









La funzionalità di ripristino di emergenza (disaster recovery) di SASE Orchestrator previene la perdita dei dati archiviati e riprende i servizi di SASE Orchestrator in caso di errore di sistema o di rete.
- L'obiettivo di tempo di ripristino (RTO) dipende pertanto dall'azione esplicita dell'operatore per l'attivazione della promozione dello standby.
- L'obiettivo punto di ripristino (RPO) è tuttavia essenzialmente zero, indipendentemente dal tempo di recupero, perché tutte le configurazioni vengono replicate istantaneamente. I dati di monitoraggio che sarebbero stati raccolti durante l'interruzione vengono memorizzati nella cache degli Edge e dei gateway in attesa della promozione dello standby.
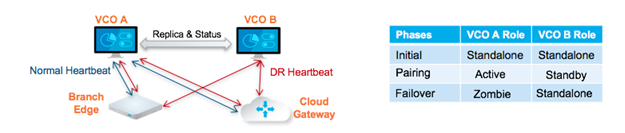
Coppia attivo/standby
In una distribuzione di ripristino di emergenza di SASE Orchestrator, due sistemi di SASE Orchestrator identici sono configurati come coppia attivo/standby. L'operatore può visualizzare lo stato della disponibilità del ripristino di emergenza tramite l'interfaccia Web su uno dei server. Gli Edge e i gateway sono consapevoli della presenza di entrambe le istanze di SASE Orchestrator e, mentre ricevono le modifiche di configurazione solo dall'SASE Orchestrator attivo, inviano periodicamente heartbeat di ripristino di emergenza a entrambi i sistemi per segnalare che sono in grado di rilevare i due server e per interrogare lo stato del sistema di ripristino di emergenza. Quando l'operatore attiva un failover, gli Edge e i gateway vengono informati della modifica nel successivo heartbeat di DR.
Stati del ripristino di emergenza
Dal punto di vista di un operatore, nonché degli Edge e dei gateway, un SASE Orchestrator può avere uno dei quattro stati di DR seguenti:
| Stato ripristino di emergenza | Descrizione |
|---|---|
| Autonomo (Standalone) | Nessun ripristino di emergenza configurato. |
| Attivo (Active) | Ripristino di emergenza configurato, operante come server SASE Orchestrator primario. |
| Standby | Ripristino di emergenza configurato, operante come server SASE Orchestrator di replica inattivo. |
| Zombie | Ripristino di emergenza precedentemente configurato e attivo, ma non operante come attivo o in standby. |
Funzionamento in fase di esecuzione
Quando il ripristino di emergenza è configurato, il server di standby è in esecuzione in modalità limitata, bloccando tutte le chiamate API a eccezione di quelle relative allo stato del ripristino di emergenza e agli heartbeat previsti dal ripristino di emergenza. Quando l'operatore richiama un failover, il server in standby viene promosso per diventare completamente operativo come server autonomo. Il server che era in precedenza attivo viene automaticamente portato in uno stato definito "Zombie" se è in grado di rispondere ed è visibile dal server di standby promosso. Nello stato di zombie, i servizi di configurazione gestione sono bloccati e qualsiasi contatto da Edge e gateway che non hanno effettuato la transizione al nuovo server SASE Orchestrator attivo viene reindirizzato al server promosso.
Configurazione della replica di SASE Orchestrator
Per avviare la replica, devono essere installate due istanze di SASE Orchestrator.
- Per l'istanza di standby selezionata viene impostato lo stato
STANDBY_CANDIDATEche ne consente la configurazione da parte del server attivo. - Al server attivo vengono quindi assegnati l'indirizzo e le credenziali dell'istanza di standby e per tale server viene impostato lo stato
ACTIVE_CONFIGURING.
STANDBY_CONFIG_RQST dall'istanza attiva all'istanza di standby, i due server vengono sincronizzati tramite le transizioni di stato.
- Il fuso orario del Gateway deve essere impostato su Etc/UTC. Utilizzare il comando seguente per visualizzare il fuso orario di NTP.
vcadmin@vcg1-example:~$ cat /etc/timezone Etc/UTC vcadmin@vcg1-example:~$
Se il fuso orario non è corretto, utilizzare i comandi seguenti per aggiornarlo.
echo "Etc/UTC" | sudo tee /etc/timezone sudo dpkg-reconfigure --frontend noninteractive tzdata
- L'offset di NTP deve essere minore o uguale a 15 millisecondi. Utilizzare il comando seguente per visualizzare l'offset di NTP.
