









NSX supporta distribuzioni multisito in cui è possibile gestire tutti i siti da un cluster NSX Manager.
- Ripristino di emergenza
- Attivo-attivo
Il diagramma seguente illustra una distribuzione del ripristino di emergenza.
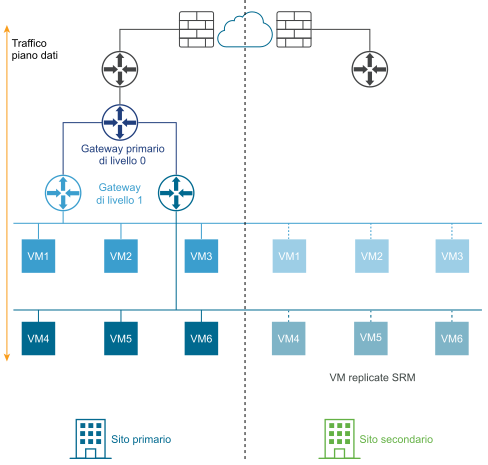
In una distribuzione con ripristino di emergenza, la piattaforma NSX nel sito principale gestisce la rete per l'azienda. Il sito secondario è in standby e subentra solo in caso di errore irreversibile nel sito primario.
Il diagramma seguente illustra una distribuzione attiva-attiva.
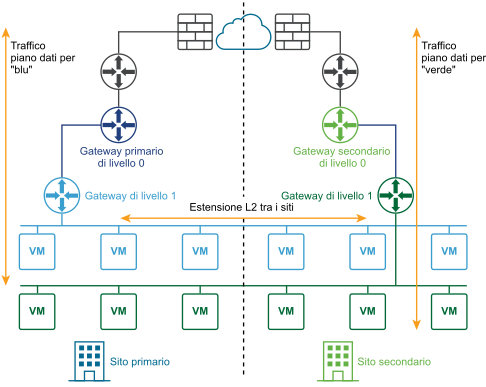
È possibile distribuire due siti per il ripristino automatico o manuale/controllato da script del piano di gestione e del piano dati.
Ripristino automatico del piano di gestione
- Un cluster vCenter esteso con alta disponibilità nei siti configurati.
- Una VLAN di gestione estesa.
Il cluster di NSX Manager viene distribuito nella VLAN di gestione e si trova fisicamente nel sito primario. Se si verifica un errore del sito primario, vSphere HA riavvierà NSX Manager nel sito secondario. Tutti i nodi di trasporto si riconnetteranno automaticamente agli NSX Manager riavviati. Il processo richiede circa 10 minuti. Durante questo periodo di tempo, il piano di gestione non è disponibile ma ciò non influisce sul piano dati.
I diagrammi seguenti illustrano il ripristino automatico del piano di gestione.
Prima del ripristino di emergenza:
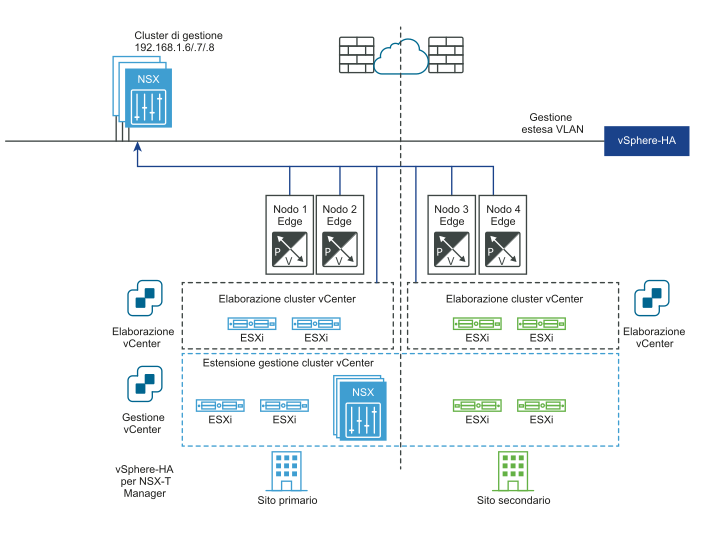
Dopo il ripristino di emergenza:
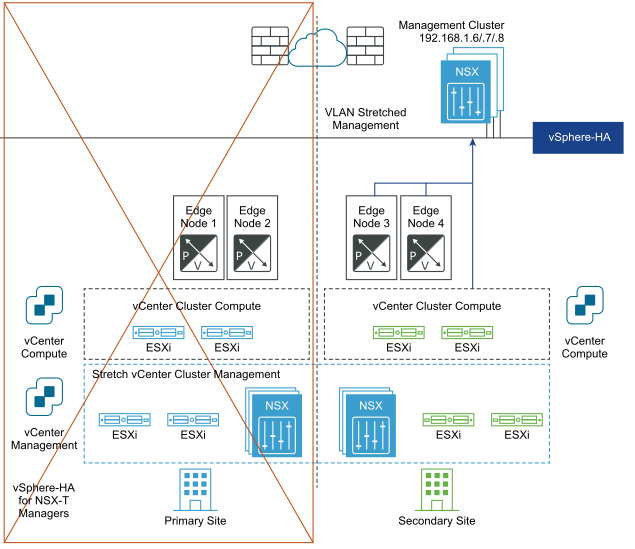
Ripristino automatico del piano dati
È possibile configurare domini di errore per i nodi Edge per ottenere il ripristino automatico del piano dati. È possibile raggruppare i nodi Edge di un cluster Edge in diversi domini di errore. NSX Manager posizionerà automaticamente qualsiasi nuovo gateway attivo di livello 1 nel dominio di errore preferito e il gateway di livello 1 di standby nell'altro dominio. Si tenga presente che un T1 distribuito prima della creazione del dominio di errore manterrà il posizionamento del nodo Edge originale e potrebbe non essere in esecuzione nella posizione desiderata. Se si desidera correggerne il posizionamento, modificare T1 e selezionare manualmente i nodi Edge per T1-Attivo e T1-Standby.
