









Quando si abilita vSphere IaaS control plane in cluster vSphere che poi diventano Supervisori, il piano di controllo Kubernetes viene creato all'interno del livello dell'hypervisor. Questo layer contiene oggetti specifici che consentono di eseguire i carichi di lavoro Kubernetes all'interno di ESXi.
Il diagramma mostra l'architettura generale di vSphere IaaS control plane, con Tanzu Kubernetes Grid in alto, il Supervisore al centro, quindi ESXi, rete e storage in fondo e vCenter Server che svolge la funzione di gestione.
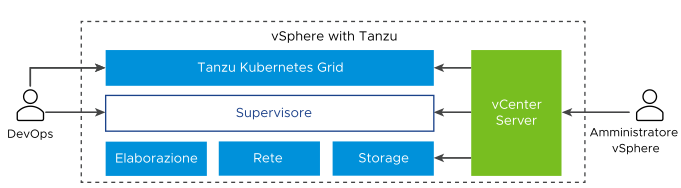
Un Supervisore viene eseguito in un livello SDDC costituito da ESXi per l'elaborazione, rete di NSX o VDS e vSAN o un'altra soluzione di storage condiviso. Lo storage condiviso viene utilizzato per i volumi persistenti di Pod vSphere, macchine virtuali in esecuzione nel Supervisore e pod in un cluster Tanzu Kubernetes Grid. Dopo aver creato un Supervisore, l'amministratore di vSphere può creare Spazi dei nomi vSphere all'interno del Supervisore. Un tecnico di DevOps può eseguire carichi di lavoro costituiti da container in esecuzione all'interno di Pod vSphere, distribuire macchine virtuali tramite il servizio macchina virtuale e creare cluster Tanzu Kubernetes Grid.
È possibile distribuire un Supervisore in tre zone vSphere per fornire alta disponibilità a livello del cluster in modo da proteggere i carichi di lavoro Kubernetes da errori a livello del cluster. Una zona vSphere viene mappata a un cluster vSphere che è possibile configurare come dominio di errore indipendente. In una distribuzione a tre zone, tutti e tre i cluster vSphere diventano un Supervisore. Un Supervisore può anche essere distribuito in un solo cluster vSphere, che creerà automaticamente una zona vSphere e la mapperà al cluster, a meno che non venga utilizzato un cluster vSphere già mappato a una zona. In una distribuzione a cluster singolo, il Supervisore ha alta disponibilità solo a livello di host fornita da vSphere HA.
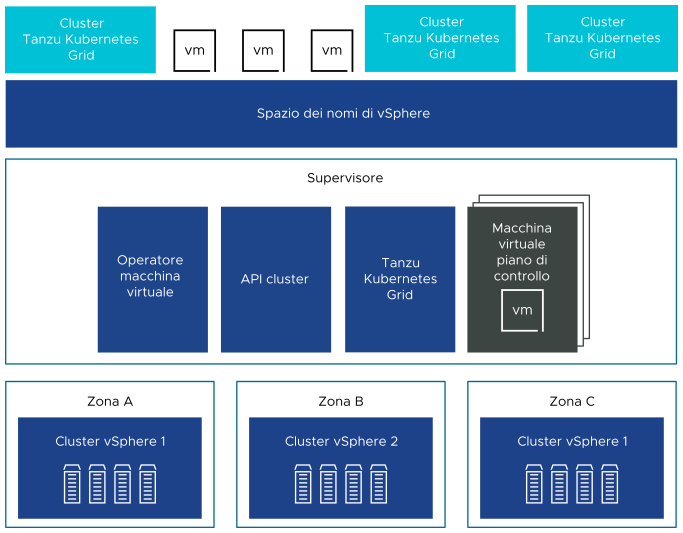
In un Supervisore a tre zone è possibile eseguire carichi di lavoro Kubernetes in cluster Tanzu Kubernetes Grid e macchine virtuali create utilizzando il servizio delle macchine virtuali. Un Supervisore a tre zone include i componenti seguenti:
- Macchina virtuale del piano di controllo del Supervisore. Nel Supervisore vengono create tre macchine virtuali del piano di controllo del Supervisore in totale. In una distribuzione a tre zone, ciascuna zona include una macchina virtuale del piano di controllo. Per le tre macchine virtuali del piano di controllo del Supervisore viene eseguito il bilanciamento del carico, perché ciascuna ha il proprio indirizzo IP. Inoltre, a una delle macchine virtuali viene assegnato un indirizzo IP mobile e viene riservato un 5° indirizzo IP per l'applicazione delle patch. vSphere DRS determina il posizionamento esatto delle macchine virtuali del piano di controllo negli host ESXi che fanno parte del Supervisore e ne esegue la migrazione quando è necessario.