sudo ntpqvcadmin@vcg1-example:~$ sudo ntpq -p remote refid st t when poll reach delay offset jitter ============================================================================== *ntp1-us1.prod.v 74.120.81.219 3 u 474 1024 377 10.171 -1.183 1.033 ntp1-eu1-old.pr .INIT. 16 u - 1024 0 0.000 0.000 0.000 vcadmin@vcg1-example:~$Se l'offset non è corretto, utilizzare i comandi seguenti per aggiornare l'offset NTP.
sudo systemctl stop ntp sudo ntpdate <server> sudo systemctl start ntp
- Per impostazione predefinita, nel file
/etc/ntpd.confviene configurato un elenco di server NTP. Gli Orchestrator in cui è necessario stabilire il ripristino di emergenza devono disporre di Internet per accedere ai server NTP predefiniti e assicurarsi che l'ora sia sincronizzata in entrambi gli Orchestrator. I clienti possono inoltre utilizzare il server NTP locale in esecuzione nel proprio ambiente per sincronizzare l'ora.
Configurazione dell'Orchestrator di standby
Per configurare l'Orchestrator di standby, eseguire i passaggi seguenti:
- Nel servizio SD-WAN del portale dell'azienda, fare clic sulla scheda Orchestrator e quindi nel riquadro sinistro fare clic sul pulsante Replica (Replication) per visualizzare la schermata Replica Orchestrator (Orchestrator Replication).
- Attivare l'Orchestrator di standby selezionando il pulsante di opzione Standby (ruolo replica).
- Fare clic sul pulsante Abilita per standby (Enable for Standby).
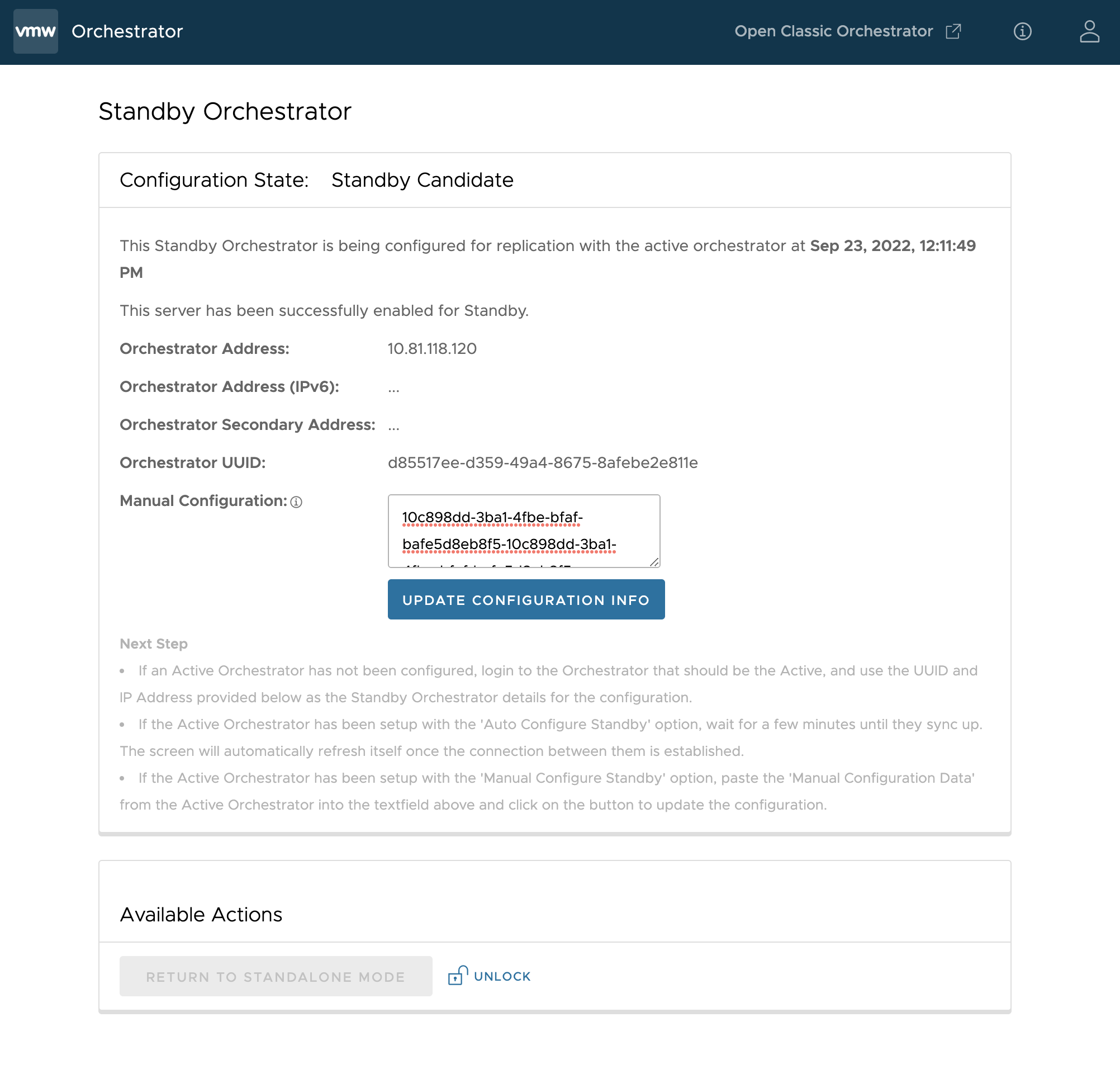
Viene visualizzata la pagina Orchestrator di standby (Standby Orchestrator).
