









Informazioni di riferimento sulle variabili del file di configurazione
In queste informazioni di riferimento sono elencate tutte le variabili che è possibile specificare per fornire opzioni di configurazione del cluster alla CLI di Tanzu.
Per impostare queste variabili in un file di configurazione YAML, lasciare uno spazio tra i due punti (:) e il valore della variabile. Ad esempio:
CLUSTER_NAME: my-cluster
L'ordine delle righe nel file di configurazione non è importante. Qui le opzioni sono elencate in ordine alfabetico. Vedere inoltre la sezione Precedenza dei valori della configurazione di seguito.
Variabili comuni per tutte le piattaforme di destinazione
In questa sezione sono elencate le variabili comuni a tutte le piattaforme di destinazione. Queste variabili possono essere applicate ai cluster di gestione, ai cluster del carico di lavoro oppure a entrambi. Per ulteriori informazioni, vedere Informazioni sulla configurazione della creazione del cluster di gestione di base in Creazione di un file di configurazione del cluster di gestione.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
APISERVER_EVENT_RATE_LIMIT_CONF_BASE64 |
✔ | ✔ | Solo cluster basati sulla classe. Abilita e configura un controller di ammissione EventRateLimit per moderare il traffico verso il server dell'API di Kubernetes. Impostare questa proprietà creando un file di configurazione config.yaml di EventRateLimit come descritto nella documentazione di Kubernetes e quindi convertendolo in un valore stringa eseguendo base64 -w 0 config.yaml |
CAPBK_BOOTSTRAP_TOKEN_TTL |
✔ | ✖ | Facoltativa. Il valore predefinito è 15m, 15 minuti. Valore TTL del token di bootstrap utilizzato da kubeadm durante le operazioni di inizializzazione del cluster. |
CLUSTER_API_SERVER_PORT |
✔ | ✔ | Facoltativa. Il valore predefinito è 6443. Questa variabile viene ignorata se si abilita NSX Advanced Load Balancer (vSphere). Per sostituire la porta del server dell'API Kubernetes predefinita per le distribuzioni con NSX Advanced Load Balancer, impostare VSPHERE_CONTROL_PLANE_ENDPOINT_PORT. |
CLUSTER_CIDR |
✔ | ✔ | Facoltativa. Il valore predefinito è 100.96.0.0/11. Intervallo CIDR da utilizzare per i pod. Modificare il valore predefinito solo se l'intervallo default non è disponibile. |
CLUSTER_NAME |
✔ | ✔ | Questo nome deve essere conforme ai requisiti del nome host DNS in base alla RFC 952 e alla modifica indicata nella RFC 1123 e può contenere al massimo 42 caratteri. Per i cluster del carico di lavoro, questa impostazione viene sostituita dall'argomento CLUSTER_NAME passato a tanzu cluster create.Per i cluster di gestione, se non si specifica CLUSTER_NAME, viene generato un nome univoco. |
CLUSTER_PLAN |
✔ | ✔ | Obbligatoria. Impostarla su dev, prod o un piano personalizzato, come indicato in nginx di un nuovo piano.Il piano dev distribuisce un cluster con un singolo nodo del piano di controllo. Il piano prod distribuisce un cluster ad alta disponibilità con tre nodi del piano di controllo. |
CNI |
✖ | ✔ | Facoltativa. Il valore predefinito è antrea. Container network interface. Non sostituire il valore predefinito per i cluster di gestione. Per i cluster del carico di lavoro, è possibile impostare CNI su antrea, calico o none. L'opzione calico non è supportata in Windows. Per ulteriori informazioni, vedere Distribuzione di un cluster con una CNI non predefinita. Per personalizzare la configurazione di Antrea, vedere Configurazione della CNI di Antrea di seguito. |
CONTROLPLANE_CERTIFICATE_ROTATION_ENABLED |
✔ | ✔ | Facoltativa. Il valore predefinito è false. Impostarla su true se si desidera che i certificati delle macchine virtuali del nodo del piano di controllo vengano rinnovati automaticamente prima della scadenza. Per ulteriori informazioni, vedere Rinnovo automatico del certificato del nodo del piano di controllo. |
CONTROLPLANE_CERTIFICATE_ROTATION_DAYS_BEFORE |
✔ | ✔ | Facoltativa. Il valore predefinito è 90. Se CONTROLPLANE_CERTIFICATE_ROTATION_ENABLED è true, specificare quanti giorni prima della data di scadenza del certificato si desidera che il certificato del nodo del cluster venga rinnovato automaticamente. Per ulteriori informazioni, vedere Rinnovo automatico del certificato del nodo del piano di controllo. |
ENABLE_AUDIT_LOGGING |
✔ | ✔ | Facoltativa. Il valore predefinito è false. Registrazione di controllo per il server dell'API di Kubernetes. Per abilitare la creazione di un registro di controllo, impostarla su true. Tanzu Kubernetes Grid scrive questi registri in /var/log/kubernetes/audit.log. Per ulteriori informazioni, vedere Registrazione di controllo.L'abilitazione del controllo Kubernetes può causare volumi di registri molto elevati. Per gestire questa quantità, VMware consiglia di utilizzare un server di inoltro dei registri come Fluent Bit. |
ENABLE_AUTOSCALER |
✖ | ✔ | Facoltativa. Il valore predefinito è false. Se è impostata su true, è necessario impostare variabili aggiuntive nella tabella Scalabilità automatica del cluster seguente. |
ENABLE_CEIP_PARTICIPATION |
✔ | ✖ | Facoltativa. Il valore predefinito è true. Impostarla su false se non si desidera partecipare al programma Customer Experience Improvement Program di VMware. È possibile scegliere o rifiutare esplicitamente il programma anche dopo la distribuzione del cluster di gestione. Per informazioni, vedere Scelta o rifiuto del programma CEIP di VMware in Gestione della partecipazione al programma CEIP e Customer Experience Improvement Program ("CEIP"). |
ENABLE_DEFAULT_STORAGE_CLASS |
✖ | ✔ | Facoltativa. Il valore predefinito è true. Per informazioni sulle classi di storage, vedere Storage dinamico. |
ENABLE_MHC e così via |
✔ | ✔ | Facoltativa. Vedere Controlli di integrità delle macchine di seguito per informazioni sul set completo delle variabili MHC e sul loro funzionamento.Per i cluster del carico di lavoro creati da vSphere with Tanzu, impostare ENABLE_MHC su false. |
IDENTITY_MANAGEMENT_TYPE |
✔ | ✖ | Facoltativa. Il valore predefinito è none.Per i cluster di gestione: impostare |
INFRASTRUCTURE_PROVIDER |
✔ | ✔ | Obbligatoria. Impostare su vsphere, aws, azure o tkg-service-vsphere. |
NAMESPACE |
✖ | ✔ | Facoltativa; il valore predefinito è default, per distribuire i cluster del carico di lavoro in uno spazio dei nomi denominato default. |
SERVICE_CIDR |
✔ | ✔ | Facoltativa; il valore predefinito è 100.64.0.0/13. Intervallo CIDR da utilizzare per i servizi Kubernetes. Modificare questo valore solo se l'intervallo predefinito non è disponibile. |
Provider di identità - OIDC
Se si imposta IDENTITY_MANAGEMENT_TYPE: oidc, impostare le variabili seguenti per configurare un provider di identità OIDC. Per ulteriori informazioni, vedere Configurazione della gestione delle identità in Creazione di un file di configurazione del cluster di gestione.
Tanzu Kubernetes Grid si integra con OIDC tramite Pinniped, come descritto in Informazioni sulla gestione di identità e accessi.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
CERT_DURATION |
✔ | ✖ | Facoltativa. Il valore predefinito è 2160h. Impostare questa variabile se si configura Pinniped in modo che utilizzino certificati autofirmati gestiti da cert-manager. |
CERT_RENEW_BEFORE |
✔ | ✖ | Facoltativa. Il valore predefinito è 360h. Impostare questa variabile se si configura Pinniped in modo che utilizzino certificati autofirmati gestiti da cert-manager. |
OIDC_IDENTITY_PROVIDER_CLIENT_ID |
✔ | ✖ | Obbligatoria. Valore di client_id ottenuto dal provider OIDC. Ad esempio, se il provider è Okta, accedere a Okta, creare un'applicazione Web e selezionare le opzioni di Credenziali client (Client Credentials) per ottenere client_id e secret. Questa impostazione verrà archiviata in un segreto a cui OIDCIdentityProvider.spec.client.secretName fa riferimento nella risorsa personalizzata OIDCIdentityProvider di Pinniped. |
OIDC_IDENTITY_PROVIDER_CLIENT_SECRET |
✔ | ✖ | Obbligatoria. valore di secret ottenuto dal provider OIDC. Non codificare questo valore in base64. |
OIDC_IDENTITY_PROVIDER_GROUPS_CLAIM |
✔ | ✖ | Facoltativa. Nome della richiesta di gruppi. Questa variabile viene utilizzata per impostare il gruppo di un utente nella richiesta JSON Web Token (JWT). Il valore predefinito è groups. Questa impostazione corrisponde a OIDCIdentityProvider.spec.claims.groups nella risorsa personalizzata OIDCIdentityProvider di Pinniped. |
OIDC_IDENTITY_PROVIDER_ISSUER_URL |
✔ | ✖ | Obbligatoria. Indirizzo IP o DNS del server OIDC. Questa impostazione corrisponde a OIDCIdentityProvider.spec.issuer in custom resource di Pinniped. |
OIDC_IDENTITY_PROVIDER_SCOPES |
✔ | ✖ | Obbligatoria. Elenco delimitato da virgole degli ambiti aggiuntivi da richiedere nella risposta del token. Ad esempio, "email,offline_access". Questa impostazione corrisponde a OIDCIdentityProvider.spec.authorizationConfig.additionalScopes nella risorsa personalizzata OIDCIdentityProvider di Pinniped. |
OIDC_IDENTITY_PROVIDER_USERNAME_CLAIM |
✔ | ✖ | Obbligatoria. Nome della richiesta del nome utente. Questa variabile viene utilizzata per impostare il nome utente di un utente nella richiesta JWT. In base al provider in uso, immettere richieste come user_name, email o code. Questa impostazione corrisponde a OIDCIdentityProvider.spec.claims.username nella risorsa personalizzata OIDCIdentityProvider di Pinniped. |
OIDC_IDENTITY_PROVIDER_ADDITIONAL_AUTHORIZE_PARAMS |
✔ | ✖ | Facoltativa. Aggiungere parametri personalizzati da inviare al provider di identità OIDC. In base al provider, queste richieste potrebbero essere necessarie per ricevere un token di aggiornamento dal provider. Ad esempio prompt=consent. Separare i valori multipli con virgole. Questa impostazione corrisponde a OIDCIdentityProvider.spec.authorizationConfig.additionalAuthorizeParameters nella risorsa personalizzata OIDCIdentityProvider di Pinniped. |
OIDC_IDENTITY_PROVIDER_CA_BUNDLE_DATA_B64 |
✔ | ✖ | Facoltativa. Un bundle CA con codifica Base64 per stabilire TLS con i provider di identità OIDC. Questa impostazione corrisponde a OIDCIdentityProvider.spec.tls.certificateAuthorityData nella risorsa personalizzata OIDCIdentityProvider di Pinniped. |
SUPERVISOR_ISSUER_URL |
✔ | ✖ | Non modificarla. Questa variabile viene aggiornata automaticamente nel file di configurazione quando si esegue il comando tanzu cluster create command. Questa impostazione corrisponde a JWTAuthenticator.spec.audience nella risorsa personalizzata JWTAuthenticator di Pinniped e FederationDomain.spec.issuer nella risorsa personalizzata FederationDomain di Pinniped. |
SUPERVISOR_ISSUER_CA_BUNDLE_DATA_B64 |
✔ | ✖ | Non modificarla. Questa variabile viene aggiornata automaticamente nel file di configurazione quando si esegue il comando tanzu cluster create command. Questa impostazione corrisponde a JWTAuthenticator.spec.tls.certificateAuthorityData nella risorsa personalizzata JWTAuthenticator di Pinniped. |
Provider di identità - LDAP
Se si imposta IDENTITY_MANAGEMENT_TYPE: ldap, impostare le variabili seguenti per configurare un provider di identità LDAP. Per ulteriori informazioni, vedere Configurazione della gestione delle identità in Creazione di un file di configurazione del cluster di gestione.