- La latenza massima tra i nodi Edge è 10 ms.
- Il routing nord-sud asimmetrico non è realizzabile, ad esempio un firewall fisico viene utilizzato in nordbound verso il nodo di NSX Edge, la modalità HA per il gateway di livello 0 deve essere attivo-standby e la modalità di failover deve essere preventiva.
- Se il routing nord-sud asimmetrico è possibile, ad esempio le due posizioni sono due edifici senza alcun firewall fisico tra loro, la modalità HA per il gateway di livello 0 può essere attiva-attiva.
I nodi Edge possono essere macchine virtuali o bare-metal. La modalità di failover del gateway di livello 1 può essere preventiva o non preventiva, ma è consigliata la modalità preventiva per garantire che i gateway di livello 0 e 1 si trovino nella stessa posizione.
- Utilizzando l'API, creare domini di errore per i due siti, ad esempio FD1A-Preferred_Site1 e FD2A-Preferred_Site1.
Nota: Se si desidera che tutti i nodi di livello 1 con T1-Attivo nei nodi Edge e T1-Standby negli altri nodi Edge facciano parte dello stesso dominio di errore (FD1A-Preferred_Site1 e FD2A-Preferred_Site1), è innanzitutto necessario creare il livello 1 con l'opzione preventiva e quindi creare il dominio di errore primario (FD1A-Preferred_Site1) impostato su
preferred_active_edge_services = true. Ad esempio,POST /api/v1/failure-domains { "display_name": "FD1A-Preferred_Site1", "preferred_active_edge_services": "true" } POST /api/v1/failure-domains { "display_name": "FD2A-Preferred_Site1", "preferred_active_edge_services": "false" } - Utilizzando l'API, configurare un cluster Edge esteso tra i due siti. Ad esempio, il cluster include i nodi Edge EdgeNode1A e EdgeNode1B nel sito primario e i nodi Edge EdgeNode2A e EdgeNode2B nel sito secondario. I gateway attivi di livello 0 e 1 verranno eseguiti in EdgeNode1A e EdgeNode1B. I gateway di livello 0 e 1 di standby verranno eseguiti in EdgeNode2A e EdgeNode2B.