- Immettere i parametri della Configurazione manuale (Manuale Configuration) e fare clic sul pulsante Aggiorna informazioni di configurazione (Update Configuration Info).
Dopo aver configurato l'Orchestrator di standby per la replica, configurare l'Orchestrator attivo in base alle istruzioni seguenti.
Configurazione dell'Orchestrator attivo
Per configurare l'Orchestrator attivo, selezionare il Ruolo replica (Replication Role) come Attivo (Active) e configurare quanto segue
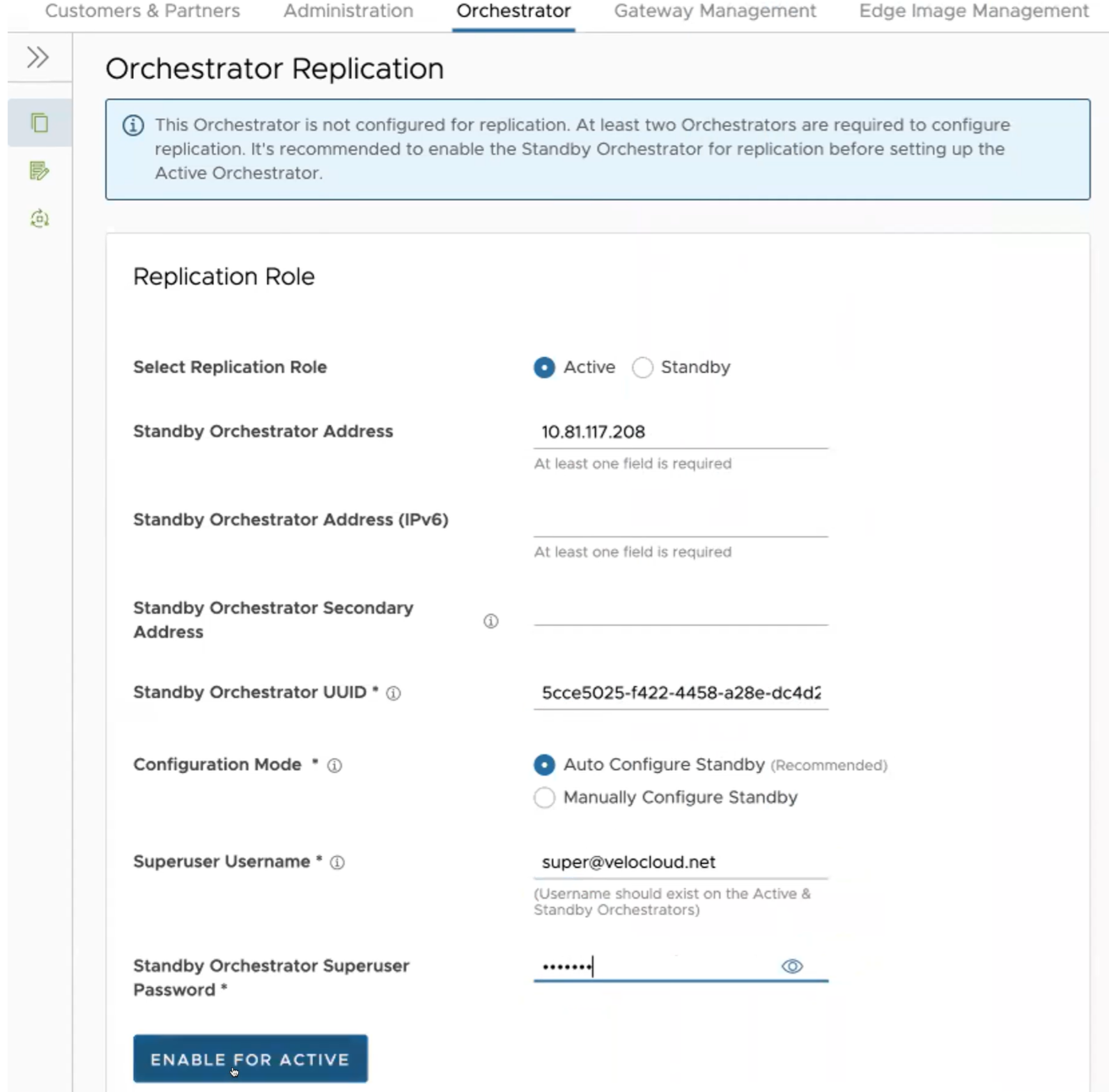
| Opzione | Descrizione |
|---|---|
| Selezionare il ruolo replica (Select Replication Role) | Selezionare il pulsante di opzione Attivo (Active) per il ruolo di replica. |
| Indirizzo Orchestrator di standby (Standby Orchestrator Address) | Immettere l'indirizzo IP dell'Orchestrator di standby primario. |
