - Remplacer $$KEY par VALUE dans la zone d'entrée YAML en lignefilePath : chemin d'accès relatif à partir du point de terminaison Git SCM, s'il est fourni, à partir duquel extraire le YAMLscmConstants : paire KEY, VALUE - Remplacer $${KEY} par VALUE dans le YAML extrait sur SCM.continueOnConflict : lorsqu'elle est définie sur true, si une ressource est déjà présente, la tâche se poursuit. ROLLBACK
resourceType : type de ressource à restaurerresourceName : nom de la ressource à restaurernamespace : espace de noms dans lequel la restauration doit être effectuéerevision : révision à restaurer |
${MY_STAGE.MY_TASK.input.action} #Détermine l'action à effectuer.
${MY_STAGE.MY_TASK.input.timeout}
${MY_STAGE.MY_TASK.input.filterByLabel}
${MY_STAGE.MY_TASK.input.yaml}
${MY_STAGE.MY_TASK.input.parameters}
${MY_STAGE.MY_TASK.input.filePath}
${MY_STAGE.MY_TASK.input.scmConstants}
${MY_STAGE.MY_TASK.input.continueOnConflict}
${MY_STAGE.MY_TASK.input.resourceType}
${MY_STAGE.MY_TASK.input.resourceName}
${MY_STAGE.MY_TASK.input.namespace}
${MY_STAGE.MY_TASK.input.revision}
|
|
Output |
response : capture la réponse complète
response.<RESOURCE> : ressource correspond à configMaps, deployments, endpoints, ingresses, jobs, namespaces, pods, replicaSets, replicationControllers, secrets, services, statefulSets, nodes, loadBalancers.
response.<RESOURCE>.<KEY> : la clé correspond à apiVersion, kind, metadata, spec
|
${MY_STAGE.MY_TASK.output.response}
${MY_STAGE.MY_TASK.output.response.}
|
Tableau 7.
Intégrer des applications de développement, de test et de déploiement
| Tâche |
Scope |
Key |
Utilisation de SCOPE et KEY dans la tâche |
| Bamboo |
|
Input |
plan : nom du plan
planKey : clé du plan
variables : variables à transmettre au plan
parameters : paramètres à transmettre au plan
|
${MY_STAGE.MY_TASK.input.plan}
${MY_STAGE.MY_TASK.input.planKey}
${MY_STAGE.MY_TASK.input.variables}
${MY_STAGE.MY_TASK.input.parameters} # Faire référence à tous les paramètres
${MY_STAGE.MY_TASK.input.parameters.param1} # Faire référence à la valeur de param1
|
|
Output |
resultUrl : URL de la build résultante
buildResultKey : clé de la build résultante
buildNumber : numéro de la build
buildTestSummary : résumé de l'exécution des tests
successfulTestCount : résultat du test transmis
failedTestCount : résultat du test ayant échoué
skippedTestCount : résultat du test ignoré
artifacts: artifacts de la build
|
${MY_STAGE.MY_TASK.output.resultUrl}
${MY_STAGE.MY_TASK.output.buildResultKey}
${MY_STAGE.MY_TASK.output.buildNumber}
${MY_STAGE.MY_TASK.output.buildTestSummary} # Faire référence à tous les résultats
${MY_STAGE.MY_TASK.output.successfulTestCount} # Faire référence à un nombre de tests spécifique
${MY_STAGE.MY_TASK.output.buildNumber}
|
| Jenkins |
|
Input |
job : nom du travail Jenkins
parameters : paramètres à transmettre à la tâche
|
${MY_STAGE.MY_TASK.input.job}
${MY_STAGE.MY_TASK.input.parameters} # Faire référence à tous les paramètres
${MY_STAGE.MY_TASK.input.parameters.param1} # Faire référence à la valeur d'un paramètre
|
|
Output |
job : nom du travail Jenkins
jobId : ID du travail résultant, tel que 1234
jobStatus : état dans Jenkins
jobResults : collecte des résultats de la couverture de test/code
jobUrl : URL de l'exécution de la tâche résultante
|
${MY_STAGE.MY_TASK.output.job}
${MY_STAGE.MY_TASK.output.jobId}
${MY_STAGE.MY_TASK.output.jobStatus}
${MY_STAGE.MY_TASK.output.jobResults} # Faire référence à tous les résultats
${MY_STAGE.MY_TASK.output.jobResults.junitResponse} # Faire référence aux résultats JUnit
${MY_STAGE.MY_TASK.output.jobResults.jacocoRespose} # Faire référence aux résultats JaCoCo
${MY_STAGE.MY_TASK.output.jobUrl}
|
| TFS |
|
Input |
projectCollection : collection de projets depuis TFS
teamProject : projet sélectionné dans la collection disponible
buildDefinitionId : ID de définition de build à exécuter
|
${MY_STAGE.MY_TASK.input.projectCollection}
${MY_STAGE.MY_TASK.input.teamProject}
${MY_STAGE.MY_TASK.input.buildDefinitionId}
|
|
Output |
buildId : ID de build résultant
buildUrl : URL pour consulter le résumé de la build
logUrl : URL pour consulter les journaux
dropLocation : emplacement cible des artefacts, le cas échéant
|
${MY_STAGE.MY_TASK.output.buildId}
${MY_STAGE.MY_TASK.output.buildUrl}
${MY_STAGE.MY_TASK.output.logUrl}
${MY_STAGE.MY_TASK.output.dropLocation}
|
| vRO |
|
Input |
workflowId : ID du workflow à exécuter
parameters : paramètres à transmettre au workflow
|
${MY_STAGE.MY_TASK.input.workflowId}
${MY_STAGE.MY_TASK.input.parameters}
|
|
Output |
workflowExecutionId : ID de l'exécution du workflow
properties : propriétés de sortie de l'exécution du workflow
|
${MY_STAGE.MY_TASK.output.workflowExecutionId}
${MY_STAGE.MY_TASK.output.properties}
|
Tableau 8.
