









Distribuzione di un cluster del carico di lavoro in hardware specializzato
Tanzu Kubernetes Grid supporta la distribuzione di cluster del carico di lavoro in tipi specifici di host abilitati per GPU in vSphere 7.0 e versioni successive.
Distribuzione di un cluster del carico di lavoro abilitato per GPU
Per utilizzare un nodo con una GPU in un cluster del carico di lavoro vSphere, è necessario abilitare la modalità passthrough PCI. In questo modo, il cluster può accedere direttamente alla GPU, ignorando l'hypervisor ESXi, che fornisce un livello di prestazioni simile a quello della GPU in un sistema nativo. Quando si utilizza la modalità passthrough PCI, ogni dispositivo GPU viene dedicato a una macchina virtuale nel cluster del carico di lavoro vSphere.
NotaPer aggiungere nodi abilitati per GPU ai cluster esistenti, utilizzare il comando
tanzu cluster node-pool set.
Prerequisiti
- Host ESXi con scheda GPU NVIDIA V100 o NVIDIA Tesla T4.
- vSphere 7.0 Update 3 e versioni successive. Di seguito sono elencate le build per 7.0u3, che è il minimo necessario per supportare questa funzionalità.
- Tanzu Kubernetes Grid v1.6+.
- Helm, il gestore dei pacchetti di Kubernetes. Per l'installazione, vedere Installazione di Helm nella documentazione di Helm.
Procedura
Per creare un cluster del carico di lavoro di host abilitati per GPU, eseguire i passaggi seguenti per abilitare il passthrough PCI, creare un'immagine della macchina personalizzata, creare un file di configurazione del cluster e una versione Tanzu Kubernetes, distribuire il cluster del carico di lavoro e installare un operatore GPU tramite Helm.
-
Aggiungere gli host ESXi con le schede GPU al vSphere Client.
-
Abilitare il passthrough PCI e registrare gli ID GPU nel modo seguente:
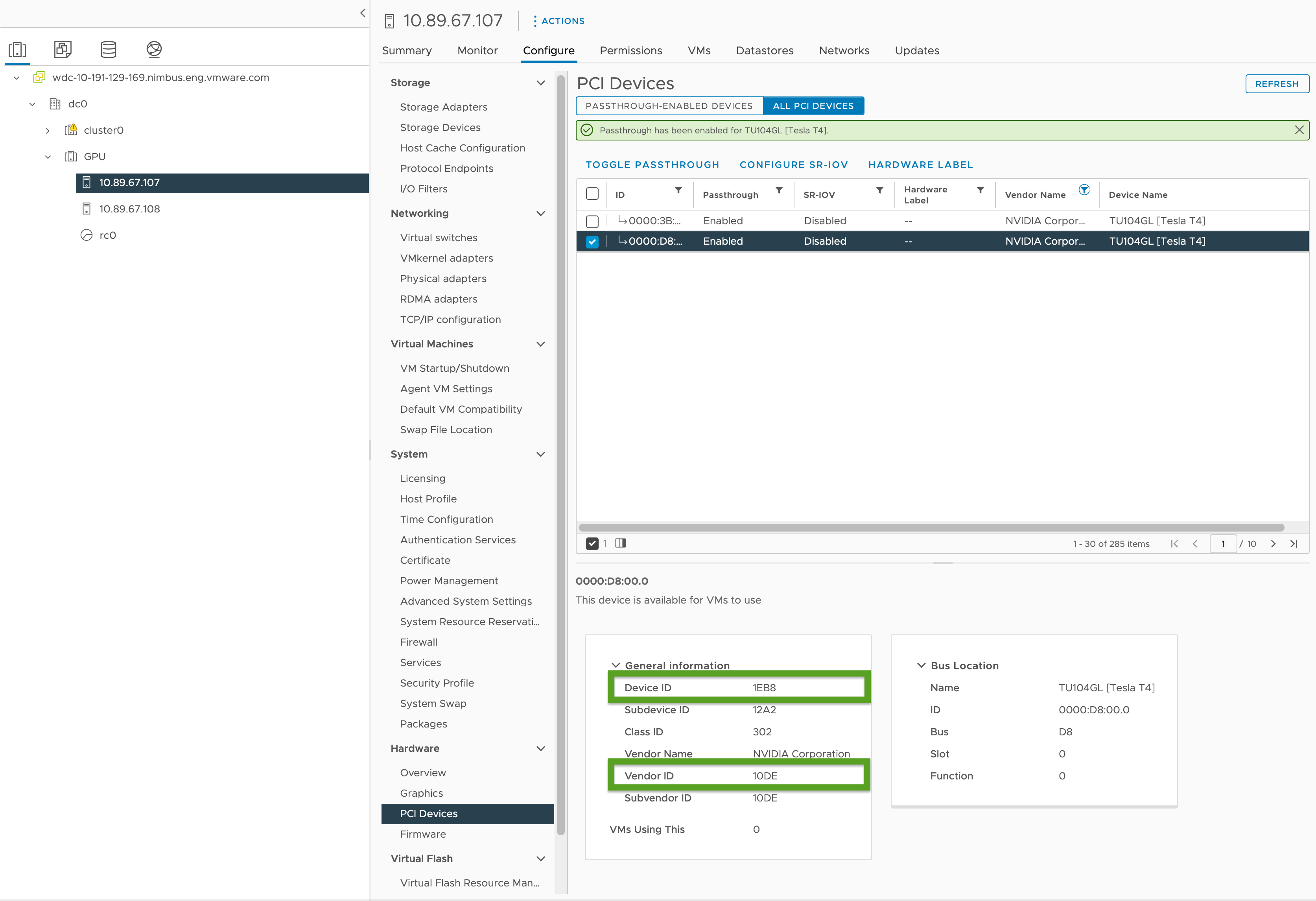
- In vSphere Client, selezionare l'host ESXi di destinazione nel cluster