Tanzu Kubernetes Grid si integra con LDAP tramite Pinniped, come descritto in Informazioni sulla gestione di identità e accessi. Ciascuna delle variabili seguenti corrisponde a un'impostazione di configurazione nella risorsa personalizzata LDAPIdentityProvider di Pinniped. Per una descrizione completa di queste impostazioni e informazioni su come configurarle, vedere LDAPIdentityProvider nella documentazione di Pinniped.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
| Per la connessione al server LDAP: | |||
LDAP_HOST |
✔ | ✖ | Obbligatorio. Indirizzo IP o DNS del server LDAP. Se il server LDAP è in ascolto nella porta predefinita 636, ovvero la configurazione protetta, non è necessario specificare la porta. Se il server LDAP è in ascolto in una porta diversa, specificare l'indirizzo e la porta del server LDAP, nel formato "host:port". Questa impostazione corrisponde a LDAPIdentityProvider.spec.host nella risorsa personalizzata LDAPIdentityProvider di Pinniped. |
LDAP_ROOT_CA_DATA_B64 |
✔ | ✖ | Facoltativa. Se si utilizza un endpoint LDAPS, incollare i contenuti codificati Base64 del certificato del server LDAP. Questa impostazione corrisponde a LDAPIdentityProvider.spec.tls.certificateAuthorityData nella risorsa personalizzata LDAPIdentityProvider di Pinniped. |
LDAP_BIND_DN |
✔ | ✖ | Obbligatorio. DN per l'account di servizio di un'applicazione esistente. Ad esempio, "cn=bind-user,ou=people,dc=example,dc=com". Il connettore utilizza queste credenziali per cercare utenti e gruppi. Questo account di servizio deve disporre come minimo delle autorizzazioni di sola lettura per eseguire le query configurate dalle altre opzioni di configurazione LDAP_*. Incluso nel segreto per spec.bind.secretName nella risorsa personalizzata LDAPIdentityProvider di Pinniped. |
LDAP_BIND_PASSWORD |
✔ | ✖ | Obbligatorio. Password dell'account del servizio applicazioni impostato in LDAP_BIND_DN. Incluso nel segreto per spec.bind.secretName nella risorsa personalizzata LDAPIdentityProvider di Pinniped. |
| Per la ricerca dell'utente: | |||
LDAP_USER_SEARCH_BASE_DN |
✔ | ✖ | Obbligatorio. Punto da cui avviare la ricerca LDAP. Ad esempio, OU=Users,OU=domain,DC=io. Questa impostazione corrisponde a LDAPIdentityProvider.spec.userSearch.base nella risorsa personalizzata LDAPIdentityProvider di Pinniped. |
LDAP_USER_SEARCH_FILTER |
✔ | ✖ | Facoltativa. filtro facoltativo che deve essere utilizzato dalla ricerca LDAP. Questa impostazione corrisponde a LDAPIdentityProvider.spec.userSearch.filter nella risorsa personalizzata LDAPIdentityProvider di Pinniped. A partire da TKG v2.3, quando si crea un cluster di gestione o si aggiorna il segreto del pacchetto Pinniped per un cluster di gestione esistente, è necessario utilizzare il formato Pinniped per questo valore. Ad esempio &(objectClass=posixAccount)(uid={}). |
LDAP_USER_SEARCH_ID_ATTRIBUTE |
✔ | ✖ | Facoltativa. Attributo LDAP che contiene l'ID utente. Il valore predefinito è dn. Questa impostazione corrisponde a LDAPIdentityProvider.spec.userSearch.attributes.uid nella risorsa personalizzata LDAPIdentityProvider di Pinniped. |
LDAP_USER_SEARCH_NAME_ATTRIBUTE |
✔ | ✖ | Obbligatorio. Attributo LDAP che contiene il nome dell'utente specificato. Ad esempio mail. Questa impostazione corrisponde a LDAPIdentityProvider.spec.userSearch.attributes.username nella risorsa personalizzata LDAPIdentityProvider di Pinniped. |
| Per la ricerca di gruppi: | |||
LDAP_GROUP_SEARCH_BASE_DN |
✔ | ✖ | Facoltativa. Punto da cui avviare la ricerca LDAP. Ad esempio, OU=Groups,OU=domain,DC=io. Quando non è impostato, la ricerca del gruppo viene ignorata. Questa impostazione corrisponde a LDAPIdentityProvider.spec.groupSearch.base nella risorsa personalizzata LDAPIdentityProvider di Pinniped. |
LDAP_GROUP_SEARCH_FILTER |
✔ | ✖ | Facoltativa. filtro facoltativo che deve essere utilizzato dalla ricerca LDAP. Questa impostazione corrisponde a LDAPIdentityProvider.spec.groupSearch.filer nella risorsa personalizzata LDAPIdentityProvider di Pinniped. A partire da TKG v2.3, quando si crea un cluster di gestione o si aggiorna il segreto del pacchetto Pinniped per un cluster di gestione esistente, è necessario utilizzare il formato Pinniped per questo valore. Ad esempio &(objectClass=posixGroup)(memberUid={}). |
LDAP_GROUP_SEARCH_NAME_ATTRIBUTE |
✔ | ✖ | Facoltativa. Attributo LDAP che contiene il nome del gruppo. Il valore predefinito è dn. Questa impostazione corrisponde a LDAPIdentityProvider.spec.groupSearch.attributes.groupName nella risorsa personalizzata LDAPIdentityProvider di Pinniped. |
LDAP_GROUP_SEARCH_USER_ATTRIBUTE |
✔ | ✖ | Facoltativa. Attributo del record utente utilizzato come valore dell'attributo di appartenenza del record gruppo. Il valore predefinito è dn. Questa impostazione corrisponde a LDAPIdentityProvider.spec.groupSearch.userAttributeForFilter nella risorsa personalizzata LDAPIdentityProvider di Pinniped. |
LDAP_GROUP_SEARCH_SKIP_ON_REFRESH |
✔ | ✖ | Facoltativa. Il valore predefinito è false. Quando è impostata su true, le appartenenze al gruppo di un utente vengono aggiornate solo all'inizio della sessione giornaliera dell'utente. L'impostazione di LDAP_GROUP_SEARCH_SKIP_ON_REFRESH su true non è consigliata e deve essere eseguita solo quando non è possibile rendere sufficientemente veloce l'esecuzione della query del gruppo durante l'aggiornamento della sessione. Questa impostazione corrisponde a LDAPIdentityProvider.spec.groupSearch.skipGroupRefresh nella risorsa personalizzata LDAPIdentityProvider di Pinniped. |
Configurazione del nodo
Configurare il piano di controllo e i nodi worker, nonché il sistema operativo eseguito dalle istanze del nodo. Per ulteriori informazioni, vedere Configurazione delle impostazioni del nodo in Creazione di un file di configurazione del cluster di gestione.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
CONTROL_PLANE_MACHINE_COUNT |
✔ | ✔ | Facoltativa. Distribuire un cluster del carico di lavoro con un numero di nodi del piano di controllo maggiore del numero predefinito dei piani dev e prod. Il numero di nodi del piano di controllo specificato deve essere dispari. |
CONTROL_PLANE_NODE_LABELS |
✔ | ✔ | Solo cluster basati sulla classe. Assegnare etichette persistenti personalizzate ai nodi del piano di controllo, ad esempio CONTROL_PLANE_NODE_LABELS: 'key1=value1,key2=value2'. Per configurare questa variabile in un cluster legacy basato sul piano, utilizzare un overlay ytt come descritto in Etichette dei nodi personalizzati.Le etichette dei nodi worker vengono impostate nel relativo pool di nodi come descritto in Gestione di pool di nodi di diversi tipi di macchine virtuali. |
CONTROL_PLANE_NODE_NAMESERVERS |
✔ | ✔ | Solo vSphere. In questo modo l'utente può specificare un elenco delimitato da virgole di server DNS da configurare nei nodi del piano di controllo, ad esempio CONTROL_PLANE_NODE_NAMESERVERS: 10.132.7.1, 10.142.7.1. Supportato su Ubuntu e Photon; non supportato in Windows. Per un caso d'uso di esempio, vedere l'IPAM del nodo di seguito. |
CONTROL_PLANE_NODE_SEARCH_DOMAINS |
✔ | ✔ | Solo cluster basati sulla classe. Configura i domini di ricerca .local per i nodi del cluster, ad esempio CONTROL_PLANE_NODE_SEARCH_DOMAINS: corp.local. Per configurare questa variabile in un cluster legacy basato sul piano in vSphere, utilizzare un overlay ytt come descritto in Risoluzione del dominio .local. |
CONTROLPLANE_SIZE |
✔ | ✔ | Facoltativa. Dimensioni delle macchine virtuali del nodo del piano di controllo. Sostituisce i parametri SIZE e VSPHERE_CONTROL_PLANE_*. Per i possibili valori, vedere SIZE. |
OS_ARCH |
✔ | ✔ | Facoltativa. Architettura del sistema operativo della macchina virtuale del nodo. Il valore predefinito e l'unica opzione al momento disponibile è amd64. |
OS_NAME |
✔ | ✔ | Facoltativa. Sistema operativo della macchina virtuale del nodo. Il valore predefinito è ubuntu per Ubuntu LTS. Può essere anche photon per Photon OS in vSphere o amazon per Amazon Linux in AWS. |
OS_VERSION |
✔ | ✔ | Facoltativa. Versione del sistema operativo OS_NAME precedente. Il valore predefinito è 20.04 per Ubuntu. Può essere 3 per Photon in vSphere e 2 per Amazon Linux in AWS. |
SIZE |
✔ | ✔ | Facoltativa. Dimensioni per le macchine virtuali del piano di controllo e del nodo worker. Sostituisce i parametri VSPHERE_CONTROL_PLANE_\* e VSPHERE_WORKER_\*. Per vSphere, impostare small, medium, large o extra-large come descritto in Dimensioni dei nodi predefinite. Per AWS, impostare un tipo di istanza, ad esempio t3.small. Per Azure, impostare un tipo di istanza, ad esempio Standard_D2s_v3. |
WORKER_MACHINE_COUNT |
✔ | ✔ | Facoltativa. Distribuire un cluster del carico di lavoro con un numero di nodi worker maggiore del numero predefinito dei piani dev e prod. |
WORKER_NODE_NAMESERVERS |
✔ | ✔ | Solo vSphere. In questo modo l'utente può specificare un elenco delimitato da virgole di server DNS da configurare nei nodi di lavoro, ad esempio WORKER_NODE_NAMESERVERS: 10.132.7.1, 10.142.7.1. Supportato su Ubuntu e Photon; non supportato in Windows. Per un caso d'uso di esempio, vedere l'IPAM del nodo di seguito. |
WORKER_NODE_SEARCH_DOMAINS |
✔ | ✔ | Solo cluster basati sulla classe. Configura i domini di ricerca .local per i nodi del cluster, ad esempio CONTROL_PLANE_NODE_SEARCH_DOMAINS: corp.local. Per configurare questa variabile in un cluster legacy basato sul piano in vSphere, utilizzare un overlay ytt come descritto in Risoluzione del dominio .local. |
WORKER_SIZE |
✔ | ✔ | Facoltativa. Dimensioni per le macchine virtuali del nodo worker. Sostituisce i parametri SIZE e VSPHERE_WORKER_*. Per i possibili valori, vedere SIZE. |
CUSTOM_TDNF_REPOSITORY_CERTIFICATE |
✔ | ✔ | (Anteprima tecnica) Facoltativa. Impostare se si utilizza un server di repository tdnf personalizzato con un certificato autofirmato, anziché il server del repository tdnf predefinito di Photon. Immettere il contenuto del certificato con codifica base64 del server del repository tdnf. Elimina tutti i repos in |
Standard di sicurezza del pod per il controller di ammissione sicurezza pod
Configurare gli standard di sicurezza del pod per un controller di ammissione sicurezza pod (PSA) a livello di cluster, il piano di controllo e i nodi di lavoro e il sistema operativo che le istanze dei nodi eseguono. Per ulteriori informazioni, vedere Controller di ammissione sicurezza pod.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
POD_SECURITY_STANDARD_AUDIT |
✖ | ✔ | Facoltativa. Il valore predefinito è restricted. Imposta il criterio di sicurezza per la modalità audit del controller PSA a livello di cluster. Valori possibili: restricted baseline e privileged. |
POD_SECURITY_STANDARD_DEACTIVATED |
✖ | ✔ | Facoltativa. Il valore predefinito è false. Impostare su true per disattivare PSA a livello di cluster. |
POD_SECURITY_STANDARD_ENFORCE |
✖ | ✔ | Facoltativa. Il valore predefinito è nessun valore. Imposta il criterio di sicurezza per la modalità enforce del controller PSA a livello di cluster. Valori possibili: restricted baseline e privileged. |
POD_SECURITY_STANDARD_WARN |
✖ | ✔ | Facoltativa. Il valore predefinito è restricted. Imposta il criterio di sicurezza per la modalità warn del controller PSA a livello di cluster. Valori possibili: restricted baseline e privileged. |
Ottimizzazione Kubernetes (solo cluster basati sulla classe)
I server dell'API Kubernetes, i Kubelet e altri componenti espongono vari flag di configurazione per l'ottimizzazione, ad esempio il flag --tls-cipher-suites per configurare i pacchetti di crittografia per la protezione della sicurezza, il flag --election-timeout il flag per aumentare etcd il timeout in un cluster di grandi dimensioni e così via.
