









NSX-T Data Center supporta distribuzioni multisito in cui è possibile gestire tutti i siti da un cluster NSX Manager.
- Ripristino di emergenza
- Attivo-attivo
Il diagramma seguente illustra una distribuzione del ripristino di emergenza.
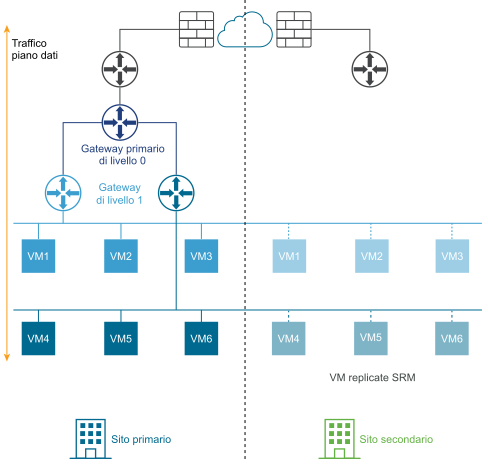
In una distribuzione con ripristino di emergenza, la piattaforma NSX-T Data Center nel sito principale gestisce la rete per l'azienda. Il sito secondario è in standby e subentra solo in caso di errore irreversibile nel sito primario.
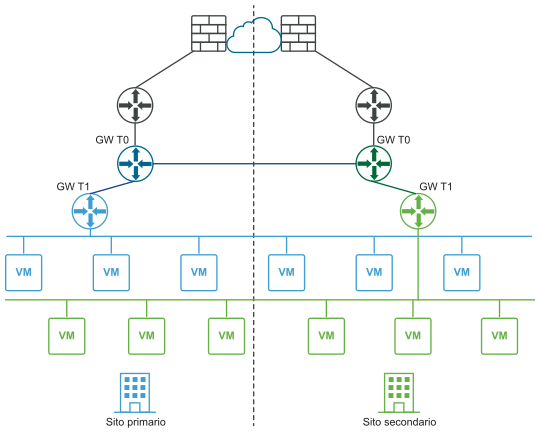
Il diagramma seguente illustra una distribuzione attiva-attiva.
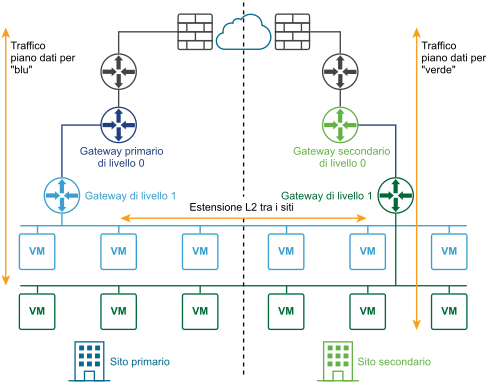
È possibile distribuire due siti per il ripristino automatico o manuale/controllato da script del piano di gestione e del piano dati.
Ripristino automatico del piano di gestione
- Un cluster vCenter esteso con alta disponibilità (HA) nei siti configurati.
- Una VLAN di gestione estesa.
Il cluster di NSX Manager viene distribuito nella VLAN di gestione e si trova fisicamente nel sito primario. Se si verifica un errore del sito primario, vSphere HA riavvierà gli NSX Manager nel sito secondario. Tutti i nodi di trasporto si riconnetteranno automaticamente agli NSX Manager riavviati. Il processo richiede circa 10 minuti. Durante questo periodo di tempo, il piano di gestione non è disponibile ma questo non influisce in alcun modo sul piano dati.
