Scopri come trasmettere in streaming le metriche Supervisore raccolte da Telegraf a una piattaforma di osservabilità personalizzata. Telegraf è abilitato per impostazione predefinita in Supervisore e raccoglie le metriche in formato Prometheus dai componenti di Supervisore, ad esempio il server dell'API Kubernetes, il servizio della macchina virtuale, Tanzu Kubernetes Grid e altri. In qualità di amministratore di vSphere, è possibile configurare una piattaforma di osservabilità personalizzata, ad esempio VMware Aria Operations for Applications, Grafana e altri, per visualizzare e analizzare le metriche di Supervisore raccolte.
Telegraf è un agente basato su server per la raccolta e l'invio di metriche da diversi sistemi, database e IoT. Ogni componente Supervisore espone un endpoint a cui Telegraf si connette. Telegraf invia quindi le metriche raccolte a una piattaforma di osservabilità a scelta. È possibile configurare uno qualsiasi dei plug-in di output supportati da Telegraf come piattaforma di osservabilità per l'aggregazione e l'analisi delle metriche Supervisore. Per informazioni sui plug-in di output supportati, vedere la documentazione di Telegraf.
I componenti seguenti espongono endpoint in cui Telegraf si connette e raccoglie le metriche: server dell'API Kubernetes, etcd, kubelet, gestore controller Kubernetes, pianificatore Kubernetes, Tanzu Kubernetes Grid, servizio della macchina virtuale, servizio delle immagini della macchina virtuale, NSX Container Plug-in (NCP), Container Storage Interface (CSI), gestore certificati, NSX e varie metriche dell'host come CPU, memoria e storage.
Visualizzazione dei pod e della configurazione di Telegraf
Telegraf viene eseguito nello spazio dei nomi del sistema vmware-system-monitoring nel Supervisore. Per visualizzare i pod di Telegraf e ConfigMaps:
- Accedere al pannello di controllo Supervisore con un account amministratore vCenter Single Sign-On.
kubectl vsphere login --server <control planе IP> --vsphere-username [email protected]
- Utilizzare il comando seguente per visualizzare i pod di Telegraf:
kubectl -n vmware-system-monitoring get pods
I pod risultanti sono i seguenti:telegraf-csqsl telegraf-dkwtk telegraf-l4nxk
- Utilizzare il comando seguente per visualizzare le ConfigMaps di Telegraf:
kubectl -n vmware-system-monitoring get cm
Le ConfigMaps risultanti sono le seguenti:default-telegraf-config kube-rbac-proxy-config kube-root-ca.crt telegraf-config
La mappa di configurazione
default-telegraf-configcontiene la configurazione di Telegraf predefinita ed è di sola lettura. È possibile utilizzarla come opzione di fallback per ripristinare la configurazione intelegraf-confignel caso in cui il file sia danneggiato o si desideri solo ripristinare le impostazioni predefinite. L'unica ConfigMap che è possibile modificare ètelegraf-config, definisce quali componenti inviano metriche agli agenti Telegraf e a quali piattaforme. - Visualizza la ConfigMap di
telegraf-config:kubectl -n vmware-system-monitoring get cm telegraf-config -o yaml
inputs della ConfigMap
telegraf-config definisce tutti gli endpoint dei componenti
Supervisore da cui Telegraf raccoglie le metriche, nonché i tipi di metriche stesse. Ad esempio, l'input seguente definisce il server dell'API Kubernetes come endpoint :
[[inputs.prometheus]]
# APIserver
## An array of urls to scrape metrics from.
alias = "kube_apiserver_metrics"
urls = ["https://127.0.0.1:6443/metrics"]
bearer_token = "/run/secrets/kubernetes.io/serviceaccount/token"
# Dropping metrics as a part of short term solution to vStats integration 1MB metrics payload limit
# Dropped Metrics:
# apiserver_request_duration_seconds
namepass = ["apiserver_request_total", "apiserver_current_inflight_requests", "apiserver_current_inqueue_requests", "etcd_object_counts", "apiserver_admission_webhook_admission_duration_seconds", "etcd_request_duration_seconds"]
# "apiserver_request_duration_seconds" has _massive_ cardinality, temporarily turned off. If histogram, maybe filter the highest ones?