ImportanteQueste variabili di configurazione di Kubernetes sono per gli utenti avanzati. VMware non garantisce la funzionalità dei cluster configurati con combinazioni arbitrarie di queste impostazioni.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
APISERVER_EXTRA_ARGS |
✔ | ✔ | Solo cluster basati sulla classe. Specificare i flag kube-apiserver nel formato "key1=value1;key2=value2". Ad esempio, impostare pacchetti di crittografia con APISERVER_EXTRA_ARGS: "tls-min-version=VersionTLS12;tls-cipher-suites=TLS_RSA_WITH_AES_256_GCM_SHA384" |
CONTROLPLANE_KUBELET_EXTRA_ARGS |
✔ | ✔ | Solo cluster basati sulla classe. Specificare i flag kubelet del piano di controllo nel formato "key1=value1;key2=value2". Ad esempio, limitare il numero di pod del piano di controllo con CONTROLPLANE_KUBELET_EXTRA_ARGS: "max-pods=50" |
ETCD_EXTRA_ARGS |
✔ | ✔ | Solo cluster basati sulla classe. Specificare i flag etcd nel formato "key1=value1;key2=value2". Ad esempio, se il cluster presenta più di 500 nodi o le prestazioni dello storage non sono sufficienti, è possibile aumentare heartbeat-interval e election-timeout con ETCD_EXTRA_ARGS: "heartbeat-interval=300;election-timeout=2000" |
KUBE_CONTROLLER_MANAGER_EXTRA_ARGS |
✔ | ✔ | Solo cluster basati sulla classe. Specificare i flag kube-controller-manager nel formato "key1=value1;key2=value2". Ad esempio, disattivare la profilatura delle prestazioni con KUBE_CONTROLLER_MANAGER_EXTRA_ARGS: "profiling=false" |
KUBE_SCHEDULER_EXTRA_ARGS |
✔ | ✔ | Solo cluster basati sulla classe. Specificare i flag kube-scheduler nel formato "key1=value1;key2=value2". Ad esempio, abilitare la modalità di accesso a un singolo pod con KUBE_SCHEDULER_EXTRA_ARGS: "feature-gates=ReadWriteOncePod=true" |
WORKER_KUBELET_EXTRA_ARGS |
✔ | ✔ | Solo cluster basati sulla classe. Specificare i flag kubelet del worker nel formato "key1=value1;key2=value2". Ad esempio, limitare il numero di pod worker con WORKER_KUBELET_EXTRA_ARGS: "max-pods=50" |
Scalabilità automatica del cluster
Se la variabile ENABLE_AUTOSCALER è impostata su true, è possibile configurare le variabili aggiuntive seguenti. Per informazioni sulla scalabilità automatica del cluster, vedere Scalabilità dei cluster del carico di lavoro.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
AUTOSCALER_MAX_NODES_TOTAL |
✖ | ✔ | Facoltativa. Il valore predefinito è 0. Numero massimo totale di nodi worker e di nodi del piano di controllo nel cluster. Imposta il valore per il parametro di scalabilità automatica del cluster max-nodes-total. La scalabilità automatica del cluster non tenta di scalare il cluster oltre questo limite. Se questa variabile è impostata su 0, la scalabilità automatica del cluster prende decisioni sulla scalabilità in base alle impostazioni minima e massima di SIZE configurate. |
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_ADD |
✖ | ✔ | Facoltativa. Il valore predefinito è 10m. Imposta il valore per il parametro di scalabilità automatica del cluster scale-down-delay-after-add. Quantità di tempo che la scalabilità automatica del cluster attende dopo un'operazione di scalabilità verticale prima di riprendere le analisi di scalabilità orizzontale. |
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_DELETE |
✖ | ✔ | Facoltativa. Il valore predefinito è 10s. Imposta il valore per il parametro di scalabilità automatica del cluster scale-down-delay-after-delete. Quantità di tempo che la scalabilità automatica del cluster attende dopo l'eliminazione di un nodo prima di riprendere le analisi di scalabilità orizzontale. |
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_FAILURE |
✖ | ✔ | Facoltativa. Il valore predefinito è 3m. Imposta il valore per il parametro di scalabilità automatica del cluster scale-down-delay-after-failure. Quantità di tempo che la scalabilità automatica del cluster attende dopo un errore di scalabilità orizzontale prima di riprendere le analisi di scalabilità orizzontale. |
AUTOSCALER_SCALE_DOWN_UNNEEDED_TIME |
✖ | ✔ | Facoltativa. Il valore predefinito è 10m. Imposta il valore per il parametro di scalabilità automatica del cluster scale-down-unneeded-time. Quantità di tempo che la scalabilità automatica del cluster deve attendere prima di scalare orizzontalmente un nodo idoneo. |
AUTOSCALER_MAX_NODE_PROVISION_TIME |
✖ | ✔ | Facoltativa. Il valore predefinito è 15m. Imposta il valore per il parametro di scalabilità automatica del cluster max-node-provision-time. Quantità di tempo massima per cui la scalabilità automatica del cluster attende il provisioning di un nodo. |
AUTOSCALER_MIN_SIZE_0 |
✖ | ✔ | Obbligatorioa. Tutti gli IaaS. Numero minimo di nodi worker. La scalabilità automatica del cluster non tenta di scalare orizzontalmente i nodi al di sotto di questo limite. Per i cluster di prod in AWS, AUTOSCALER_MIN_SIZE_0 imposta il numero minimo di nodi worker nella prima ZD. Se il numero non viene impostato, il valore predefinito è WORKER_MACHINE_COUNT per i cluster con un singolo nodo worker o WORKER_MACHINE_COUNT_0 per i cluster con più nodi worker. |
AUTOSCALER_MAX_SIZE_0 |
✖ | ✔ | Obbligatorioa. Tutti gli IaaS. Numero massimo di nodi worker. La scalabilità automatica del cluster non tenta di scalare verticalmente i nodi oltre questo limite. Per i cluster di prod in AWS, AUTOSCALER_MAX_SIZE_0 imposta il numero massimo di nodi worker nella prima ZD. Se il numero non viene impostato, il valore predefinito è WORKER_MACHINE_COUNT per i cluster con un singolo nodo worker o WORKER_MACHINE_COUNT_0 per i cluster con più nodi worker. |
AUTOSCALER_MIN_SIZE_1 |
✖ | ✔ | Obbligatoria. Utilizzarla solo per i cluster di prod in AWS. Numero minimo di nodi worker nella seconda ZD. La scalabilità automatica del cluster non tenta di scalare orizzontalmente i nodi al di sotto di questo limite. Se il valore non è specificato, per impostazione predefinita viene utilizzato il valore WORKER_MACHINE_COUNT_1. |
AUTOSCALER_MAX_SIZE_1 |
✖ | ✔ | Obbligatoria. Utilizzarla solo per i cluster di prod in AWS. Numero massimo di nodi worker nella seconda ZD. La scalabilità automatica del cluster non tenta di scalare verticalmente i nodi oltre questo limite. Se il valore non è specificato, per impostazione predefinita viene utilizzato il valore WORKER_MACHINE_COUNT_1. |
AUTOSCALER_MIN_SIZE_2 |
✖ | ✔ | Obbligatoria. Utilizzarla solo per i cluster di prod in AWS. Numero minimo di nodi worker nella terza ZD. La scalabilità automatica del cluster non tenta di scalare orizzontalmente i nodi al di sotto di questo limite. Se il valore non è specificato, per impostazione predefinita viene utilizzato il valore WORKER_MACHINE_COUNT_2. |
AUTOSCALER_MAX_SIZE_2 |
✖ | ✔ | Obbligatoria. Utilizzarla solo per i cluster di prod in AWS. Numero massimo di nodi worker nella terza ZD. La scalabilità automatica del cluster non tenta di scalare verticalmente i nodi oltre questo limite. Se il valore non è specificato, per impostazione predefinita viene utilizzato il valore WORKER_MACHINE_COUNT_2. |
Configurazione del proxy
Se nell'ambiente sono presenti limitazioni Internet o proxy, è possibile configurare facoltativamente Tanzu Kubernetes Grid per inviare il traffico HTTP e HTTPS in uscita da kubelet, containerd e il piano di controllo ai proxy.
Tanzu Kubernetes Grid consente di abilitare i proxy per uno degli elementi seguenti:
- Per il cluster di gestione e per uno o più cluster del carico di lavoro
- Solo per il cluster di gestione
- Per uno o più cluster del carico di lavoro
Per ulteriori informazioni, vedere Configurazione dei proxy in Creazione di un file di configurazione del cluster di gestione.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
TKG_HTTP_PROXY_ENABLED |
✔ | ✔ | Facoltativa. Consente di inviare il traffico HTTP(S) in uscita dal cluster di gestione a un proxy, ad esempio in un ambiente con limitazioni Internet, impostare questa variabile su |
TKG_HTTP_PROXY |
✔ | ✔ | Facoltativo. Impostarla se si desidera configurare un proxy. Per disattivare la configurazione del proxy per un singolo cluster, impostarla su
Ad esempio, |
TKG_HTTPS_PROXY |
✔ | ✔ | Facoltativa. Impostarla se si desidera configurare un proxy. Si applica solo quando TKG_HTTP_PROXY_ENABLED = true. URL del proxy HTTPS. È possibile impostare questa variabile sullo stesso valore di TKG_HTTP_PROXY o specificare un valore diverso. L'URL deve iniziare con http://. Se si imposta TKG_HTTPS_PROXY, è necessario impostare anche TKG_HTTP_PROXY. |
TKG_NO_PROXY |
✔ | ✔ | Facoltativa. Si applica solo quando Uno o più CIDR di rete o nomi host che devono ignorare il proxy HTTP(S), separati da virgole ed elencati senza spazi o caratteri jolly ( Ad esempio, Internamente, Tanzu Kubernetes Grid aggiunge Se si imposta TKG_NO_PROXY consente alle macchine virtuali del cluster di comunicare direttamente con l'infrastruttura che esegue la stessa rete, dietro lo stesso proxy. Ciò può includere, a titolo esemplificativo, l'infrastruttura, il server OIDC o LDAP, Harbor, VMware NSX e NSX Advanced Load Balancer (vSphere). Impostare TKG_NO_PROXY per includere tutti gli endpoint a cui i cluster devono accedere ma che non sono raggiungibili dai proxy. |
TKG_PROXY_CA_CERT |
✔ | ✔ | Facoltativa. Impostarla se il server proxy utilizza un certificato autofirmato. Specificare il certificato CA in formato con codifica base64, ad esempio TKG_PROXY_CA_CERT: "LS0t[...]tLS0tLQ=="". |
TKG_NODE_SYSTEM_WIDE_PROXY |
✔ | ✔ | (Anteprima tecnica) Facoltativa. Imposta le seguenti impostazioni in export HTTP_PROXY=$TKG_HTTP_PROXY Quando gli utenti accedono tramite SSH al nodo TKG ed eseguono comandi, per impostazione predefinita i comandi utilizzano le variabili definite. I processi systemd non sono interessati. |
Configurazione della CNI di Antrea
Variabili facoltative aggiuntive da impostare se CNI è impostata su antrea. Per ulteriori informazioni, vedere Configurazione della CNI di Antrea in Creazione di un file di configurazione del cluster di gestione.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
ANTREA_DISABLE_UDP_TUNNEL_OFFLOAD |
✔ | ✔ | Facoltativa. Il valore predefinito è false. Impostarla su true per disattivare l'offload del checksum UDP di Antrea. Impostando questa variabile su true si evitano i problemi noti relativi ai driver della rete underlay e della rete NIC fisica. |
ANTREA_EGRESS |
✔ | ✔ | Facoltativa. Il valore predefinito è true. Abilitare questa variabile per definire l'IP SNAT utilizzato per il traffico pod in uscita dal cluster. Per ulteriori informazioni, vedere Egress nella documentazione di Antrea. |
ANTREA_EGRESS_EXCEPT_CIDRS |
✔ | ✔ | Facoltativa. Gli intervalli CIDR che escono non eseguiranno SNAT per il traffico del pod in uscita. Includere le virgolette (""). Ad esempio, "10.0.0.0/6". |
ANTREA_ENABLE_USAGE_REPORTING |
✔ | ✔ | Facoltativa. Il valore predefinito è false. Attiva o disattiva la creazione di report sull'utilizzo (telemetria). |
ANTREA_FLOWEXPORTER |
✔ | ✔ | Facoltativa. Il valore predefinito è false. Impostarla su true per la visibilità del flusso di rete. L'esportatore del flusso esegue periodicamente il polling dei flussi conntrack ed esporta i flussi come record di flusso IPFIX. Per ulteriori informazioni, vedere Network Flow Visibility in Antrea nella documentazione di Antrea. |
ANTREA_FLOWEXPORTER_ACTIVE_TIMEOUT |
✔ | ✔ | Facoltativa. Il valore predefinito è Nota: le unità di tempo valide sono |
ANTREA_FLOWEXPORTER_COLLECTOR_ADDRESS |
✔ | ✔ | Facoltativa. Questa variabile specifica l'indirizzo dell'agente di raccolta IPFIX. Includere le virgolette (""). Il valore predefinito è "flow-aggregator.flow-aggregator.svc:4739:tls". Per ulteriori informazioni, vedere Network Flow Visibility in Antrea nella documentazione di Antrea. |
ANTREA_FLOWEXPORTER_IDLE_TIMEOUT |
✔ | ✔ | Facoltativa. Il valore predefinito è Nota: le unità di tempo valide sono |
ANTREA_FLOWEXPORTER_POLL_INTERVAL |
✔ | ✔ | Facoltativa. Il valore predefinito è Nota: le unità di tempo valide sono |
ANTREA_IPAM |