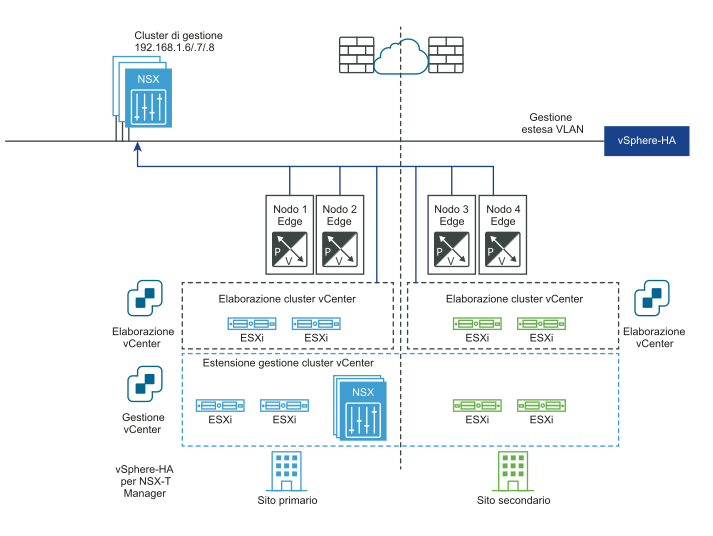
I diagrammi seguenti illustrano il ripristino automatico del piano di gestione.
Prima del ripristino di emergenza:
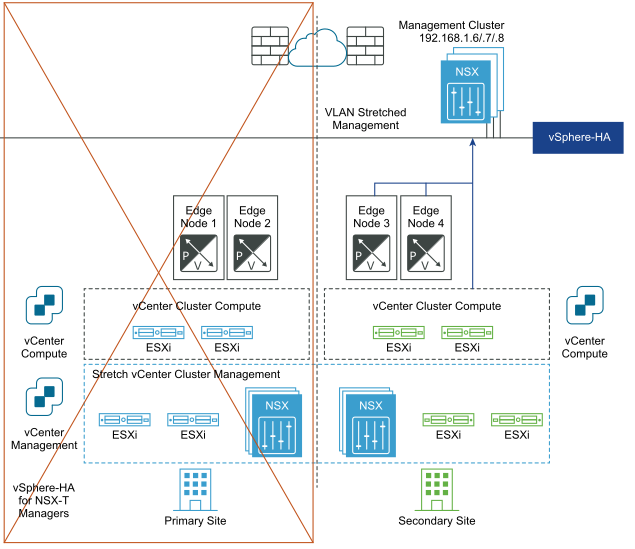
Dopo il ripristino di emergenza:
Ripristino automatico del piano dati
Per ottenere il ripristino automatico del piano dati, è possibile configurare domini di errore per i nodi Edge. È possibile raggruppare i nodi Edge di un cluster Edge in diversi domini di errore. NSX Manager posiziona automaticamente qualsiasi nuovo gateway di livello 1 attivo nel dominio di errore preferito e il gateway di livello 1 di standby nell'altro dominio. I gateway di livello 1 distribuiti prima della creazione del dominio di errore mantengono il posizionamento del nodo Edge originale e potrebbero non essere in esecuzione nella posizione desiderata. Se si desidera modificarne la posizione, modificare il gateway di livello 1 selezionando manualmente i nodi Edge per il gateway attivo di livello 1 e il gateway di standby di livello 1.
- La latenza massima tra i nodi Edge è 10 ms.
- Il routing nord-sud asimmetrico non è realizzabile, ad esempio un firewall fisico viene utilizzato in nordbound verso il nodo di NSX Edge, la modalità HA per il gateway di livello 0 deve essere attivo-standby e la modalità di failover deve essere preventiva.
- Se il routing nord-sud asimmetrico è possibile, ad esempio le due posizioni sono due edifici senza alcun firewall fisico tra loro, la modalità HA per il gateway di livello 0 può essere attiva-attiva.
I nodi Edge possono essere macchine virtuali o bare-metal. La modalità di failover del gateway di livello 1 può essere preventiva o non preventiva, ma è consigliata la modalità preventiva per garantire che i gateway di livello 0 e 1 si trovino nella stessa posizione.
- Utilizzando l'API di, creare domini di errore per i due siti, ad esempio FD1A-Preferred_Site1 e FD2A-Preferred_Site1. Impostare il parametro preferred_active_edge_services su
trueper il sito primario e sufalseper il sito secondario.POST /api/v1/failure-domains { "display_name": "FD1A-Preferred_Site1", "preferred_active_edge_services": "true" } POST /api/v1/failure-domains { "display_name": "FD2A-Preferred_Site1", "preferred_active_edge_services": "false" } - Utilizzando l'API, configurare un cluster Edge che è stato esteso tra i due siti. Ad esempio, il cluster include i nodi Edge EdgeNode1A e EdgeNode1B nel sito primario e i nodi Edge EdgeNode2A e EdgeNode2B nel sito secondario. Il gateway di livello 0 attivo e il gateway di livello 1 attivo vengono eseguiti in EdgeNode1A e EdgeNode1B. Il gateway di livello 0 di standby e il gateway di livello 1 di standby vengono eseguiti in EdgeNode2A e EdgeNode2B.