GPU. - Selezionare Configura (Configure) > Hardware > Dispositivi PCI (PCI Devices).
- Selezionare la scheda Tutti i dispositivi PCI.
- Selezionare la GPU di destinazione dall'elenco.
- Fare clic su Attiva/disattiva passthrough.
- In Informazioni generali (General Information), registrare l'ID dispositivo (Device ID) e l'ID fornitore (Vendor ID), evidenziati in verde nell'immagine seguente. Gli ID sono gli stessi per schede GPU identiche. Saranno necessari per il file di configurazione del cluster.
- In vSphere Client, selezionare l'host ESXi di destinazione nel cluster
-
Creare un file di configurazione del cluster del carico di lavoro utilizzando il modello in Modello di cluster del carico di lavoro e includere le seguenti variabili:
... VSPHERE_WORKER_PCI_DEVICES: "0x<VENDOR-ID>:0x<DEVICE-ID>" VSPHERE_WORKER_CUSTOM_VMX_KEYS: 'pciPassthru.allowP2P=true,pciPassthru.RelaxACSforP2P=true,pciPassthru.use64bitMMIO=true,pciPassthru.64bitMMIOSizeGB=<GPU-SIZE>' VSPHERE_IGNORE_PCI_DEVICES_ALLOW_LIST: "<BOOLEAN>" VSPHERE_WORKER_HARDWARE_VERSION: vmx-17 WORKER_ROLLOUT_STRATEGY: "RollingUpdate"In cui:
<VENDOR-ID>e<DEVICE-ID>sono l'ID fornitore e l'ID del dispositivo registrati in un passaggio precedente. Ad esempio, se l'ID fornitore è10DEe l'ID dispositivo è1EB8, il valore è"0x10DE:0x1EB8".<GPU-SIZE>sono i GB totali di memoria di framebuffer di tutte le GPU nel cluster arrotondati per eccesso alla potenza superiore di due.- Ad esempio, con due GPU da 40 GB il totale è 80 GB, arrotondato per eccesso a 128 GB; quindi si imposterà il valore a
pciPassthru.64bitMMIOSizeGB=128. - Per trovare la memoria richiesta per la scheda GPU; consultare la scheda della GPU NVIDIA specifica. Vedere la tabella Requisiti per l'utilizzo di vGPU su GPU che richiedono 64 GB o più di spazio MMIO con macchine virtuali a memoria estesa nella documentazione di NVIDIA.