✔ | ✔ | Facoltativa. Il valore predefinito è false. Impostarla su true per allocare gli indirizzi IP da IPPool. Il set di intervalli di IP desiderato, facoltativamente con VLAN, viene definito con CRD IPPool. Per ulteriori informazioni, vedere Antrea IPAM Capabilities nella documentazione di Antrea. |
ANTREA_KUBE_APISERVER_OVERRIDE |
✔ | ✔ | Facoltativa. Consente di specificare l'indirizzo del server dell'API di Kubernetes. Per ulteriori informazioni, vedere Removing kube-proxy nella documentazione di Antrea. |
ANTREA_MULTICAST |
✔ | ✔ | Facoltativa. Il valore predefinito è false. Impostarla su true per il traffico multicast nella rete del cluster (tra pod) e tra la rete esterna e la rete del cluster. |
ANTREA_MULTICAST_INTERFACES |
✔ | ✔ | Facoltativa. Nomi delle interfacce nei nodi utilizzati per inoltrare il traffico multicast. Includere le virgolette (""). Ad esempio, "eth0". |
ANTREA_NETWORKPOLICY_STATS |
✔ | ✔ | Facoltativa. Il valore predefinito è true. Abilitare questa variabile per raccogliere le statistiche di NetworkPolicy. I dati statistici includono il numero totale di sessioni, i pacchetti e i byte consentiti o negati da un elemento NetworkPolicy. |
ANTREA_NO_SNAT |
✔ | ✔ | Facoltativa. Il valore predefinito è false. Impostarla su true per disattivare SNAT (Source Network Address Translation). |
ANTREA_NODEPORTLOCAL |
✔ | ✔ | Facoltativa. Il valore predefinito è true. Impostarla su false per disattivare la modalità NodePortLocal. Per ulteriori informazioni, vedere NodePortLocal (NPL) nella documentazione di Antrea. |
ANTREA_NODEPORTLOCAL_ENABLED |
✔ | ✔ | Facoltativa. Impostarla su true per abilitare la modalità NodePortLocal, come descritto in NodePortLocal (NPL) nella documentazione di Antrea. |
ANTREA_NODEPORTLOCAL_PORTRANGE |
✔ | ✔ | Facoltativa. Il valore predefinito è 61000-62000. Per ulteriori informazioni, vedere NodePortLocal (NPL) nella documentazione di Antrea. |
ANTREA_POLICY |
✔ | ✔ | Facoltativa. Il valore predefinito è true. Attiva o disattiva l'API del criterio nativo di Antrea, rappresentata da CRD del criterio specifici di Antrea. Inoltre, l'implementazione dei criteri di rete di Kubernetes rimane attiva quando questa variabile è abilitata. Per informazioni sull'utilizzo dei criteri di rete, vedere Antrea Network Policy CRDs nella documentazione di Antrea. |
ANTREA_PROXY |
✔ | ✔ | Facoltativa. Il valore predefinito è false. Attiva o disattiva AntreaProxy per sostituire kube-proxy per il traffico del servizio da pod a ClusterIP, per migliorare le prestazioni e ridurre la latenza. Si tenga presente che kube-proxy viene comunque utilizzato per altri tipi di traffico di servizio. Per ulteriori informazioni sull'utilizzo dei proxy, vedere AntreaProxy nella documentazione di Antrea. |
ANTREA_PROXY_ALL |
✔ | ✔ | Facoltativa. Il valore predefinito è false. Attiva o disattiva AntreaProxy per gestire tutto il traffico del servizio, incluso il traffico NodePort, LoadBalancer e ClusterIP. Per sostituire kube-proxy con AntreaProxy, è necessario abilitare ANTREA_PROXY_ALL. Per ulteriori informazioni sull'utilizzo dei proxy, vedere AntreaProxy nella documentazione di Antrea. |
ANTREA_PROXY_LOAD_BALANCER_IPS |
✔ | ✔ | Facoltativa. Il valore predefinito è true. Impostarla su false per indirizzare il traffico del bilanciamento del carico verso il LoadBalancer esterno. |
ANTREA_PROXY_NODEPORT_ADDRS |
✔ | ✔ | Facoltativa. Indirizzo IPv4 o IPv6 per NodePort. Includere le virgolette (""). |
ANTREA_PROXY_SKIP_SERVICES |
✔ | ✔ | Facoltativa. Array di valori stringa che possono essere utilizzati per indicare un elenco di servizi che AntreaProxy deve ignorare. Il carico del traffico verso questi servizi non verrà bilanciato. Includere le virgolette (""). Ad esempio, un ClusterIP valido come 10.11.1.2 o un nome di servizio con uno spazio dei nomi come kube-system/kube-dns, sono valori validi. Per ulteriori informazioni, vedere Special use cases nella documentazione di Antrea. |
ANTREA_SERVICE_EXTERNALIP |
✔ | ✔ | Facoltativa. Il valore predefinito è false. Impostarla su true per consentire a un controller di allocare IP esterni da una risorsa "ExternalIPPool" per i servizi di tipo "LoadBalancer". Per ulteriori informazioni su come implementare i servizi di tipo "LoadBalancer", vedere Servizio di tipo LoadBalancer nella documentazione di Antrea. |
ANTREA_TRACEFLOW |
✔ | ✔ | Facoltativa. Il valore predefinito è true. Per informazioni sull'utilizzo di Traceflow, vedere Traceflow User Guide nella documentazione di Antrea. |
ANTREA_TRAFFIC_ENCAP_MODE |
✔ | ✔ | Facoltativa. Il valore predefinito è Nota: le modalità La modalità |
ANTREA_TRANSPORT_INTERFACE |
✔ | ✔ | Facoltativa. Nome dell'interfaccia nel nodo utilizzato per il tunneling o il routing del traffico. Includere le virgolette (""). Ad esempio, "eth0". |
ANTREA_TRANSPORT_INTERFACE_CIDRS |
✔ | ✔ | Facoltativa. CIDR di rete dell'interfaccia nel nodo utilizzato per il tunneling o il routing del traffico. Includere le virgolette (""). Ad esempio, "10.0.0.2/24". |
Controlli di integrità delle macchine
Se si desidera configurare i controlli di integrità delle macchine per i cluster di gestione e del carico di lavoro, impostare le variabili seguenti. Per ulteriori informazioni, vedere Configurazione dei controlli di integrità delle macchine in Creazione di un file di configurazione del cluster di gestione. Per informazioni su come eseguire le operazioni di controllo dell'integrità delle macchine dopo la distribuzione del cluster, vedere Configurazione dei controlli di integrità delle macchine per i cluster del carico di lavoro.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
ENABLE_MHC |
✔ | basato sulla classe: ✖ basato sul piano: ✔ |
Facoltativa. Impostarla su true o false per attivare o disattivare il controller MachineHealthCheck nei nodi del piano di controllo e nei nodi worker del cluster di gestione o del cluster del carico di lavoro di destinazione. Oppure lasciarla vuota e impostare ENABLE_MHC_CONTROL_PLANE e ENABLE_MHC_WORKER_NODE separatamente per i nodi del piano di controllo e i nodi worker. Il valore predefinito è vuoto.Il controller fornisce la funzionalità di monitoraggio e riparazione automatica dell'integrità della macchina. Per i cluster del carico di lavoro creati da vSphere with Tanzu, impostarla su false. |
ENABLE_MHC_CONTROL_PLANE |
✔ | Facoltativa. Il valore predefinito è true. Per ulteriori informazioni, vedere la tabella seguente. |
|
ENABLE_MHC_WORKER_NODE |
✔ | Facoltativa. Il valore predefinito è true. Per ulteriori informazioni, vedere la tabella seguente. |
|
MHC_MAX_UNHEALTHY_CONTROL_PLANE |
✔ | ✖ | Facoltativo; solo cluster basati sulla classe. Il valore predefinito è 100%. Se il numero di macchine non integre supera il valore impostato, il controller MachineHealthCheck non esegue la correzione. |
MHC_MAX_UNHEALTHY_WORKER_NODE |
✔ | ✖ | Facoltativo; solo cluster basati sulla classe. Il valore predefinito è 100%. Se il numero di macchine non integre supera il valore impostato, il controller MachineHealthCheck non esegue la correzione. |
MHC_FALSE_STATUS_TIMEOUT |
✔ | basato sulla classe: ✖ basato sul piano: ✔ |
Facoltativa. Il valore predefinito è 12m. Tempo per cui il controller MachineHealthCheck consente alla condizione Ready di un nodo di rimanere False prima di considerare la macchina non integra e ricrearla. |
MHC_UNKNOWN_STATUS_TIMEOUT |
✔ | Facoltativa. Il valore predefinito è 5m. Tempo per cui il controller MachineHealthCheck consente alla condizione Ready di un nodo di rimanere Unknown prima di considerare la macchina non integra e ricrearla. |
|
NODE_STARTUP_TIMEOUT |
✔ | Facoltativa. Il valore predefinito è 20m. Per quanto tempo il controller MachineHealthCheck attende che un nodo venga unito a un cluster prima di considerare la macchina non integra e ricrearla. |
|
Utilizzare la tabella seguente per stabilire come configurare le variabili ENABLE_MHC, ENABLE_MHC_CONTROL_PLANE e ENABLE_MHC_WORKER_NODE.
Valore di ENABLE_MHC |
Valore di ENABLE_MHC_CONTROL_PLANE |
Valore di ENABLE_MHC_WORKER_NODE |
Correzione del piano di controllo abilitata? | Correzione del nodo worker abilitata? |
|---|---|---|---|---|
true / Emptytrue / Emptytrue / Vuoto |
true / false / Vuoto |
true / false / Vuoto |
Sì | Sì |
false |
true / Vuoto |
true / Vuoto |
Sì | Sì |
false |
true / Vuoto |
false |
Sì | No |
false |
false |
true / Vuoto |
No | Sì |
Configurazione del registro di immagini privato
Se si distribuiscono cluster di gestione di Tanzu Kubernetes Grid e cluster di Kubernetes in ambienti non connessi a Internet, è necessario configurare un repository di immagini privato nel firewall e popolarlo con le immagini di Tanzu Kubernetes Grid. Per informazioni sulla configurazione di un repository di immagini privato, vedere Preparazione di un ambiente con limitazioni Internet.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
ADDITIONAL_IMAGE_REGISTRY_1, ADDITIONAL_IMAGE_REGISTRY_2, ADDITIONAL_IMAGE_REGISTRY_3 |
✔ | ✔ | Solo cluster del carico di lavoro basati sulla classe e cluster di gestione autonomi. Indirizzi IP o nomi di dominio completi di un massimo di tre registri privati attendibili, oltre al registro di immagini primario impostato da TKG_CUSTOM_IMAGE_REPOSITORY, a cui i nodi del cluster del carico di lavoro possono accedere. Vedere Registri attendibili per un cluster basato sulla classe. |
ADDITIONAL_IMAGE_REGISTRY_1_CA_CERTIFICATE, ADDITIONAL_IMAGE_REGISTRY_2_CA_CERTIFICATE, ADDITIONAL_IMAGE_REGISTRY_3_CA_CERTIFICATE |
✔ | ✔ | Solo cluster del carico di lavoro basati sulla classe e cluster di gestione autonomi. Certificati CA in formato codificato in base64 dei registri di immagini privati configurati con la variabile ADDITIONAL_IMAGE_REGISTRY-* indicata in precedenza. Ad esempio, ADDITIONAL_IMAGE_REGISTRY_1_CA_CERTIFICATE: "LS0t[...]tLS0tLQ==". |
ADDITIONAL_IMAGE_REGISTRY_1_SKIP_TLS_VERIFY, ADDITIONAL_IMAGE_REGISTRY_2_SKIP_TLS_VERIFY, ADDITIONAL_IMAGE_REGISTRY_3_SKIP_TLS_VERIFY |
✔ | ✔ | Solo cluster del carico di lavoro basati sulla classe e cluster di gestione autonomi. Impostarla su true per tutti i registri di immagini privati configurati con la variabile ADDITIONAL_IMAGE_REGISTRY-* indicata in precedenza che utilizzano un certificato autofirmato ma non ADDITIONAL_IMAGE_REGISTRY_*_CA_CERTIFICATE. Poiché il webhook di connettività di Tanzu inserisce il certificato CA di Harbor nei nodi del cluster, la variabile ADDITIONAL_IMAGE_REGISTRY_*_SKIP_TLS_VERIFY deve essere sempre impostata su false quando si utilizza Harbor. |
TKG_CUSTOM_IMAGE_REPOSITORY |
✔ | ✔ | Obbligatoria se si distribuisce Tanzu Kubernetes Grid in un ambiente con limitazioni Internet. Specificare l'indirizzo IP o il nome di dominio completo del registro privato che contiene immagini del sistema TKG da cui viene eseguito il bootstrap dei cluster, denominato registro di immagini primario di seguito. Ad esempio, custom-image-repository.io/yourproject. |
TKG_CUSTOM_IMAGE_REPOSITORY_SKIP_TLS_VERIFY |
✔ | ✔ | Facoltativa. Impostarla su true se il registro di immagini primario privato utilizza un certificato autofirmato e non si usa TKG_CUSTOM_IMAGE_REPOSITORY_CA_CERTIFICATE. Poiché il webhook di connettività di Tanzu inserisce il certificato CA di Harbor nei nodi del cluster, la variabile TKG_CUSTOM_IMAGE_REPOSITORY_SKIP_TLS_VERIFY deve essere sempre impostata su false quando si utilizza Harbor. |
TKG_CUSTOM_IMAGE_REPOSITORY_CA_CERTIFICATE |
✔ | ✔ | Facoltativa. Impostarla se il registro di immagini primario privato utilizza un certificato autofirmato. Specificare il certificato CA in formato con codifica base64, ad esempio TKG_CUSTOM_IMAGE_REPOSITORY_CA_CERTIFICATE: "LS0t[...]tLS0tLQ==". |
vSphere
La tabella seguente include le opzioni minime che devono essere specificate nel file di configurazione del cluster quando si distribuiscono cluster del carico di lavoro in vSphere. La maggior parte di queste opzioni è uguale per il cluster del carico di lavoro e per il cluster di gestione utilizzato per distribuirlo.