- Utilizzando l'API, associare ogni nodo Edge al dominio di errore per il sito. Per recuperare i dati relativi al nodo Edge, eseguire l'API
GET /api/v1/transport-nodes/<transport-node-id>. Utilizzare il risultato dell'API GET come input per l'APIPUT /api/v1/transport-nodes/<transport-node-id>, con la proprietà failure_domain_id impostata correttamente. Ad esempio,GET /api/v1/transport-nodes/<transport-node-id> Response: "resource_type": "TransportNode", "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... } PUT /api/v1/transport-nodes/<transport-node-id> { "resource_type": "TransportNode", "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... "failure_domain_id": "<UUID>", } - Utilizzando l'API, configurare il cluster Edge per allocare i nodi in base al dominio di errore. Per recuperare i dati relativi al cluster Edge, eseguire l'API
GET /api/v1/edge-clusters/<edge-cluster-id>. Utilizzare il risultato dell'API GET come input per l'APIPUT /api/v1/edge-clusters/<edge-cluster-id>con la proprietà aggiuntiva allocation_rules impostata correttamente. Ad esempio,GET /api/v1/edge-clusters/<edge-cluster-id> Response: { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... } PUT /api/v1/edge-clusters/<edge-cluster-id> { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... "allocation_rules": [ { "action": { "enabled": true, "action_type": "AllocationBasedOnFailureDomain" } } ], } - Creare il gateway di livello 0 eil gatewy di livello 1 utilizzando l'API o l'interfaccia utente di NSX Manager.
Se si verifica un errore dell'intero sito primario, il gateway di standby di livello 0 e il gateway di standby di livello 1 nel sito secondario subentrano automaticamente e diventano i nuovi gateway attivi.
I diagrammi seguenti illustrano il ripristino automatico del piano dati.
Prima del ripristino di emergenza:
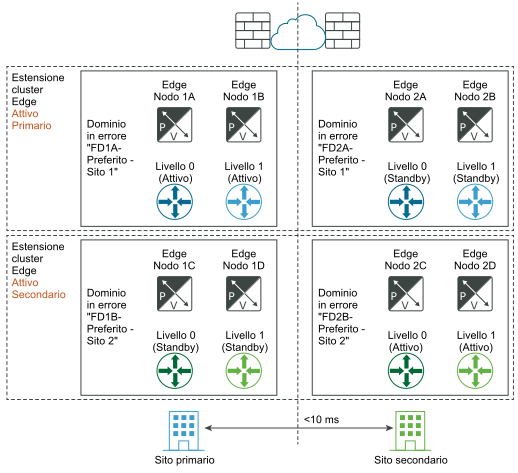
Dopo il ripristino di emergenza:
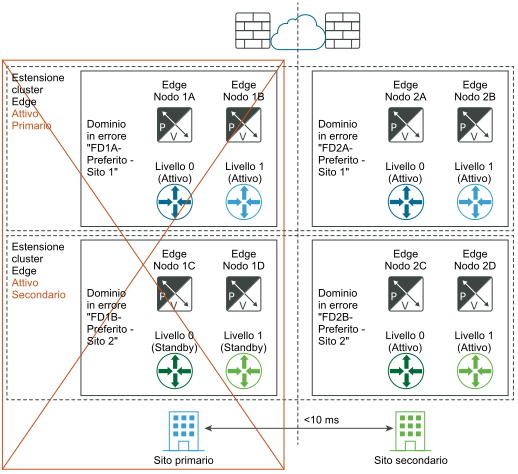
Se si verifica un errore di uno dei nodi Edge nel sito primario, ma non si tratta di un errore dell'intero sito, è importante che venga applicato lo stesso principio. Ad esempio, nel diagramma "Prima del ripristino di emergenza", si supponga che il nodo Edge 1B ospiti il gateway attivo di livello 1 blu e che il nodo Edge 2B ospiti il gateway di standby di livello 1 blu. Se si verifica un errore nel nodo Edge 1B, subentra il gateway di standby di livello 1 blu nel nodo Edge 2B e diventa il nuovo gateway attivo di livello 1 blu.
