









Avec l'introduction de la disponibilité continue dans vRealize Operations 8, plusieurs questions ont été posées fréquemment. Cette section permet d'améliorer les connaissances sur la disponibilité continue.
- Comment les données sont-elles stockées dans les nœuds d'analyse ?
-
Lorsqu'un objet est détecté, vRealize Operations détermine le nœud dans lequel les données doivent être conservées, puis copie (duplique) les données vers leur nœud correspondant dans l'autre domaine de pannes. Chaque objet est stocké dans deux nœuds d'analyse (paires de nœuds) dans les domaines de pannes et est toujours synchronisé.
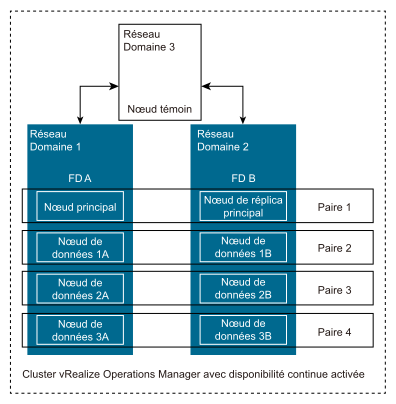
Par exemple, vRealize Operations dispose de huit nœuds d'analyse, l'autorité de certification (CA) est activée, et en conséquence chaque domaine de panne a quatre nœuds d'analyse (voir le diagramme ci-dessus).
Lorsqu'un nouvel objet est détecté, vRealize Operations décide de stocker les données dans « Nœud de données 2B » (principal) et une copie des données est automatiquement enregistrée dans « Nœud de données 2A » (secondaire).
Si, toutefois, le « DP A » n'est plus disponible, les données « principales » du « Nœud de données 2B » seront utilisées.
Si, toutefois, le « DP B » n'est plus disponible, les données « secondaires » du « Nœud de données 2A » seront utilisées.
- Quelles situations peuvent interrompre un cluster de disponibilité continue ? La perte simultanée du nœud principal ou du nœud de réplica principal et de nœuds de données, ou de deux ou plusieurs nœuds de données dans les deux domaines de pannes, n'est pas prise en charge.
-
Chaque nœud d'analyse du domaine de pannes 1 a sa paire de nœuds dans le domaine de pannes 2 ou inversement.
Dans l'exemple précédent, nous disposons de quatre paires de nœuds :
Nœud principal + réplica
Nœud de données 1A (DP A) + nœud de données 1B (DP B)
Nœud de données 2 A (DP A) + nœud de données 2 B (DP B)
Nœud de données 3 A (DP A) + nœud de données 3 B (DP B)
Les deux nœuds de chaque paire de nœuds sont toujours synchronisés et stockent les mêmes données. Par conséquent, le cluster continue de fonctionner sans perte de données lorsqu'un nœud parmi toutes les paires de nœuds est disponible.
- Que se passe-t-il si un nœud de données d'un des domaines de pannes n'est plus disponible ?
- Lorsqu'un nœud n'est plus disponible dans un domaine de pannes, le cluster est dans un état dégradé, mais continue à fonctionner. Il n'y aura aucune perte de données. Le nœud de données doit être réparé ou remplacé de sorte que le cluster ne reste pas dans un état dégradé.
- Le cluster sera-t-il interrompu si deux nœuds de données dans le domaine de pannes 1 et le nœud de réplica principal dans le domaine de pannes 2 sont perdus ?
- Dans cet exemple, le cluster continuera à fonctionner sans perte de données. Si un nœud d'analyse de chaque paire de nœuds est toujours disponible, il n'y aura aucune perte de données.
- Que se passe-t-il si l'ensemble d'un domaine de pannes n'est plus disponible ?
-
Lorsqu'un domaine de pannes entier n'est plus disponible, le cluster sera dans un état dégradé, mais continuera à fonctionner. Il n'y aura aucune perte de données. Le domaine de pannes doit être réparé et mis en ligne afin que le cluster ne reste pas dans un état dégradé.
Si le domaine de pannes est irrécupérable, il est possible de remplacer l'intégralité du domaine de pannes par des nœuds récemment déployés. Dans l'interface utilisateur d'administration, seul le nœud de réplica principal peut être remplacé. Si l'ensemble du domaine de pannes du nœud principal est perdu, vous devez attendre que le basculement du nœud principal soit effectué et que le nœud de réplica principal ait été promu comme nouveau nœud principal.
- Quel est le processus adéquat pour rajouter un nœud ayant échoué à un domaine de pannes ? Combien de temps peut prendre la synchronisation ?
- La procédure recommandée pour ajouter à nouveau un nœud ayant échoué consiste à utiliser la fonctionnalité de remplacement des nœuds du cluster dans l'interface utilisateur d'administration. Une fois que le nœud de remplacement a été ajouté, les données sont synchronisées. La durée de la synchronisation dépend fortement du nombre d'objets, de la période d'historique des objets, de la bande passante réseau et de la charge sur le cluster.
- Que se passe-t-il lorsque la latence réseau entre les domaines de pannes dépasse 20 ms ? Combien de temps vRealize Operations peut-il tolérer une latence prolongée ?
- Le respect des exigences de latence est nécessaire pour obtenir des performances optimales. La latence entre les domaines de pannes doit être inférieure à 10 ms, avec des pics allant jusqu'à 20 ms pendant des intervalles de 20 secondes. Pour plus d'informations sur les directives relatives à la latence réseau, reportez-vous à l'article de la base de connaissances Instructions de dimensionnement vRealize Operations Manager (KB 2093783).
- Lorsque la latence réseau entre les domaines de pannes dépasse « 20 ms pendant 20 secondes » pendant un certain temps, mais qu'elle redevient ensuite inférieure à 10 ms, combien de temps faut-il pour effectuer la resynchronisation ?
- Une forte latence ne signifie pas que la synchronisation s'est arrêtée. Lorsqu'un objet est détecté, vRealize Operations décide quel nœud doit conserver les données (nœud principal), puis une deuxième copie des données est transférée à sa paire de nœuds (nœud secondaire). Chaque objet est stocké dans deux nœuds d'analyse (paires) dans les deux domaines de pannes. La synchronisation est un processus continu dans lequel le nœud secondaire se synchronise régulièrement avec le nœud principal. La synchronisation est effectuée en fonction des horodatages de la dernière synchronisation des nœuds principaux et secondaires. Par conséquent, il n'y a pas de file d'attente de données de synchronisation dans vRealize Operations.
- Quelle est la tolérance réelle du nœud témoin aux pertes d'interrogations ?
- Les opérations du nœud témoin ne sont pas basées sur les interrogations. Le nœud témoin interagit uniquement lorsque l'un des nœuds ne peut pas communiquer (après plusieurs vérifications) avec des nœuds de l'autre domaine de pannes.
- À quel moment le nœud principal et le nœud de réplica principal vont-ils basculer ?
- Le basculement se produit uniquement lorsque le nœud principal n'est plus accessible ou n'est pas actif.
- Quand le nœud de réplica principal est-il promu comme nœud principal ?
-
Le nœud de réplica principal est promu en tant que nœud principal dans deux cas seulement :
- Lorsque le nœud principal existant est inactif.
- Lorsque le domaine de pannes associé est hors service/hors ligne.
- Lorsque le nœud principal d'origine revient en ligne, reprend-il le contrôle principal ? Comment les données sont-elles synchronisées ?
- Lorsque les opérations reviennent à la normale, avec le nœud principal et le nœud de réplica principal en ligne, le nœud récemment promu principal (anciennement nœud de réplica principal) reste le nœud principal et le nouveau réplica principal (anciennement nœud principal) est synchronisé avec le nouveau nœud principal.
- Que se passe-t-il si la connectivité entre les domaines de pannes est complètement interrompue, mais qu'elle est ensuite rétablie ?
- Si les communications entre les domaines de pannes sont complètement interrompues pendant plusieurs minutes, l'un des domaines de pannes sera automatiquement mis hors ligne. Une fois l'interruption du réseau restaurée, l'utilisateur Admin doit mettre en ligne manuellement le domaine de pannes pour commencer la synchronisation des données.
- Que se passe-t-il dans les domaines de pannes lorsque le nœud témoin n'est pas disponible ?
-
Tant que les deux domaines de pannes sont sains et communiquent entre eux, l'indisponibilité du nœud témoin n'aura aucun effet sur le cluster. vRealize Operations continuera à fonctionner. En cas de problème de communication entre les domaines de pannes, trois situations peuvent se produire :
- Le nœud témoin est accessible à partir des deux domaines de pannes : le témoin va mettre un domaine de pannes hors ligne en fonction de la santé du site.
- Le nœud témoin n'est accessible qu'à partir d'un seul domaine de pannes : l'autre domaine de pannes sera mis hors ligne automatiquement.
- Le nœud témoin n'est pas accessible à partir des deux domaines de pannes : les deux domaines de pannes seront mis hors ligne automatiquement.
- Lorsque le domaine de pannes hors ligne devient à nouveau disponible, les domaines de pannes synchronisent-ils toutes les données collectées lors de la panne de communication ?
- Les données collectées sont synchronisées immédiatement lorsque la connectivité au domaine de pannes est restaurée et synchronisée pour capturer toutes les données manquées.
- Que se passe-t-il lorsqu'un nœud d'analyse ne peut pas communiquer avec les nœuds d'analyse dans l'autre domaine de pannes ?
- Si un nœud d'analyse ne peut pas communiquer avec tous les nœuds dans l'autre domaine de pannes ou avec le nœud témoin, il sera automatiquement mis hors ligne. Tous les nœuds ou l'ensemble du domaine de pannes qui ont été mis hors ligne automatiquement doivent être remis en ligne manuellement par l'utilisateur Admin après avoir vérifié que tous les problèmes de communication ont été résolus.
- Si le nombre maximal de nœuds dans un cluster standard est de 10 très grands nœuds, qui prennent en charge 440 000 objets, pourquoi le nombre maximal de nœuds en disponibilité continue est-il plus élevé, avec 12 très grands nœuds, qui prennent en charge 264 000 objets ?
- Les 12 très grands nœuds sont pris en charge uniquement dans un cluster de disponibilité continue et font référence à un maximum de 6 très grands nœuds dans deux domaines de pannes distincts. Cela permet d'augmenter le nombre de nœuds dans un cluster standard et permet la collecte d'un plus grand nombre d'objets.
- Un équilibrage de charge est-il pris en charge avec la disponibilité continue ?
- Oui. Pour plus d'informations sur la configuration de l'équilibrage de charge, consultez le Guide de configuration de l'équilibrage de charge de vRealize Operations, disponible sous Ressources sur la page de documentation de vRealize Operations Manager.
- La documentation indique : « Lorsque la disponibilité continue est activée, le nœud de réplica peut prendre le relais de toutes les fonctions fournies par le nœud principal, en cas de panne d'un nœud principal. Le basculement vers le nœud de réplica est automatique et ne nécessite que deux à trois minutes d'interruption de service de vRealize Operations pour reprendre les opérations et redémarrer la collecte de données. »
- Pendant les tests, en déconnectant l'interface réseau sur le nœud principal, le basculement vers le nouveau principal a fonctionné dans les 5 minutes, vous êtes éjecté de l'interface utilisateur du produit ou vous obtenez des erreurs étranges.
- Les deux ou trois minutes indiquées sont des valeurs moyennes approximatives, donc 5 minutes sont acceptables.
- Lorsque le nœud principal est reconnecté au réseau après un basculement, quelle est la procédure recommandée pour renvoyer le nœud principal d'origine au rôle de principal ?
- Il n'est pas nécessaire de ramener le nœud de réplica principal au rôle de nœud principal ou inversement. Si vous voulez quand même restaurer l'ancien nœud principal au rôle de principal, utilisez « Mettre le nœud hors ligne/en ligne » sur le nouveau nœud principal ou son domaine de pannes (où réside le nœud principal d'origine)
- Chaque fois qu'un nœud est mis hors ligne ou redémarré, est-il nécessaire de mettre le domaine de pannes correspondant hors ligne, puis de le remettre en ligne ?
- Tous les nœuds, après le redémarrage ou la mise hors ligne/en ligne, continuent de fonctionner automatiquement. Aucune autre étape n'est nécessaire.