Per ulteriori informazioni sui file di configurazione per vSphere, vedere Configurazione del cluster di gestione per vSphere e Distribuzione dei cluster del carico di lavoro in vSphere.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
DEPLOY_TKG_ON_VSPHERE7 |
✔ | ✔ | Facoltativa. Se si esegue la distribuzione in vSphere 7 o 8, impostarla su true per ignorare la richiesta relativa alla distribuzione in vSphere 7 o 8 oppure impostarla su false. Vedere Cluster di gestione in vSphere with Tanzu. |
ENABLE_TKGS_ON_VSPHERE7 |
✔ | ✔ | Facoltativa. Se si esegue la distribuzione in vSphere 7 o 8, impostarla su true per essere reindirizzati alla pagina dell'interfaccia utente di abilitazione di vSphere with Tanzu oppure impostarla su false. Vedere Cluster di gestione in vSphere with Tanzu. |
NTP_SERVERS |
✔ | ✔ | Solo cluster basati sulla classe. Configura il server NTP del cluster se si distribuiscono cluster in un ambiente vSphere in cui non è disponibile l'opzione DHCP 42, ad esempio NTP_SERVERS: time.google.com. Per configurare questa variabile in un cluster legacy basato sul piano, utilizzare un overlay ytt come descritto in Configurazione di NTP senza l'opzione DHCP 42 (vSphere). |
TKG_IP_FAMILY |
✔ | ✔ | Facoltativa. Per distribuire un cluster in vSphere 7 o 8 con IPv6 puro, impostare questa variabile su ipv6. Per la rete dual stack (sperimentale), vedere Cluster dual stack . |
VIP_NETWORK_INTERFACE |
✔ | ✔ | Facoltativa. Impostarla su eth0, eth1 e così via. Nome dell'interfaccia di rete, ad esempio un'interfaccia Ethernet. Il valore predefinito è eth0. |
VSPHERE_AZ_CONTROL_PLANE_MATCHING_LABELS |
✔ | ✔ | Per i cluster distribuiti in più ZD, imposta le etichette del selettore chiave/valore per specificare le ZD in cui possono essere distribuiti i nodi del piano di controllo del cluster. Ciò consente di configurare i nodi, ad esempio in modo che vengano eseguiti in tutte le ZD in una regione e un ambiente specificati senza elencare singolarmente le ZD, ad esempio: "region=us-west-1,environment=staging". Vedere Esecuzione dei cluster in più zone di disponibilità |
VSPHERE_AZ_0, VSPHERE_AZ_1, VSPHERE_AZ_2 |
✔ | ✔ | Facoltativa. Zone di distribuzione in cui vengono distribuite le macchine in un cluster. Vedere Esecuzione dei cluster in più zone di disponibilità |
VSPHERE_CONTROL_PLANE_DISK_GIB |
✔ | ✔ | Facoltativa. Dimensioni in gigabyte del disco per le macchine virtuali del nodo del piano di controllo. Includere le virgolette (""). Ad esempio, "30". |
VSPHERE_CONTROL_PLANE_ENDPOINT |
✔ | ✔ | Obbligatoria per Kube-Vip. Indirizzo IP virtuale statico o nome di dominio completo (FQDN) mappato a un indirizzo statico per le richieste dell'API al cluster. Questa impostazione è obbligatoria se si utilizza Kube-Vip per l'endpoint del server API come configurato impostando AVI_CONTROL_PLANE_HA_PROVIDER su false. Se si utilizza NSX Advanced Load Balancer, AVI_CONTROL_PLANE_HA_PROVIDER: true, è possibile:
|
VSPHERE_CONTROL_PLANE_ENDPOINT_PORT |
✔ | ✔ | Facoltativa. Impostarla se si desidera sostituire la porta del server dell'API Kubernetes per le distribuzioni in vSphere con NSX Advanced Load Balancer. La porta predefinita è 6443. Per sostituire la porta del server dell'API Kubernetes per le distribuzioni in vSphere senza NSX Advanced Load Balancer, impostare CLUSTER_API_SERVER_PORT. |
VSPHERE_CONTROL_PLANE_MEM_MIB |
✔ | ✔ | Facoltativa. Quantità di memoria in megabyte per le macchine virtuali dei nodi del piano di controllo. Includere le virgolette (""). Ad esempio, "2048". |
VSPHERE_CONTROL_PLANE_NUM_CPUS |
✔ | ✔ | Facoltativa. Numero di CPU per le macchine virtuali dei nodi del piano di controllo. Includere le virgolette (""). Deve essere almeno 2. Ad esempio, "2". |
VSPHERE_DATACENTER |
✔ | ✔ | Obbligatoria. Nome del data center in cui distribuire il cluster, come viene visualizzato nell'inventario di vSphere. Ad esempio, /MY-DATACENTER. |
VSPHERE_DATASTORE |
✔ | ✔ | Obbligatoria. Nome del datastore di vSphere per il cluster da utilizzare, come viene visualizzato nell'inventario di vSphere. Ad esempio, /MY-DATACENTER/datastore/MyDatastore. |
VSPHERE_FOLDER |
✔ | ✔ | Obbligatoria. Nome di una cartella di macchine virtuali esistente in cui posizionare le macchine virtuali di Tanzu Kubernetes Grid, come visualizzato nell'inventario di vSphere. Ad esempio, se è stata creata una cartella denominata TKG, il percorso è /MY-DATACENTER/vm/TKG. |
VSPHERE_INSECURE |
✔ | ✔ | Facoltativa. Impostarla su true per ignorare la verifica dell'identificazione personale. Se è false, impostare VSPHERE_TLS_THUMBPRINT. |
VSPHERE_MTU |
✔ | ✔ | Facoltativa. Impostare le dimensioni dell'unità massima di trasmissione (MTU) per i nodi di gestione e del cluster del carico di lavoro in un commutatore vSphere Standard. Se non impostato, il valore predefinito è 1500. Il valore massimo è 9000. Vedere Configurazione dell'MTU del nodo del cluster. |
VSPHERE_NETWORK |
✔ | ✔ | Obbligatoria. Nome di una rete di vSphere esistente da utilizzare come rete del servizio Kubernetes, come visualizzato nell'inventario di vSphere. Ad esempio, VM Network. |
VSPHERE_PASSWORD |
✔ | ✔ | Obbligatoria. Password dell'account utente di vSphere. Questo valore viene codificato in base64 quando si esegue tanzu cluster create. |
VSPHERE_REGION |
✔ | ✔ | Facoltativa. Tag per la regione in vCenter, utilizzato per:
|
VSPHERE_RESOURCE_POOL |
✔ | ✔ | Obbligatoria. Nome di un pool di risorse esistente in cui posizionare questa istanza di Tanzu Kubernetes Grid, come viene visualizzato nell'inventario di vSphere. Per utilizzare il pool di risorse root per un cluster, immettere il percorso completo, ad esempio per un cluster denominato cluster0 nel data center MY-DATACENTER, il percorso completo è /MY-DATACENTER/host/cluster0/Resources. |
VSPHERE_SERVER |
✔ | ✔ | Obbligatoria. Indirizzo IP o nome di dominio completo dell'istanza di vCenter Server in cui si desidera distribuire il cluster del carico di lavoro. |
VSPHERE_SSH_AUTHORIZED_KEY |
✔ | ✔ | Obbligatoria. Incollare i contenuti della chiave pubblica SSH creata in Distribuzione di un cluster di gestione in vSphere. Ad esempio, "ssh-rsa NzaC1yc2EA [...] hnng2OYYSl+8ZyNz3fmRGX8uPYqw== [email protected]". |
VSPHERE_STORAGE_POLICY_ID |
✔ | ✔ | Facoltativa. Nome di un criterio di storage della macchina virtuale per il cluster di gestione, come viene visualizzato in Criteri e profili > Criteri di storage macchina virtuale. Se è impostato VSPHERE_DATASTORE, il criterio di storage deve includerlo. In caso contrario, il processo di creazione del cluster sceglie un datastore compatibile con il criterio. |
VSPHERE_TEMPLATE |
✖ | ✔ | Facoltativa. Specificare il percorso di un file OVA se si utilizzano più immagini OVA personalizzate per la stessa versione di Kubernetes, nel formato /MY-DC/vm/MY-FOLDER-PATH/MY-IMAGE. Per ulteriori informazioni, vedere Distribuzione di un cluster con un'immagine OVA personalizzata. |
VSPHERE_TLS_THUMBPRINT |
✔ | ✔ | Obbligatoria se VSPHERE_INSECURE è false. Identificazione personale del certificato di vCenter Server. Per informazioni su come ottenere l'identificazione personale del certificato di vCenter Server, vedere Recupero delle identificazioni personali del certificato di vSphere. Questo valore può essere ignorato se l'utente desidera utilizzare una connessione non sicura impostando VSPHERE_INSECURE su true. |
VSPHERE_USERNAME |
✔ | ✔ | Obbligatoria. Account utente di vSphere, incluso il nome del dominio, con i privilegi necessari per le operazioni di Tanzu Kubernetes Grid. Ad esempio, [email protected]. |
VSPHERE_WORKER_DISK_GIB |
✔ | ✔ | Facoltativa. Dimensioni in gigabyte del disco per le macchine virtuali del nodo worker. Includere le virgolette (""). Ad esempio, "50". |
VSPHERE_WORKER_MEM_MIB |
✔ | ✔ | Facoltativa. Quantità di memoria in megabyte per le macchine virtuali del nodo worker. Includere le virgolette (""). Ad esempio, "4096". |
VSPHERE_WORKER_NUM_CPUS |
✔ | ✔ | Facoltativa. Numero di CPU per le macchine virtuali del nodo worker. Includere le virgolette (""). Deve essere almeno 2. Ad esempio, "2". |
VSPHERE_ZONE |
✔ | ✔ | Facoltativa. Tag per la zona in vCenter, utilizzato per:
|
Bilanciamento del carico di Kube-VIP (anteprima tecnica)
Per informazioni su come configurare Kube-VIP come servizio di bilanciamento del carico L4, vedere Bilanciamento del carico Kube-VIP.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
KUBEVIP_LOADBALANCER_ENABLE |
✖ | ✔ | Facoltativa. Il valore predefinito è false. Impostarla su true o false. Abilita Kube-VIP come bilanciamento del carico per i carichi di lavoro. Se true, è necessario impostare una delle variabili seguenti. |
KUBEVIP_LOADBALANCER_IP_RANGES |
✖ | ✔ | Elenco di intervalli IP non sovrapposti da allocare per l'IP del servizio di tipo LoadBalancer. Ad esempio: 10.0.0.1-10.0.0.23,10.0.2.1-10.0.2.24. |
KUBEVIP_LOADBALANCER_CIDRS |
✖ | ✔ | Elenco di CIDR non sovrapposti da allocare per l'IP del servizio di tipo LoadBalancer. Ad esempio: 10.0.0.0/24,10.0.2/24. Sostituisce l'impostazione per KUBEVIP_LOADBALANCER_IP_RANGES. |
NSX Advanced Load Balancer
Per informazioni su come distribuire NSX Advanced Load Balancer, vedere Installazione di NSX Advanced Load Balancer.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
AVI_ENABLE |
✔ | ✖ | Facoltativa. Il valore predefinito è false. Impostarla su true o false. Abilita NSX Advanced Load Balancer come bilanciamento del carico per i carichi di lavoro. Se è true, è necessario impostare le variabili obbligatorie elencate in NSX Advanced Load Balancer di seguito. |
AVI_ADMIN_CREDENTIAL_NAME |
✔ | ✖ | Facoltativa. Il valore predefinito è avi-controller-credentials. Nome del segreto Kubernetes che contiene il nome utente e la password dell'amministratore del controller di NSX Advanced Load Balancer. |
AVI_AKO_IMAGE_PULL_POLICY |
✔ | ✖ | Facoltativa. Il valore predefinito è IfNotPresent. |
AVI_CA_DATA_B64 |
✔ | ✖ | Obbligatoria. Contenuti dell'autorità di certificazione del controller utilizzata per firmare il certificato del controller. Deve essere codificata in base64. Recuperare i contenuti del certificato personalizzato non codificato come descritto in Configurazione del controller Avi: certificato personalizzato. |
AVI_CA_NAME |
✔ | ✖ | Facoltativa; il valore predefinito èavi-controller-ca. Nome del segreto Kubernetes che contiene l'autorità di certificazione del controller di NSX Advanced Load Balancer. |
AVI_CLOUD_NAME |
✔ | ✖ | Obbligatoria. Cloud creato nella distribuzione di NSX Advanced Load Balancer. Ad esempio, Default-Cloud. |
AVI_CONTROLLER |
✔ | ✖ | Obbligatoria. Indirizzo IP o nome host del controller di NSX Advanced Load Balancer. |
AVI_CONTROL_PLANE_HA_PROVIDER |
✔ | ✔ | Obbligatoria. Impostarla su true per abilitare NSX Advanced Load Balancer come endpoint del server dell'API del piano di controllo o su false per utilizzare Kube-Vip come endpoint del piano di controllo. |
AVI_CONTROL_PLANE_NETWORK |
✔ | ✖ | Facoltativa. Definisce la rete VIP del piano di controllo del cluster del carico di lavoro. Utilizzarla quando si desidera configurare una rete VIP separata per i cluster del carico di lavoro. Questo campo è facoltativo. Se viene lasciato vuoto, viene utilizzata la stessa rete di AVI_DATA_NETWORK. |
AVI_CONTROL_PLANE_NETWORK_CIDR |
✔ | ✖ | Facoltativa; per impostazione predefinita, è la stessa rete di AVI_DATA_NETWORK_CIDR. CIDR della subnet da utilizzare per il piano di controllo del cluster del carico di lavoro. Utilizzarla quando si desidera configurare una rete VIP separata per i cluster del carico di lavoro. È possibile visualizzare il CIDR della subnet per una determinata rete nella vista Infrastruttura - Reti dell'interfaccia di NSX Advanced Load Balancer. |
AVI_DATA_NETWORK |