Ripristino manuale/controllato da script del piano di gestione
- DNS per NSX Manager con TTL breve, ad esempio 5 minuti.
- Backup continuo di NSX Manager.
Non sono necessari né vSphere HA, né una VLAN di gestione estesa. NSX-T Data Center Manager deve essere associato a un nome DNS con TTL breve. Tutti i nodi di trasporto (nodi Edge e hypervisor) devono connettersi a NSX Manager utilizzando il loro nome DNS. Per risparmiare tempo, è possibile facoltativamente preinstallare un cluster NSX Manager nel sito secondario.
- Modificare il record DNS in modo che il cluster NSX Manager presenti indirizzi IP diversi.
- Ripristinare il cluster NSX Manager da un backup.
- Connettere i nodi di trasporto al nuovo cluster NSX Manager.
I diagrammi seguenti illustrano il ripristino manuale/controllato da script del piano di gestione.
Prima del ripristino di emergenza:
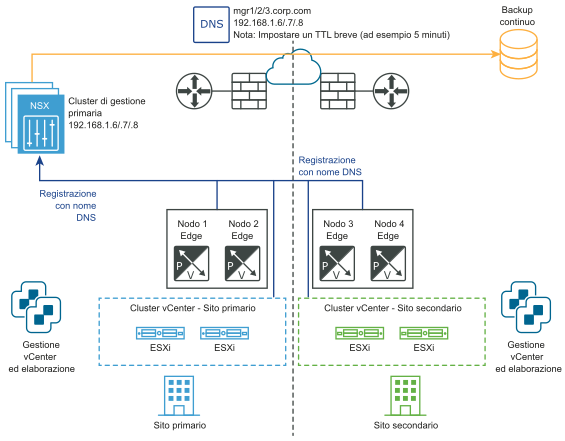
Dopo il ripristino di emergenza:
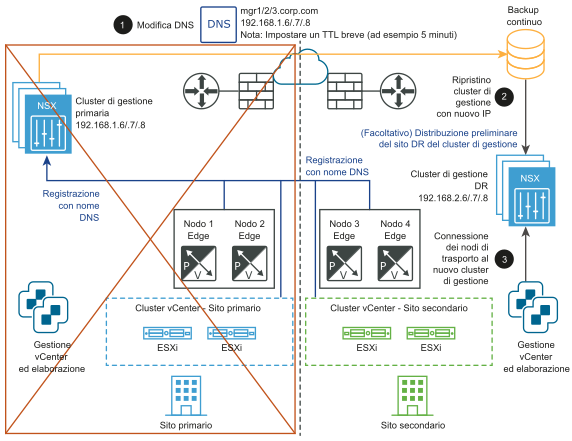
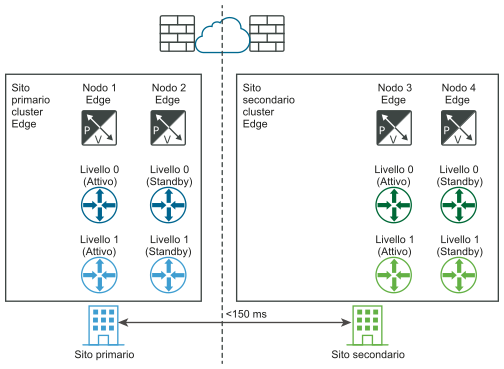
Ripristino manuale/controllato da script del piano dati
Requisito: la latenza massima tra i nodi Edge deve essere di 150 ms.
I nodi Edge possono essere macchine virtuali o bare-metal. I gateway di livello 0 in ogni posizione possono essere attivo-standby o attivo-attivo. È possibile installare le macchine virtuali del nodo Edge in vCenter Server diversi. vSphere HA non è necessario.
- Per tutti i livelli 1 nel sito primario (blu), aggiornare la configurazione del cluster Edge in modo che sia il sito del cluster Edge secondario.
- Per tutti i livelli 1 nel sito primario (blu), riconnetterli a T0 secondario (verde).