- Vedere anche:
- Articolo della Knowledge Base di VMware Configurazione dei dispositivi di I/O pass-through VMDirectPath su un host VMware ESX o VMware ESXi
- Articolo della Knowledge Base di PowerEdge: PCI Passthrough "L'accensione del modulo 'DevicePowerOn' non è riuscita" quando si utilizzano GPU con macchine virtuali su vSphere
- Ad esempio, con due GPU da 40 GB il totale è 80 GB, arrotondato per eccesso a 128 GB; quindi si imposterà il valore a
<BOOLEAN>èfalsese si utilizza la GPU NVIDIA Tesla T4 etruese si utilizza la GPU NVIDIA V100.<VSPHERE_WORKER_HARDWARE_VERSION>è la versione hardware della macchina virtuale a cui si desidera eseguire l'aggiornamento della macchina virtuale. La versione minima richiesta per i nodi GPU deve essere 17.WORKER_ROLLOUT_STRATEGYèRollingUpdatese sono presenti dispositivi PCI aggiuntivi che possono essere utilizzati dai nodi worker durante gli aggiornamenti; in caso contrario, utilizzareOnDelete.
Nota
È possibile utilizzare un solo tipo di GPU per macchina virtuale. Ad esempio, non è possibile utilizzare sia NVIDIA V100 sia NVIDIA Tesla T4 in una singola macchina virtuale, ma è possibile utilizzare più istanze di GPU con lo stesso ID fornitore e ID dispositivo.
La CLI di
tanzunon consente l'aggiornamento della specificaWORKER_ROLLOUT_STRATEGYinMachineDeployment. Se l'aggiornamento del cluster si blocca a causa di dispositivi PCI non disponibili, VMware suggerisce di modificare la strategiaMachineDeploymentutilizzando la CLIkubectl. La strategia di implementazione è definita inspec.strategy.type.Per un elenco completo delle variabili che è possibile configurare per i cluster abilitati per GPU, vedere Cluster abilitati per GPU in Informazioni di riferimento sulle variabili del file di configurazione.
-
Creare il cluster del carico di lavoro eseguendo quanto segue:
tanzu cluster create -f CLUSTER-CONFIG-NAMEDove
CLUSTER-CONFIG-NAMEè il nome di configurazione del cluster creato nei passaggi precedenti. -
Aggiungere il repository Helm NVIDIA:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \ && helm repo update -
Installare l'operatore GPU NVIDIA:
helm install --kubeconfig=./KUBECONFIG --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operatorDove
KUBECONFIGè il nome e posizione delkubeconfigper il cluster del carico di lavoro. Per ulteriori informazioni, vedere Recupero dikubeconfigdel cluster del carico di lavoro.Per informazioni sui parametri in questo comando, vedere Installazione dell'operatore GPU nella documentazione di NVIDIA.
-
Assicurarsi che l'operatore GPU NVIDIA sia in esecuzione:
kubectl --kubeconfig=./KUBECONFIG get pods -AL'output è simile a:
NAMESPACE NAME READY STATUS RESTARTS AGE gpu-operator gpu-feature-discovery-szzkr 1/1 Running 0 6m18s gpu-operator gpu-operator-1676396573-node-feature-discovery-master-7795vgdnd 1/1 Running 0 7m7s gpu-operator gpu-operator-1676396573-node-feature-discovery-worker-bq6ct 1/1 Running 0 7m7s gpu-operator gpu-operator-84dfbbfd8-jd98f 1/1 Running 0 7m7s gpu-operator nvidia-container-toolkit-daemonset-6zncv 1/1 Running 0 6m18s gpu-operator nvidia-cuda-validator-2rz4m 0/1 Completed 0 98s gpu-operator nvidia-dcgm-exporter-vgw7p 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-daemonset-mln6z 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-validator-sczdk 0/1 Completed 0 22s gpu-operator nvidia-driver-daemonset-b7flb 1/1 Running 0 6m38s gpu-operator nvidia-operator-validator-2v8zk 1/1 Running 0 6m18s
Test del cluster GPU
Per testare il cluster abilitato per la GPU, creare un manifest dei pod per l'esempio di cuda-vector-add nella documentazione di Kubernetes e distribuirlo. Il container scaricherà, eseguirà ed eseguirà un calcolo CUDA con la GPU.