# Similarly, maybe filters to _only_ allow error code related metrics through?
## Optional TLS Config
tls_ca = "/run/secrets/kubernetes.io/serviceaccount/ca.crt"
La proprietà alias indica il componente da cui vengono raccolte le metriche. La proprietà namepass specifica quali metriche dei componenti vengono esposte e raccolte rispettivamente dagli agenti Telegraf.
Anche se la ConfigMap telegraf-config contiene già un ampio intervallo di metriche, è comunque possibile definirne altre. Vedere Metriche per i componenti del sistema Kubernetes e Riferimento alle metriche di Kubernetes.
Configurazione della piattaforma di Observability per Telegraf
Nella sezione outps di telegraf-config configurare la posizione in cui Telegraf trasmette le metriche che raccoglie. Sono disponibili diverse opzioni, ad esempio outputs.file, outputs.wavefront, outputs.prometheus_client e outps-https. Nella sezione outps-https è possibile configurare le piattaforme di osservabilità che si desidera utilizzare per l'aggregazione e il monitoraggio delle metriche Supervisore. È possibile configurare Telegraf in modo che invii metriche a più piattaforme. Per modificare la ConfigMap telegraf-config e configurare una piattaforma di osservabilità per la visualizzazione delle metriche di Supervisore, eseguire i passaggi seguenti:
- Accedere al pannello di controllo Supervisore con un account amministratore vCenter Single Sign-On.
kubectl vsphere login --server <control planе IP> --vsphere-username [email protected]
- Salvare la ConfigMap
telegraf-confignella cartella kubectl locale:kubectl get cm telegraf-config -n vmware-system-monitoring -o jsonpath="{.data['telegraf\.conf']}">telegraf.confAssicurarsi di archiviare la mappa di configurazione
telegraf-configin un sistema di controllo della versione prima di apportare eventuali modifiche nel caso in cui si desideri ripristinare una versione precedente del file. Se si desidera ripristinare la configurazione predefinita, è possibile utilizzare i valori della mappa di configurazionedefault-telegraf-config. - Aggiungere le sezioni
outputs.httpcon le impostazioni di connessione delle piattaforme di osservabilità desiderate utilizzando un editor di testo, ad esempio VIM:vim telegraf.config
È possibile rimuovere direttamente il commento dalla sezione seguente e modificare i valori di conseguenza oppure aggiungere nuove sezionioutputs.httpin base alle esigenze.#[[outputs.http]] # alias = "prometheus_http_output" # url = "<PROMETHEUS_ENDPOINT>" # insecure_skip_verify = <PROMETHEUS_SKIP_INSECURE_VERIFY> # data_format = "prometheusremotewrite" # username = "<PROMETHEUS_USERNAME>" # password = "<PROMETHEUS_PASSWORD>" # <DEFAULT_HEADERS>Ad esempio, ecco come si presenta una configurazioneoutputs.httpper Grafana:[[outputs.http]] url = "http://<grafana-host>:<grafana-metrics-port>/<prom-metrics-push-path>" data_format = "influx" [outputs.http.headers] Authorization = "Bearer <grafana-bearer-token>"
Vedere Trasmettere le metriche da Telegraf a Grafana per ulteriori informazioni sulla configurazione dei dashboard e sull'utilizzo delle metriche da Telegraf.
Ed ecco un esempio con VMware Aria Operations for Applications (in precedenza Wavefront):[[outputs.wavefront]] url = "http://<wavefront-proxy-host>:<wavefront-proxy-port>"La modalità consigliata per l'inserimento delle metriche in Aria Operations for Applications è tramite un proxy. Vedere Proxy Wavefront per ulteriori informazioni.