✔ | ✖ | Obbligatoria. Nome della rete in cui la subnet IP o il pool di IP mobili vengono assegnati a un bilanciamento del carico per il traffico verso applicazioni ospitate nei cluster del carico di lavoro. Questa rete deve essere presente nella stessa istanza di vCenter Server della rete di Kubernetes utilizzata da Tanzu Kubernetes Grid, specificata nella variabile SERVICE_CIDR. In questo modo, NSX Advanced Load Balancer può individuare la rete di Kubernetes in vCenter Server, nonché distribuire e configurare i motori di servizio. |
AVI_DATA_NETWORK_CIDR |
✔ | ✖ | Obbligatoria. CIDR della subnet da utilizzare per il VIP del bilanciamento del carico. Proviene da una delle subnet configurate della rete VIP. È possibile visualizzare il CIDR della subnet per una determinata rete nella vista Infrastruttura - Reti dell'interfaccia di NSX Advanced Load Balancer. |
AVI_DISABLE_INGRESS_CLASS |
✔ | ✖ | Facoltativa. Il valore predefinito è false. Consente di disattivare la classe di ingresso.Nota: Questa variabile non funziona in TKG v2.3. Per risolvere il problema, vedere Problemi noti Alcune variabili di configurazione NSX ALB non funzionano nelle note di rilascio. |
AVI_DISABLE_STATIC_ROUTE_SYNC |
✔ | ✖ | Facoltativa. Il valore predefinito è false. Impostarla su true se le reti del pod sono raggiungibili dal motore del servizio NSX ALB.Nota: Questa variabile non funziona in TKG v2.3. Per risolvere il problema, vedere Problemi noti Alcune variabili di configurazione NSX ALB non funzionano nelle note di rilascio. |
AVI_INGRESS_DEFAULT_INGRESS_CONTROLLER |
✔ | ✖ | Facoltativa. Il valore predefinito è false. Utilizzare AKO come controller di ingresso predefinito.Nota: Questa variabile non funziona in TKG v2.3. Per risolvere il problema, vedere Problemi noti Alcune variabili di configurazione NSX ALB non funzionano nelle note di rilascio. |
AVI_INGRESS_NODE_NETWORK_LIST |
✔ | ✖ | Specifica il nome della rete del gruppo di porte di cui fanno parte i nodi e il CIDR associato che la CNI alloca a ciascun nodo per tale nodo da assegnare ai relativi pod. È consigliabile aggiornare questo valore nel file AKODeploymentConfig (vedere Ingresso L7 in modalità ClusterIP), ma se si utilizza il file di configurazione del cluster, il formato è simile a: '[{"networkName": "vsphere-portgroup","cidrs": ["100.64.42.0/24"]}]' |
AVI_INGRESS_SERVICE_TYPE |
✔ | ✖ | Facoltativa. Specifica se AKO funziona in modalità ClusterIP, NodePort o NodePortLocal. Il valore predefinito è NodePort. |
AVI_INGRESS_SHARD_VS_SIZE |
✔ | ✖ | Facoltativa. AKO utilizza una logica di partizionamento per gli oggetti in ingresso di livello 7. Un VS partizionato implica l'hosting di più ingressi non sicuri o sicuri ospitati da un VIP o IP virtuale. Impostarla su LARGE, MEDIUM o SMALL. Il valore predefinito è SMALL. Utilizzare questa variabile per controllare i numeri di VS di livello 7. Si applica a entrambi i tipi di VS sicuri e non sicuri, ma non al passthrough. |
AVI_LABELS |
✔ | ✔ | Facoltativa. Quando è impostata, NSX Advanced Load Balancer è abilitato solo nei cluster del carico di lavoro che hanno questa etichetta. Includere le virgolette (""). Ad esempio, AVI_LABELS: "{foo: 'bar'}". |
AVI_MANAGEMENT_CLUSTER_CONTROL_PLANE_VIP_NETWORK_CIDR |
✔ | ✖ | Facoltativa. CIDR della subnet da utilizzare per il piano di controllo del cluster di gestione. Utilizzarlo quando si desidera configurare una rete VIP separata per il piano di controllo del cluster di gestione. È possibile visualizzare il CIDR della subnet per una determinata rete nella vista Infrastruttura - Reti dell'interfaccia di NSX Advanced Load Balancer. Questo campo è facoltativo. Se viene lasciato vuoto, viene utilizzata la stessa rete di AVI_DATA_NETWORK_CIDR. |
AVI_MANAGEMENT_CLUSTER_CONTROL_PLANE_VIP_NETWORK_NAME |
✔ | ✖ | Facoltativa. Definisce la rete VIP del piano di controllo del cluster di gestione. Utilizzarlo quando si desidera configurare una rete VIP separata per il piano di controllo del cluster di gestione. Questo campo è facoltativo. Se viene lasciato vuoto, viene utilizzata la stessa rete di AVI_DATA_NETWORK. |
AVI_MANAGEMENT_CLUSTER_SERVICE_ENGINE_GROUP |
✔ | ✖ | Facoltativa. Specifica il nome del gruppo di motori di servizio che deve essere utilizzato da AKO nel cluster di gestione. Questo campo è facoltativo. Se viene lasciato vuoto, viene utilizzata la stessa rete di AVI_SERVICE_ENGINE_GROUP. |
AVI_MANAGEMENT_CLUSTER_VIP_NETWORK_NAME |
✔ | ✖ | Facoltativa; per impostazione predefinita, è la stessa rete di AVI_DATA_NETWORK. Nome della rete in cui si assegna una subnet IP o un pool di IP mobili a un bilanciamento del carico per il cluster di gestione e il piano di controllo del cluster del carico di lavoro (se si utilizza NSX ALB per fornire HA del piano di controllo). Questa rete deve essere presente nella stessa istanza di vCenter Server della rete Kubernetes che Tanzu Kubernetes Grid utilizza, specificata nella variabile "SERVICE_CIDR" per il cluster di gestione. In questo modo, NSX Advanced Load Balancer può individuare la rete di Kubernetes in vCenter Server, nonché distribuire e configurare i motori di servizio. |
AVI_MANAGEMENT_CLUSTER_VIP_NETWORK_CIDR |
✔ | ✖ | Facoltativa; per impostazione predefinita, è la stessa rete di AVI_DATA_NETWORK_CIDR. CIDR della subnet da utilizzare per il cluster di gestione e il piano di controllo del cluster del carico di lavoro (se si utilizza NSX ALB per fornire il VIP del bilanciamento del carico del piano di controllo HA). Proviene da una delle subnet configurate della rete VIP. È possibile visualizzare il CIDR della subnet per una determinata rete nella vista Infrastruttura - Reti dell'interfaccia di NSX Advanced Load Balancer. |
AVI_NAMESPACE |
✔ | ✖ | Facoltativa. Il valore predefinito è "tkg-system-networking". Spazio dei nomi per l'operatore AKO. |
AVI_NSXT_T1LR |
✔ | ✖ | Facoltativa. Percorso del router T1 di NSX configurato per il cluster di gestione nell'interfaccia utente del controller AVI in NSX Cloud. Questa variabile è necessaria quando si utilizza NSX Cloud nel controller NSX ALB.Per utilizzare un T1 diverso per i cluster del carico di lavoro, modificare install-ako-for-all dell'oggetto AKODeploymentConfig dopo aver creato il cluster di gestione. |
AVI_PASSWORD |
✔ | ✖ | Obbligatoria. Password impostata per l'amministratore del controller al momento della distribuzione. |
AVI_SERVICE_ENGINE_GROUP |
✔ | ✖ | Obbligatoria. Nome del gruppo di motori di servizio. Ad esempio, Default-Group. |
AVI_USERNAME |
✔ | ✖ | Obbligatoria. Nome utente dell'amministratore impostato per l'host controller al momento della distribuzione. |
Routing del pod NSX
Queste variabili configurano i pod del carico di lavoro degli indirizzi IP instradabili, come descritto in Distribuzione di un cluster con pod di IP instradabili. Tutte le impostazioni del tipo di stringa devono essere tra virgolette doppie, ad esempio "true".
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
NSXT_POD_ROUTING_ENABLED |
✖ | ✔ | Facoltativa. Il valore predefinito è "false". Impostarla su "true" per abilitare i pod instradabili di NSX con le variabili seguenti. Vedere Distribuzione di un cluster con pod di IP instradabili. |
NSXT_MANAGER_HOST |
✖ | ✔ | Obbligatoria se NSXT_POD_ROUTING_ENABLED= "true".Indirizzo IP di NSX Manager. |
NSXT_ROUTER_PATH |
✖ | ✔ | Obbligatoria se NSXT_POD_ROUTING_ENABLED= "true". Percorso del router T1 visualizzato in NSX Manager. |
| Per l'autenticazione con nome utente/password in NSX: | |||
NSXT_USERNAME |
✖ | ✔ | Nome utente per l'accesso a NSX Manager. |
NSXT_PASSWORD |
✖ | ✔ | Password per l'accesso a NSX Manager. |
Per l'autenticazione in NSX tramite credenziali e l'archiviazione di tali credenziali in un segreto di Kubernetes (impostare anche NSXT_USERNAME e NSXT_PASSWORD illustrate in precedenza): |
|||
NSXT_SECRET_NAMESPACE |
✖ | ✔ | Facoltativa. Il valore predefinito è "kube-system". Spazio dei nomi con il segreto contenente nome utente e password di NSX. |
NSXT_SECRET_NAME |
✖ | ✔ | Facoltativa. Il valore predefinito è "cloud-provider-vsphere-nsxt-credentials". Nome del segreto contenente nome utente e password di NSX. |
| Per l'autenticazione del certificato in NSX: | |||
NSXT_ALLOW_UNVERIFIED_SSL |
✖ | ✔ | Facoltativa. Il valore predefinito è false. Impostarla su "true" se NSX utilizza un certificato autofirmato. |
NSXT_ROOT_CA_DATA_B64 |
✖ | ✔ | Obbligatoria se NSXT_ALLOW_UNVERIFIED_SSL= "false".Stringa del certificato root dell'autorità di certificazione con codifica base64 che NSX utilizza per l'autenticazione LDAP. |
NSXT_CLIENT_CERT_KEY_DATA |
✖ | ✔ | Stringa del file della chiave del certificato con codifica base64 per il certificato del client locale. |
NSXT_CLIENT_CERT_DATA |
✖ | ✔ | Stringa del file del certificato con codifica base64 per il certificato del client locale. |
| Per l'autenticazione remota in NSX con VMware Identity Manager, in VMware Cloud (VMC): | |||
NSXT_REMOTE_AUTH |
✖ | ✔ | Facoltativa. Il valore predefinito è false. Impostare questa variabile su "true" per l'autenticazione remota in NSX con VMware Identity Manager in VMware Cloud (VMC). |
NSXT_VMC_AUTH_HOST |
✖ | ✔ | Facoltativa; è vuota per impostazione predefinita. Host di autenticazione di VMC. |
NSXT_VMC_ACCESS_TOKEN |
✖ | ✔ | Facoltativa; è vuota per impostazione predefinita. Token di accesso all'autenticazione di VMC. |
IPAM dei nodi
Queste variabili configurano la gestione degli indirizzi IP (IPAM) nel cluster come descritto in IPAM del nodo. Tutte le impostazioni del tipo di stringa devono essere tra virgolette doppie, ad esempio "true".
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
CONTROL_PLANE_NODE_NAMESERVERS |
✔ | ✔ | Elenco delimitato da virgole di server dei nomi, ad esempio "10.10.10.10", per gli indirizzi dei nodi del piano di controllo gestiti dall'IPAM del nodo. Supportato su Ubuntu e Photon; non supportato in Windows. |
NODE_IPAM_IP_POOL_APIVERSION |
✖ | ✔ | Versione dell'API per l'oggetto InClusterIPPool utilizzato dal cluster del carico di lavoro. Impostazione predefinita "ipam.cluster.x-k8s.io/v1alpha2"; le versioni di TKG precedenti utilizzavano v1alpha1. |
NODE_IPAM_IP_POOL_KIND |
✖ | ✔ | Tipo di oggetto pool di IP utilizzato dal cluster del carico di lavoro. L'impostazione predefinita è "InClusterIPPool" o può essere "GlobalInClusterIPPool" per condividere lo stesso pool con altri cluster. |
NODE_IPAM_IP_POOL_NAME |
✖ | ✔ | Nome dell'oggetto pool di IP che configura il pool di IP utilizzato da un cluster del carico di lavoro. |
WORKER_NODE_NAMESERVERS |
✔ | ✔ | Elenco delimitato da virgole di server dei nomi, ad esempio "10.10.10.10", per gli indirizzi dei nodi worker gestiti dall'IPAM del nodo. Supportato su Ubuntu e Photon; non supportato in Windows. |
MANAGEMENT_NODE_IPAM_IP_POOL_GATEWAY |
✔ | ✖ | Gateway predefinito per gli indirizzi dei pool IPAM in un cluster di gestione, ad esempio '"10.10.10.1". |
MANAGEMENT_NODE_IPAM_IP_POOL_ADDRESSES |
✔ | ✖ | Indirizzi disponibili per IPAM da assegnare in un cluster di gestione, in un elenco delimitato da virgole che può includere singoli indirizzi IP, intervalli (ad esempio 10.0.0.2-10.0.0.100) o CIDR (ad esempio 10.0.0.32/27).Includere gli indirizzi aggiuntivi che devono rimanere inutilizzati, in base alle esigenze degli aggiornamenti del cluster. Il numero predefinito di indirizzi aggiuntivi richiesti è uno e viene impostato dall'annotazione topology.cluster.x-k8s.io/upgrade-concurrency nelle definizioni topology.controlPlane e topology.workers della specifica dell'oggetto cluster. |
MANAGEMENT_NODE_IPAM_IP_POOL_SUBNET_PREFIX |
✔ | ✖ | Prefisso di rete della subnet per gli indirizzi dei pool IPAM in un cluster di gestione autonomo, ad esempio "24" |
Cluster abilitati per GPU
Queste variabili configurano i cluster del carico di lavoro abilitati per GPU in modalità passthrough PCI, come descritto in Distribuzione di un cluster del carico di lavoro abilitato per GPU. Tutte le impostazioni del tipo di stringa devono essere tra virgolette doppie, ad esempio "true".