- Utilizzando l'API, associare ogni nodo Edge al dominio di errore per il sito. Chiamare innanzitutto l'API
GET /api/v1/transport-nodes/<transport-node-id>per recuperare i dati relativi al nodo Edge. Utilizzare il risultato dell'API GET come input per l'API lPUT /api/v1/transport-nodes/<transport-node-id>, con la proprietà aggiuntiva failure_domain_id impostata correttamente. Ad esempio,GET /api/v1/transport-nodes/<transport-node-id> Response: { "resource_type": "TransportNode", "_revision": 15" "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... } PUT /api/v1/transport-nodes/<transport-node-id> { "resource_type": "TransportNode", "_revision": 15" "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... "failure_domain_id": "<UUID>", } - Utilizzando l'API, configurare il cluster Edge in modo da allocare i nodi in base a un dominio di errore. Chiamare innanzitutto l'API
GET /api/v1/edge-clusters/<edge-cluster-id>per recuperare i dati relativi al cluster Edge. Utilizzare il risultato dell'API GET come input per l'APIPUT /api/v1/edge-clusters/<edge-cluster-id>, con la proprietà aggiuntiva allocation_rules impostata correttamente. Ad esempio,GET /api/v1/edge-clusters/<edge-cluster-id> Response: { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... } PUT /api/v1/edge-clusters/<edge-cluster-id> { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... "allocation_rules": [ { "action": { "enabled": true, "action_type": "AllocationBasedOnFailureDomain" } } ], } - Creare gateway di livello 0 e livello 1 utilizzando l'API o l'interfaccia utente di NSX Manager.
In caso di errore di tutto il sito primario, i gateway standby di livello 0 e di livello 1 nel sito secondario subentrano automaticamente e diventano i nuovi gateway attivi.
I diagrammi seguenti illustrano il ripristino automatico del piano dati.
Prima del ripristino di emergenza:
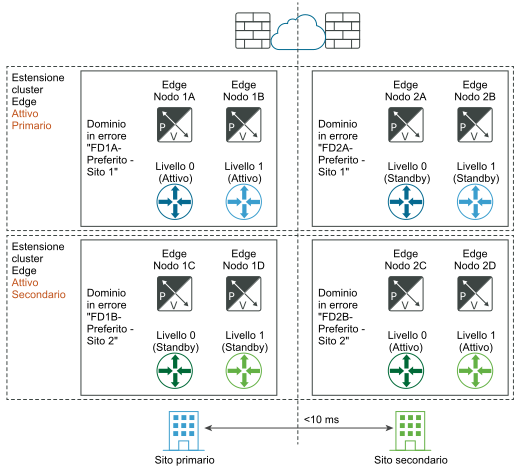
Dopo il ripristino di emergenza:
In caso di errore di uno dei nodi Edge nel sito primario e non di un errore del sito completo, è importante tenere presente che si applica lo stesso principio. Ad esempio, nel diagramma "Prima del ripristino di emergenza", si supponga che il nodo Edge 1B ospiti il livello 1-blu attivo e che il nodo Edge 2B ospiti il livello 1-blu in standby. Se il nodo Edge 1B non riesce, il livello 1-blu in standby nel nodo Edge 2B prende il controllo e diventa il nuovo gateway attivo di livello 1.
Ripristino manuale/controllato da script del piano di gestione
- DNS per NSX Manager con TTL breve, ad esempio 5 minuti.
- Backup continuo di NSX Manager.
Non sono necessari né vSphere HA, né una VLAN di gestione estesa. NSX Manager deve essere associato a un nome DNS con TTL breve. Tutti i nodi di trasporto (nodi Edge e hypervisor) devono connettersi a NSX Manager utilizzando il loro nome DNS. Per risparmiare tempo, è possibile facoltativamente preinstallare un cluster NSX Manager nel sito secondario.
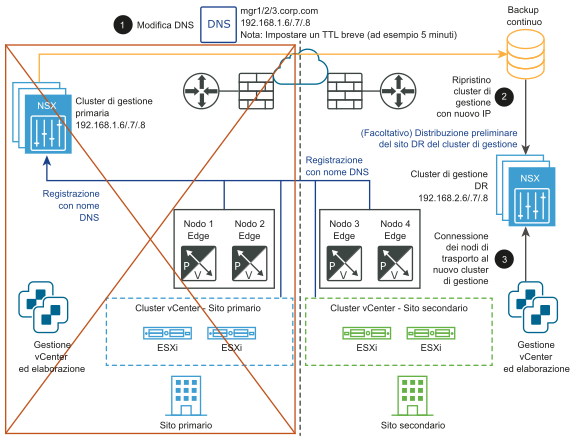
- Modificare il record DNS in modo che il cluster NSX Manager presenti indirizzi IP diversi.