- Sostituire il file
telegraf-configesistente in Supervisore con quello modificato nella cartella locale:kubectl create cm --from-file telegraf.conf -n vmware-system-monitoring telegraf-config --dry-run=client -o yaml | kubectl replace -f -
- Verificare che la nuova configurazione sia stata salvata correttamente:
- Visualizzare la nuova mappa di configurazione telegraf-config:
kubectl -n vmware-system-monitoring get cm telegraf-config -o yaml
- Verificare che tutti i pod di Telegraf siano attivi e in esecuzione:
kubectl -n vmware-system-monitoring get pods
- Nel caso in cui alcuni pod di Telegraf non siano in esecuzione, controllare i registri di Telegraf per risolvere i problemi relativi a tali pod:
kubectl -n vmware-system-monitoring logs <telegraf-pod>
- Visualizzare la nuova mappa di configurazione telegraf-config:
Operazioni di esempio per i dashboard delle applicazioni
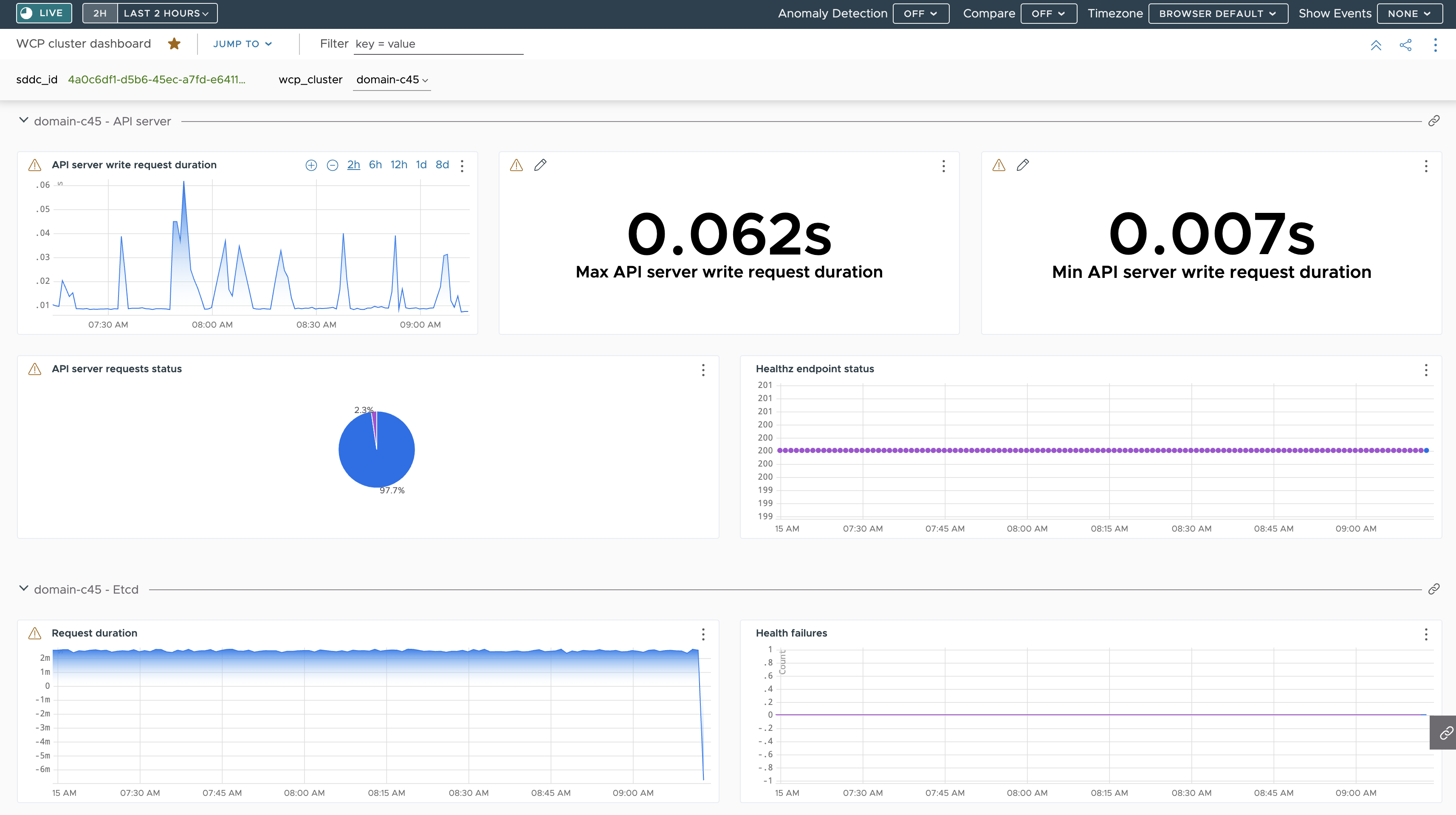
Di seguito è disponibile un dashboard che mostra un riepilogo delle metriche ricevute dal server API ed etcd in un Supervisore tramite Telegraf:
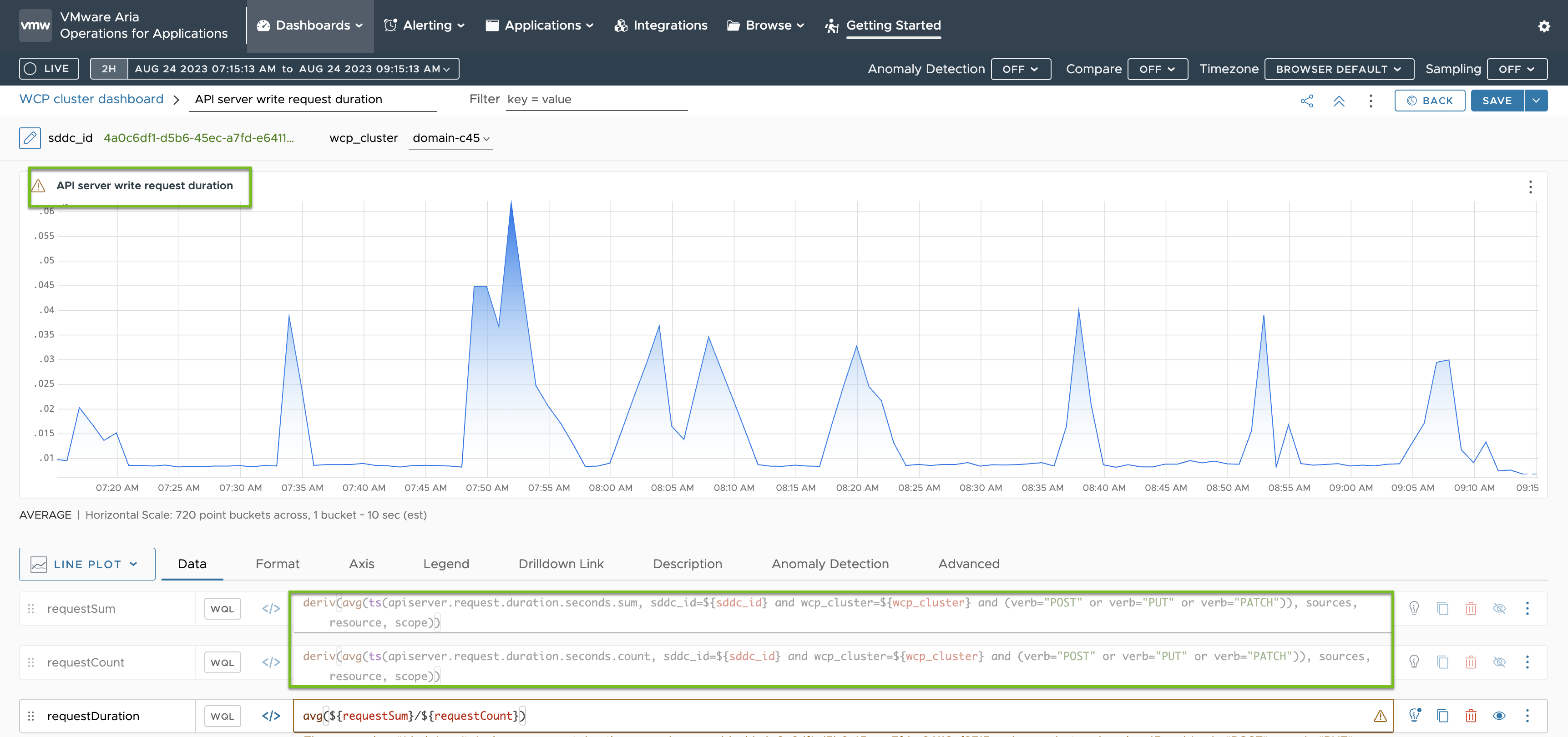
Le metriche per la durata della richiesta di scrittura del server API si basano sulle metriche specificate nella ConfigMap telegraf-config come è possibile vedere evidenziate in verde: