









Se l'amministratore del cloud ha configurato Private AI Automation Services in VMware Aria Automation, è possibile richiedere carichi di lavoro di AI utilizzando il catalogo di Automation Service Broker.
Private AI Automation Services supporta due elementi del catalogo in Automation Service Broker a cui gli utenti con le rispettive autorizzazioni possono accedere e richiedere.
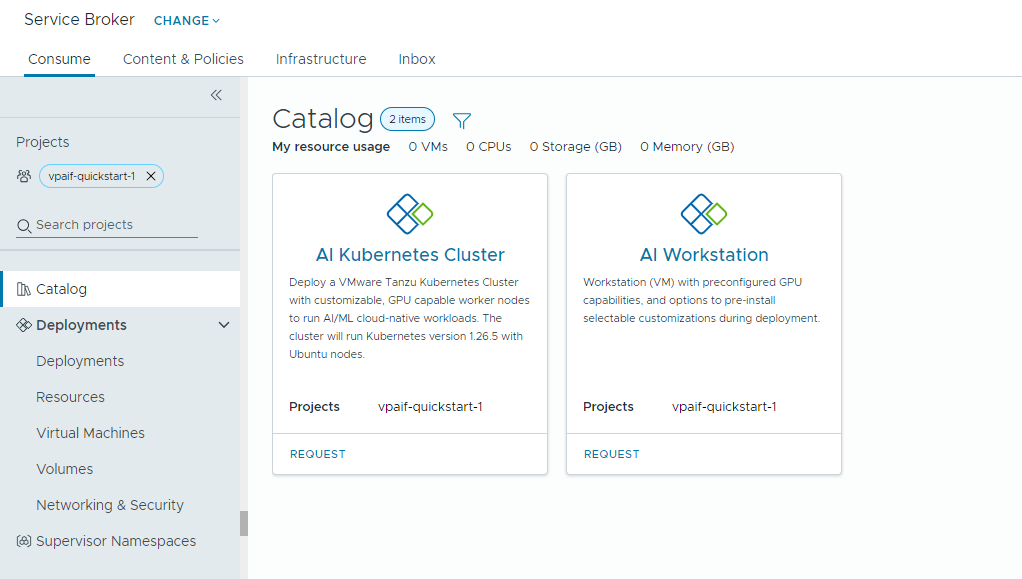
- Workstation IA: una macchina virtuale abilitata per GPU che può essere configurata con vCPU, vGPU, memoria e software IA/ML desiderato di NVIDIA.
- AI Kubernetes Cluster: un cluster Tanzu Kubernetes abilitato per GPU che può essere configurato con un operatore GPU NVIDIA.
Prima di iniziare
- Verificare che Private AI Automation Services sia configurato per il progetto e di disporre delle autorizzazioni necessarie per richiedere elementi del catalogo di AI.
Tenere presente che tutti i valori indicati qui sono esempi di casi d'uso. I valori dell'account variano in base all'ambiente in uso.
Distribuzione di una macchina virtuale di deep learning in un dominio del carico di lavoro VI
In qualità di data scientist, è possibile distribuire un singolo ambiente di sviluppo definito da software GPU dal catalogo self-service di Automation Service Broker. È possibile personalizzare la macchina virtuale abilitata per GPU con i parametri della macchina per modellare i requisiti di sviluppo, specificare le configurazioni del software IA/ML in base ai requisiti di training e inferenza e specificare i pacchetti IA/ML dal registro di NVIDIA NGC tramite una chiave di accesso al portale.
Procedura
Distribuzione di un cluster Tanzu Kubernetes abilitato per l'IA
Un tecnico di DevOps può richiedere un cluster Tanzu Kubernetes abilitato per GPU in cui i nodi worker possono eseguire carichi di lavoro IA/ML.
Il cluster TKG contiene un operatore GPU NVIDIA, che è un operatore Kubernetes responsabile della configurazione del driver NVIDIA corretto per l'hardware della GPU NVIDIA nei nodi del cluster TKG. Il cluster distribuito è pronto all'uso per i carichi di lavoro IA/ML senza necessità di una configurazione aggiuntiva correlata alla GPU.
Procedura
- Individuare la scheda AI Kubernetes Cluster e fare clic su Richiedi.
- Selezionare un progetto.
- Immettere un nome e una descrizione per la distribuzione.
- Selezionare il numero di nodi del riquadro di controllo.
Impostazione Valore di esempio Numero di nodi 1 Classe di macchine virtuali cpu-only-medium - 8 CPUs and 16 GB Memory La selezione della classe definisce le risorse disponibili all'interno della macchina virtuale.
- Selezionare il numero di nodi di lavoro.
Impostazione Descrizione Numero di nodi 3 Classe di macchine virtuali a100-medium - 4 vGPU (64 GB), 16 CPUs and 32 GB Memory - Fare clic su Invia.
risultati
La distribuzione contiene uno spazio dei nomi supervisore, un cluster TKG con tre nodi worker, più risorse all'interno del cluster TKG e un'applicazione carvel che distribuisce l'applicazione dell'operatore GPU.
Monitoraggio delle distribuzioni di Private AI
La pagina Distribuzioni consente di gestire le distribuzioni e le risorse associate apportando modifiche alle distribuzioni, risolvendo i problemi relativi alle distribuzioni non riuscite, apportando modifiche alle risorse ed eliminando le distribuzioni inutilizzate.
Per gestire le distribuzioni, selezionare .
Per ulteriori informazioni, vedere Come si gestiscono le distribuzioni personali di Automation Service Broker.