| Indirizzo Orchestrator di standby (IPv6) (Standby Orchestrator Address (IPv6)) | Immettere l'indirizzo IPv6 dell'Orchestrator di standby. |
| Indirizzo secondario Orchestrator di standby (Standby Orchestrator Secondary Address) | Immettere l'indirizzo dell'interfaccia secondaria dell'Orchestrator di standby. Questo indirizzo viene utilizzato per la replica se l'Orchestrator di standby viene promossa ad Attivo (Active). Gli utenti possono aggiungere qui l'indirizzo IPv4/IPv6 o il nome di dominio completo. |
| UUID Orchestrator di standby (Standby Orchestrator UUID) | Immettere l'UUID dell'Orchestrator di standby. |
| Modalità configurazione (Configuration Mode) | Selezionare il pulsante di opzione Configura automaticamente standby (Auto Configure Standby) o Configura manualmente standby (Manually Configure Standby) in base alle esigenze. Quando viene configurato manualmente, incollare un valore stringa da ACTIVE VCO a STANDBY_WAIT . |
| Nome utente superuser (Superuser Username) | Immettere il nome visualizzato per il superuser di Orchestrator. |
| Password superuser Orchestrator di standby (Standby Orchestrator Superuser Password) | Immettere la password del superuser di Orchestrator. |
- Fare clic sul pulsante Abilita per Attivo (Enable for Active) per attivare il ruolo di replica.
Al termine della configurazione, entrambi gli Orchestrator (standby e attivo) saranno sincronizzati.
Orchestrator di standby sincronizzato
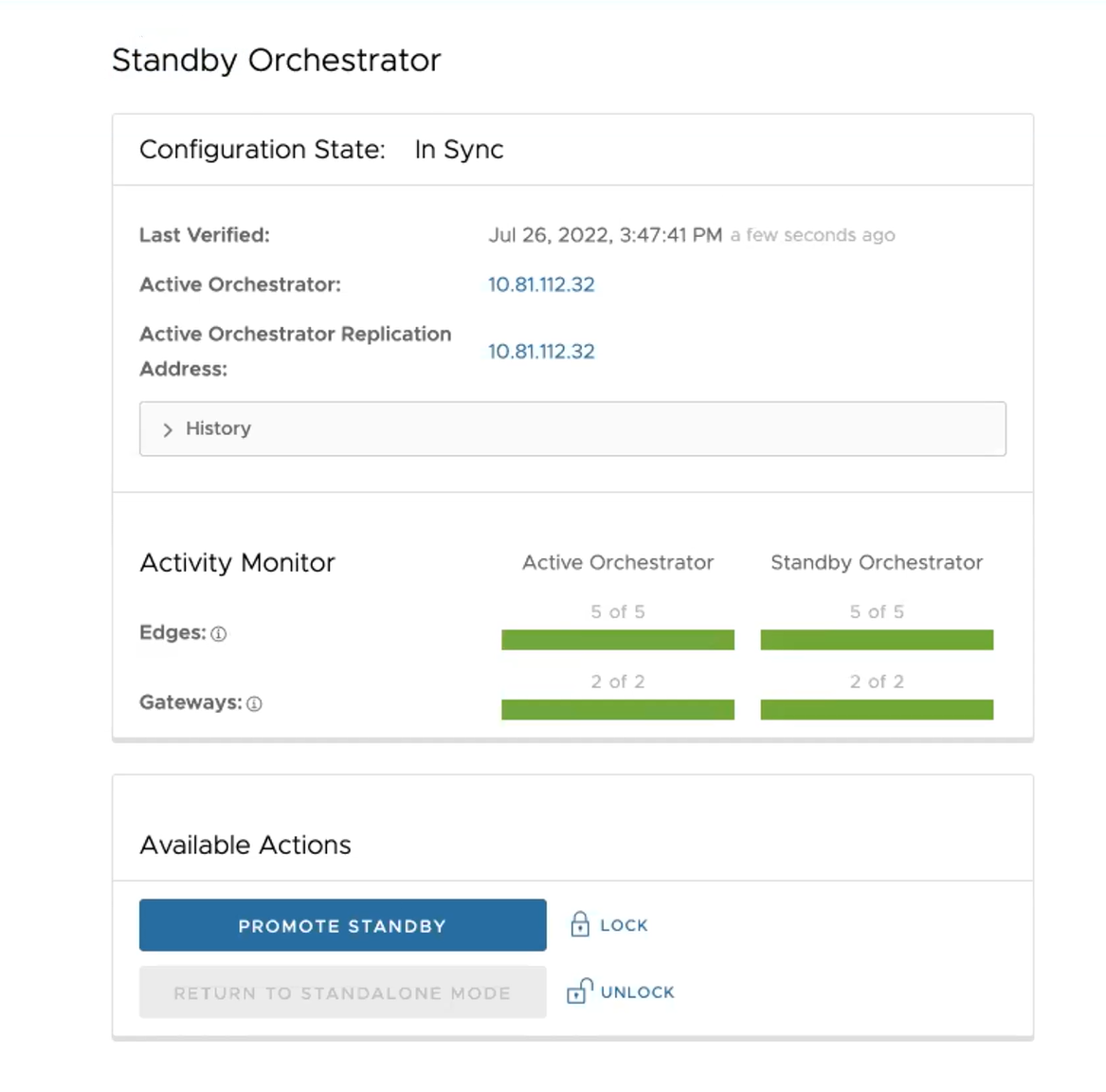
Orchestrator attivo sincronizzato
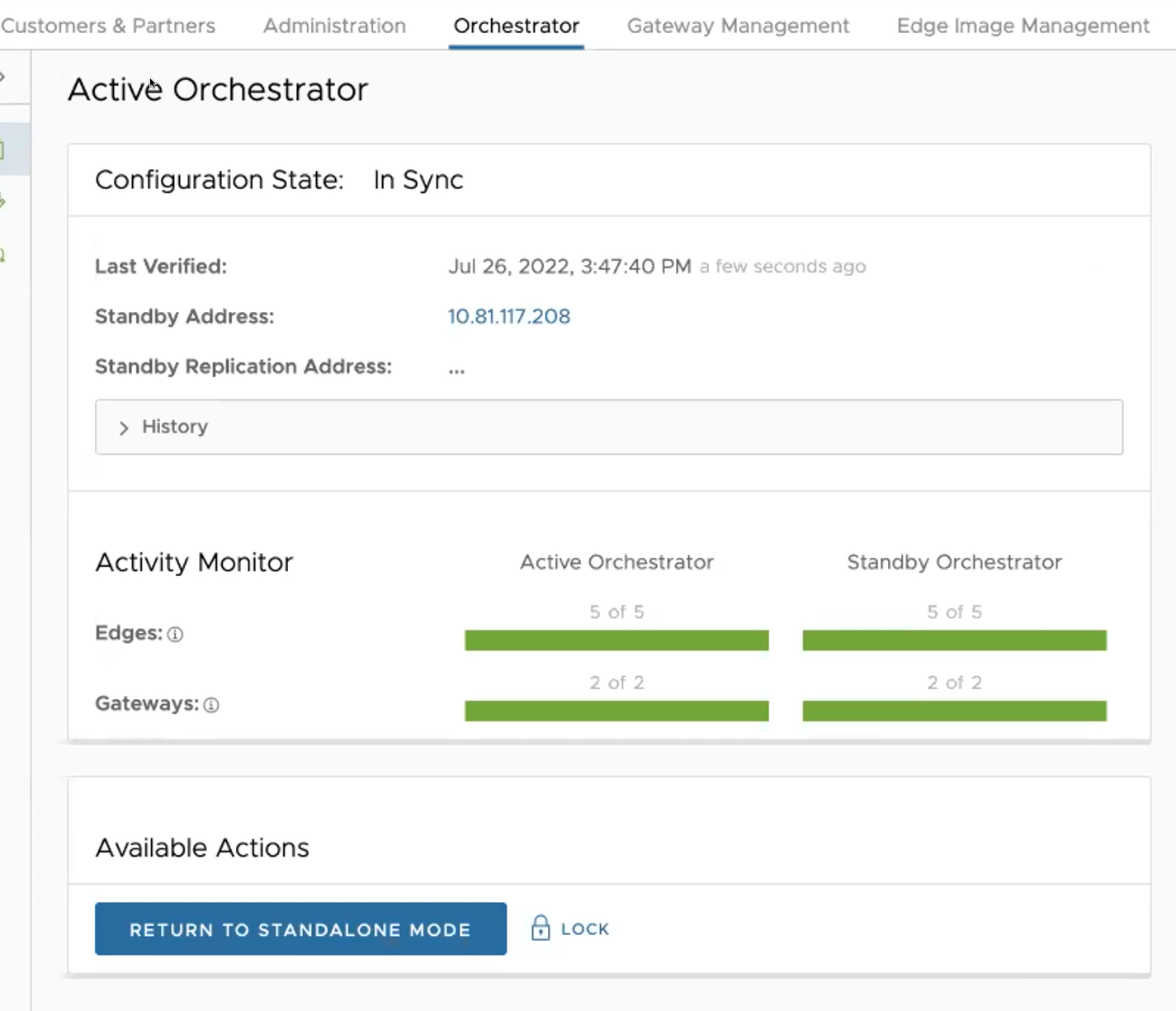
Test del failover
I seguenti scenari di testing del failover fanno riferimento a failover forzati a scopo di esempio. È possibile eseguire queste azioni nell'area Azioni disponibili (Available Actions) delle schermate Attivo (Active) e Standby.