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
VSPHERE_CONTROL_PLANE_CUSTOM_VMX_KEYS |
✔ | ✔ | Consente di impostare chiavi VMX personalizzate in tutte le macchine del piano di controllo. Utilizzare il formato Key1=Value1,Key2=Value2. Vedere Distribuzione di un cluster del carico di lavoro abilitato per GPU. |
VSPHERE_CONTROL_PLANE_HARDWARE_VERSION |
✔ | ✔ | Versione hardware per la macchina virtuale del piano di controllo con il dispositivo GPU in modalità passthrough PCI. La versione minima richiesta è la 17. Il formato del valore è vmx-17, dove le cifre finali sono la versione hardware della macchina virtuale. Per il supporto delle funzionalità su versioni hardware diverse, vedere Funzionalità hardware disponibili con le impostazioni di compatibilità delle macchine virtuali nella documentazione di vSphere. |
VSPHERE_CONTROL_PLANE_PCI_DEVICES |
✔ | ✔ | Consente di configurare il passthrough PCI in tutte le macchine del piano di controllo. Utilizzare il formato <vendor_idgt;:<device_id>. Ad esempio, VSPHERE_WORKER_PCI_DEVICES: "0x10DE:0x1EB8". Per individuare gli ID del fornitore e del dispositivo, vedere Distribuzione di un cluster del carico di lavoro abilitato per GPU. |
VSPHERE_IGNORE_PCI_DEVICES_ALLOW_LIST |
✔ | ✔ | Impostarla su false se si utilizza la GPU NVIDIA Tesla T4 e su true se si utilizza la GPU NVIDIA V100. |
VSPHERE_WORKER_CUSTOM_VMX_KEYS |
✔ | ✔ | Consente di impostare le chiavi VMX personalizzate in tutte le macchine worker. Utilizzare il formato Key1=Value1,Key2=Value2. Per un esempio, vedere Distribuzione di un cluster del carico di lavoro abilitato per GPU. |
VSPHERE_WORKER_HARDWARE_VERSION |
✔ | ✔ | Versione hardware per la macchina virtuale worker con dispositivo GPU in modalità passthrough PCI. La versione minima richiesta è la 17. Il formato del valore è vmx-17, dove le cifre finali sono la versione hardware della macchina virtuale. Per il supporto delle funzionalità su versioni hardware diverse, vedere Funzionalità hardware disponibili con le impostazioni di compatibilità delle macchine virtuali nella documentazione di vSphere. |
VSPHERE_WORKER_PCI_DEVICES |
✔ | ✔ | Consente di configurare il passthrough PCI in tutte le macchine worker. Utilizzare il formato <vendor_idgt;:<device_id>. Ad esempio, VSPHERE_WORKER_PCI_DEVICES: "0x10DE:0x1EB8". Per individuare gli ID del fornitore e del dispositivo, vedere Distribuzione di un cluster del carico di lavoro abilitato per GPU. |
WORKER_ROLLOUT_STRATEGY |
✔ | ✔ | Facoltativa. Consente di configurare la strategia di implementazione MachineDeployment. Il valore predefinito è RollingUpdate. Se è impostata su OnDelete, quando vengono eseguiti gli aggiornamenti le macchine worker esistenti vengono eliminate prima che vengano create le macchine worker sostitutive. È necessario impostare il valore su OnDelete se tutti i dispositivi PCI disponibili sono utilizzati dai nodi worker. |
AWS
Le variabili nella tabella seguente sono le opzioni specificate nel file di configurazione del cluster quando si distribuiscono cluster del carico di lavoro in AWS. Molte di queste opzioni sono uguali per il cluster del carico di lavoro e per il cluster di gestione utilizzato per distribuirlo.
Per ulteriori informazioni sui file di configurazione per AWS, vedere Configurazione del cluster di gestione per AWS e File di configurazione del cluster AWS.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
AWS_ACCESS_KEY_ID |
✔ | ✔ | Facoltativa. ID della chiave di accesso per l'account AWS. Questa è un'opzione per l'autenticazione in AWS. Vedere Configurazione delle credenziali dell'account AWS. Utilizzare solo AWS_PROFILE o una combinazione di AWS_ACCESS_KEY_ID e AWS_SECRET_ACCESS_KEY, ma non entrambi. |
AWS_CONTROL_PLANE_OS_DISK_SIZE_GIB |
✔ | ✔ | Facoltativa. Dimensioni del disco piano di controllo. Sovrascrive le dimensioni predefinite del disco per il tipo di macchina virtuale impostato da CONTROL_PLANE_MACHINE_TYPE, SIZE o CONTROLPLANE_SIZE. |
AWS_LOAD_BALANCER_SCHEME_INTERNAL |
✔ | ✔ | Facoltativa. Per i cluster di gestione, consente di impostare lo schema di bilanciamento del carico come interno impedendo l'accesso tramite Internet. Per i cluster del carico di lavoro, garantisce che il cluster di gestione acceda internamente al bilanciamento del carico del cluster del carico di lavoro quando condividono un VPC o sono in peer. Vedere Utilizzo del bilanciamento del carico interno per il server dell'API di Kubernetes. |
AWS_NODE_AZ |
✔ | ✔ | Obbligatoria. Nome della zona di disponibilità AWS nella regione scelta che si desidera utilizzare come zona di disponibilità per questo cluster di gestione. I nomi delle zone di disponibilità sono uguali al nome della regione AWS, con una singola lettera minuscola come suffisso, ad esempio a, b, c. Ad esempio, us-west-2a. Per distribuire un cluster di gestione prod con tre nodi del piano di controllo, è inoltre necessario impostare AWS_NODE_AZ_1 e AWS_NODE_AZ_2. La lettera del suffisso in ciascuna di queste zone di disponibilità deve essere univoca. Ad esempio, us-west-2a, us-west-2b e us-west-2c. |
AWS_NODE_OS_DISK_SIZE_GIB |
✔ | ✔ | Facoltativa. Dimensioni del disco per i nodi worker. Sovrascrive le dimensioni predefinite del disco per il tipo di macchina virtuale impostato da NODE_MACHINE_TYPE, SIZE o WORKER_SIZE. |
AWS_NODE_AZ_1 e AWS_NODE_AZ_2 |
✔ | ✔ | Facoltativa. Impostare queste variabili se si desidera distribuire un cluster di gestione prod con tre nodi del piano di controllo. Entrambe le zone di disponibilità devono trovarsi nella stessa regione di AWS_NODE_AZ. Per ulteriori informazioni, vedere AWS_NODE_AZ. Ad esempio, us-west-2a, ap-northeast-2b e così via. |
AWS_PRIVATE_NODE_CIDR_1 |
✔ | ✔ | Facoltativa. Se l'intervallo consigliato 10.0.2.0/24 non è disponibile, immettere un intervallo di IP diverso nel formato CIDR. Quando Tanzu Kubernetes Grid distribuisce il cluster di gestione, crea questa subnet in AWS_NODE_AZ_1. Per ulteriori informazioni, vedere AWS_PRIVATE_NODE_CIDR. |
AWS_PRIVATE_NODE_CIDR_2 |
✔ | ✔ | Facoltativa. Se l'intervallo consigliato 10.0.4.0/24 non è disponibile, immettere un intervallo di IP diverso nel formato CIDR. Quando Tanzu Kubernetes Grid distribuisce il cluster di gestione, crea questa subnet in AWS_NODE_AZ_2. Per ulteriori informazioni, vedere AWS_PRIVATE_NODE_CIDR. |
AWS_PROFILE |
✔ | ✔ | Facoltativa. Profilo delle credenziali AWS, gestito da aws configure, utilizzato da Tanzu Kubernetes Grid per accedere al proprio account AWS. Questa è l'opzione preferita per l'autenticazione in AWS. Vedere Configurazione delle credenziali dell'account AWS.Utilizzare solo AWS_PROFILE o una combinazione di AWS_ACCESS_KEY_ID e AWS_SECRET_ACCESS_KEY, ma non entrambi. |
AWS_PUBLIC_NODE_CIDR_1 |
✔ | ✔ | Facoltativa. Se l'intervallo consigliato 10.0.3.0/24 non è disponibile, immettere un intervallo di IP diverso nel formato CIDR. Quando Tanzu Kubernetes Grid distribuisce il cluster di gestione, crea questa subnet in AWS_NODE_AZ_1. Per ulteriori informazioni, vedere AWS_PUBLIC_NODE_CIDR. |
AWS_PUBLIC_NODE_CIDR_2 |
✔ | ✔ | Facoltativa. Se l'intervallo consigliato 10.0.5.0/24 non è disponibile, immettere un intervallo di IP diverso in formato CIDR. Quando Tanzu Kubernetes Grid distribuisce il cluster di gestione, crea questa subnet in AWS_NODE_AZ_2. Per ulteriori informazioni, vedere AWS_PUBLIC_NODE_CIDR. |
AWS_PRIVATE_SUBNET_ID |
✔ | ✔ | Facoltativa. Se si imposta AWS_VPC_ID per l'utilizzo di un VPC esistente, immettere l'ID di una subnet privata già esistente in AWS_NODE_AZ. Questa impostazione è facoltativa. Se non viene impostata, tanzu management-cluster create identifica automaticamente la subnet privata. Per distribuire un cluster di gestione prod con tre nodi del piano di controllo, è inoltre necessario impostare AWS_PRIVATE_SUBNET_ID_1 e AWS_PRIVATE_SUBNET_ID_2. |
AWS_PRIVATE_SUBNET_ID_1 |
✔ | ✔ | Facoltativa. ID di una subnet privata esistente in AWS_NODE_AZ_1. Se non si imposta questa variabile, tanzu management-cluster create identifica automaticamente la subnet privata. Per ulteriori informazioni, vedere AWS_PRIVATE_SUBNET_ID. |
AWS_PRIVATE_SUBNET_ID_2 |
✔ | ✔ | Facoltativa. ID di una subnet privata esistente in AWS_NODE_AZ_2. Se non si imposta questa variabile, tanzu management-cluster create identifica automaticamente la subnet privata. Per ulteriori informazioni, vedere AWS_PRIVATE_SUBNET_ID. |
AWS_PUBLIC_SUBNET_ID |
✔ | ✔ | Facoltativa. Se si imposta AWS_VPC_ID per l'utilizzo di un VPC esistente, immettere l'ID di una subnet pubblica già esistente in AWS_NODE_AZ. Questa impostazione è facoltativa. Se non si imposta questa variabile, tanzu management-cluster create identifica automaticamente la subnet pubblica. Per distribuire un cluster di gestione prod con tre nodi del piano di controllo, è inoltre necessario impostare AWS_PUBLIC_SUBNET_ID_1 e AWS_PUBLIC_SUBNET_ID_2. |
AWS_PUBLIC_SUBNET_ID_1 |
✔ | ✔ | Facoltativa. ID di una subnet pubblica esistente in AWS_NODE_AZ_1. Se non si imposta questa variabile, tanzu management-cluster create identifica automaticamente la subnet pubblica. Per ulteriori informazioni, vedere AWS_PUBLIC_SUBNET_ID. |
AWS_PUBLIC_SUBNET_ID_2 |
✔ | ✔ | Facoltativa. ID di una subnet pubblica esistente in AWS_NODE_AZ_2. Se non si imposta questa variabile, tanzu management-cluster create identifica automaticamente la subnet pubblica. Per ulteriori informazioni, vedere AWS_PUBLIC_SUBNET_ID. |
AWS_REGION |
✔ | ✔ | Obbligatoria. Nome della regione AWS in cui distribuire il cluster. Ad esempio, us-west-2. È inoltre possibile specificare le regioni us-gov-east e us-gov-west in AWS GovCloud. Se è già stata impostata una regione diversa come variabile di ambiente, ad esempio in Distribuzione di un cluster di gestione in AWS, è necessario annullare l'impostazione di tale variabile di ambiente. Ad esempio, us-west-2, ap-northeast-2 e così via. |
AWS_SECRET_ACCESS_KEY |
✔ | ✔ | Facoltativa. Chiave di accesso segreta per l'account AWS. Questa è un'opzione per l'autenticazione in AWS. Vedere Configurazione delle credenziali dell'account AWS. Utilizzare solo AWS_PROFILE o una combinazione di AWS_ACCESS_KEY_ID e AWS_SECRET_ACCESS_KEY, ma non entrambi. |
AWS_SECURITY_GROUP_APISERVER_LB |
✔ | ✔ | Facoltativa. Gruppi di sicurezza personalizzati con regole personalizzate da applicare al cluster. Vedere Configurazione di gruppi di sicurezza personalizzati. |
AWS_SECURITY_GROUP_BASTION |
|||
AWS_SECURITY_GROUP_CONTROLPLANE |
|||
AWS_SECURITY_GROUP_APISERVER_LB |
|||
AWS_SECURITY_GROUP_NODE |
|||
AWS_SESSION_TOKEN |
✔ | ✔ | Facoltativa. Specificare il token della sessione AWS concesso al proprio account se è necessario utilizzare una chiave di accesso temporanea. Per ulteriori informazioni sull'utilizzo delle chiavi di accesso temporanee, vedere Informazioni sulle credenziali di AWS e su come ottenerle. Specificare il token della sessione per l'account AWS. In alternativa, è possibile specificare le credenziali dell'account come variabili di ambiente locale o nella catena del provider delle credenziali predefinita di AWS. |
AWS_SSH_KEY_NAME |
✔ | ✔ | Obbligatoria. Nome della chiave privata SSH registrata nell'account AWS. |
AWS_VPC_ID |
✔ | ✔ | Facoltativa. Per utilizzare un VPC già esistente nella regione AWS selezionata, immettere l'ID del VPC, quindi impostare AWS_PUBLIC_SUBNET_ID e AWS_PRIVATE_SUBNET_ID. |
BASTION_HOST_ENABLED |
✔ | ✔ | Facoltativa. Per impostazione predefinita, questa opzione è impostata su "true" nella configurazione globale di Tanzu Kubernetes Grid. Specificare "true" per distribuire un host Bastion AWS o "false" per riutilizzare un host Bastion esistente. Se nelle zone di disponibilità non esiste alcun host Bastion e si imposta AWS_VPC_ID per l'utilizzo di un VPC esistente, impostare BASTION_HOST_ENABLED su "true". |
CONTROL_PLANE_MACHINE_TYPE |
✔ | ✔ | Obbligatoria se non è impostata la variabile SIZE o CONTROLPLANE_SIZE indipendente dal cloud. Tipo di istanza di Amazon EC2 da utilizzare per i nodi del piano di controllo del cluster, ad esempio t3.small o m5.large. |
NODE_MACHINE_TYPE |
✔ | ✔ | Obbligatoria se non è impostata la variabile SIZE o WORKER_SIZE indipendente dal cloud. Tipo di istanza di Amazon EC2 da utilizzare per i nodi worker del cluster, ad esempio t3.small o m5.large. |
Microsoft Azure
Le variabili nella tabella seguente sono le opzioni specificate nel file di configurazione del cluster quando si distribuiscono cluster del carico di lavoro in Azure. Molte di queste opzioni sono uguali per il cluster del carico di lavoro e per il cluster di gestione utilizzato per distribuirlo.