- Ripristinare il cluster NSX Manager da un backup.
- Connettere i nodi di trasporto al nuovo cluster NSX Manager.
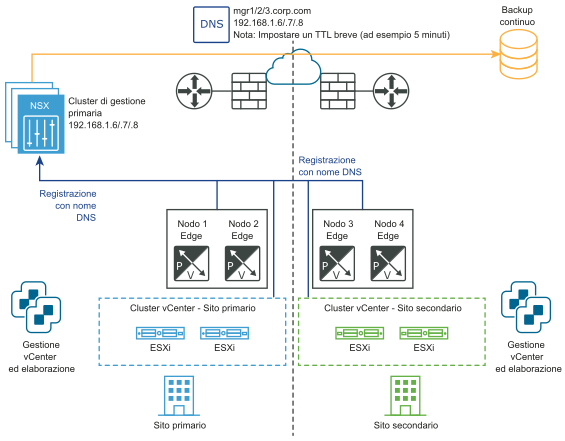
I diagrammi seguenti illustrano il ripristino manuale/controllato da script del piano di gestione.
Prima del ripristino di emergenza:
Dopo il ripristino di emergenza:
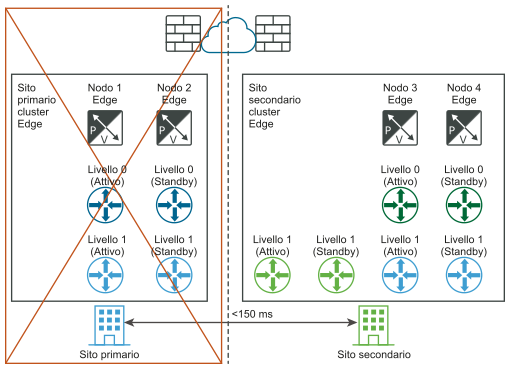
Ripristino manuale/controllato da script del piano dati
Requisito: la latenza massima tra i nodi Edge deve essere di 150 ms.
I nodi Edge possono essere macchine virtuali o bare-metal. I gateway di livello 0 in ogni posizione possono essere attivo-standby o attivo-attivo. Le macchine virtuali del nodo Edge possono essere installate in vCenter Server diversi. vSphere HA non è necessario.
- Per tutti i livelli 1 nel sito primario (blu), aggiornare la configurazione del cluster Edge in modo che sia il sito del cluster Edge secondario.
- Per tutti i livelli 1 nel sito primario (blu), riconnetterli a T0 secondario (verde).
I diagrammi seguenti illustrano il ripristino manuale/controllato da script del piano dati con entrambe le viste della rete logica e fisica.
Prima del ripristino di emergenza (visualizzazioni logiche e fisiche):
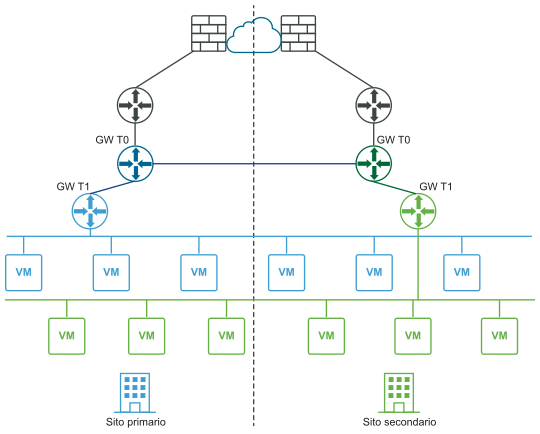
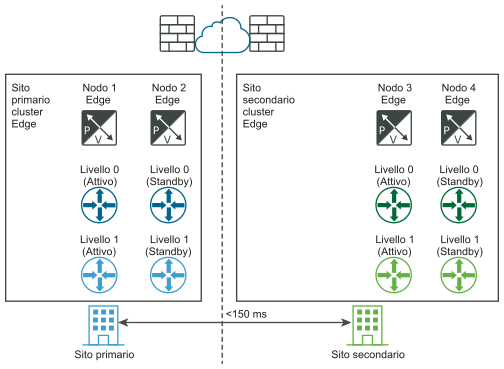
Dopo il ripristino di emergenza (visualizzazioni logiche e fisiche):
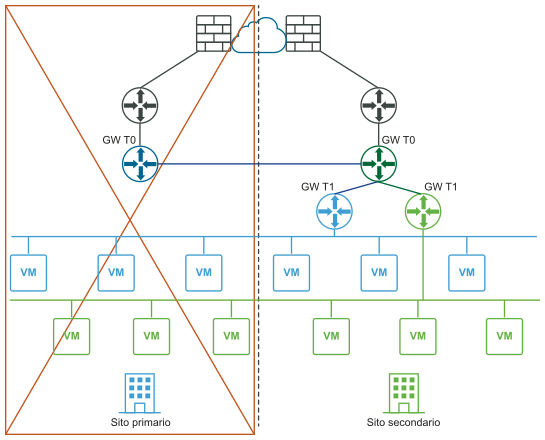
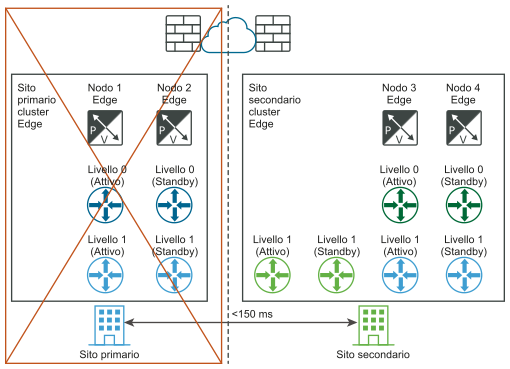
Requisiti per le distribuzioni multisito
- La larghezza di banda deve essere pari ad almeno 1 Gbps e la latenza (RTT) deve essere inferiore a 150 ms.
- La MTU deve essere pari ad almeno 1600. Il valore consigliato è 9000.
- Con ripristino automatico del piano di gestione con gestione VLAN estesa tra i siti. vSphere HA tra i siti per le macchine virtuali di NSX Manager.