Promozione di un Orchestrator di standby
Questa sezione illustra come promuovere un Orchestrator di standby.
Per promuovere un Orchestrator di standby, eseguire i passaggi seguenti:
- Fare clic sul link Sblocca (unlock).
- Fare clic sul pulsante Promuovi standby (Promote Standby) nell'area Azioni disponibili (Available Actions) della schermata dell'Orchestrator di standby.
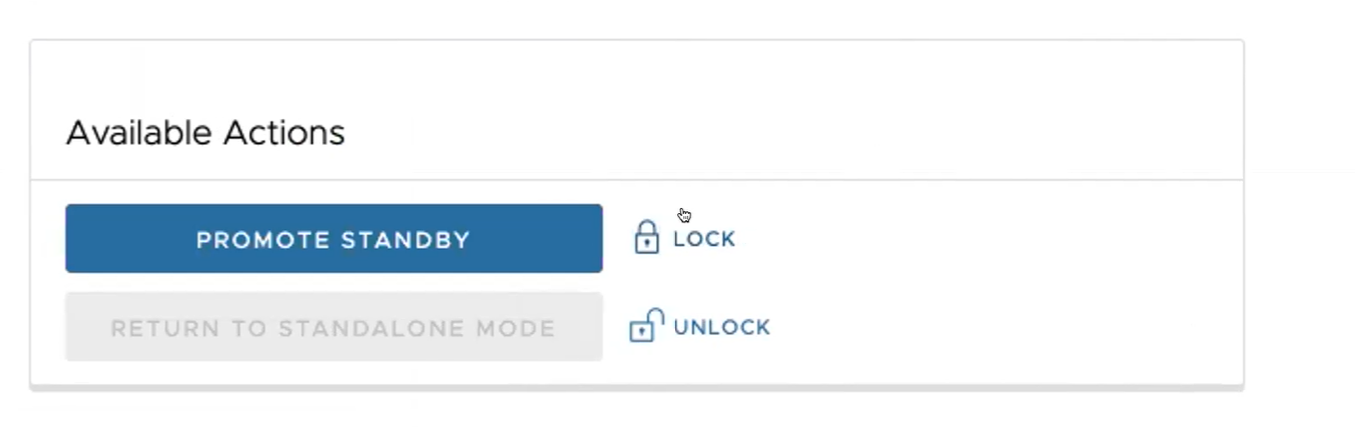
Viene visualizzata la seguente finestra di dialogo, che indica che se si promuove l'Orchestrator di standby, gli amministratori non può più gestire SASE Orchestrator utilizzando l'Orchestrator in precedenza attivo.
- Fare clic sul pulsante Promuovi Standby (Promote Standby) per promuovere l'Orchestrator di standby.