Intégrer d'autres applications via une API
| Tâche |
Scope |
Key |
Utilisation de SCOPE et KEY dans la tâche |
| REST |
|
Input |
url : URL à appeler
action : méthode HTTP à utiliser
headers : en-têtes HTTP à transmettre
payload : charge utile de la demande
fingerprint : empreinte digitale à faire correspondre si l'URL est https
allowAllCerts : lorsque la valeur est définie sur true, il peut s'agir de n'importe quel certificat disposant de l'URL https
|
${MY_STAGE.MY_TASK.input.url}
${MY_STAGE.MY_TASK.input.action}
${MY_STAGE.MY_TASK.input.headers}
${MY_STAGE.MY_TASK.input.payload}
${MY_STAGE.MY_TASK.input.fingerprint}
${MY_STAGE.MY_TASK.input.allowAllCerts}
|
|
Output |
responseCode : codes de réponse HTTP
responseHeaders : en-têtes de réponse HTTP
responseBody : format de chaîne de la réponse reçue
responseJson : réponse transversale si content-type est application/json
|
${MY_STAGE.MY_TASK.output.responseCode}
${MY_STAGE.MY_TASK.output.responseHeaders}
${MY_STAGE.MY_TASK.output.responseHeaders.header1} # Faire référence à l'en-tête de réponse « header1 »
${MY_STAGE.MY_TASK.output.responseBody}
${MY_STAGE.MY_TASK.output.responseJson} # Faire référence à la réponse JSON
${MY_STAGE.MY_TASK.output.responseJson.a.b.c} # Faire référence à l'objet imbriqué suivant le chemin d'accès a.b.c JSON dans la réponse
|
| Interrogation |
|
Input |
url : URL à appeler
headers : en-têtes HTTP à transmettre
exitCriteria : critères à respecter pour que la tâche aboutisse ou échoue. Une paire clé-valeur de « success » → expression, « failure » → Expression :
pollCount : nombre d'itérations à effectuer. Un administrateur Code Stream peut définir le nombre d'interrogations sur un maximum de 10 000.
pollIntervalSeconds : nombre de secondes à attendre entre chaque itération. L'intervalle d'interrogation doit être supérieur ou égal à 60 secondes.
ignoreFailure : lorsque la valeur est définie sur true, ignore les échecs de réponse intermédiaire
fingerprint : empreinte digitale à faire correspondre si l'URL est https
allowAllCerts : lorsque la valeur est définie sur true, il peut s'agir de n'importe quel certificat disposant de l'URL https
|
${MY_STAGE.MY_TASK.input.url}
${MY_STAGE.MY_TASK.input.headers}
${MY_STAGE.MY_TASK.input.exitCriteria}
${MY_STAGE.MY_TASK.input.pollCount}
${MY_STAGE.MY_TASK.input.pollIntervalSeconds}
${MY_STAGE.MY_TASK.input.ignoreFailure}
${MY_STAGE.MY_TASK.input.fingerprint}
${MY_STAGE.MY_TASK.input.allowAllCerts}
|
|
Output |
responseCode : codes de réponse HTTP
responseBody : format de chaîne de la réponse reçue
responseJson : réponse transversale si content-type est application/json
|
${MY_STAGE.MY_TASK.output.responseCode}
${MY_STAGE.MY_TASK.output.responseBody}
${MY_STAGE.MY_TASK.output.responseJson} # Refer to response as JSON
|
Tableau 9.