- Con ripristino manuale/controllato da script del piano di gestione con gestione VLAN estesa tra i siti. VMware SRM per le macchine virtuali di NSX Manager.
- Con ripristino manuale/controllato da script del piano di gestione senza gestione VLAN estesa tra i siti.
- Backup continuo di NSX Manager.
- NSX Manager deve essere configurato per l'utilizzo del nome di dominio completo.
- Se gli indirizzi IP pubblici vengono esposti tramite servizi come NAT o il bilanciamento del carico, è necessario utilizzare lo stesso provider Internet.
- Con il ripristino automatico del piano di gestione
- La latenza massima tra le posizioni è 10 ms.
- La modalità HA per il gateway di livello 0 deve essere attiva-standby e la modalità di failover deve essere preventiva per evitare il routing asimmetrico.
- La modalità HA per il gateway di livello 0 può essere attiva-attiva se il routing asimmetrico è accettato (ad esempio edifici diversi in una regione metropolitana).
- Con ripristino manuale/controllato da script del piano di gestione
- La latenza massima tra le posizioni è 150 ms.
- CMS deve supportare un plug-in NSX. In questa versione, VMware Integrated OpenStack (VIO) e vRealize Automation (vRA) soddisfano questo requisito.
Limitazioni
- Nessuna funzionalità di uscita locale. Tutto il traffico nord-sud deve avvenire all'interno di un sito.
- Il software per il ripristino di emergenza deve supportare NSX, ad esempio VMware SRM 8.1.2 o versione successiva.
- Se si ripristinano NSX Manager in un ambiente con più siti, eseguire le operazioni seguenti nel sito secondario/primario:
- Dopo la sospensione del processo di ripristino al passaggio AggiungiNodoACluster, è innanzitutto necessario rimuovere il VIP esistente e impostare il nuovo IP virtuale dalla pagina Interfaccia utente prima di aggiungere altri nodi del gestore.
- Aggiungere nuovi nodi a un cluster con un solo nodo ripristinato dopo l'aggiornamento del VIP.