-
Creare un file denominato
cuda-vector-add.yamle aggiungere quanto segue:apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add # https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile image: "registry.k8s.io/cuda-vector-add:v0.1" resources: limits: nvidia.com/gpu: 1 # requesting 1 GPU -
Applicare il file:
kubectl apply -f cuda-vector-add.yaml -
Eseguire:
kubectl get po cuda-vector-addL'output è simile a:
cuda-vector-add 0/1 Completed 0 91s -
Eseguire:
kubectl logs cuda-vector-addL'output è simile a:
[Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done
Distribuzione di un cluster del carico di lavoro in un sito Edge
Tanzu Kubernetes Grid v1.6+ supporta la distribuzione di cluster del carico di lavoro in host VMware ESXi Edge. È possibile utilizzare questo approccio se si desidera eseguire molti cluster Kubernetes in posizioni diverse tutti gestiti da un cluster di gestione centrale.
Topologia: È possibile eseguire cluster del carico di lavoro Edge in produzione con un singolo nodo del piano di controllo e solo uno o due host. Tuttavia, anche se in questo modo si utilizza meno CPU, memoria e larghezza di banda di rete, non sono disponibili le stesse caratteristiche di resilienza e ripristino dei cluster Tanzu Kubernetes Grid standard per gli ambienti di produzione. Per ulteriori informazioni, vedere Architettura di riferimento della soluzione VMware Tanzu Edge 1.0.
Registro locale: Per ridurre al minimo i ritardi di comunicazione e massimizzare la resilienza, ogni cluster Edge deve disporre del proprio registro di container Harbor locale. Per una panoramica di questa architettura, vedere Registro dei container in Panoramica dell'architettura. Per installare un registro Harbor locale, vedere Distribuzione di un registro Harbor offline in vSphere.
Timeout: Inoltre, quando un cluster del carico di lavoro Edge ha il proprio cluster di gestione remoto in un data center principale, potrebbe essere necessario modificare determinati timeout per dare al cluster di gestione tempo sufficiente per connettersi alle macchine del cluster del carico di lavoro. Per regolare questi timeout, vedere Estensione dei timeout per i cluster Edge per gestire una latenza più elevata, di seguito.
Specifica di un modello di macchina virtuale locale
Se i cluster del carico di lavoro Edge utilizzano il proprio storage isolato anziché lo storage vCenter condiviso, è necessario configurarli per recuperare le immagini dei modelli di macchine virtuali dei nodi, come file OVA, dallo storage locale.
NotaNon è possibile utilizzare
tanzu cluster upgradeper aggiornare la versione di Kubernetes di un cluster del carico di lavoro Edge che utilizza un modello di macchina virtuale locale. Aggiornare invece il cluster seguendo Aggiornamento di un cluster Edge con un modello di macchina virtuale locale nell'argomento Aggiornamento dei cluster del carico di lavoro.
Per specificare un singolo modello di macchina virtuale per il cluster o modelli diversi specifici delle distribuzioni di macchine worker e del piano di controllo:
-
Creare il file di configurazione del cluster e generare il manifesto del cluster come passaggio 1 del processo in due passaggi descritto in Creazione di un cluster basato sulla classe.
-
Assicurarsi che i modelli di macchine virtuali per il cluster:
- Dispongano di una versione di Kubernetes valida per TKG.
- Dispongano di una versione OVA valida corrispondente alla proprietà
spec.osImagesdi un TKr. - Vengano caricati nei vCenter locali e abbiano un percorso di inventario valido, ad esempio
/dc0/vm/ubuntu-2004-kube-v1.27.5+vmware.1-tkg.1.
-
Modifichino la specifica dell'oggetto
Clusternel manifesto nel modo seguente a seconda del fatto che si stia definendo un modello di macchina virtuale a livello di cluster o più modelli di macchine virtuali:-
Modello di macchina virtuale a livello di cluster:
- In
annotations, impostarerun.tanzu.vmware.com/resolve-vsphere-template-from-pathsulla stringa vuota. - Nel blocco
vcenterinspec.topology.variablesimpostaretemplatesul percorso dell'inventario per il modello di macchina virtuale. -
Ad esempio:
annotations: run.tanzu.vmware.com/resolve-vsphere-template-from-path: "" ... spec: topology: class: tkg-vsphere-default-v1.0.0 variables: - name: vcenter value: cloneMode: fullClone datacenter: /dc0 datastore: /dc0/datastore/sharedVmfs-0 folder: /dc0/vm/folder0 network: /dc0/network/VM Network resourcePool: /dc0/host/cluster0/Resources/rp0 ... template: VM-TEMPLATE ...Dove
VM-TEMPLATEè il percorso del modello di macchina virtuale per il cluster.