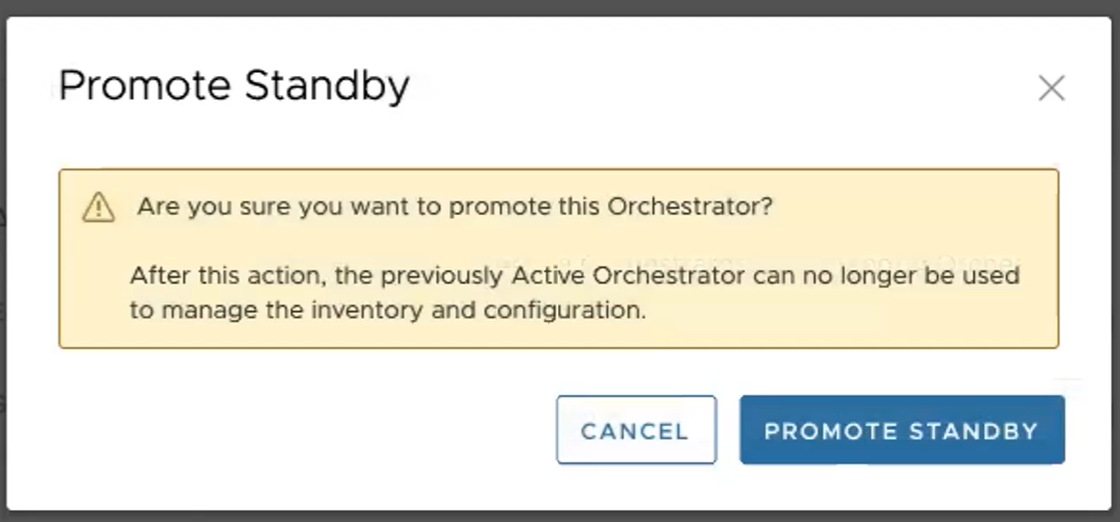
- Fare clic su Forza promozione Standby (Force Promote Standby) per promuovere l'Orchestrator.
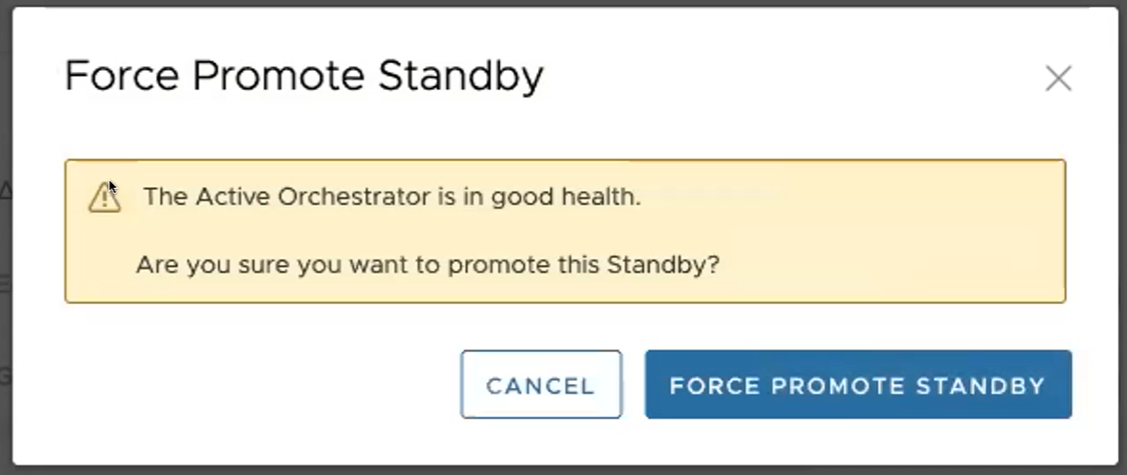
Viene visualizzata una finestra di dialogo finale che indica che l'Orchestrator non è più un Orchestrator di standby e verrà riavviato in modalità autonoma.

Quando si promuove un Orchestrator di standby, viene riavviato in modalità autonoma.
Se l'Orchestrator di standby riesce a comunicare con l'Orchestrator in precedenza attivo, indicherà a tale Orchestrator di passare allo stato non valido. Nello stato non valido, l'Orchestrator comunica ai propri client (edge, gateway, interfaccia utente/API) che non è più attivo e che devono comunicare con l'Orchestrator appena promosso. Se l'Orchestrator di standby promosso non è in grado di comunicare con l'Orchestrator in precedenza attivo, l'operatore deve declassare manualmente il livello dell'Orchestrator in precedenza attivo, se possibile.