Exécuter des scripts distants et définis par l'utilisateur
| Tâche |
Scope |
Key |
Utilisation de SCOPE et KEY dans la tâche |
| PowerShell Pour exécuter une tâche PowerShell, vous devez :
- Disposer d'une session active vers un hôte Windows distant.
- Si vous avez l'intention d'entrer une commande PowerShell en base 64, calculez d'abord la longueur de la commande globale. Pour plus d'informations, reportez-vous à la section Types de tâches disponibles dans Code Stream.
|
|
Input |
host : adresse IP ou nom de domaine complet de la machine
username : nom d'utilisateur à utiliser pour la connexion
password : mot de passe à utiliser pour se connecter
useTLS : tentative de connexion https
trustCert : lorsque la valeur est définie sur true, approuve les certificats auto-signés
script : script à exécuter
workingDirectory : chemin d'accès au répertoire vers lequel basculer avant d'exécuter le script
environmentVariables : paire clé-valeur de variable d'environnement à définir
arguments : arguments à passer au script
|
${MY_STAGE.MY_TASK.input.host}
${MY_STAGE.MY_TASK.input.username}
${MY_STAGE.MY_TASK.input.password}
${MY_STAGE.MY_TASK.input.useTLS}
${MY_STAGE.MY_TASK.input.trustCert}
${MY_STAGE.MY_TASK.input.script}
${MY_STAGE.MY_TASK.input.workingDirectory}
${MY_STAGE.MY_TASK.input.environmentVariables}
${MY_STAGE.MY_TASK.input.arguments}
|
|
Output |
response : contenu du fichier $SCRIPT_RESPONSE_FILE
responseFilePath : valeur de $SCRIPT_RESPONSE_FILE
exitCode : code de sortie du processus
logFilePath : chemin d'accès au fichier contenant stdout
errorFilePath : chemin d'accès au fichier contenant stderr
|
${MY_STAGE.MY_TASK.output.response}
${MY_STAGE.MY_TASK.output.responseFilePath}
${MY_STAGE.MY_TASK.output.exitCode}
${MY_STAGE.MY_TASK.output.logFilePath}
${MY_STAGE.MY_TASK.output.errorFilePath}
|
| SSH |
|
Input |
host : adresse IP ou nom de domaine complet de la machine
username : nom d'utilisateur à utiliser pour la connexion
password : mot de passe à utiliser pour se connecter (si vous le souhaitez, vous pouvez utiliser privateKey)
privateKey : PrivateKey à utiliser pour se connecter
passphrase : phrase secrète facultative pour déverrouiller privateKey
script : script à exécuter
workingDirectory : chemin d'accès au répertoire vers lequel basculer avant d'exécuter le script
environmentVariables : paire clé-valeur de la variable d'environnement à définir
|
${MY_STAGE.MY_TASK.input.host}
${MY_STAGE.MY_TASK.input.username}
${MY_STAGE.MY_TASK.input.password}
${MY_STAGE.MY_TASK.input.privateKey}
${MY_STAGE.MY_TASK.input.passphrase}
${MY_STAGE.MY_TASK.input.script}
${MY_STAGE.MY_TASK.input.workingDirectory}
${MY_STAGE.MY_TASK.input.environmentVariables}
|
|
Output |
response : contenu du fichier $SCRIPT_RESPONSE_FILE
responseFilePath : valeur de $SCRIPT_RESPONSE_FILE
exitCode : code de sortie du processus
logFilePath : chemin d'accès au fichier contenant stdout
errorFilePath : chemin d'accès au fichier contenant stderr
|
${MY_STAGE.MY_TASK.output.response}
${MY_STAGE.MY_TASK.output.responseFilePath}
${MY_STAGE.MY_TASK.output.exitCode}
${MY_STAGE.MY_TASK.output.logFilePath}
${MY_STAGE.MY_TASK.output.errorFilePath}
|
Utilisation d'une liaison de variable entre des tâches
Cet exemple montre comment utiliser des liaisons de variables dans vos tâches de pipeline.
Tableau 10.
Exemples de formats de syntaxe
| Exemple |
Syntaxe |
| Pour utiliser une valeur de sortie de tâche pour les notifications de pipeline et les propriétés de sortie de pipeline |
${<Stage Key>.<Task Key>.output.<Task output key>} |
| Pour faire référence à la valeur de sortie de la tâche précédente comme entrée de la tâche actuelle |
${<Previous/Current Stage key>.<Previous task key not in current Task group>.output.<task output key>} |
Pour en savoir plus
Pour en savoir plus sur la liaison de variables dans les tâches, consultez :