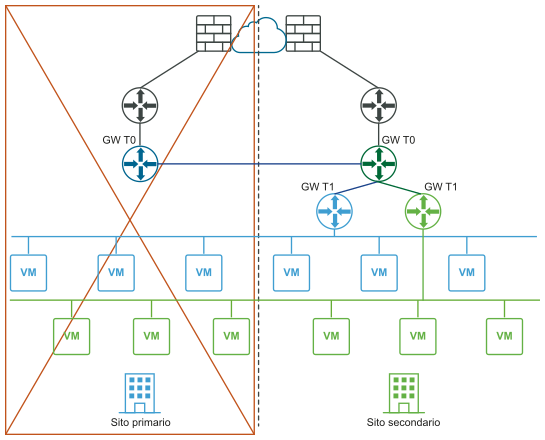
I diagrammi seguenti illustrano il ripristino manuale/controllato da script del piano dati con entrambe le viste della rete logica e fisica.
Prima del ripristino di emergenza (visualizzazioni logiche e fisiche):
Dopo il ripristino di emergenza (visualizzazioni logiche e fisiche):
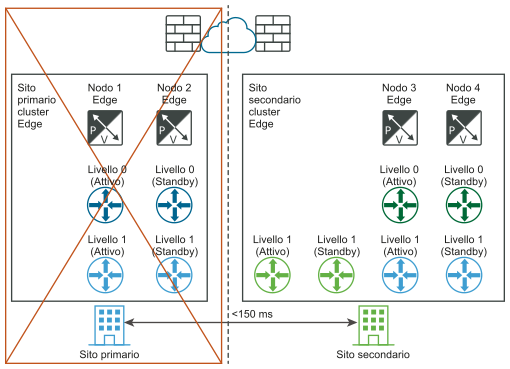
Requisiti per le distribuzioni multisito
- La larghezza di banda deve essere pari ad almeno 1 Gbps e la latenza (RTT) deve essere inferiore a 150 ms.
- Impostare MTU su 9000. Deve essere almeno 1600.
- Con ripristino automatico del piano di gestione con gestione VLAN estesa tra i siti. vSphere HA tra i siti per le macchine virtuali di NSX Manager.
- Con ripristino manuale/controllato da script del piano di gestione con gestione VLAN estesa tra i siti. VMware SRM per le macchine virtuali di NSX Manager.
- Con ripristino manuale/controllato da script del piano di gestione senza gestione VLAN estesa tra i siti.
- Backup continuo di NSX Manager.
- NSX Manager deve essere configurato per l'utilizzo del nome di dominio completo.
- Se gli indirizzi IP pubblici vengono esposti tramite servizi come NAT o il bilanciamento del carico, è necessario utilizzare lo stesso provider Internet.
- Con il ripristino automatico del piano di gestione
- La latenza massima tra le posizioni è 10 ms.
- La modalità HA per il gateway di livello 0 deve essere attiva-standby e la modalità di failover deve essere preventiva per evitare il routing asimmetrico.
- La modalità HA per il gateway di livello 0 può essere attiva-attiva se il routing asimmetrico è accettato (ad esempio edifici diversi in una regione metropolitana).
- Con ripristino manuale/controllato da script del piano di gestione
- La latenza massima tra le posizioni è 150 ms.
- CMS deve supportare un plug-in NSX-T Data Center. In questa versione, VMware Integrated OpenStack (VIO) e vRealize Automation (vRA) soddisfano questo requisito.
Limitazioni
- Nessuna funzionalità di uscita locale. Tutto il traffico nord-sud deve avvenire all'interno di un sito.
- Il software per il ripristino di emergenza deve supportare NSX-T Data Center, ad esempio VMware Site Recovery Manager 8.1.2 o versione successiva.
- Se si ripristinano NSX Manager in un ambiente con più siti, eseguire le operazioni seguenti nel sito secondario/primario:
- Dopo la sospensione del processo di ripristino al passaggio AggiungiNodoACluster, è innanzitutto necessario rimuovere il VIP esistente e impostare il nuovo IP virtuale nella pagina dell'interfaccia utente prima di aggiungere nodi del gestore.
- Aggiungere nuovi nodi a un cluster con un solo nodo ripristinato dopo l'aggiornamento del VIP.
