









Il servizio di scalabilità automatica di VMware Cloud on AWS monitora l'integrità dell'infrastruttura SDDC, rileva gli errori imminenti e quelli effettivi e corregge automaticamente l'infrastruttura sostituendo gli host prima o dopo il verificarsi di un errore.
L'infrastruttura AWS è affidabile, ma gli errori sono inevitabili anche nell'infrastruttura più affidabile. Il pillar Affidabilità del framework dell'architettura AWS illustra i principi di progettazione per l'affidabilità nel cloud. VMware Cloud on AWS estende questi principi astraendo l'infrastruttura sottostante e sfruttando le capacità di analisi predittiva degli errori di vCenter Server e ESXi per fornire una correzione reattiva quando si verificano errori e una correzione predittiva in grado di impedire che gli errori influiscano sui carichi di lavoro.
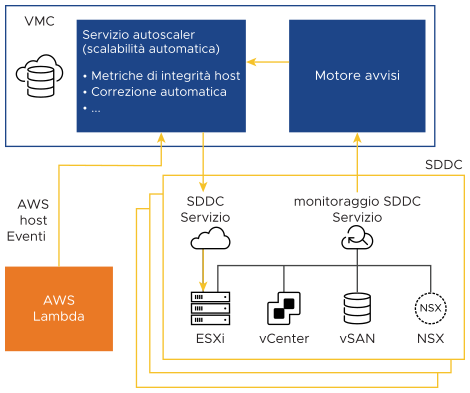
Architettura di alto livello per la correzione automatica
- AWS invia a VMware le informazioni a livello di host, in particolare relativamente agli eventi di manutenzione pianificata di AWS. Il servizio di scalabilità automatica riceve queste notifiche e corregge automaticamente eventuali problemi all'interno dell'SDDC.
- Un servizio di monitoraggio a livello di SDDC riceve notifiche dai componenti VMware Cloud on AWS sottostanti.
Correzione reattiva
La correzione automatica reattiva monitora gli errori hardware e software e tenta di correggere i problemi in diversi modi. La correzione automatica è un processo interno ed è in continua evoluzione. Gli utenti di VMware Cloud on AWS non hanno accesso al workflow o alla relativa configurazione, ma per una migliore comprensione, di seguito viene fornita una panoramica ad alto livello dei passaggi attualmente coinvolti.
- 1: Monitora
- VMware Cloud on AWS monitora continuamente l'integrità di ogni host nell'SDDC. Quando viene rilevato un errore, viene inviato un evento per la correzione automatica.
- 2: Attendi eventi transitori
- Alcuni degli errori rilevati possono essere temporanei. Ad esempio, quando il sistema di monitoraggio non può raggiungere un host a causa di un problema temporaneo di connettività. La correzione automatica attende cinque minuti per determinare se il problema è temporaneo. In tal caso, la correzione automatica non esegue alcuna azione.
- 3: Aggiungi un host
- Se l'errore non viene risolto dopo 5 minuti, la correzione automatica inizia ad aggiungere host all'SDDC. L'aggiunta preventiva di un host in questo modo garantisce che l'host sia disponibile, se necessario. Si noti che tale host non viene fatturato finché non sostituisce un host guasto nell'SDDC.
- 4: Determina il tipo di errore e intervieni
- Gli host possono non riuscire per motivi diversi e richiedere un'azione diversa. Ad esempio, un errore del disco vSAN in un host ancora connesso a un vCenter Server può essere corretto tramite un riavvio del software, mentre un host PSOD richiede un riavvio dell'hardware.
- 5: Controlla integrità dell'host
- Il passaggio successivo consiste nel verificare che l'azione di correzione abbia corretto l'host. Se l'host problematico è ora integro dopo un riavvio del software o dell'hardware, la correzione automatica evita ulteriori interruzioni per l'SDDC. Raccoglie ed esegue tutte le altre azioni necessarie e rimuove il nuovo host che è stato aggiunto preventivamente nel Passaggio 3.
- 6: Sostituisci host
- Se non è possibile risolvere il problema con l'host, la scalabilità automatica rimuove l'host non riuscito e lo sostituisce con l'host aggiunto al Passaggio 3. vSphere HA e vSAN vengono attivati e i tag dei criteri di elaborazione vengono collegati al nuovo host.
Correzione preventiva
- Al cluster viene aggiunto un nuovo host. I tag vengono copiati in questo nuovo host dall'host da sostituire.
- L'host in errore viene messo in modalità di manutenzione con un'evacuazione completa dei dati. In questo modo, tutte le macchine virtuali e/o i dati di vSAN vengono spostati senza interruzioni in altri host del cluster.
- L'host in errore viene rimosso dal cluster.
Eventi del servizio di scalabilità automatica
Quando il servizio di scalabilità automatica riceve un evento di errore, determina il tipo di errore e quindi intraprende l'azione appropriata. Il registro delle attività dell'SDDC include tutte le attività del servizio di scalabilità automatica, ma non mostra l'evento di errore che ha attivato l'attività.
- Eventi vCenter Server.
-
- Viene attivato un evento per verificare lo stato della connessione dell'host
- Viene attivato un evento quando l'host ESXi è disconnesso o non risponde.
- Eventi DAS
-
- eventi vSphere HA: viene attivato un evento quando non è presente alcuna comunicazione con il nodo primario, oppure quando HA è inattivo. (FDM)
- Quando un host non funziona, il sistema HA segnala un errore dell'host.
- vSAN eventi
-
- Quando si verifica un errore del disco negli host.
- Quando l'host vSAN è disconnesso.
- Eventi EDRS (non errore)
- Aggiornamento: disabilitare EDRS. Le attività di manutenzione richiedono spesso un host aggiuntivo, il quale viene aggiunto come parte dell'evento di manutenzione. EDRS è disabilitato per la durata di una manutenzione pianificata, così da impedire che queste attività attivino eventi di scalabilità verticale/orizzontale.
- Eventi AWS
-
- Eventi di manutenzione pianificati. Notifica da AWS che indica che è stato rilevato un problema di integrità dell'istanza e che l'istanza deve essere svuotata.
- Dashboard di integrità personale (PHD). Un flusso di eventi che fornisce informazioni sui vari componenti hardware e consente a VMware di individuare preventivamente gli errori hardware.
- Controllo dello stato del sistema. Monitora l'integrità dei sistemi AWS su cui si basa l'istanza. Questo controllo segnala i problemi che solo AWS può risolvere. In molti casi, questi problemi sono temporanei e non è necessaria alcuna azione.
- Controllo dello stato dell'istanza. Monitora il software e la configurazione di rete per ogni istanza. Questo controllo consente di monitorare la disponibilità dell'istanza inviando richieste ARP periodiche alla scheda NIC, oltre a segnalare la disponibilità delle istanze a livello di EC2. I controlli dello stato dell'istanza monitorano l'utilizzo dell'hardware sottostante, segnalano problemi di rete, esaurimento della memoria, file system corrotto, errori del kernel e così via. A differenza dei controlli dello stato del sistema, i controlli dello stato dell'istanza richiedono l'interazione di VMware per la risoluzione.
- Eventi SDDC
- Integrità dell'host vCenter Server.