Per ulteriori informazioni sui file di configurazione per Azure, vedere Configurazione del cluster di gestione per Azure e File di configurazione del cluster Azure.
| Variabile | Può essere impostata in... | Descrizione | |
|---|---|---|---|
| YAML del cluster di gestione | YAML del cluster del carico di lavoro | ||
AZURE_CLIENT_ID |
✔ | ✔ | Obbligatoria. ID client dell'app per Tanzu Kubernetes Grid registrata in Azure. |
AZURE_CLIENT_SECRET |
✔ | ✔ | Obbligatoria. Segreto del client Azure di Registrazione di un'app Tanzu Kubernetes Grid in Azure. |
AZURE_CUSTOM_TAGS |
✔ | ✔ | Facoltativa. Elenco di tag separati da virgola da applicare alle risorse di Azure create per il cluster. Un tag è una coppia chiave-valore, ad esempio "foo=bar, plan=prod". Per ulteriori informazioni sull'assegnazione di tag alle risorse di Azure, vedere Usare i tag per organizzare le risorse di Azure e la gerarchia di gestione e Supporto dei tag per le risorse di Azure nella documentazione di Microsoft Azure. |
AZURE_ENVIRONMENT |
✔ | ✔ | Facoltativa. Il valore predefinito è AzurePublicCloud. I cloud supportati sono AzurePublicCloud, AzureChinaCloud, AzureGermanCloud e AzureUSGovernmentCloud. |
AZURE_IDENTITY_NAME |
✔ | ✔ | Facoltativa. Impostarla se si desidera utilizzare cluster di account Azure diversi. Nome da utilizzare per la variabile AzureClusterIdentity creata per utilizzare cluster di account Azure diversi. Per ulteriori informazioni, vedere Cluster in account Azure diversi in Distribuzione dei cluster del carico di lavoro in Azure. |
AZURE_IDENTITY_NAMESPACE |
✔ | ✔ | Facoltativa. Impostarla se si desidera utilizzare cluster di account Azure diversi. Spazio dei nomi per la variabile AzureClusterIdentity creata per utilizzare cluster di account Azure diversi. Per ulteriori informazioni, vedere Cluster in account Azure diversi in Distribuzione dei cluster del carico di lavoro in Azure. |
AZURE_LOCATION |
✔ | ✔ | Obbligatoria. Nome della regione di Azure in cui distribuire il cluster. Ad esempio, eastus. |
AZURE_RESOURCE_GROUP |
✔ | ✔ | Facoltativa; l'impostazione predefinita è CLUSTER_NAME. Nome del gruppo di risorse di Azure che si desidera utilizzare per il cluster. Il nome deve essere univoco per ogni cluster. AZURE_RESOURCE_GROUP e AZURE_VNET_RESOURCE_GROUP sono uguali per impostazione predefinita. |
AZURE_SSH_PUBLIC_KEY_B64 |
✔ | ✔ | Obbligatoria. Chiave pubblica SSH, creata in Distribuzione di un cluster di gestione in Microsoft Azure, convertita in base64 con i caratteri di fine riga rimossi. Ad esempio, c3NoLXJzYSBB [...] vdGFsLmlv. |
AZURE_SUBSCRIPTION_ID |
✔ | ✔ | Obbligatoria. ID della sottoscrizione di Azure. |
AZURE_TENANT_ID |
✔ | ✔ | Obbligatoria. ID tenant dell'account azure. |
| Rete | |||
AZURE_CONTROL_PLANE_OUTBOUND_LB_FRONTEND_IP_COUNT |
✔ | ✔ | Facoltativa. Il valore predefinito è 1. Impostare questa variabile per aggiungere più indirizzi IP front-end al bilanciamento del carico del piano di controllo negli ambienti in cui è previsto un numero elevato di connessioni in uscita. |
AZURE_ENABLE_ACCELERATED_NETWORKING |
✔ | ✔ | Facoltativa. Il valore predefinito è true. Impostarla su false per disattivare la rete accelerata di Azure nelle macchine virtuali con più di 4 CPU. |
AZURE_ENABLE_CONTROL_PLANE_OUTBOUND_LB |
✔ | ✔ | Facoltativa. Impostare questa variabile su true se AZURE_ENABLE_PRIVATE_CLUSTER è true e si desidera abilitare un indirizzo IP pubblico nel bilanciamento del carico in uscita per il piano di controllo. |
AZURE_ENABLE_NODE_OUTBOUND_LB |
✔ | ✔ | Facoltativa. Impostare questo valore su true se AZURE_ENABLE_PRIVATE_CLUSTER è true e si desidera abilitare un indirizzo IP pubblico nel bilanciamento del carico in uscita per i nodi worker. |
AZURE_ENABLE_PRIVATE_CLUSTER |
✔ | ✔ | Facoltativa. Impostare questa variabile su true per configurare il cluster come privato e utilizzare un bilanciamento del carico interno di Azure per il traffico in entrata. Per ulteriori informazioni, vedere Cluster privati di Azure. |
AZURE_FRONTEND_PRIVATE_IP |
✔ | ✔ | Facoltativa. Impostare questa variabile se AZURE_ENABLE_PRIVATE_CLUSTER è true e si desidera sostituire l'indirizzo del bilanciamento del carico interno predefinito 10.0.0.100. |
AZURE_NODE_OUTBOUND_LB_FRONTEND_IP_COUNT |
✔ | ✔ | Facoltativa. Il valore predefinito è 1. Impostare questa variabile per aggiungere più indirizzi IP front-end al bilanciamento del carico del nodo worker in ambienti in cui è previsto un numero elevato di connessioni in uscita. |
AZURE_NODE_OUTBOUND_LB_IDLE_TIMEOUT_IN_MINUTES |
✔ | ✔ | Facoltativa. Il valore predefinito è 4. Impostare questa variabile per specificare il numero di minuti per cui le connessioni TCP in uscita vengono tenute aperte tramite il bilanciamento del carico in uscita del nodo worker. |
AZURE_VNET_CIDR |
✔ | ✔ | Facoltativa. Impostarla se si desidera distribuire il cluster in nuove VNet e subnet e sostituire i valori predefiniti. Per impostazione predefinita, AZURE_VNET_CIDR è impostata su 10.0.0.0/16, AZURE_CONTROL_PLANE_SUBNET_CIDR è impostata su 10.0.0.0/24 e AZURE_NODE_SUBNET_CIDR è impostata su 10.0.1.0/24. |
AZURE_CONTROL_PLANE_SUBNET_CIDR |
|||
AZURE_NODE_SUBNET_CIDR |
|||
AZURE_VNET_NAME |
✔ | ✔ | Facoltativa. Impostarla se si desidera distribuire il cluster in VNet e subnet esistenti o assegnare nomi a nuove VNet e subnet. |
AZURE_CONTROL_PLANE_SUBNET_NAME |
|||
AZURE_NODE_SUBNET_NAME |
|||
AZURE_VNET_RESOURCE_GROUP |
✔ | ✔ | Facoltativa; il valore predefinito è AZURE_RESOURCE_GROUP. |
| Macchine virtuali del piano di controllo | |||
AZURE_CONTROL_PLANE_DATA_DISK_SIZE_GIB |
✔ | ✔ | Facoltativa. Dimensioni del disco dati e del disco del sistema operativo, come descritto nella documentazione di Azure Ruoli del disco, per le macchine virtuali del piano di controllo, in GB. Esempi: 128, 256. I nodi del piano di controllo vengono sempre sottoposti a provisioning con un disco dati. |
AZURE_CONTROL_PLANE_OS_DISK_SIZE_GIB |
|||
AZURE_CONTROL_PLANE_MACHINE_TYPE |
✔ | ✔ | Facoltativa. Il valore predefinito è Standard_D2s_v3. Dimensioni della macchina virtuale Azure per le macchine virtuali del nodo del piano di controllo, scelte in base ai carichi di lavoro previsti. Il requisito minimo per i tipi di istanza di Azure è 2 CPU e 8 GB di memoria. Per i possibili valori, vedere l'interfaccia del programma di installazione di Tanzu Kubernetes Grid. |
AZURE_CONTROL_PLANE_OS_DISK_STORAGE_ACCOUNT_TYPE |
✔ | ✔ | Facoltativa. Tipo di account di storage di Azure per i dischi della macchina virtuale del piano di controllo. Esempio: Premium_LRS. |
| Macchine virtuali del nodo worker | |||
AZURE_ENABLE_NODE_DATA_DISK |
✔ | ✔ | Facoltativa. Il valore predefinito è false. Impostarla su true per eseguire il provisioning di un disco dati per ogni macchina virtuale del nodo worker, come descritto nella documentazione di Azure Ruoli del disco. |
AZURE_NODE_DATA_DISK_SIZE_GIB |
✔ | ✔ | Facoltativa. Impostare questa variabile se AZURE_ENABLE_NODE_DATA_DISK è true. Dimensioni del disco dati, come descritto nella documentazione di Azure Ruoli del disco, per le macchine virtuali worker, in GB. Esempi: 128, 256. |
AZURE_NODE_OS_DISK_SIZE_GIB |
✔ | ✔ | Facoltativa. Dimensioni del disco del sistema operativo, come descritto nella documentazione di Azure Ruoli del disco, per le macchine virtuali worker, in GB. Esempi: 128, 256. |
AZURE_NODE_MACHINE_TYPE |
✔ | ✔ | Facoltativa. Dimensioni della macchina virtuale Azure per le macchine virtuali del nodo worker, scelte in base ai carichi di lavoro previsti. Il valore predefinito è Standard_D2s_v3. Per i possibili valori, vedere l'interfaccia del programma di installazione di Tanzu Kubernetes Grid. |
AZURE_NODE_OS_DISK_STORAGE_ACCOUNT_TYPE |
✔ | ✔ | Facoltativa. Impostare questa variabile se AZURE_ENABLE_NODE_DATA_DISK è true. Tipo di account di storage di Azure per i dischi della macchina virtuale worker. Esempio: Premium_LRS. |
Precedenza dei valori della configurazione
Quando la CLI di Tanzu crea un cluster, legge i valori per le variabili elencate in questo argomento di più origini. Se tali origini sono in conflitto, risolve i conflitti nell'ordine di precedenza decrescente seguente:
| Livelli di elaborazione, in ordine di precedenza decrescente | Origine | Esempi |
|---|---|---|
| 1. Variabili di configurazione del cluster di gestione impostate nell'interfaccia del programma di installazione | Immesse nell'interfaccia del programma di installazione avviata dall'opzione --ui e scritte nei file di configurazione del cluster. La posizione del file predefinita è ~/.config/tanzu/tkg/clusterconfigs/. |
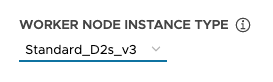 |
| 2. Variabili di configurazione del cluster impostate nell'ambiente locale | Impostate nella shell. | export AZURE_NODE_MACHINE_TYPE=Standard_D2s_v3 |
3. Variabili di configurazione del cluster impostate nella CLI di Tanzu, con tanzu config set env. |
Impostate nella shell; salvate nel file di configurazione globale della CLI di Tanzu, ~/.config/tanzu/config.yaml. |
tanzu config set env.AZURE_NODE_MACHINE_TYPE Standard_D2s_v3 |
| 4. Variabili di configurazione del cluster impostate nel file di configurazione del cluster | Impostate nel file passato all'opzione --file di tanzu management-cluster create o tanzu cluster create. Il file predefinito è ~/.config/tanzu/tkg/cluster-config.yaml. |
AZURE_NODE_MACHINE_TYPE: Standard_D2s_v3 |
| 5. Valori di configurazione predefiniti | Impostarli in providers/config_default.yaml. Non modificare questo file. |
AZURE_NODE_MACHINE_TYPE: "Standard_D2s_v3" |