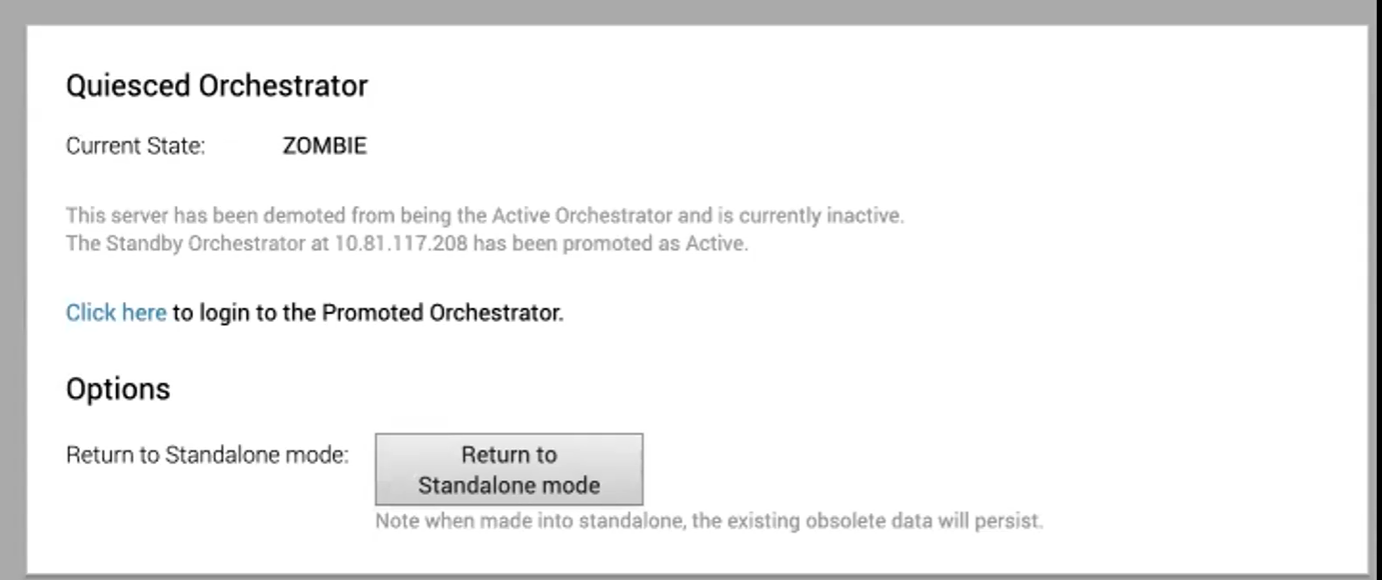
Ritorno alla modalità autonoma
Per ripristinare la modalità autonoma, fare clic sul pulsante Torna alla modalità autonoma (Return to Standalone Mode) nell'area Azioni disponibili (Available Actions) della schermata Orchestrator attivo (Active Orchestrator) o Orchestrator di standby (Standby Orchestrator).
È possibile fare in modo che Orchestrator passi di nuovo alla modalità autonoma dallo stato Zombie dopo il tempo specificato nella proprietà di sistema "vco.disasterRecovery.zombie.expirySeconds" il cui valore predefinito è 1800 secondi.
Risoluzione dei problemi del ripristino di emergenza di SASE Orchestrator
Questa sezione illustra gli stati di errore del sistema, che sono elencati anche nell'interfaccia utente, insieme a una descrizione più dettagliata di ogni errore. Nel registro di VMware sono disponibili informazioni aggiuntive.
Errori reversibili
Gli errori seguenti sono errori reversibili che possono verificarsi dopo che il ripristino di emergenza di SASE Orchestrator ha raggiunto lo stato di sincronizzazione. Se il problema che causa questi errori viene risolto, il ripristino di emergenza di SASE Orchestrator tornerà automaticamente al funzionamento normale.
FAILURE_SYNCING_FILESFAILURE_GET_STANDBY_STATUSFAILURE_MYSQL_ACTIVE_STATUSFAILURE_MYSQL_STANDBY_STATUS
Errori irreversibili
Durante la configurazione del ripristino di emergenza di SASE Orchestrator, possono verificarsi gli errori seguenti. Il ripristino di emergenza di SASE Orchestrator non verrà ripristinato automaticamente da questi errori.
FAILURE_ACTIVE_CONFIGURINGFAILURE_LAUNCHING_STANDBYFAILURE_STANDBY_CONFIGURINGFAILURE_COPYING_DBFAILURE_COPYING_FILESFAILURE_SYNC_CONFIGURINGFAILURE_GET_STANDBY_CONFIGFAILURE_STANDBY_CANDIDATEFAILURE_STANDBY_UNCONFIGFAILURE_STANDBY_PROMOTIONFAILURE_ACTIVE_DEMOTION