- Tanzu Kubernetes Grid e API del cluster. Moduli in esecuzione in Supervisore che abilitano il provisioning e la gestione dei cluster Tanzu Kubernetes Grid.
- Servizio macchina virtuale. Modulo che è responsabile della distribuzione e dell'esecuzione di macchine virtuali autonome e macchine virtuali che costituiscono i cluster Tanzu Kubernetes Grid.
In un Supervisore a tre zone, viene creato un pool di risorse dello spazio dei nomi in ogni cluster vSphere mappato a una zona. Lo spazio dei nomi si distribuisce in tutti e tre i cluster vSphere in ogni zona. Le risorse utilizzate per lo spazio dei nomi in un Supervisore a tre zone vengono acquisite da tutti e tre i cluster vSphere sottostanti in parti uguali. Ad esempio, se vengono dedicati 300 MHz di CPU, ogni cluster vSphere acquisisce 100 MHz.
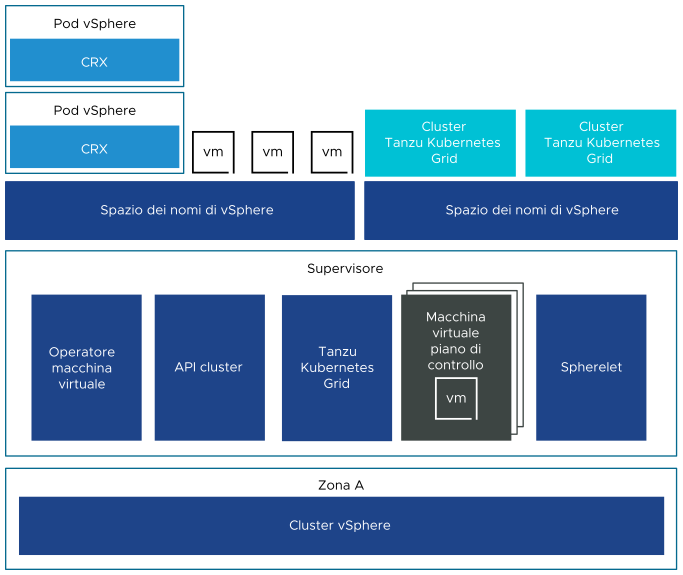
Anche un Supervisore distribuito in un singolo cluster vSphere dispone di tre macchine virtuali del piano di controllo che si trovano negli host ESXi che fanno parte del cluster. In un Supervisore a cluster singolo, è possibile eseguire Pod vSphere oltre a cluster Tanzu Kubernetes Grid e macchine virtuali. vSphere DRS è integrato anche con l'utilità di pianificazione Kubernetes nelle macchine virtuali del piano di controllo del Supervisore, in modo che DRS possa stabilire il posizionamento di Pod vSphere. Quando un tecnico di DevOps pianifica una Pod vSphere, la richiesta passa attraverso il workflow Kubernetes regolare quindi arriva a DRS, che prende la decisione di posizionamento finale.
A causa del supporto di Pod vSphere, un Supervisore a cluster singolo include i componenti aggiuntivi seguenti:
- Spherelet. In ogni host viene creato un processo aggiuntivo chiamato Eletlet. Si tratta di un kubelet per il quale è stato eseguito un porting nativo in ESXi e che consente all'host ESXi di diventare parte del cluster Kubernetes.
- Componente Container Runtime Executive (CRX). CRX è simile a una macchina virtuale dal punto di vista di Hostd e vCenter Server. CRX include un kernel Linux paravirtualizzato che funziona insieme all'hypervisor. CRX utilizza le stesse tecniche di virtualizzazione dell'hardware delle macchine virtuali ed è interessato da un limite di macchine virtuali. Viene utilizzata una tecnica di avvio diretto, che consente al guest Linux di CRX di iniziare il processo init principale senza passare attraverso l'inizializzazione del kernel. Ciò consente ai Pod vSphere di avviarsi rapidamente come i container.