- In
-
Più modelli di macchine virtuali per
machineDeployment:- In
annotations, impostarerun.tanzu.vmware.com/resolve-vsphere-template-from-pathsulla stringa vuota. - In
variables.overridesper ogni bloccomachineDeploymentsinspec.topology.workerecontrolplane, aggiungere una riga pervcenterche impostatemplateal percorso dell'inventario per il modello di macchina virtuale. -
Ad esempio:
annotations: run.tanzu.vmware.com/resolve-vsphere-template-from-path: "" ... spec: workers: machineDeployments: - class: tkg-worker metadata: annotations: run.tanzu.vmware.com/resolve-os-image: image-type=ova,os-name=ubuntu name: md-1 replicas: 2 variables: overrides: - name: vcenter value: ... datacenter: /dco template: VM-TEMPLATE ...Dove
VM-TEMPLATEè il percorso del modello di macchina virtuale permachineDeployment.
- In
-
-
Utilizzare il file di configurazione modificato per creare il cluster come passaggio 2 del processo descritto in Creazione di un cluster basato sulla classe.
Estensione dei timeout per i cluster Edge per gestire una latenza più elevata
Se il cluster di gestione gestisce in remoto i cluster del carico di lavoro in esecuzione in siti Edge oppure gestisce più di 20 cluster del carico di lavoro, è possibile modificare timeout specifici in modo che Cluster API non blocchi o elimini le macchine che potrebbero essere offline temporaneamente o che impiegano più di 12 minuti per comunicare con il cluster di gestione remoto, in particolare se il provisioning dell'infrastruttura è insufficiente.
Sono disponibili tre impostazioni che è possibile modificare per concedere ai dispositivi Edge ulteriore tempo per comunicare con il loro piano di controllo:
-
MHC_FALSE_STATUS_TIMEOUT: Estendere il valore predefinito12mimpostandolo ad esempio su40mper impedire al controllerMachineHealthCheckdi ricreare la macchina se la condizioneReadyrimaneFalseper più di 12 minuti. Per ulteriori informazioni sui controlli di integrità delle macchine, vedere Configurazione dei controlli di integrità delle macchine per i cluster Tanzu Kubernetes. -
NODE_STARTUP_TIMEOUT: Estendere il valore predefinito20mimpostandolo ad esempio su60mper impedire al controllerMachineHealthCheckdi bloccare l'ingresso di nuove macchine nel cluster perché il loro avvio ha impiegato più di 20 minuti, che è considerato un comportamento che indica mancanza di integrità. -
etcd-dial-timeout-duration: Estendere il valore predefinito di10mpredefinito ad esempio a40snel manifestcapi-kubeadm-control-plane-controller-managerper evitare che i clientetcdnel cluster di gestione si interrompano prematuramente durante la scansione dell'integrità dietcdnei cluster del carico di lavoro. Il cluster di gestione utilizza la sua capacità di connettersi aetcdcome parametro fondamentale per l'integrità della macchina. Ad esempio:-
In un terminale, eseguire:
kubectl edit capi-kubeadm-control-plane-controller-manager -n capi-system -
Modificare il valore per
--etcd-dial-timeout-duration:- args: - --leader-elect - --metrics-bind-addr=localhost:8080 - --feature-gates=ClusterTopology=false - --etcd-dial-timeout-duration=40s command: - /manager image: projects.registry.vmware.com/tkg/cluster-api/kubeadm-control-plane-controller:v1.0.1_vmware.1
-
Inoltre, prestare attenzione a:
-
capi-kubedm-control-plane-manager: Se si "separa" in qualche modo dai cluster del carico di lavoro, potrebbe essere necessario rimbalzarlo su un nuovo nodo, in modo che possa monitorare correttamente
etcdnei cluster del carico di lavoro. -
Le configurazioni Pinniped in TKG presuppongono che i cluster del carico di lavoro siano connessi al cluster di gestione. In caso di disconnessione, è necessario assicurarsi che i pod del carico di lavoro utilizzino account amministrativi o di servizio per comunicare con il server API nei siti Edge. Altrimenti, la disconnessione dal cluster di gestione interferirà con la possibilità dei siti Edge di eseguire l'autenticazione tramite Pinniped nei server API del carico di lavoro locali.
